







机器学习——科学计算库中主要介绍的内容是人工智能深度学习过程常用的几个python库,主要有Numpy,Matplotlib,Pandas等,具体如下所示
在学习的过程中,我也从网上借鉴了多位大佬的优秀博文并结合自己的想法形成了自己的学习笔记,对此对大佬的博文表示感谢,所有的借鉴内容都有在文章的最后标明链接来源。
目录
2.6.1 np.linspace (start, stop, num, endpoint)
2.6.2 np.arange(start,stop, step, dtype)
2.10.1 ndarray.reshape(shape, order)
2.10.2 ndarray.resize(new_shape)
2.10.5 ndarray.tostring([order])或者ndarray.tobytes([order])
2.4.5 多个坐标系显示— plt.subplots(面向对象的画图方法)
前言
目前在对python的第三方库进行安装的时候经常会出现,无法安装或者安装失败的情况,这种情况下可以将安装的源换成国内的源进行安装,比如:
pip install numpy -i https://pypi.tuna.tsinghua.edu.cn/simple
注意后面的 -i https://pypi.tuna.tsinghua.edu.cn/simple 是让下载速度变快的。
一、Numpy库的介绍
Numpy(Numerical Python)是一个开源的Python科学计算库,用于快速处理任意维度的数组。
Numpy支持常见的数组和矩阵操作。对于同样的数值计算任务,使用Numpy比直接使用Python要简洁的多。
Numpy使用ndarray对象来处理多维数组,该对象是一个快速而灵活的大数据容器。
Numpy是一个用python实现的科学计算的扩展程序库,包括:
* 1、一个强大的N维数组对象Array;
* 2、比较成熟的(广播)函数库;
* 3、用于整合C/C++和Fortran代码的工具包;
* 4、实用的线性代数、傅里叶变换和随机数生成函数。numpy和稀疏矩阵运算包scipy配合使用更加方便。
NumPy(Numeric Python)提供了许多高级的数值编程工具,如:矩阵数据类型、矢量处理,以及精密的运算库。专为进行严格的数字处理而产生。多为很多大型金融公司使用,以及核心的科学计算组织如:Lawrence Livermore,NASA用其处理一些本来使用C++,Fortran或Matlab等所做的任务。
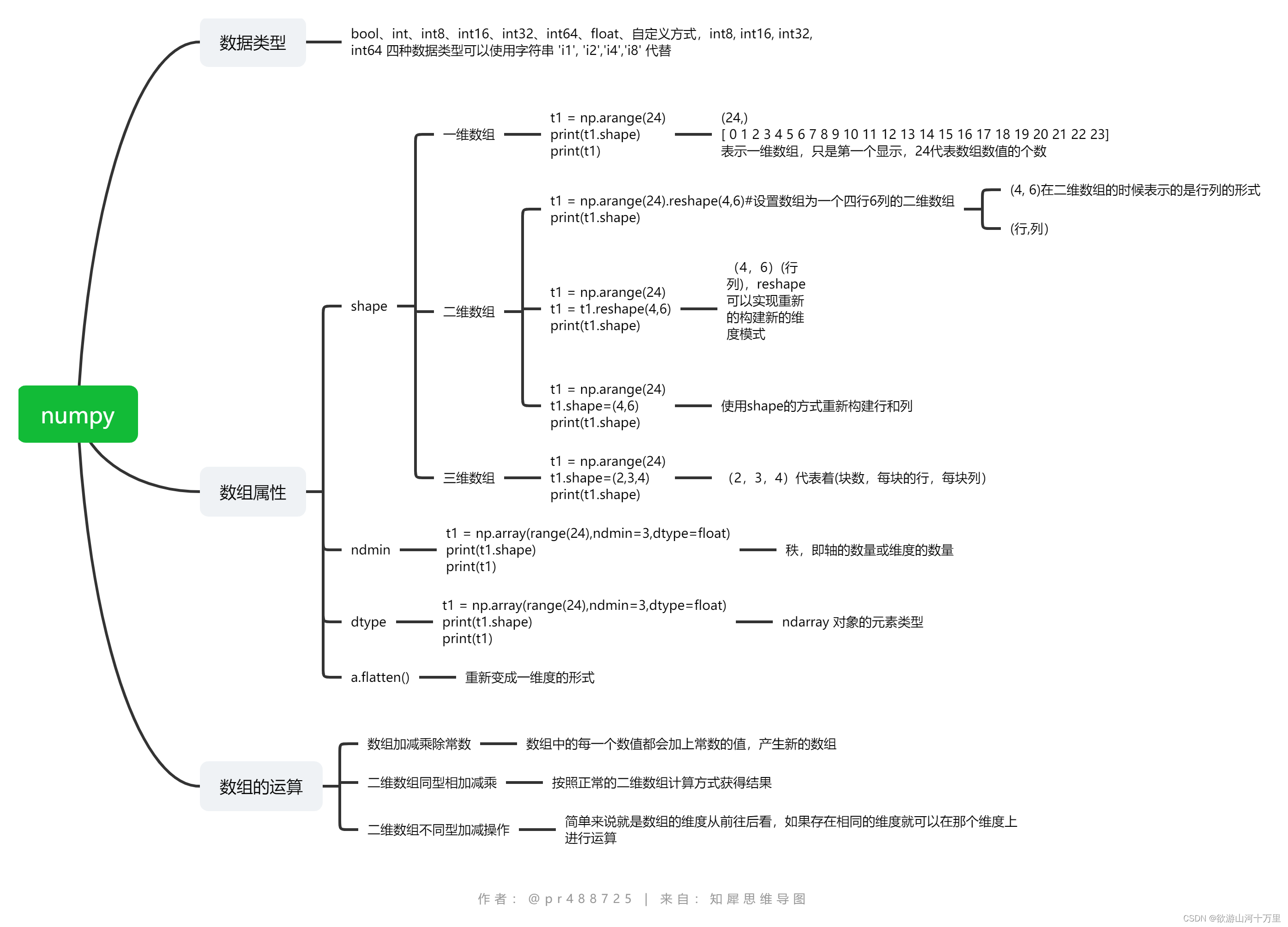
1.N维数组-ndarray
1.1ndarray的属性
| 属性名字 | 属性解释 |
|---|---|
| ndarray.shape | 数组维度的元组 |
| ndarray.ndim | 数组维数 |
| ndarray.size | 数组中的元素数量 |
| ndarray.itemsize | 一个数组元素的长度(字节) |
| ndarray.dtype | 数组元素的类型 |
1.2 ndarray的形状
import numpy as np
a = np.array([[1,2,3],[4,5,6]])
b = np.array([1,2,3,4])
c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])
print(a.shape)#二位数组(2,3)代表2行3列
print(b.shape)#一维数组(4,)代表1行4列
print(c.shape)#三维数组(3,2,3)。代表2行3列,3个高度如何理解数组的形状?
二维数组:
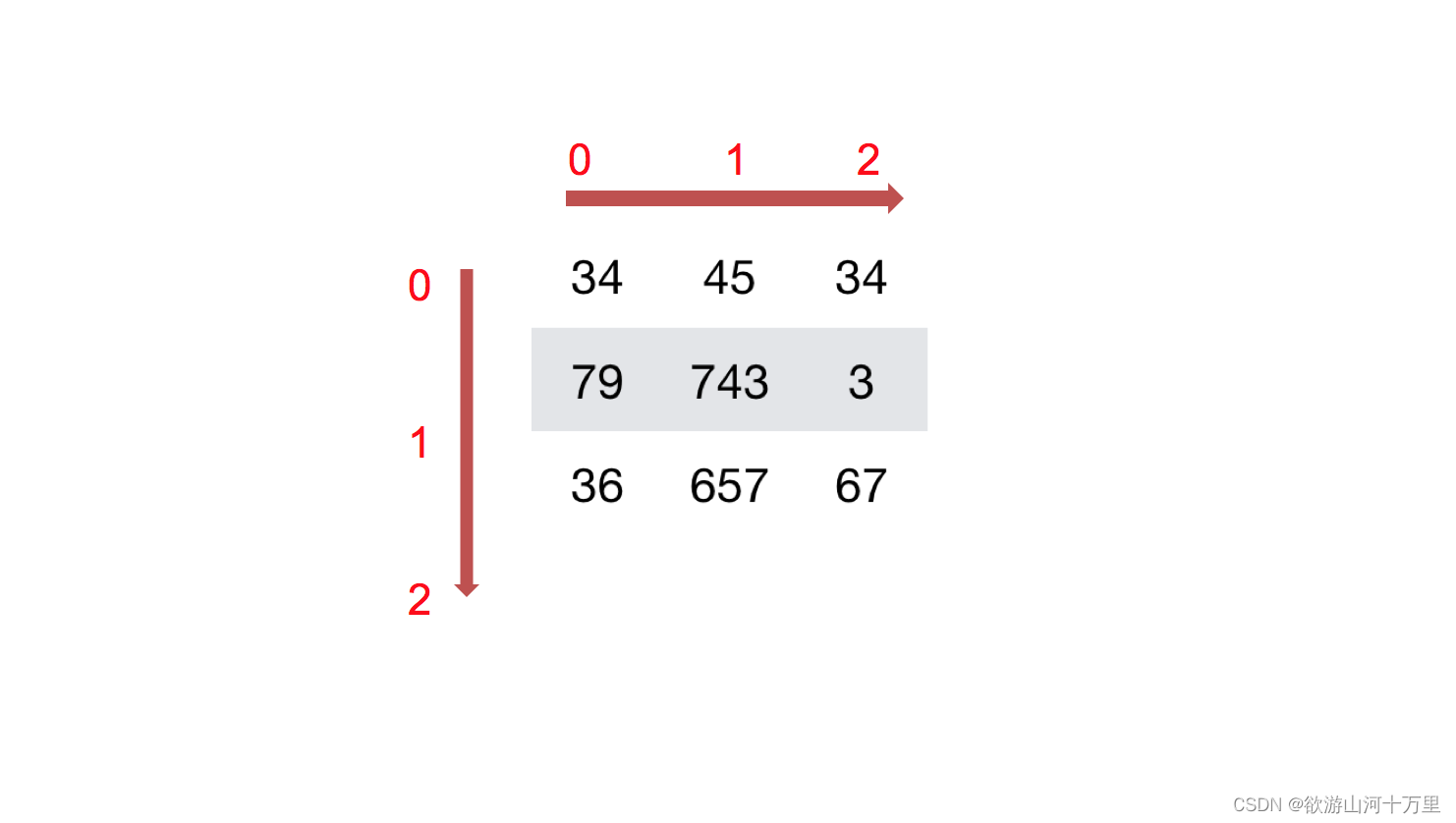
二维数组比较容易理解,比如a = np.array([[1,2,3],[4,5,6]])中的形状是(2,3)。这里面的2代表的是行数,3代表的是列数,看起来是比较直观的
三维数组:
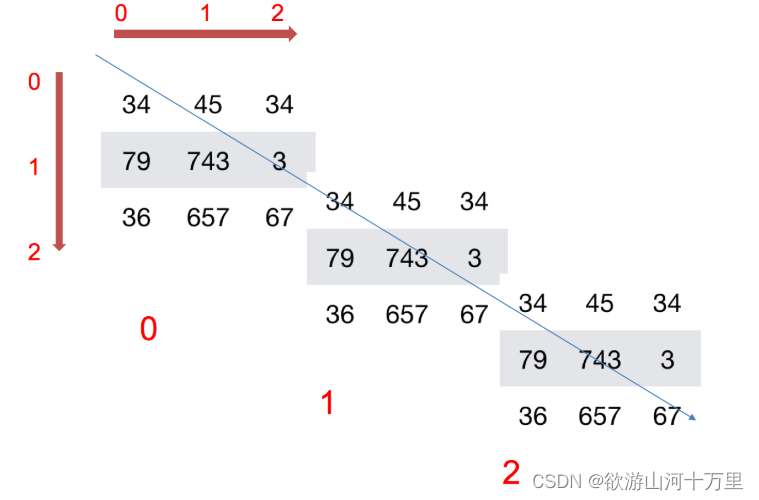
三维数组理解起来会比二维数组相对来说会复杂一些,比如c = np.array([[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]],[[1,2,3],[4,5,6]]])中的形状是(3,2,3)在形状中第二位和第三位的2和3代表是二维平面下的行和列数,第一个数值代表的是层数。就是像2行3列这样的平面一共有多少层。
1.3ndarray的类型
判断数组的类型可以通过语法type的形式实现。
>>> type(score.dtype)
<type 'numpy.dtype'>dtype是numpy.dtype类型,先看看对于数组来说都有哪些类型
| 名称 | 描述 | 简写 |
|---|---|---|
| np.bool | 用一个字节存储的布尔类型(True或False) | 'b' |
| np.int8 | 一个字节大小,-128 至 127 | 'i' |
| np.int16 | 整数,-32768 至 32767 | 'i2' |
| np.int32 | 整数,-2^31 至 2^32 -1 | 'i4' |
| np.int64 | 整数,-2^63 至 2^63 - 1 | 'i8' |
| np.uint8 | 无符号整数,0 至 255 | 'u' |
| np.uint16 | 无符号整数,0 至 65535 | 'u2' |
| np.uint32 | 无符号整数,0 至 2^32 - 1 | 'u4' |
| np.uint64 | 无符号整数,0 至 2^64 - 1 | 'u8' |
| np.float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | 'f2' |
| np.float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | 'f4' |
| np.float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | 'f8' |
| np.complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | 'c8' |
| np.complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | 'c16' |
| np.object_ | python对象 | 'O' |
| np.string_ | 字符串 | 'S' |
| np.unicode_ | unicode类型 | 'U' |
创建数组的时候指定类型
>>> a = np.array([[1, 2, 3],[4, 5, 6]], dtype=np.float32)
