









FCN全卷积网络模型——高分辨率遥感影像地物识别
这是一篇操作日记
win10与ubuntu的caffe安装过程独立,只是两次不同系统下的演习,真正实验在ubuntu下完成。
操作空间
win10
1:Anaconda 2.0
2:Visual Studio 2013
3:caffe
4:python2.7
Ubuntu 16.04
cuda8.0
cudnn5.1
caffe
win10 python接口配置
本人之前未曾进行过相关学习,搜索到https://blog.csdn.net/zb1165048017/article/details/52980102这篇blog,其中配置步骤十分详细。
经测试而知,anaconda安装完成。
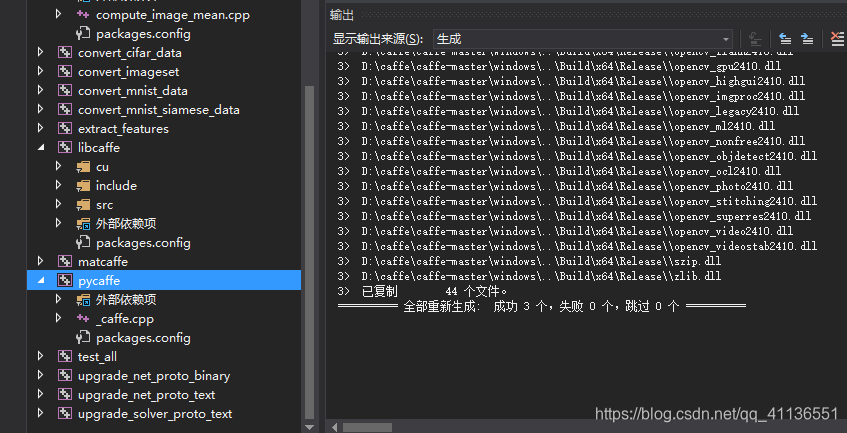
1.生成pycaffe
在vs2013里生成pycaffe后发生错误如下:
错误 110 error LNK1104: 无法打开文件“python27.lib” D:\caffe\caffe-master\windows\caffe\LINK caffe
错误 111 error C2220: 警告被视为错误 - 没有生成“object”文件 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include\cuda_fp16.h 1 1 pycaffe
修正办法:将Anaconda 3.0卸载改为2.0(别忘记修改CommonSettings里的版本),重新编译Pycaffe,任然出现错误:
错误 35 error C2220: 警告被视为错误 - 没有生成“object”文件 C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\include\cuda_fp16.h 1 1 pycaffe
突然想起来,pycaffe的属性没有改变c/c++的 “将警告视为错误”没有改为“否”。改正后运行成功。
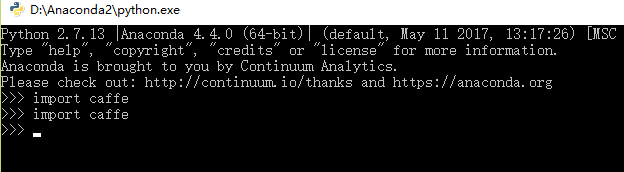
2.import caffe
使用win+R 打开命令行,输入cmd回车。有很多不懂的错误…
开学后重拾FCN配置工作,在另一篇博主那里发现,其实应该是在anaconda里打开对应的python exe,然后>>>import caffe。
结果,当然是一堆错误啦(死亡警告~)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "D:\Anaconda2\lib\site-packages\caffe\__init__.py", line 1, in <module>
from .pycaffe import Net, SGDSolver, NesterovSolver, AdaGradSolver, RMSPropSolver, AdaDeltaSolver, AdamSolver
File "D:\Anaconda2\lib\site-packages\caffe\pycaffe.py", line 15, in <module>
import caffe.io
File "D:\Anaconda2\lib\site-packages\caffe\io.py", line 8, in <module>
from caffe.proto import caffe_pb2
File "D:\Anaconda2\lib\site-packages\caffe\proto\caffe_pb2.py", line 6, in <module>
from google.protobuf.internal import enum_type_wrapper
**ImportError**: No module named google.protobuf.internal
出现这个错误,就直接打开dos,输入 C:\windows\system32>*conda install protobuf*
它提示我 :
“‘conda’ 不是内部或外部命令,也不是可运行的程序或批处理文件。”
这应该是Anaconda没有装好的错误。
在重装了Anaconda2.0后,一切变得快又方便,所以安装这一步真的很重要,版本信息是否和其他软件匹配也必须注意!(之前装的cudnn版本太高,还没降,瑟瑟发抖…)
import caffe后不成功,便第一时间想到是没有装protobuf 在dos端(有的博主说要转到Anaconda Scripts目录下执行)直接 使用conda install protobuf(有博主说这个不行切换为pip install protobuf也可以,但是我这里试了后发现不行,就两个都装了)

