






将第一列的所有词表示成[6,9]的词向量,3个batch_size形成一个3维的矩阵向量
[batch_size,seq_length,embedding_dim]=[3,6,9]
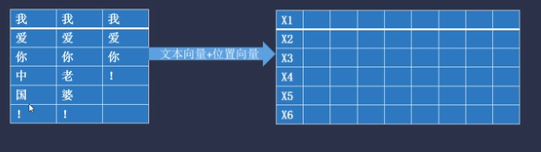
初始化3个[9,9]的权重矩阵,分别是Query_w,Key_W,Value_W,用于模型参数更新

Query_w,Key_W,Value_W分别于每一batch_size相乘得到Q,K,V3个矩阵

超参数设置head=3,将Q,KV分别除以3,得到3个多头的q1,q2,q3,k1,k2,k3,v1,v2,v3
最终Q,K,V的维度变成了[batch_size,seq_length,h,embedd_dim/h]=[3,6,3,3]

将上述的Q,K,V的1维,2维通过transpose互换,得到Q,K,V=[batch_size,h,seq_length,embedd_dim/h],根据注意力的计算公式K需要转置,在最后一维和倒数第2维进行转置互换transpose(-2, -1)) ,为的就是获得词与词之间的关系
取一个头q1,k1举例计算,根据最终计算结果可知,多头的目的是并行执行
,获取一句话单个词与其他词的关系,理解句子上下文的信息

根据注意力计算公式得到一个头的attention
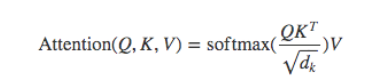

将多头的的attention进行拼接,经过全连接层输出结果

Transformer Encoder multi-head-Attention的理解
最新推荐文章于 2024-02-27 19:37:26 发布















 2494
2494











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