>>> a.dtype
dtype('float32')
>>> arr = np.array(['python', 'tensorflow', 'scikit-learn', 'numpy'], dtype = np.string_)
>>> arr
array([b'python', b'tensorflow', b'scikit-learn', b'numpy'], dtype='|S12')2.Numpy基本操作
2.1列表转化为矩阵
import numpy as np
array = np.array([[1,3,5],[4,6,9]])
print(array)
#使用ndmin输出数组的维度
print("number of dim:",array.ndim)#输出数组的维度
print("shape:",array.shape)#输出数组的形状
print("size",array.size)#输出数组元素的个数
#创建一个一维度的数组
a = np.array([2,23,4], dtype=np.int32) # np.int默认为int32
print(a)
print(a.dtype)
#创建多维数组
b = np.array([[2,3,4],
[3,4,5]])
print(b) # 生成2行3列的矩阵2.2创建全1数组
ones = np.ones([4,8])
#返回的结果
array([[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.],
[1., 1., 1., 1., 1., 1., 1., 1.]])np.zeros_like(ones)#创建一个全0的矩阵像ones维度一样
返回的结果
array([[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0.]])2.3创建全0数组
a = np.zeros((3,4))
print(a) # 生成3行4列的全零矩阵2.4创建全空数组
a = np.empty((3,4))
#空的值用0表示2.5np.array和np.asarray的区别
a = np.array([[1,2,3],[4,5,6]])
# 从现有的数组当中创建
a1 = np.array(a)
# 相当于索引的形式,并没有真正的创建一个新的
a2 = np.asarray(a)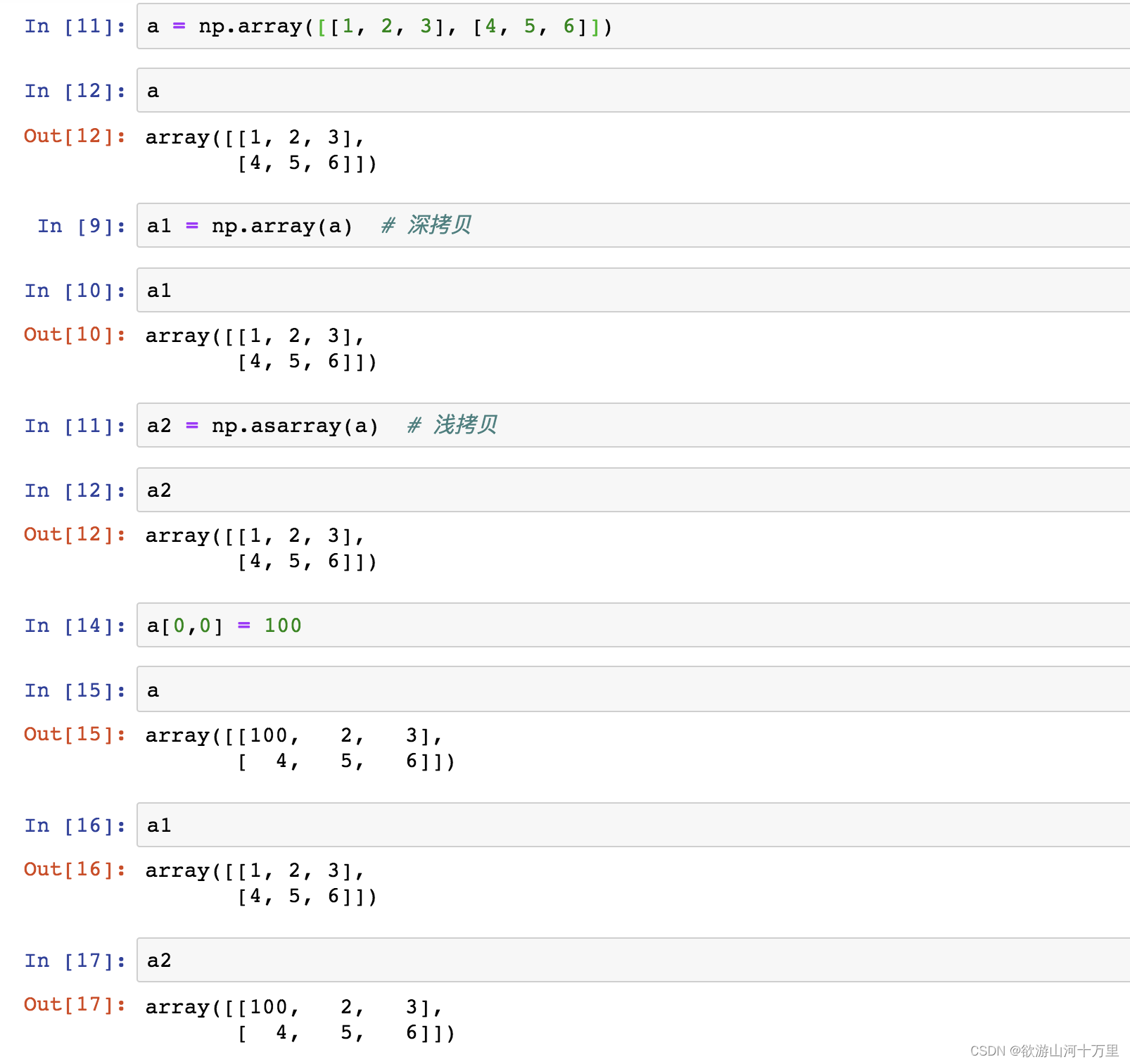
2.6 生成固定范围的数组
2.6.1 np.linspace (start, stop, num, endpoint)
- 创建等差数组 — 指定数量
- 参数:
- start:序列的起始值
- stop:序列的终止值
- num:要生成的等间隔样例数量,默认为50
- endpoint:序列中是否包含stop值,默认为ture
# 生成等间隔的数组
np.linspace(0, 100, 11)
#返回结果
array([ 0., 10., 20., 30., 40., 50., 60., 70., 80., 90., 100.])2.6.2 np.arange(start,stop, step, dtype)
- 创建等差数组 — 指定步长
- 参数
- step:步长,默认值为1
np.arange(10, 50, 2)
#返回的结果是
array([10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30, 32, 34, 36, 38, 40, 42,
44, 46, 48])2.7 reshape操作
import numpy as np
#创建线段型数据
a = np.linspace(1,10,20) # 开始端1,结束端10,且分割成20个数据,生成线段
b = a.reshape((5,4))#将a转化成(5,4)复制给b
print(b.shape)#(5,4)2.8 生成随机数组(np.random模块)
2.8.1正态分布
什么是正态分布?
正态分布是一种概率分布。正态分布是具有两个参数μ和σ的连续型随机变量的分布,第一参数μ是服从正态分布的随机变量的均值,第二个参数σ是此随机变量的标准差,所以正态分布记作N(μ,σ )。
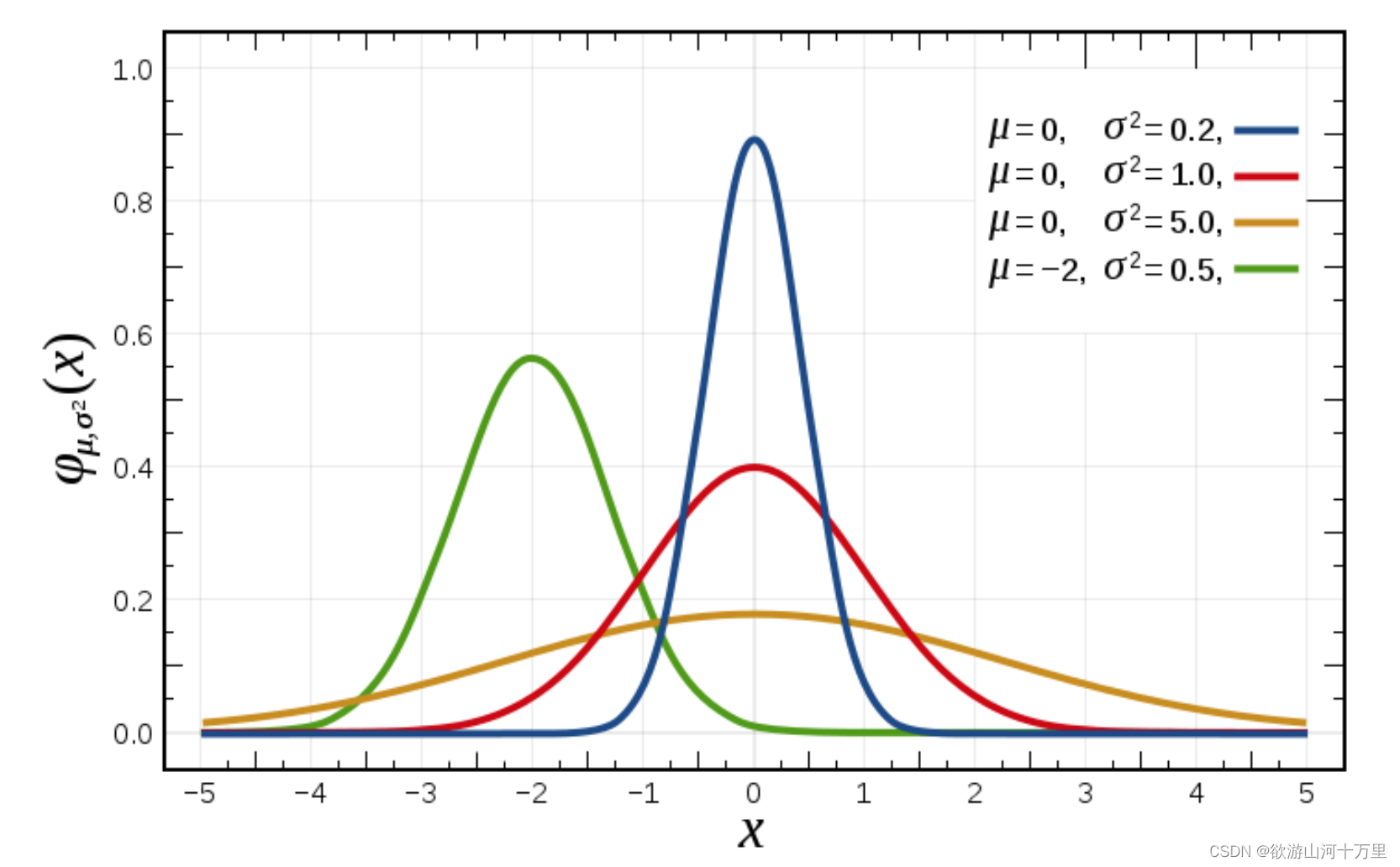
2.正态分布的应用
生活、生产与科学实验中很多随机变量的概率分布都可以近似地用正态分布来描述。
3.正态分布特点
μ决定了其位置,其标准差σ决定了分布的幅度。当μ = 0,σ = 1时的正态分布是标准正态分布。
方差:是在概率论和统计方差衡量一组数据时离散程度的度量
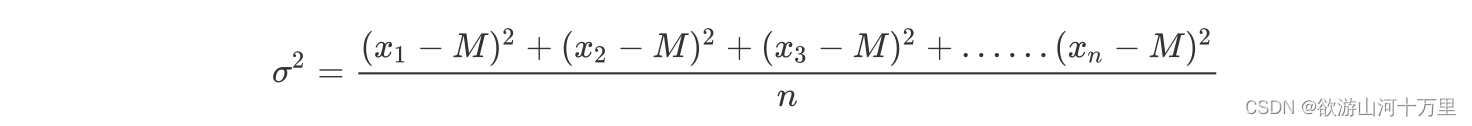
其中M为平均值,n为数据总个数,σ 为标准差,σ ^2可以理解一个整体为方差

标准差与方差的意义可以理解成数据的一个离散程度的衡量
2.8.2 正态分布创建方式
np.random.randn(d0, d1, …, dn)
功能:从标准正态分布中返回一个或多个样本值
np.random.normal(loc=0.0, scale=1.0, size=None)
loc:float
此概率分布的均值(对应着整个分布的中心centre)
scale:float
此概率分布的标准差(对应于分布的宽度,scale越大越矮胖,scale越小,越瘦高)
size:int or tuple of ints
输出的shape,默认为None,只输出一个值
np.random.standard_normal(size=None)
返回指定形状的标准正态分布的数组。举例1:生成均值为1.75,标准差为1的正态分布数据,100000000个
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
x1 = np.random.normal(1.75,1,10000)#:生成均值为1.75,标准差为1的正态分布数据,10000个
print(x1.shape)#输出形状
print(x1)#输出值
将以上的数据绘制成直方图
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
x1 = np.random.normal(1.75,1,100000000)#:生成均值为1.75,标准差为1的正态分布数据,10000个
print(x1.shape)#输出形状
print(x1)#输出值
# 1.创建画布
fig = plt.figure(figsize=(20,8),dpi=80)
plt.hist(x1,1000)
plt.show() 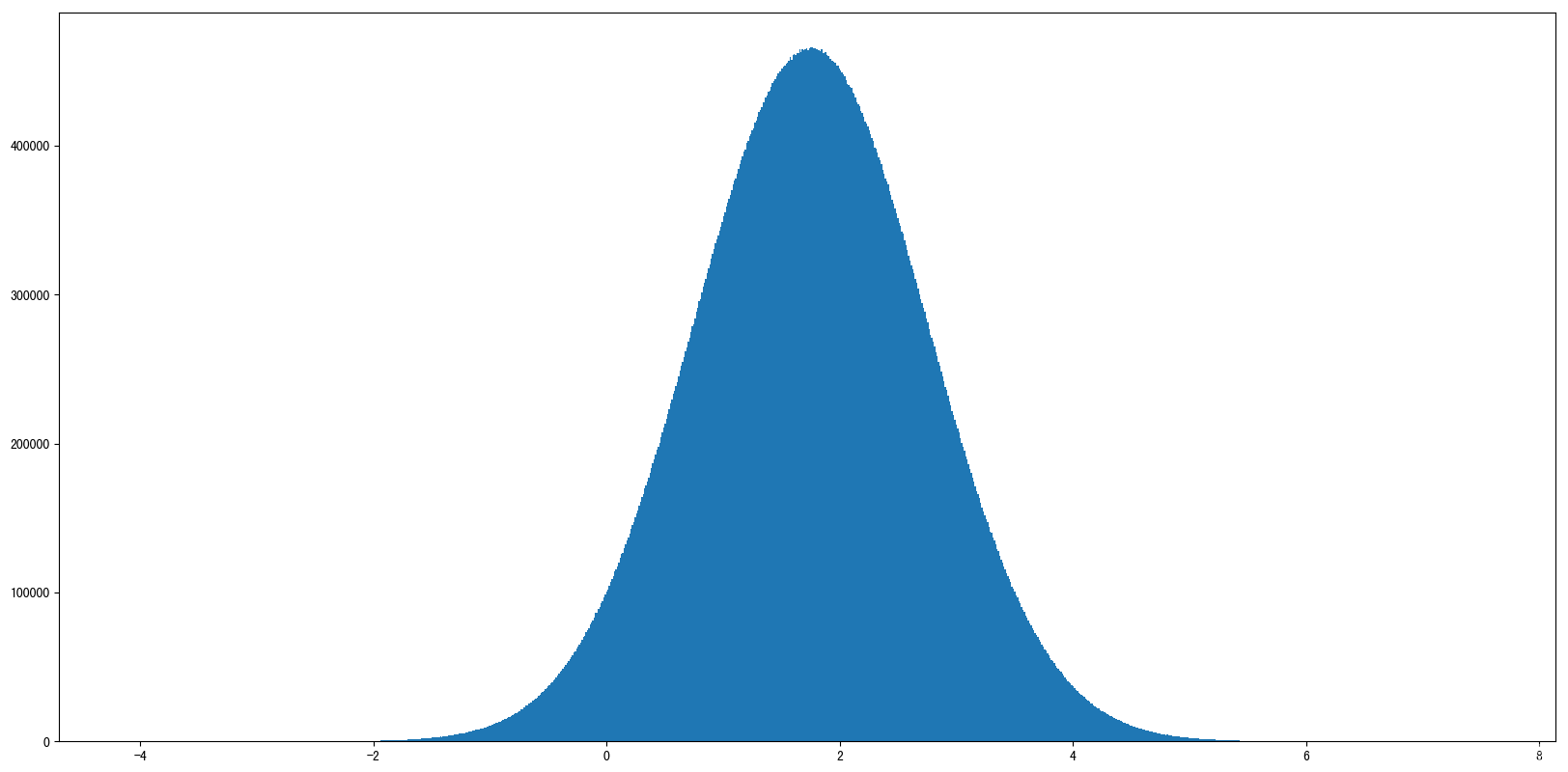
举例2:随机生成4支股票1周的交易日涨幅数据
4支股票,一周(5天)的涨跌幅数据,如何获取?