在Proceed那里,突然暂停了,等了好久也没反应,按了回车才出现的。
回到Anaconda2里的python.exe,执行import caffe 没有报错,也没有其他信息提供给我,算是成功了?

上面只是在ubuntu正式训练之前的预热,因为那时候导师还没有给我台式机的使用权~~。
win10安装双系统ubuntu16.04
安装过程直接百度,需要准备一个可格式化的U盘,至少20G吧。
安装ubuntu的电脑是办公室台式服务器,只有它才带的动我的模型啊~~~
按照教程下载Ubuntu16.04LTS、U盘制作软件rufus、设置系统启动模式的EasyBCD,需要可留言,网盘似乎有存档。
分割磁盘大概需要200-300G(前提是内存有那么大),如果只是拿来玩玩100G也够,这里分盘需要记住每个盘大概多大,不行就截个图,后面EasyBCD启动需要用到。
重启后疯狂点击某个键(不同电脑打开方式不同,有F8,F1,F2等)打开bios,设置从U盘启动。
and,第一次一定要设置语言为English,不然后面安装caffe时第一步禁用nouveau会乱码,不习惯英文,安装完caffe之后再切换也没关系的。
ubuntu下配置caffe
大致包括这几个步骤:安装依赖包 、禁用 nouveau 、配置环境变量 、下载 CUDA 8.0
、安装 CUDA 8.0 、验证 CUDA 8.0 是否安装成功 、安装 cudnn 、安装 opencv3.1 、安装 caffe
大致参考的https://blog.csdn.net/yhaolpz/article/details/71375762这篇文章,其中会有报错,一个个解决就Ok。
ps…open cv、pycaffe notebook 可以不装,相应地,Makefile.config 里的屏蔽也可以不取消。
caffe中配置FCN
将下载的FCN模型放置在caffe目录下,个人习惯备份一份原始代码在硬盘上。
labelme影像贴图
贴图之前要将影像裁剪为一样大小(128x128或256x256或512x512),本人使用的arcGIS的splitRaster工具,将影像裁为256x256的jpg格式图像。
数据集按照3:7分为验证集和训练集,使用rename.py对图像全部重命名,注意:python中不允许有中文字符出现,即使是注释也不行!
#coding:utf-8
import os
path = "...\Users\Administrator\Desktop\train" #替换为自己的目录
filelist = os.listdir(path)
count=0 #从0开始
for file in filelist:
Olddir=os.path.join(path,file)
if os.path.isdir(Olddir):
continue
filename=os.path.splitext(file)[0]
filetype=os.path.splitext(file)[1]
Newdir=os.path.join(path,'train_'+str(count).zfill(4)+filetype) #输出目录+文件名+filetype文件类型
os.rename(Olddir,Newdir)
print('train_'+str(count).zfill(4)) #这里记得把print出来的文件名全部复制到一个txt文件中去,后面fcn模型中train和test需要用到!
count+=1
input()
输出结果为“train_0000.jpg”、“train_0001.jpg”…
本人下载的label是最简单版本的,安装过程与https://www.cnblogs.com/wangxiaocvpr/p/9997690.html大致相同,为了方便操作,该插件是在本人笔记本上安装的,直接使用命令端调用labelme,具体安装过程请移步百度。
贴图完成后会生成json文件,我一般打开labelme后就会把output_dir和input_dir设置好,点击自动保存按钮,因为有时候贴图超过图片所在范围labelme就会崩掉,下一次打开记录仍然在,且直接点击next就可以切换到下一张。
json_to_dataset.exe,原本的代码是一个个转的,这里贴出本人的批量转换代码:
import argparse
import base64
import json
import os
import os.path as osp
import PIL.Image
import yaml
from labelme.logger import logger
from labelme import utils
def main():
logger.warning('This script is aimed to demonstrate how to convert the'
'JSON file to a single image dataset, and not to handle'
'multiple JSON files to generate a real-use dataset.')
parser = argparse.ArgumentParser()
parser.add_argument('File')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
files = os.listdir(args.File)
for i in range(0,len(files)):
print(files[i])
json_file = os.path.join(args.File,files[i])
if args.out is None:
out_dir = osp.basename(json_file).replace('.', '_')
out_dir = osp.join(osp.dirname(json_file), out_dir)
else:
out_dir = args.out
if not osp.exists(out_dir):
os.mkdir(out_dir)
data = json.load(open(json_file))
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(json_file), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in sorted(data['shapes'], key=lambda x: x['label']):
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
label_names = [None] * (max(label_name_to_value.values()) + 1)
for name, value in label_name_to_value.items():
label_names[value] = name
lbl_viz = utils.draw_label(lbl, img, label_names)
num=os.path.splitext(files[i])[0] ###split the file count[i] --> 0030.json to 0030 and .json
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, num+'.png'), lbl) ###输出贴图png文件名与json文件名相同
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
#logger.warning('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
logger.info('Saved to: {}'.format(out_dir))
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
之前参考了一些其他博主的批量转换,结果是错的,融合图的图例会变成1:0background、2:4 0100、3:2 0200 这样(0100、0200是我的标签名),实际应该是下图这样:

