









Softmax函数公式:

Si 代表的是第i个神经元的输出
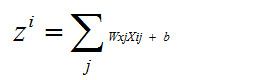
其中wij 是第i个神经元的第 j 个权重,b是偏移值。zi 表示该网络的第i个输出
隐藏层输出经过softmax:
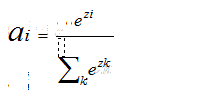
具体过程如下图所示:
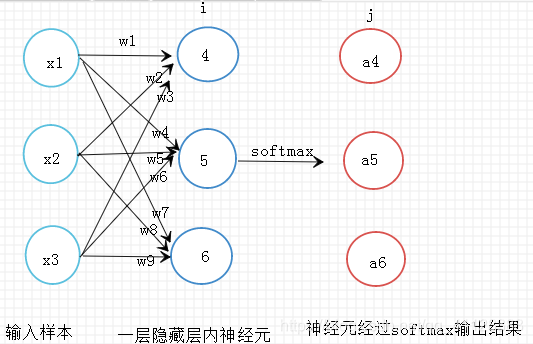
神经元输出结果
z4 = w1x1+w2x2+w3x3
z5 = w4x1+w5x2+w6x3
z6 = w7x1+w8x2+w9*x3
经过softmax函数得到
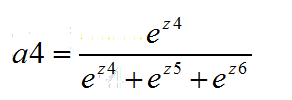
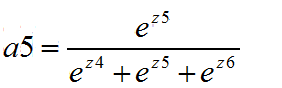
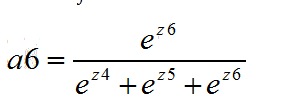
多分类损失函数公式:
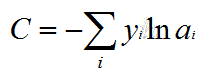 其中yi表示真实的分类结果
其中yi表示真实的分类结果
利用损失函数求梯度
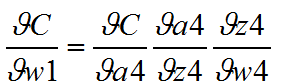
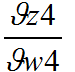 已知不做推导
已知不做推导
求解书过程推导:
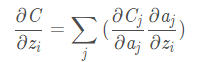
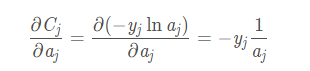
如果i等于j:
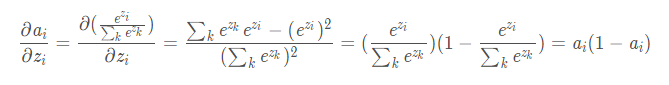
如果i不等于j:
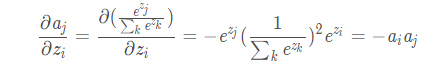
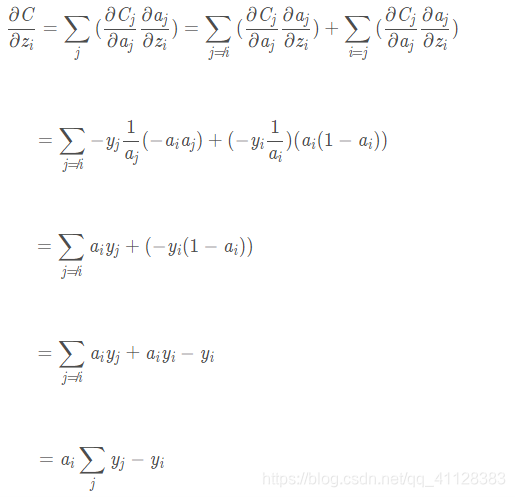
针对分类问题,给定的结果yi 最终只会有一个类别是1,其他类别都是0,因此,对于分类问题,这个梯度等于:
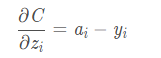

















 1941
1941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