- 随机生成涨跌幅在某个正态分布内,比如均值0,方差1
股票涨跌幅数据的创建
# 创建符合正态分布的4只股票5天的涨跌幅数据
stock_change = np.random.normal(0, 1, (4, 5))
stock_change返回结果
array([[ 0.0476585 , 0.32421568, 1.50062162, 0.48230497, -0.59998822],
[-1.92160851, 2.20430374, -0.56996263, -1.44236548, 0.0165062 ],
[-0.55710486, -0.18726488, -0.39972172, 0.08580347, -1.82842225],
[-1.22384505, -0.33199305, 0.23308845, -1.20473702, -0.31753223]])2.8.3均匀分布
np.random.rand(d0, d1, ..., dn)
返回[0.0,1.0)内的一组均匀分布的数。
np.random.uniform(low=0.0, high=1.0, size=None)
功能:从一个均匀分布[low,high)中随机采样,注意定义域是左闭右开,即包含low,不包含high.
参数介绍:
low: 采样下界,float类型,默认值为0;
high: 采样上界,float类型,默认值为1;
size: 输出样本数目,为int或元组(tuple)类型,例如,size=(m,n,k), 则输出mnk个样本,缺省时输出1个值。
返回值:ndarray类型,其形状和参数size中描述一致。
np.random.randint(low, high=None, size=None, dtype='l')
从一个均匀分布中随机采样,生成一个整数或N维整数数组,
取数范围:若high不为None时,取[low,high)之间随机整数,否则取值[0,low)之间随机整数。画图看分布情况:
#coding = utf-8
from matplotlib import pyplot as plt
import numpy as np
#生成均分分布的随机数
x2 = np.random.uniform(-1,1,1000000)
#创建画布
fig = plt.figure(figsize=(10,10),dpi=100)
#绘制直方图
plt.hist(x2,bins=1000)
plt.show()
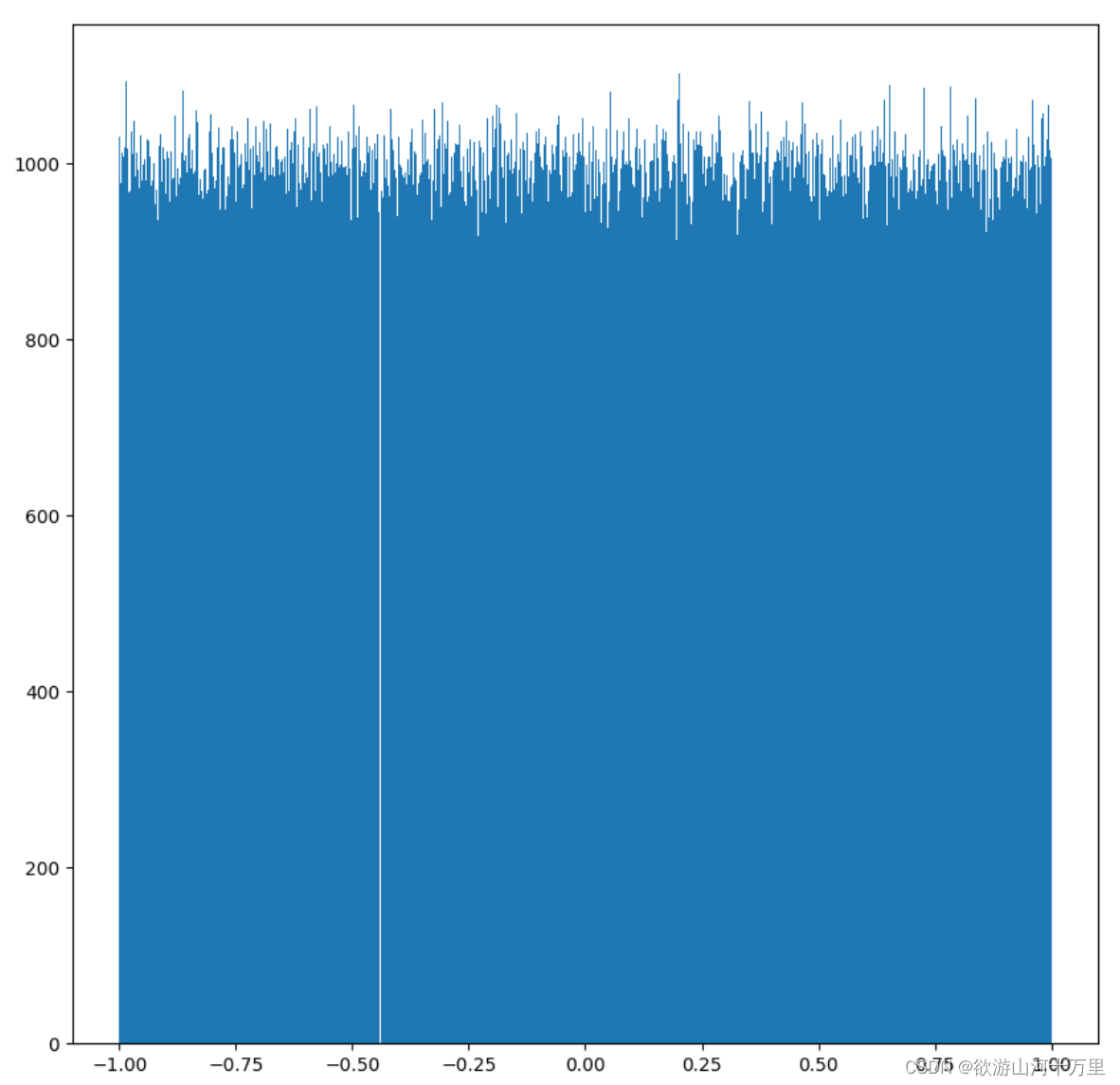
2.9 数组的索引、切片
一维、二维、三维的数组如何索引?
- 直接进行索引,切片
- 对象[:, :] -- 先行后列
二维数组索引方式:
- 举例:获取第一个股票的前3个交易日的涨跌幅数据
# 二维的数组,两个维度
stock_change[0, 0:3]
#返回结果
array([-0.03862668, -1.46128096, -0.75596237])三维索引方式
# 三维
a1 = np.array([ [[1,2,3],[4,5,6]], [[12,3,34],[5,6,7]]])
# 返回结果
array([[[ 1, 2, 3],
[ 4, 5, 6]],
[[12, 3, 34],
[ 5, 6, 7]]])
# 索引、切片
>>> a1[0, 0, 1] # 输出: 22.10形状修改
2.10.1 ndarray.reshape(shape, order)
- 返回一个具有相同数据域,但shape不一样的视图
- 行、列不进行互换
# 在转换形状的时候,一定要注意数组的元素匹配
stock_change.reshape([5, 4])
stock_change.reshape([-1,10]) # 数组的形状被修改为: (2, 10), -1: 表示通过待计算2.10.2 ndarray.resize(new_shape)
- 修改数组本身的形状(需要保持元素个数前后相同)
- 行、列不进行互换
stock_change.resize([5, 4])
# 查看修改后结果
stock_change.shape
(5, 4)2.10.3 ndarray.T数组的转置
- 数组的转置
- 将数组的行、列进行互换
stock_change.T.shape
(4, 5)2.10.4 ndarray.astype(type)
stock_change.astype(np.int32)2.10.5 ndarray.tostring([order])或者ndarray.tobytes([order])
arr = np.array([[[1, 2, 3], [4, 5, 6]], [[12, 3, 34], [5, 6, 7]]])
arr.tostring()3.ndarray的基本运算
3.1数组与数的运算
数组与数之间的运算可以理解为数组中的每一个数据和数之间的运算操作,可以进行的操作有+,-,*,/,**,//等
#coding = utf-8
import numpy as np
arr = np.array([[1,2,3,2,1,4],[5,6,1,2,3,1]])
print(arr)
print(arr+1)
print(arr/2)
print(arr*2)
print(arr**2)
print(arr-1)
print(arr//2)
print(arr%2)
3.2数组与数组的运算
同维度的数组运算并不会遵守矩阵的运算规则,也是矩阵中对应位置的数据实现相加。比如
a = np.array([[1,2],[1,2]])
b = np.array([[1,2],[1,2]])
c=a*b这种情况的运算结果是[[1,4],[1,4]]显示是不符合矩阵的运算规则的。也就是说,数组之间的加减乘除也都是同位置数据之间的操作。这里面需要保证数组的维度是一样的。
3.2.1 广播机制
数组在进行矢量化运算时,要求数组的形状是相等的。当形状不相等的数组执行算术运算的时候,就会出现广播机制,该机制会对数组进行扩展,使数组的shape属性值一样,这样,就可以进行矢量化运算了。下面通过一个例
arr1 = np.array([[0],[1],[2],[3]])
arr1.shape
# (4, 1)
arr2 = np.array([1,2,3])
arr2.shape
# (3,)
arr1+arr2
# 结果是:
array([[1, 2, 3],
[2, 3, 4],
[3, 4, 5],
[4, 5, 6]])上述代码中,数组arr1是4行1列,arr2是1行3列。这两个数组要进行相加,按照广播机制会对数组arr1和arr2都进行扩展,使得数组arr1和arr2都变成4行3列。
下面通过一张图来描述广播机制扩展数组的过程:
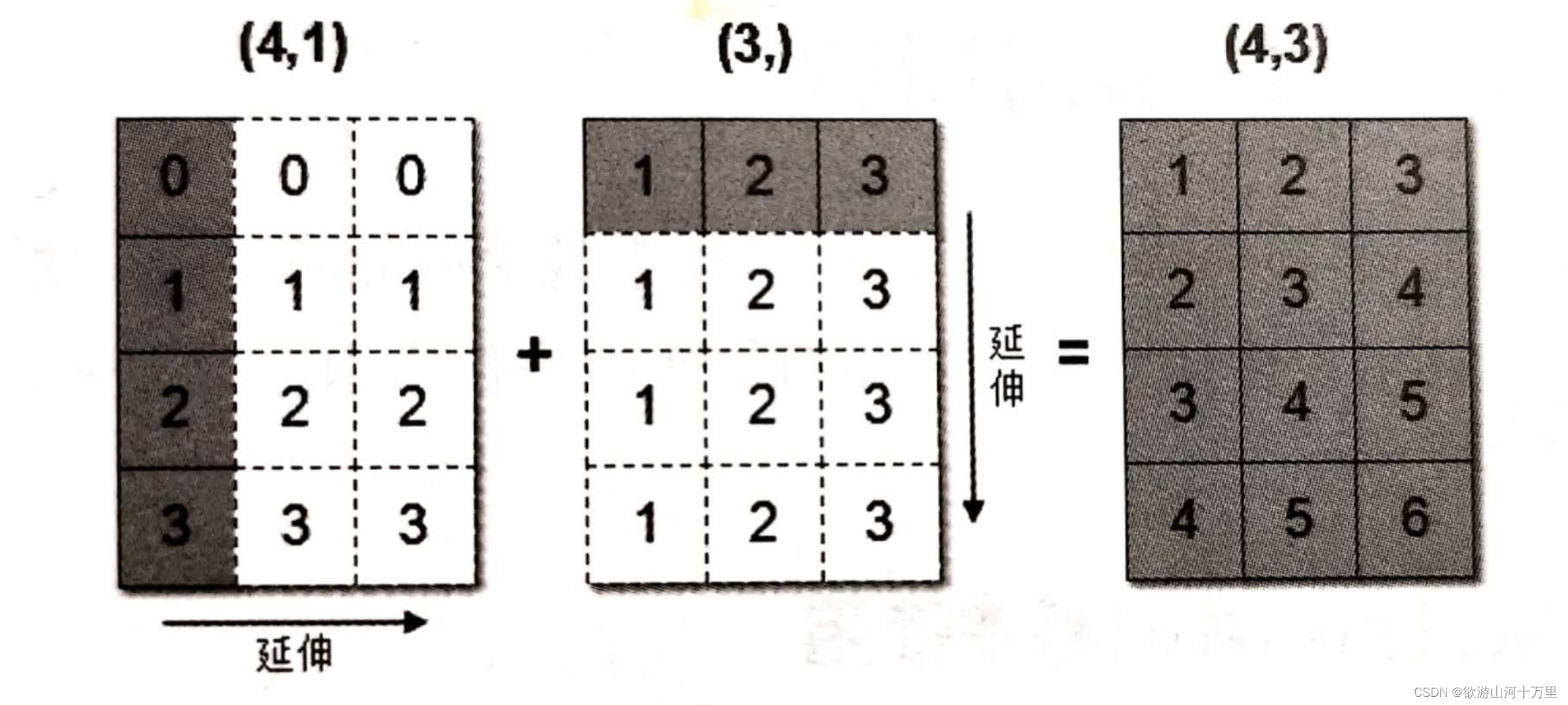
广播机制实现了时两个或两个以上数组的运算,即使这些数组的shape不是完全相同的,只需要满足如下任意一个条件即可。
- 1.数组的某一维度等长。
- 2.其中一个数组的某一维度为1 。
3.2.2矩阵之间的运算
目标
- 知道什么是矩阵和向量
- 知道矩阵的加法,乘法
- 知道矩阵的逆和转置
- 应用np.matmul、np.dot实现矩阵运算
矩阵乘法的api
- np.matmul
- np.dot