不过这里本人有个疑问:labelme使用json_to_dataset后我的标签图是8位彩色,并非其他博主说的8位灰度图,不知道是不是labelme更新了版本?参考github给出的labelme代码说明,贴图label也是彩色的。
FCN模型训练及测试
本人是仿照voc数据集制作的,将测试集(包括:jpg原图+png贴图)放在pascal/voc2012目录下对应位置,训练集放在sbdd/banchmark/benchmarkRelease目录下对应位置,其中,sbdd需要新建,banchmark文件需要下载,下载地址 https://pan.baidu.com/s/1bhPulA6M4fXZH9Nl3yfCYA mm:i9st
将上面rename.py后复制的图片文件名复制到相应的训练集train.txt、验证集seg11valid.txt中去,在训练的时候会调用该文件夹来读取图片。
另外,不知道大家有没有把图片从win10复制到ubuntu下拓展名变成大写JPG的情况,反正我是有,写一个bat文件,放在win10的图片文件夹下跑一遍就Ok了。
超参数、分类数、迭代次数和权重获取方式等都是按照自己的情况修改。
net.py文件中有个计算平均RGB的地方,看有的博主修改了,有的没有修改,在此奉上从别人那里借鉴的计算代码:
import os
from PIL import Image
import matplotlib.pyplot as plt
import numpy as np
from scipy.misc import imread
filepath = '/home/zjhzwhj/caffe/fcn.berkeleyvision.org-master/data/sbdd/benchmark/benchmark_RELEASE/dataset/img'
pathDir = os.listdir(filepath)
R_channel = 0
G_channel = 0
B_channel = 0
for idx in xrange(len(pathDir)):
filename = pathDir[idx]
img = imread(os.path.join(filepath, filename))
R_channel = R_channel + np.sum(img[:,:,0])
G_channel = G_channel + np.sum(img[:,:,1])
B_channel = B_channel + np.sum(img[:,:,2])
num = len(pathDir) * 256 * 256
R_mean = R_channel / num
G_mean = G_channel / num
B_mean = B_channel / num
print("R_mean is %f, G_mean is %f, B_mean is %f" %(R_mean, G_mean, B_mean))
修改好net.py中的num_output=21的地方和数据集地址后,运行python net.py,train.prototxt、val.prototxt会相应改动,不需要自己手动修改!
其他也没什么好说的,需要详细教程的可以参考这一篇的后半部分:https://blog.csdn.net/zoro_lov3/article/details/74550735
summary
受到样本数据集太小的影响,加上我用的影像光谱分辨率不够高,即使用了fine-tune,精度最高也只有0.60,与预期效果相差甚远,但也算是一次caffe小小实践。训练+数据处理前后耗时大半个月,年前配置caffe耗费一个星期,安装双系统对本人来说也是一个未知领域,算是给大学生活留下最后一笔财富,前两天提交了毕业论文终稿,接下来就是答辩啦,请叫我过儿!!!
第一次开博,写得不够好,一些地方也只是个人理解,望各位大佬多多批评指正!

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}