>>> a = np.array([[80, 86],
[82, 80],
[85, 78],
[90, 90],
[86, 82],
[82, 90],
[78, 80],
[92, 94]])
>>> b = np.array([[0.7], [0.3]])
>>> np.matmul(a, b)
array([[81.8],
[81.4],
[82.9],
[90. ],
[84.8],
[84.4],
[78.6],
[92.6]])
>>> np.dot(a,b)
array([[81.8],
[81.4],
[82.9],
[90. ],
[84.8],
[84.4],
[78.6],
[92.6]])np.matmul和np.dot的区别:
二者都是矩阵乘法。 np.matmul中禁止矩阵与标量的乘法。 在矢量乘矢量的內积运算中,np.matmul与np.dot没有区别。
4.基本函数介绍
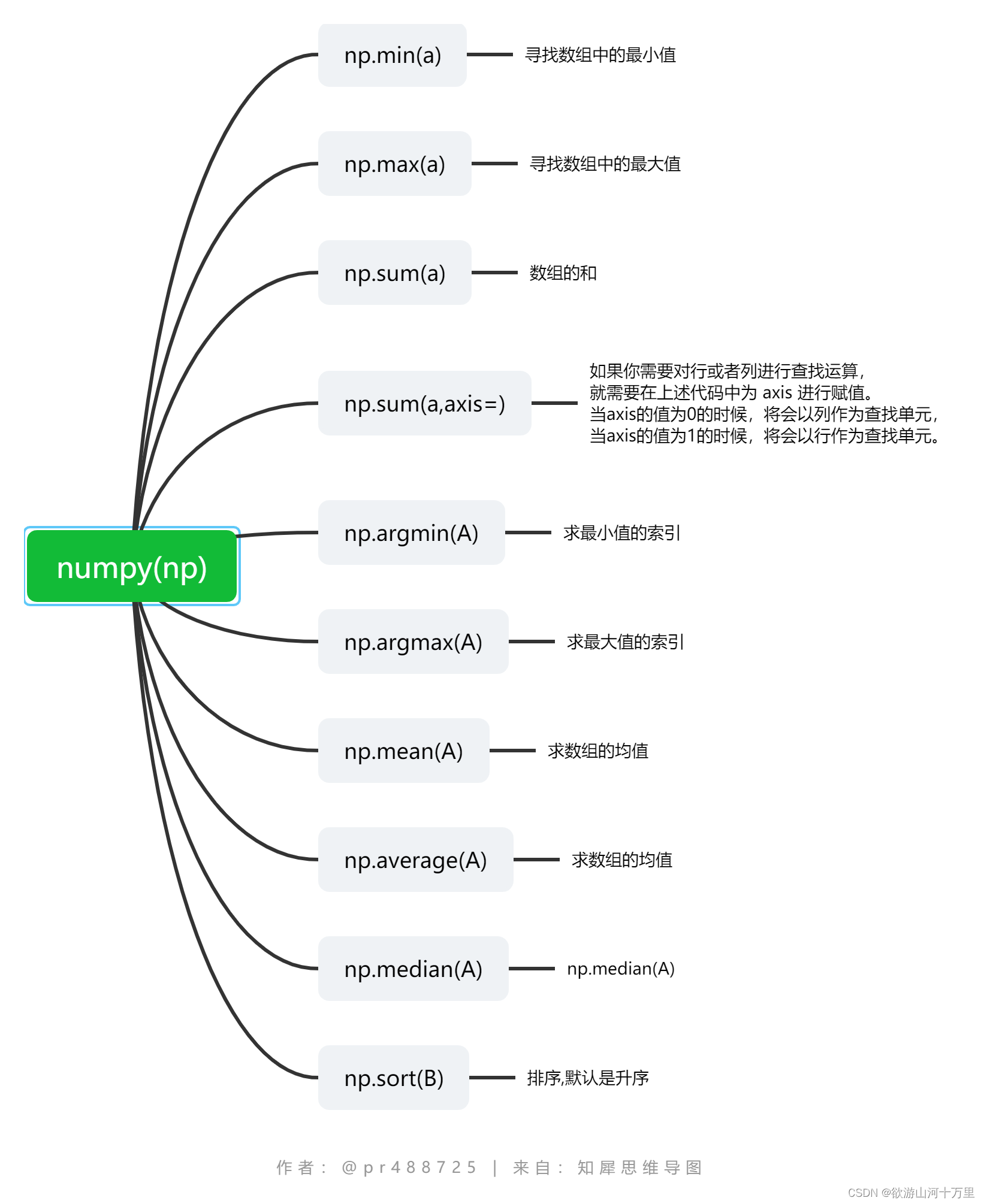
#coding = utf-8
import numpy as np
a = np.array([[1,2,3,4],[5,6,7,8]])
print(np.min(a))#寻找数组中的最小值
print(np.max(a))#寻找数组中的最大值
'''
如果你需要对行或者列进行查找运算,
就需要在上述代码中为 axis 进行赋值。
当axis的值为0的时候,将会以列作为查找单元,
当axis的值为1的时候,将会以行作为查找单元。
'''
print(np.sum(a,axis=0))#[ 6 8 10 12]
print(np.sum(a,axis=1))#[10 26]
A=np.arange(2,14).reshape(3,4)#生成一个3行4列的数组
print(np.argmin(A))#求最小值的索引
print(np.argmax(A))#求最大值的索引
print(np.mean(A))#求数组的均值
print(np.average(A))#求数组的均值
print(np.median(A))#求中位数
print(np.sum(A))#数组的和
print(np.cumsum(A))#累加
B=np.arange(14,2,-1)
print(np.sort(B))#排序,默认是升序
4.1 np.bincount()统计索引出现次数
x = np.array([1, 2, 3, 3, 0, 1, 4])
np.bincount(x)
array([1,2,1,2,1],dtype=int64)统计索引出现次数:索引0出现1次,1出现2次,2出现1次,3出现2次,4出现1次
因此通过bincount计算出索引出现次数如下:
上面怎么得到的?
对于bincount计算吗,bin的数量比x中最大数多1,例如x最大为4,那么bin数量为5(index从0到4),也就会bincount输出的一维数组为5个数,bincount中的数又代表什么?代表的是它的索引值在x中出现的次数!
还是以上述x为例子,当我们设置weights参数时候,结果又是什么?
这里假定:
w = np.array([0.3,0.5,0.7,0.6,0.1,-0.9,1])那么设置这个w权重后,结果为多少?
np.bincount(x,weights=w)array([0.1,-0.6,0.5,1.3,1.])
怎么计算的?
先对x与w抽取出来:
`x ---> [1, 2, 3, 3, 0, 1, 4]`
`w ---> [0.3,0.5,0.7,0.6,0.1,-0.9,1]`
索引 0 出现在x中index=4位置,那么在w中访问index=4的位置即可,w[4]=0.1
索引 1 出现在x中index=0与index=5位置,那么在w中访问`index=0`与`index=5`的位置即可,然后将两这个加和,计算得:`w[0]+w[5]=-0.6`
其余的按照上面的方法即可!
bincount的另外一个参数为minlength,这个参数简单,可以这么理解,当所给的bin数量多于实际从x中得到的bin数量后,后面没有访问到的设置为0即可。
还是上述x为例:
这里我们直接设置minlength=7参数,并输出!
np.bincount(x,weights=w,minlength=7)
与上面相比多了两个0,这两个怎么会多?
上面知道,这个bin数量为5,index从0到4,那么当minlength为7的时候,也就是总长为7,index从0到6,多了后面两位,直接补位为0即可!
5.numpy读取数据
numpy读取数据
CSV:Comma-Separated Value 逗号分隔值文件
显示:表格状态
源文件:换行和逗号分隔行列的格式化文本,每一行的数据表示一条记录
方法:
np.loadtxt(frame,dtype=np.float,delimiter=None,skiprows=0,usecols=None,unpack=False)
frame 文件、字符或产生器,可以是.gz或者bz2压缩文件
dtype 数据类型,可选,CSV的字符串以什么数据类型读入数组中,默认np.float
delimiter 分隔字符串,默认是任何空格,改为逗号
skiprows 跳过前x行,一般跳过第一行表头
usecols 读取指定的列,索引,元祖类型
unpack 如果True,读入属性将分别写入不同数组变量,False读入数据只写入一个数组变量,默认False,就是按照对角线进行转制操作
就是行变成列,列变成行
test.csv中的数据有
1,2,3,4
1,2,3,4
1,2,3,4
1,2,3,4
1,2,3,4
1,2,3,4
1,2,3,4完整代码如下
import numpy as np
file_path="test.csv"
t1 = np.loadtxt(file_path,delimiter=",",dtype="int")
t2 = np.loadtxt(file_path,delimiter=",",dtype="int",unpack=True)
print(t1)
print("===============================")
print(t2)#如果将unpack设置成True形式其实本质上就是数组之间的转秩
#取得行
print(t2[2])#只取一行
print(t2[2:])#取得连续的多行,也就是取得在3行之后的所有行数
print(t2[[0,1,2]])#取得不连续的多行,这里面就是取得0,1,2三行
#取列
print(t2[:,0])#取单列
print(t2[:,2:])#取连续列
print(t2[:,[0,2,3]])#取的多个不连续的列
#取得多行多列的值
print(t2[2,3])#取出一个值
#取出多行和多列,取第3行到第5行,第2列到第4列的结果
print(t2[2:5,1:4])二、Matplotlib介绍
2.1Matplotlib介绍
Matplotlib 是一个Python的2D绘图库。通过 Matplotlib,开发者可以仅需要几行代码,便可以生成绘图,直方图,功率谱,条形图,错误图,散点图等。
通过学习Matplotlib,可让数据可视化,更直观的真实给用户。使数据更加客观、更具有说服力。 Matplotlib是Python的库,又是开发中常用的库。
对于更多知识,也就是图形的绘画可以通过官网进行了解:网址如下:https://matplotlib.org
对于未来我们可以需要画更多的图形,可以参考官方的文档完成:官方地址:https://matplotlib.org/stable/gallery/index
例如下面两个图为数字展示和图形展示:
matplotlib学习的技术重点如下:
1.绘制了折线图(plt.plot)
2.设置了图片的大小和分辨率(plt.figure)
3.实现了图片的保存(plt.savefig)
4.设置了xy轴上的刻度和字符串(xticks)
5.解决了刻度稀疏和密集的问题(xticks)
6.设置了标题,xy轴的label(title,xlabel,ylabel)
7.设置了字体(font_manager、fontProperties)
8.在一个图上绘制多个图形(plt.plot多次即可)
9.为不同的图形添加图例
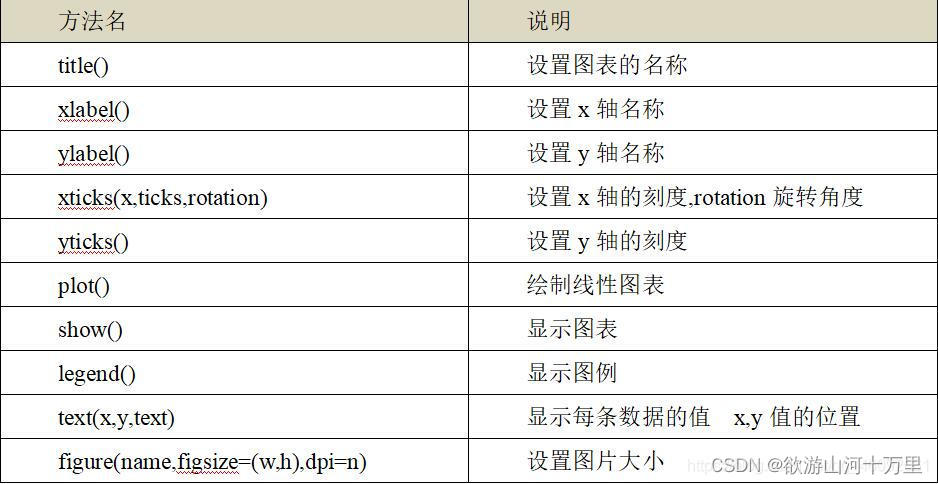
绘制基础:在使用Matplotlib绘制图形时,其中有两个最为常用的场景。一个是画点,一个是画线。pyplot基本方法的使用如下表。
2.2Matplotlib画图步骤
1.创建画布——plt.figure()
plt.figure(figsize=(), dpi=)
figsize:指定图的长宽
dpi:图像的清晰度
返回fig对象2.绘制图像——plt.plot(x,y)以折线图为列
3.显示图像——plt.show()
举例:展现上海一周的天气,比如从星期一到星期日的天气温度如下
import matplotlib.pyplot as plt
# 1.创建画布
plt.figure(figsize=(10, 10), dpi=100)
# 2.绘制折线图
plt.plot([1, 2, 3, 4, 5, 6 ,7], [17,17,18,15,11,11,13])
# 3.显示图像
plt.show()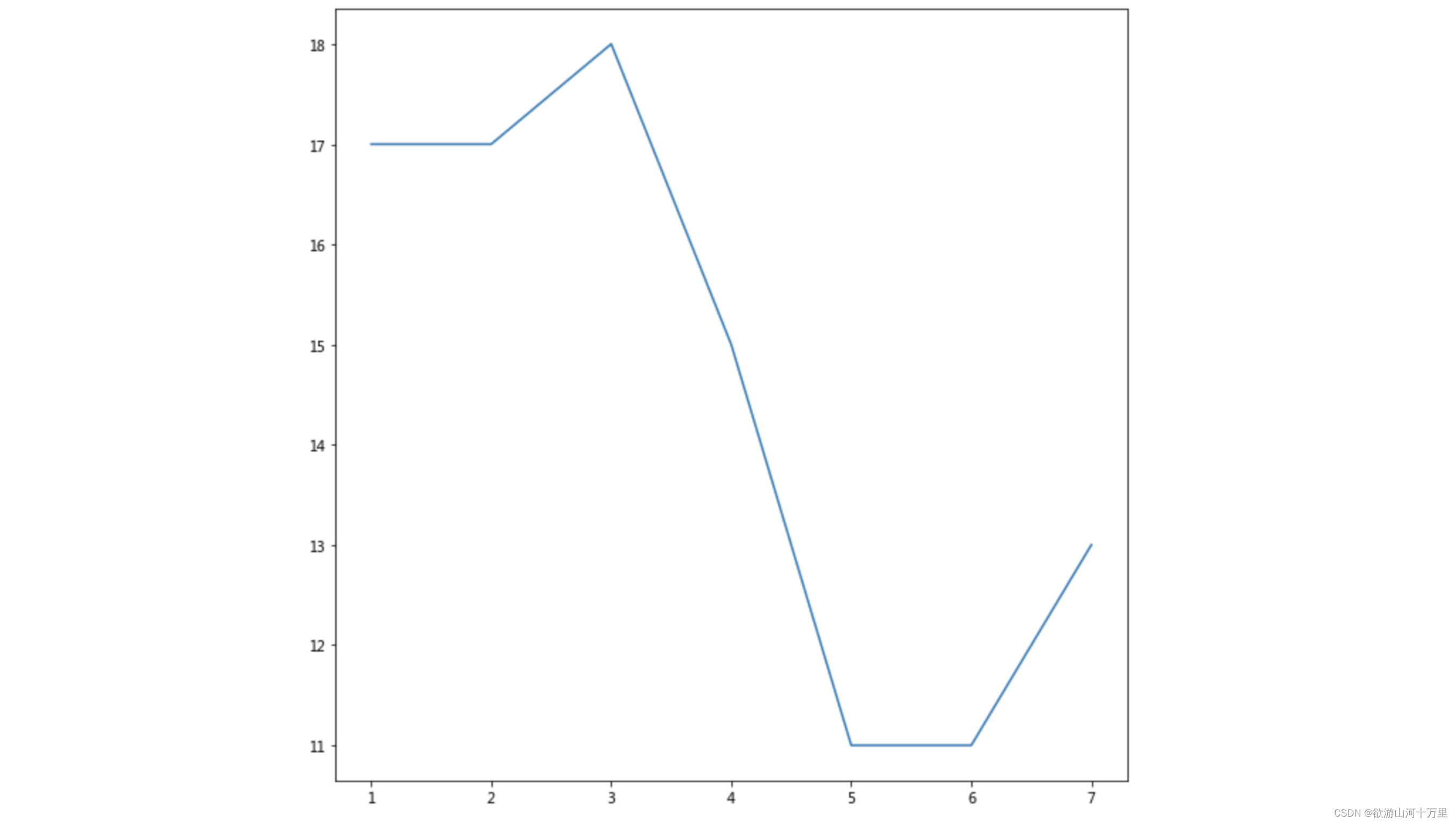 2.3 认识Matplotlib图像结构(了解)
2.3 认识Matplotlib图像结构(了解)
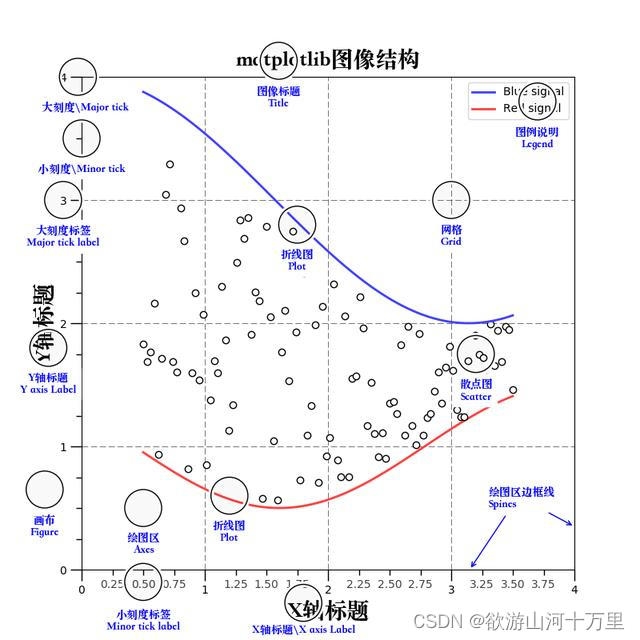
2.4 实现基础绘图功能
2.4.1中文乱码问题
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ['SimHei']
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
加上这一段代码就可以解决中文乱码以及符号无法正常显示等问题
2.4.2添加自定义刻度
-
plt.xticks(x, **kwargs)
x:要显示的刻度值
-
plt.yticks(y, **kwargs)
y:要显示的刻度值
比如如下操作,对图片添加描述信息
plt.xlabel("时间")
plt.ylabel("温度")
plt.title("中午11点0分到12点之间的温度变化图示", fontsize=20)2.4.3图像保存
# 保存图片到指定路径
plt.savefig("test.png")
注意:plt.show()会释放figure资源,如果在显示图像之后保存图片将只能保存空图片。2.4.4 设置图形风格
2.4.5 多个坐标系显示— plt.subplots(面向对象的画图方法)
如果我们想要将上海和北京的天气图显示在同一个图的不同坐标系当中,效果如下:
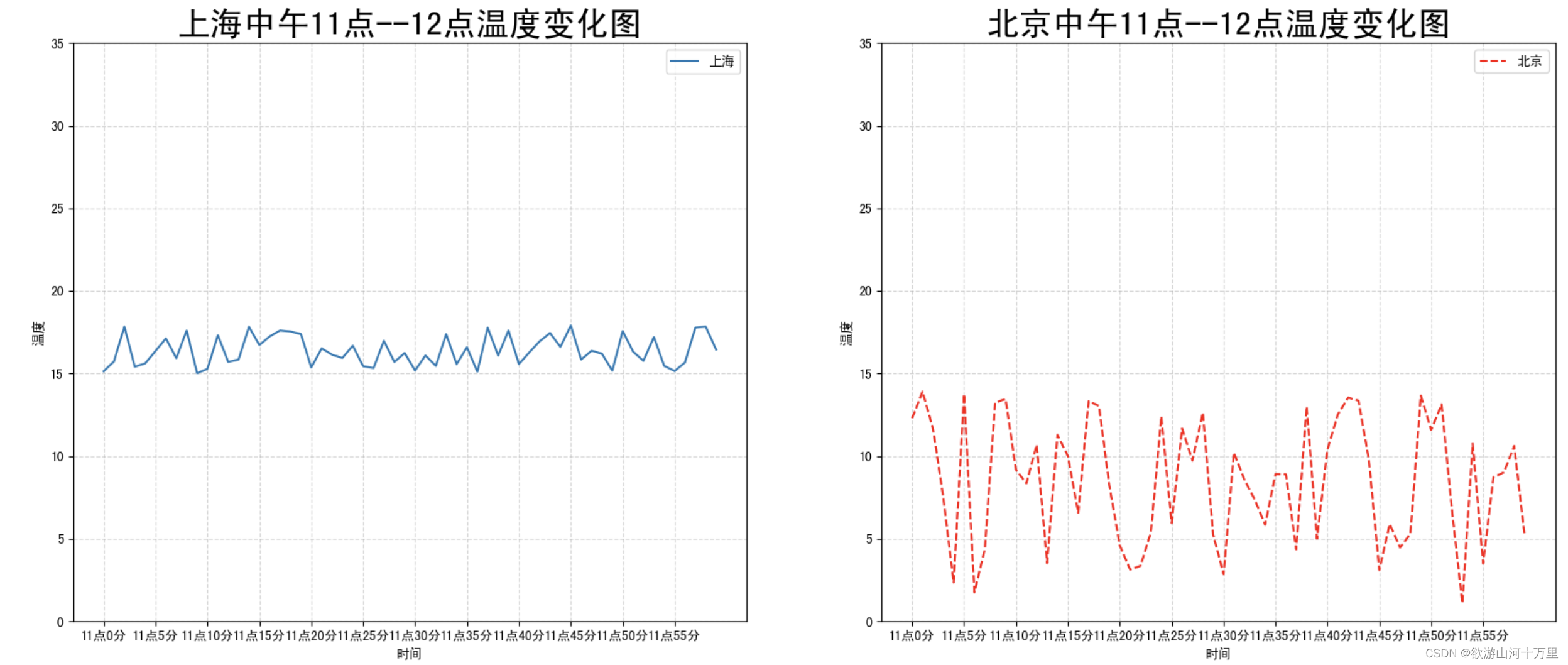
可以通过subplots函数实现(旧的版本中有subplot,使用起来不方便),推荐subplots函数
-
matplotlib.pyplot.subplots(nrows=1, ncols=1, **fig_kw) 创建一个带有多个axes(坐标系/绘图区)的图、
Parameters:
nrows, ncols : 设置有几行几列坐标系
int, optional, default: 1, Number of rows/columns of the subplot grid.
Returns:
fig : 图对象
axes : 返回相应数量的坐标系
设置标题等方法不同:
set_xticks
set_yticks
set_xlabel
set_ylabel完整代码:
#coding = utf-8
from matplotlib import pyplot as plt
import random
#设置中文乱码问题
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ['SimHei']
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 0.准备数据
x = range(60)
y_shanghai = [random.uniform(15, 18) for i in x]
y_beijing = [random.uniform(1, 5) for i in x]
# 1.创建画布
# plt.figure(figsize=(20, 8), dpi=100)
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(20, 8), dpi=100)
# 2.绘制图像
# plt.plot(x, y_shanghai, label="上海")
# plt.plot(x, y_beijing, color="r", linestyle="--", label="北京")
axes[0].plot(x, y_shanghai, label="上海")
axes[1].plot(x, y_beijing, color="r", linestyle="--", label="北京")
# 2.1 添加x,y轴刻度
# 构造x,y轴刻度标签
x_ticks_label = ["11点{}分".format(i) for i in x]
y_ticks = range(40)
# 刻度显示
# plt.xticks(x[::5], x_ticks_label[::5])
# plt.yticks(y_ticks[::5])
axes[0].set_xticks(x[::5])#设置步长是5
axes[0].set_yticks(y_ticks[::5])#设置步长是5
axes[0].set_xticklabels(x_ticks_label[::5])
axes[1].set_xticks(x[::5])
axes[1].set_yticks(y_ticks[::5])
axes[1].set_xticklabels(x_ticks_label[::5])
# 2.2 添加网格显示
# plt.grid(True, linestyle="--", alpha=0.5)
axes[0].grid(True, linestyle="--", alpha=0.5)
axes[1].grid(True, linestyle="--", alpha=0.5)
# 2.3 添加描述信息
# plt.xlabel("时间")
# plt.ylabel("温度")
# plt.title("中午11点--12点某城市温度变化图", fontsize=20)
axes[0].set_xlabel("时间")
axes[0].set_ylabel("温度")
axes[0].set_title("中午11点--12点某城市温度变化图", fontsize=20)
axes[1].set_xlabel("时间")
axes[1].set_ylabel("温度")
axes[1].set_title("中午11点--12点某城市温度变化图", fontsize=20)
# # 2.4 图像保存
plt.savefig("./test.png")
# # 2.5 添加图例
# plt.legend(loc=0)
axes[0].legend(loc="best")#设置显示标签
axes[1].legend(loc="best")#设置显示标签
# 3.图像显示
plt.show()3.常见图形绘制
figure
在任何绘图之前,我们需要一个Figure对象,可以理解成我们需要一张画板才能开始绘图。
import matplotlib.pyplot as plt
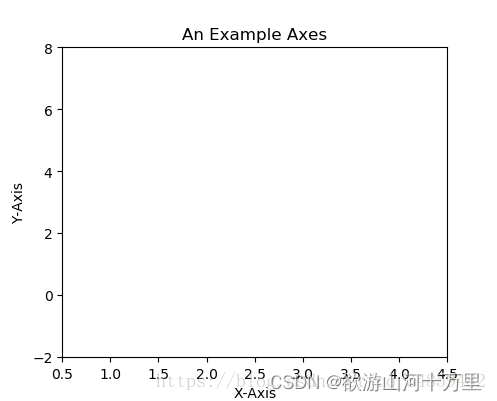
fig = plt.figure()Axes
在拥有Figure对象之后,在作画前我们还需要轴,没有轴的话就没有绘图基准,所以需要添加Axes。也可以理解成为真正可以作画的纸。
fig = plt.figure()
ax = fig.add_subplot(111)
ax.set(xlim=[0.5, 4.5], ylim=[-2, 8], title='An Example Axes',
ylabel='Y-Axis', xlabel='X-Axis')
plt.show()上的代码,在一幅图上添加了一个Axes,然后设置了这个Axes的X轴以及Y轴的取值范围(这些设置并不是强制的,后面会再谈到关于这些设置),效果如下图:
对于上面的fig.add_subplot(111)就是添加Axes的,参数的解释的在画板的第1行第1列的第一个位置生成一个Axes对象来准备作画。也可以通过fig.add_subplot(2, 2, 1)的方式生成Axes,前面两个参数确定了面板的划分,例如 2, 2会将整个面板划分成 2 * 2 的方格,第三个参数取值范围是 [1, 2*2] 表示第几个Axes。如下面的例
fig = plt.figure()
ax1 = fig.add_subplot(221)
ax2 = fig.add_subplot(222)
ax3 = fig.add_subplot(224) 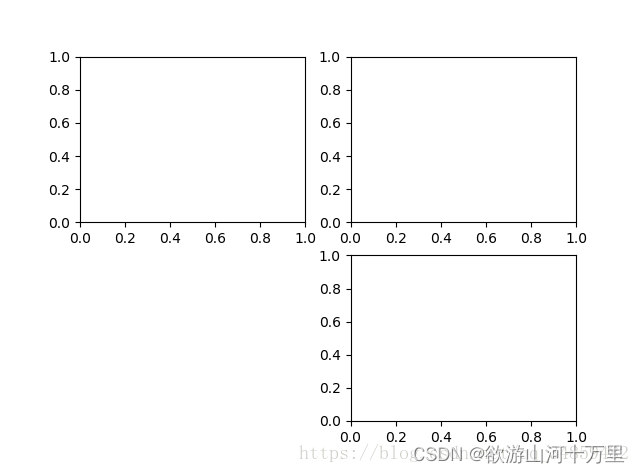
可以发现我们上面添加 Axes 似乎有点弱鸡,所以提供了下面的方式一次性生成所有 Axes:
fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].set(title='Upper Left')
axes[0,1].set(title='Upper Right')
axes[1,0].set(title='Lower Left')
axes[1,1].set(title='Lower Right')fig 还是我们熟悉的画板, axes 成了我们常用二维数组的形式访问,这在循环绘图时,额外好用。
3.1 基本线图
完整代码
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
#设置中文乱码问题
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ['SimHei']
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
fig, axes = plt.subplots(nrows=2, ncols=2)
axes[0,0].set(title='Upper Left')
axes[0,1].set(title='Upper Right')
axes[1,0].set(title='Lower Left')
axes[1,1].set(title='Lower Right')
x = np.linspace(0, np.pi)#x的范围0-pi
y_sin = np.sin(x)
y_cos = np.cos(x)
axes[0,0].plot(x, y_sin)
axes[0,1].plot(x, y_sin,"go--",linewidth=2, markersize=12)
axes[1,0].plot(x, y_cos, color='red',linestyle='--')
'''
linestyle代表的是线的类型
'''
plt.show()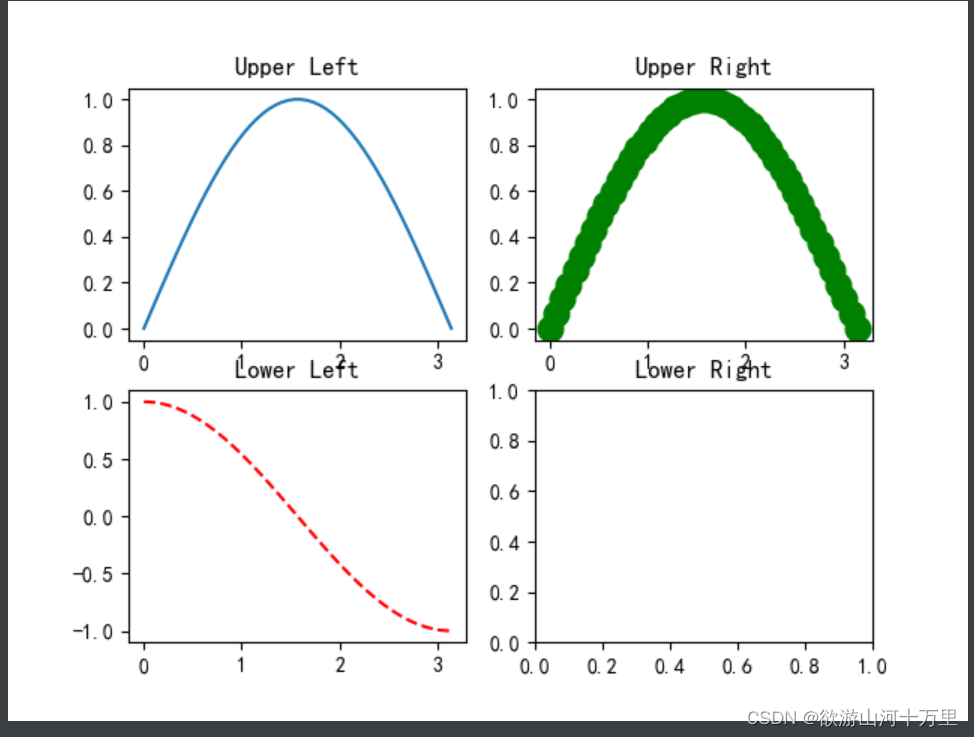
绘制正弦曲线和余弦曲线
使用plt函数绘制任何曲线的第一步都是生成若干个坐标点(x,y),理论上坐标点是越多越好。本例取0到10之间100个等差数作为x的坐标,然后将这100个x坐标值一起传入Numpy的sin和cos函数,就会得到100个y坐标值,最后就可以使用plot函数绘制正弦曲线和余弦曲线。
import matplotlib.pyplot as plt
import numpy as np
#生成x的坐标(0-10的100个等差数列)
x=np.linspace(0,10,100)
sin_y=np.sin(x)
#绘制正弦曲线
plt.plot(x,sin_y)
#绘制余弦曲线
cos_y=np.cos(x)
plt.plot(x,cos_y)
plt.show()

3.2绘制散点图
散点图:用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式。
特点:判断变量之间是否存在数量关联趋势,展示离群点(分布规律)
api:plt.scatter(x, y)
使用scatter函数可以绘制随机点,该函数需要接收x坐标和y坐标的序列。
sin函数的散点图
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
x=np.linspace(0,10,100)#生成0到10中100个等差数
plt.scatter(x,np.sin(x),color='g')
plt.xlabel("x轴的标签")
plt.ylabel("y轴的标签")
plt.show()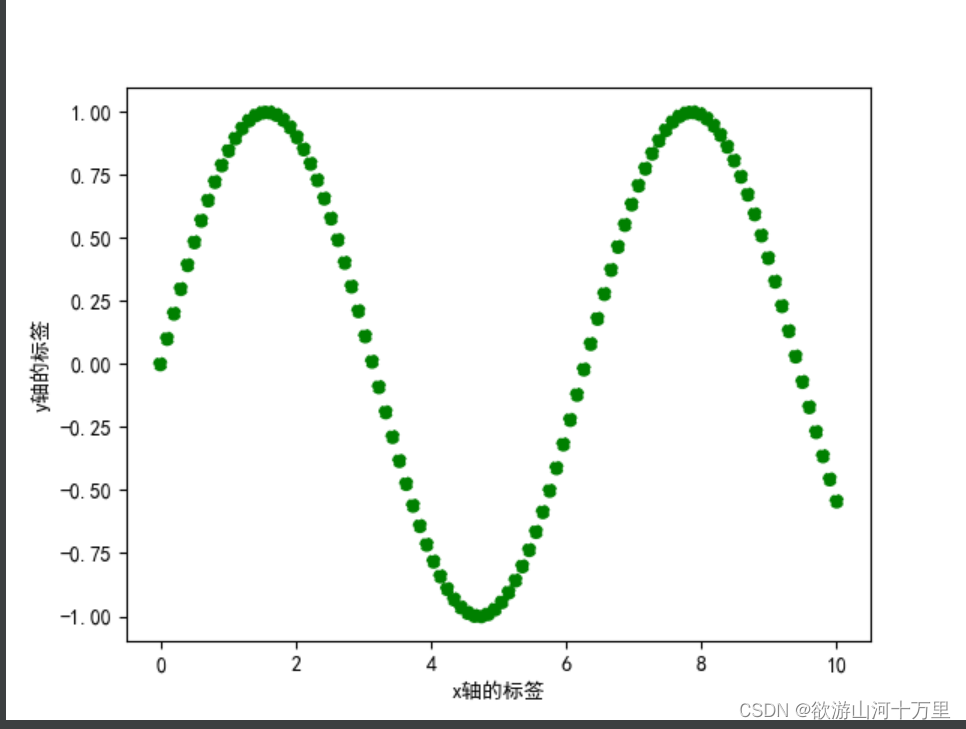
使用scatter画10种大小100种颜色的散点图
完整代码:
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
# 画10种大小, 100种颜色的散点图
np.random.seed(0)
x = np.random.rand(100)
y = np.random.rand(100)
colors = np.random.rand(100)
size = np.random.rand(10)*1000
plt.scatter(x,y,c=colors,sizes=size,alpha=0.7)
plt.xlabel("x轴的标签")
plt.ylabel("y轴的标签")
plt.show()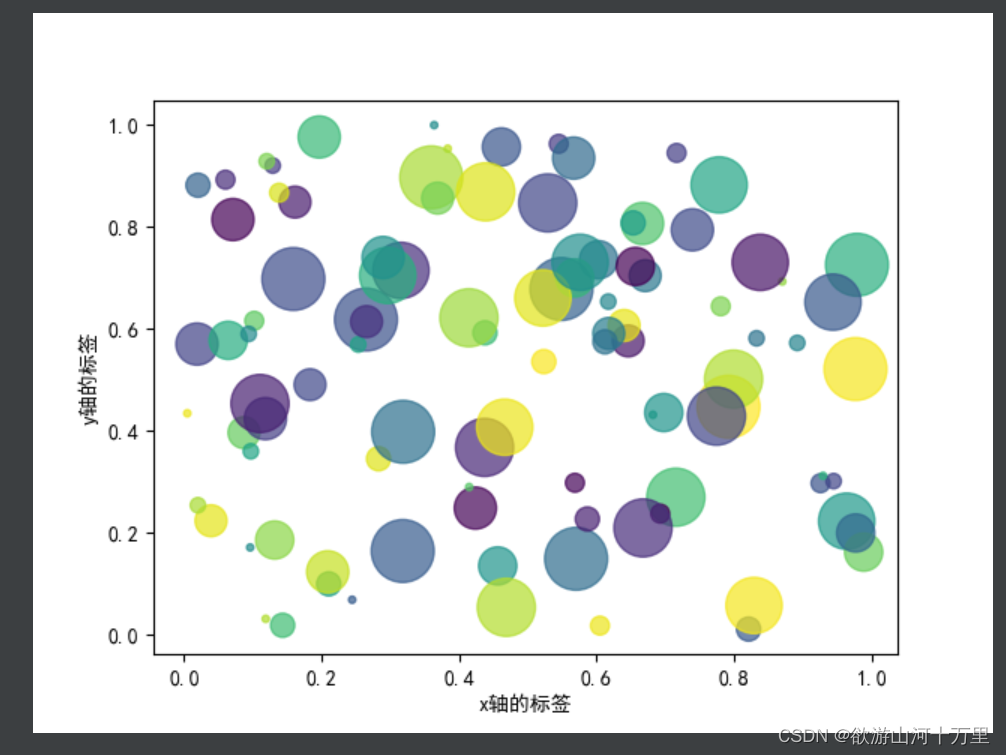
散点图绘制举例:
需求:探究房屋面积和房屋价格的关系
import matplotlib.pyplot as plt
from pylab import mpl
# 设置显示中文字体
mpl.rcParams["font.sans-serif"] = ['SimHei']
# 设置正常显示符号
mpl.rcParams["axes.unicode_minus"] = False
# 0.准备数据
x = [225.98, 247.07, 253.14, 457.85, 241.58, 301.01, 20.67, 288.64,
163.56, 120.06, 207.83, 342.75, 147.9 , 53.06, 224.72, 29.51, 21.61, 483.21, 245.25, 399.25, 343.35]
y = [196.63, 203.88, 210.75, 372.74, 202.41, 247.61, 24.9 , 239.34,
140.32, 104.15, 176.84, 288.23, 128.79, 49.64, 191.74, 33.1 , 30.74, 400.02, 205.35, 330.64, 283.45]
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制图像
plt.scatter(x, y)
# 设置x轴刻度
plt.xticks(range(500)[::50])
# 添加网格
plt.grid()
# 3. 图像显示
plt.show()
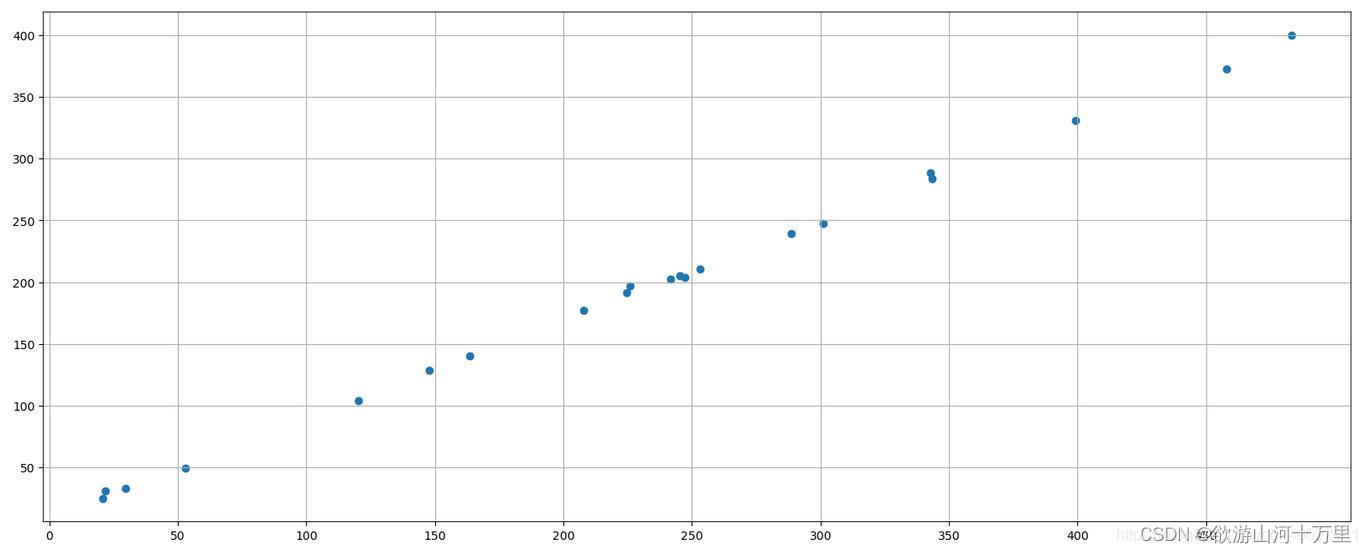
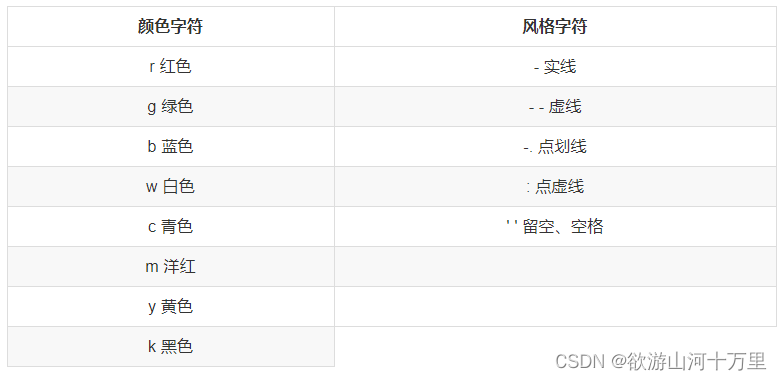
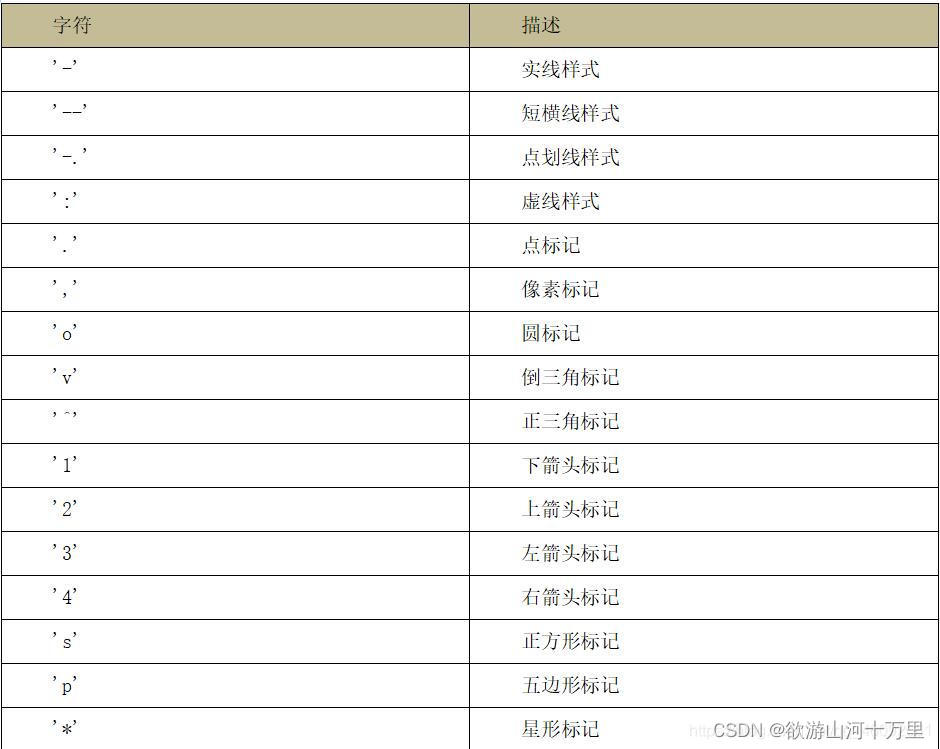
作为线性图的替代,可以通过向 plot() 函数添加格式字符串来显示离散值。 可以使用以下格式化字符。
以下是颜色的缩写:
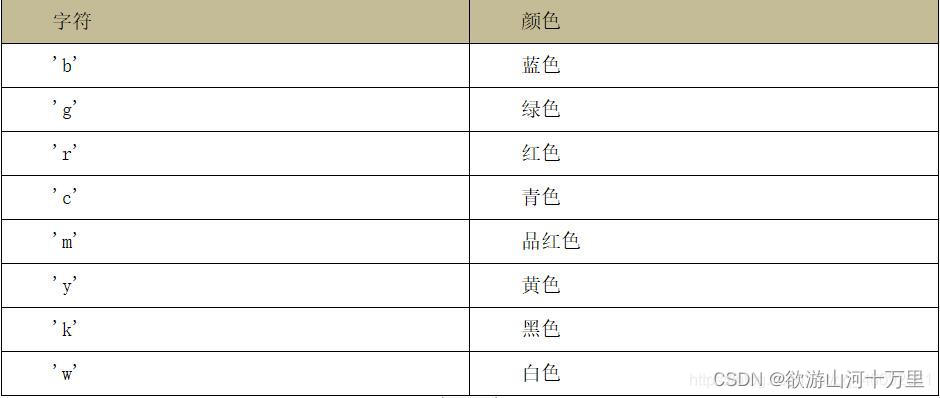
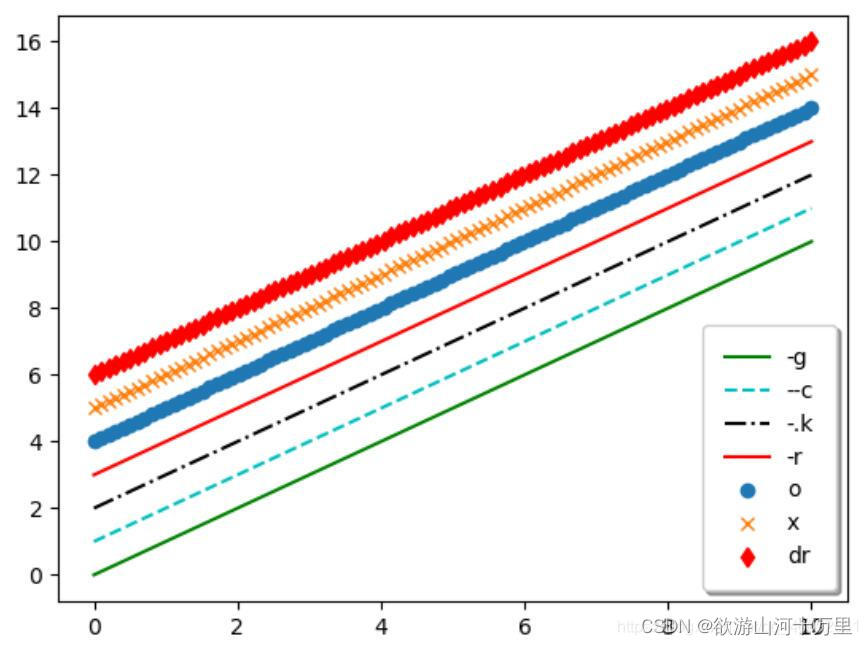
不同种类不同颜色的线并添加图例
#不同种类不同颜色的线并添加图例
x=np.linspace(0,10,100)
plt.plot(x,x+0,'-g',label='-g') #实线 绿色
plt.plot(x,x+1,'--c',label='--c') #虚线 浅蓝色
plt.plot(x,x+2,'-.k',label='-.k') #点划线 黑色
plt.plot(x,x+3,'-r',label='-r') #实线 红色
plt.plot(x,x+4,'o',label='o') #点 默认是蓝色
plt.plot(x,x+5,'x',label='x') #叉叉 默认是蓝色
plt.plot(x,x+6,'dr',label='dr') #砖石 红色
#添加图例右下角lower right 左上角upper left 边框 透明度 阴影 边框宽度
plt.legend(loc='lower right',fancybox=True,framealpha=1,shadow=True,borderpad=1)
plt.show()
3.3绘制柱状图
柱状图:排列在工作表的列或行中的数据可以绘制到柱状图中。
特点:绘制连离散的数据,能够一眼看出各个数据的大小,比较数据之间的差别。(统计/对比)
api:plt.bar(x, width, align='center', **kwargs)
Parameters:
x : 需要传递的数据
width : 柱状图的宽度
align : 每个柱状图的位置对齐方式
{‘center’, ‘edge’}, optional, default: ‘center’
**kwargs :
color:选择柱状图的颜色
使用bar函数可以绘制柱状图。柱状图需要水平的x坐标值,以及每一个x坐标值对应的y坐标值,从而形成柱状的图。柱状图主要用来纵向对比和横向对比的。例如,根据年份对销售收据进行纵向对比,x坐标值就表示年份,y坐标值表示销售数据。
import matplotlib.pyplot as plt
import numpy as np
x=[1980,1985,1990,1995]
x_labels=['1980年','1985年','1990年','1995年']
y=[1000,3000,4000,5000]
plt.bar(x,y,width=3)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.xticks(x,x_labels)
plt.xlabel('年份')
plt.ylabel('销量')
plt.title('根据年份销量对比图')
plt.show()
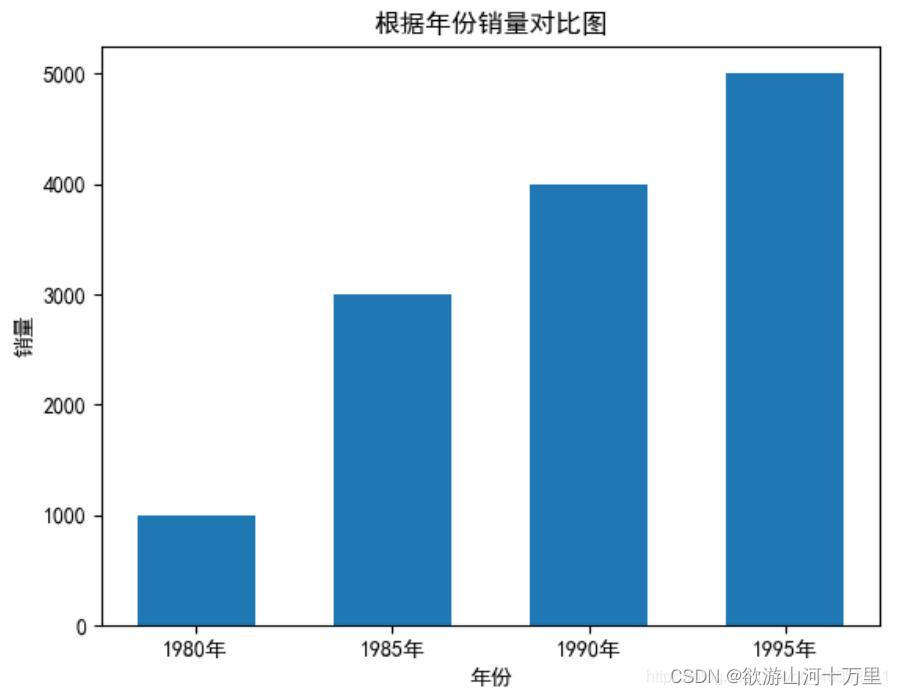
需要注意的是bar函数的宽度并不是像素宽度。bar函数会根据二维坐标系的尺寸,以及x坐标值的多少,自动确定每一个柱的宽度,而width指定的宽度就是这个标准柱宽度的倍数。该参数值可以是浮点数,如0.5,表示柱的宽度是标准宽度的0.5倍。
使用bar和barh绘制柱状图
import matplotlib.pyplot as plt
import numpy as np
np.random.seed(0)
x=np.arange(5)
y=np.random.randint(-5,5,5)
print(x,y)
# 将画布分隔成一行两列
plt.subplot(1,2,1)
#在第一列中画图
v_bar=plt.bar(x,y)
#在第一列的画布中 0位置画一条蓝线
plt.axhline(0,color='blue',linewidth=2)
plt.subplot(1,2,2)
#barh将y和x轴对换 竖着方向为x轴
h_bar=plt.barh(x,y,color='red')
#在第二列的画布中0位置处画红色的线
plt.axvline(0,color='red',linewidth=2)
plt.show()
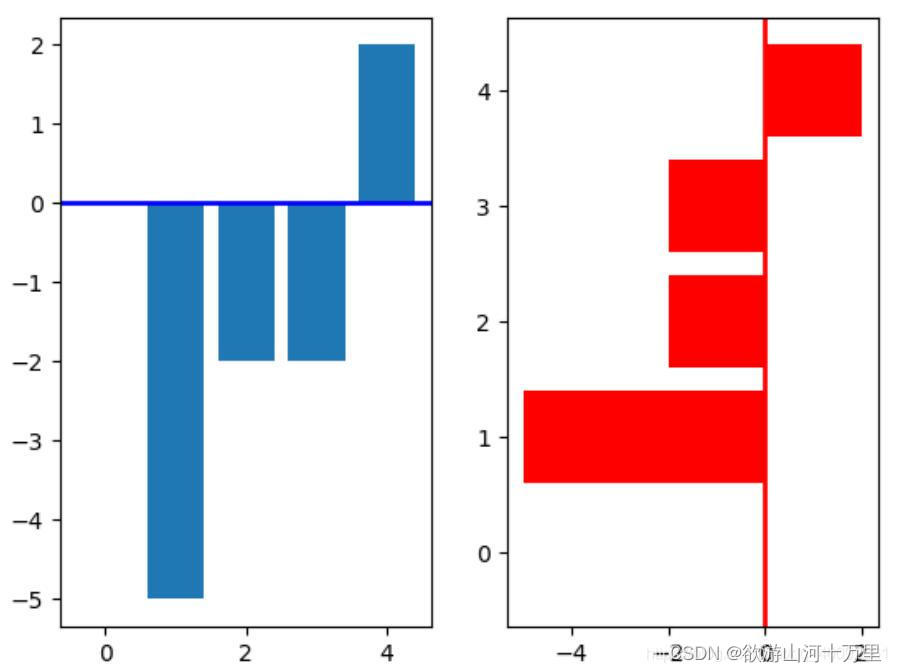
柱状图使用实例
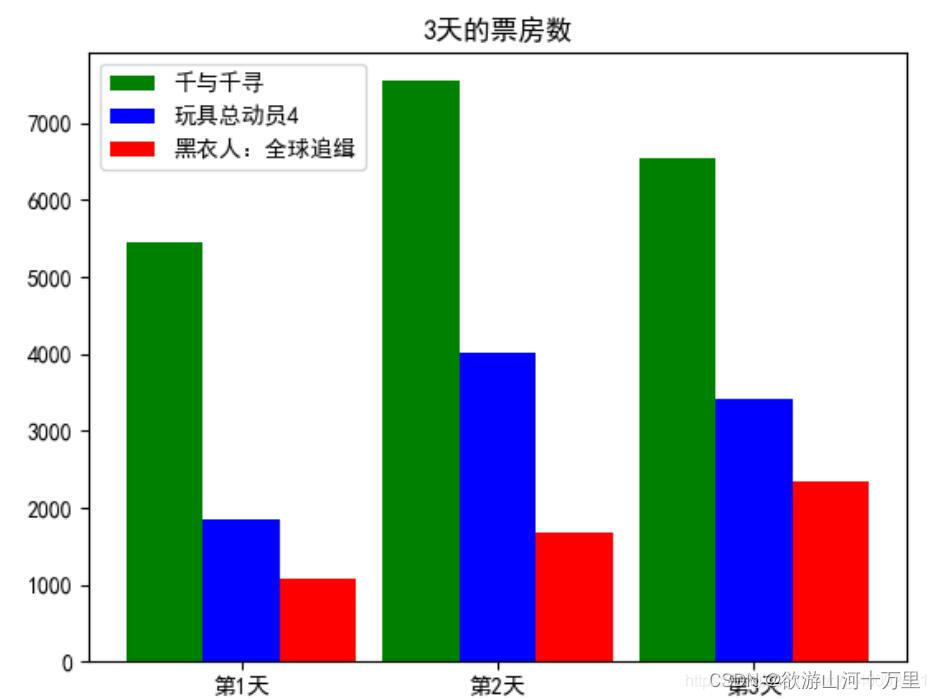
电影票房柱状图绘制1:
import matplotlib.pyplot as plt
import numpy as np
#三天中三部电影的票房变化
real_names=['千与千寻','玩具总动员4','黑衣人:全球追缉']
real_num1=[5453,7548,6543]
real_num2=[1840,4013,3421]
real_num3=[1080,1673,2342]
#生成x 第1天 第2天 第3天
x=np.arange(len(real_names))
x_label=['第{}天'.format(i+1) for i in range(len(real_names))]
#绘制柱状图
#设置柱的宽度
width=0.3
plt.bar(x,real_num1,color='g',width=width,label=real_names[0])
plt.bar([i+width for i in x],real_num2,color='b',width=width,label=real_names[1])
plt.bar([i+2*width for i in x],real_num3,color='r',width=width,label=real_names[2])
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
#修改x坐标
plt.xticks([i+width for i in x],x_label)
#添加图例
plt.legend()
#添加标题
plt.title('3天的票房数')
plt.show()
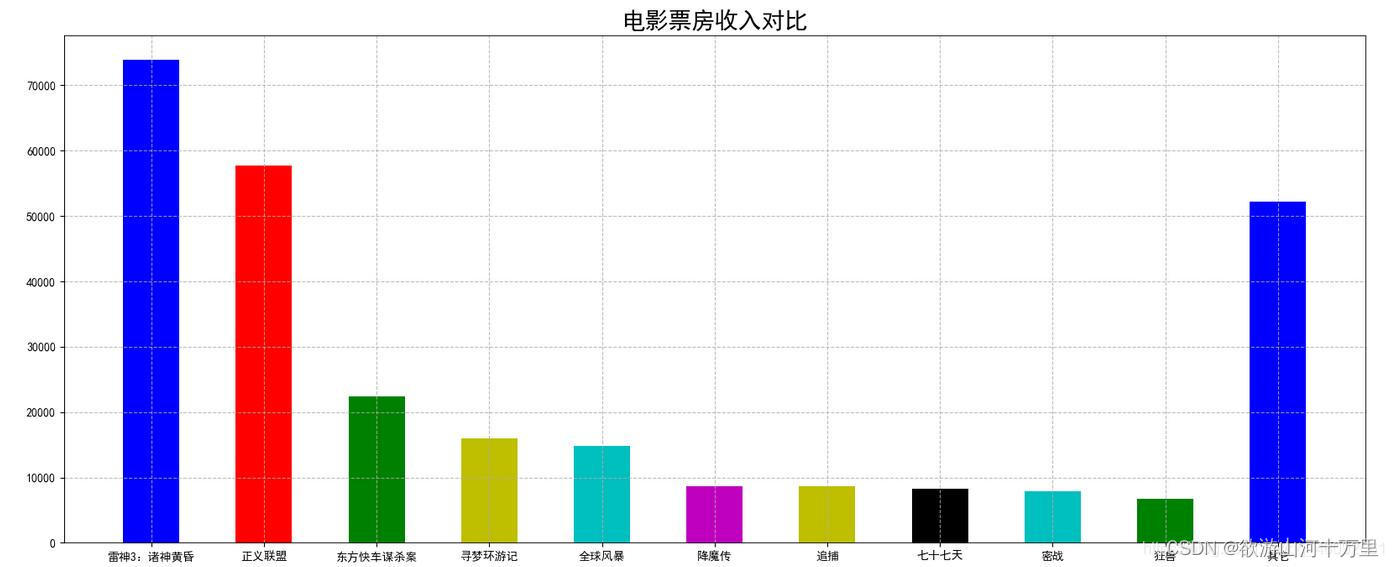
电影票房柱状图绘制2:
需求:对比每部电影的票房收入.
电影数据如下图所示:
# 0.准备数据
# 电影名字
movie_name = ['雷神3:诸神黄昏','正义联盟','东方快车谋杀案','寻梦环游记','全球风暴','降魔传','追捕','七十七天','密战','狂兽','其它']
# 横坐标
x = range(len(movie_name))
# 票房数据
y = [73853,57767,22354,15969,14839,8725,8716,8318,7916,6764,52222]
# 1. 创建画布
plt.figure(figsize=(20, 8), dpi=100)
# 2. 绘制柱状图
plt.bar(x, y, width=0.5, color=['b','r','g','y','c','m','y','k','c','g','b'])
# 2.1 修改x轴刻度显示
plt.xticks(x, movie_name)
# 2.2 添加网格
plt.grid(linestyle='--', alpha=0.8)
# 2.3 添加标题
plt.title('电影票房收入对比', fontsize=20)
# 3.图像显示
plt.show()
3.4绘制饼状图
饼图:用于表示不同分类的占比情况,通过弧度大小来对比各种分类。
特点:分类数据的占比情况(占比)
api:plt.pie(x, labels=,autopct=,colors)
Parameters:
x:数量,自动算百分比
labels:每部分名称
autopct:占比显示指定%1.2f%%
colors:每部分颜色
pie函数可以绘制饼状图,饼图主要是用来呈现比例的。只要传入比例数据即可
绘制饼状图
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
#准备男、女的人数及比例
man=71351
woman=68187
man_perc=man/(woman+man)
woman_perc=woman/(woman+man)
#添加名称
labels=['男','女']
#添加颜色
colors=['blue','red']
#绘制饼状图 pie
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
# labels 名称 colors:颜色,explode=分裂 autopct显示百分比
paches,texts,autotexts=plt.pie([man_perc,woman_perc],labels=labels,colors=colors,explode=(0,0.05),autopct='%0.1f%%')
#设置饼状图中的字体颜色
for text in autotexts:
text.set_color('white')
#设置字体大小
for text in texts+autotexts:
text.set_fontsize(20)
plt.show()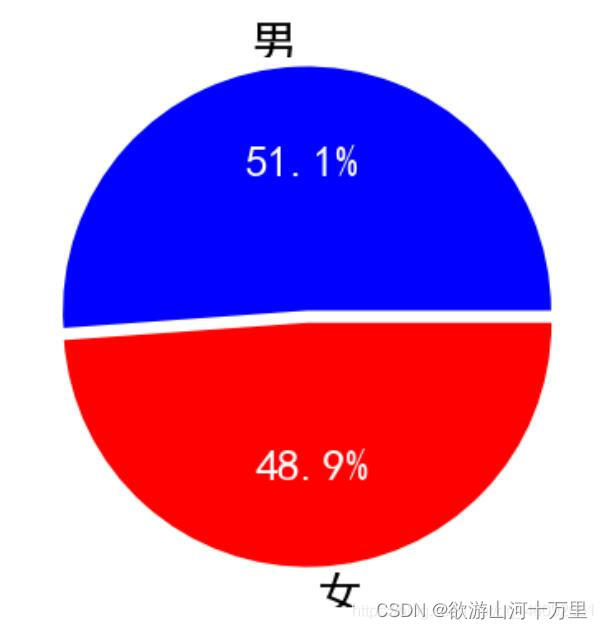
3.5绘制直方图
直方图:由一系列高度不等的纵向条纹或线段表示数据分布的情况。 一般用横轴表示数据范围,纵轴表示分布情况。
特点:绘制连续性的数据展示一组或者多组数据的分布状况(统计)
api:matplotlib.pyplot.hist(x, bins=None)
Parameters:
x : 需要传递的数据
bins : 组距
直方图与柱状图的风格类似,都是由若干个柱组成,但直方图和柱状图的含义却有很大的差异。直方图是用来观察分布状态的,而柱状图是用来看每一个X坐标对应的Y的值的。也就是说,直方图关注的是分布,并不关心具体的某个值,而柱状图关心的是具体的某个值。使用hist函数绘制直方图。
使用randn函数生成1000个正态分布的随机数,使用hist函数绘制这1000个随机数的分布状态
#coding = utf-8
from matplotlib import pyplot as plt
import random
import numpy as np
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
#频次直方图,均匀分布
#正太分布
x=np.random.randn(1000)
#画正太分布图
# plt.hist(x)
plt.hist(x,bins=10) #装箱的操作,将10个柱装到一起及修改柱的宽度
#bins的值越大所绘制出来的柱状图就越细
plt.show() 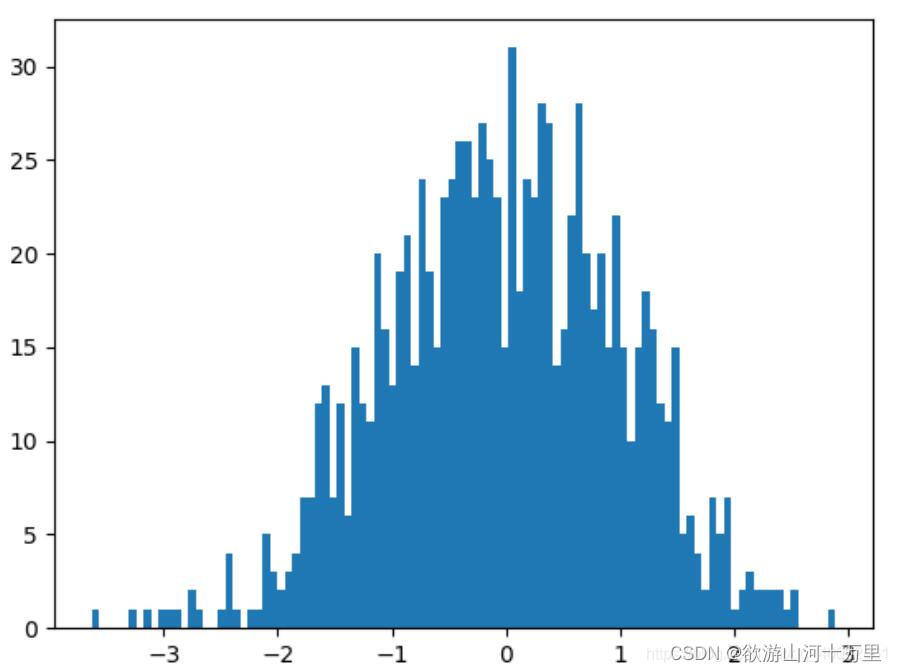
使用normal函数生成1000个正态分布的随机数,使用hist函数绘制这100个随机数的分布状态
import numpy as np
import matplotlib.pyplot as plt
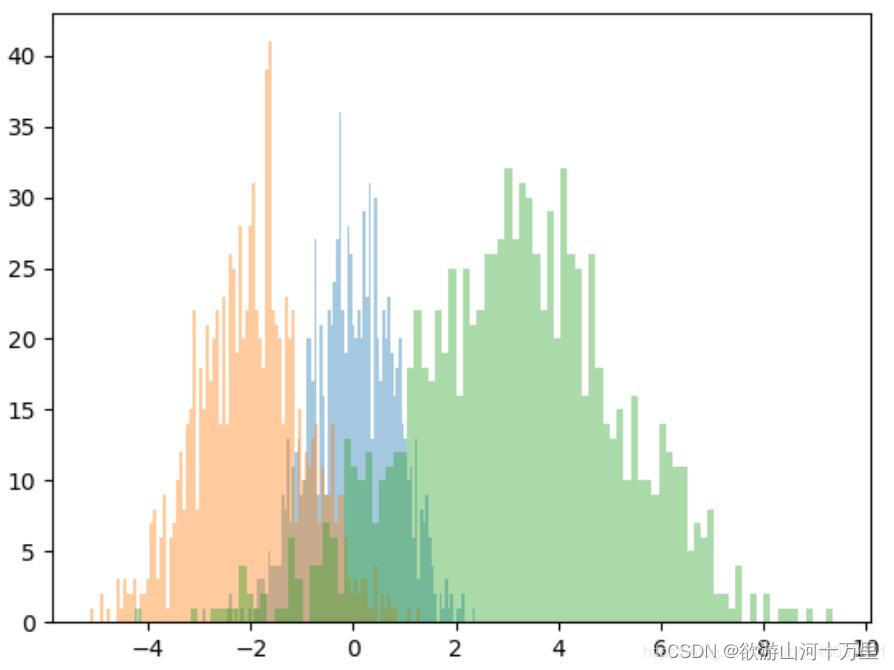
#几个直方图画到一个画布中,第一个参数期望 第二个均值
x1=np.random.normal(0,0.8,1000)
x2=np.random.normal(-2,1,1000)
x3=np.random.normal(3,2,1000)
#参数分别是bins:装箱,alpha:透明度
kwargs=dict(bins=100,alpha=0.4) # 字典,作为传参使用
plt.hist(x1,**kwargs)
plt.hist(x2,**kwargs)
plt.hist(x3,**kwargs)
plt.show()
3.6绘制等高线图
使用pyplot绘制等高线图
#coding = utf-8
from matplotlib import pyplot as plt
import numpy as np
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
x=np.linspace(-10,10,100)
y=np.linspace(-10,10,100)
#计算x和y的相交点a
X,Y=np.meshgrid(x,y)
# 计算Z的坐标
Z=np.sqrt(X**2+Y**2)
plt.contourf(X,Y,Z)
plt.contour(X,Y,Z)
plt.show()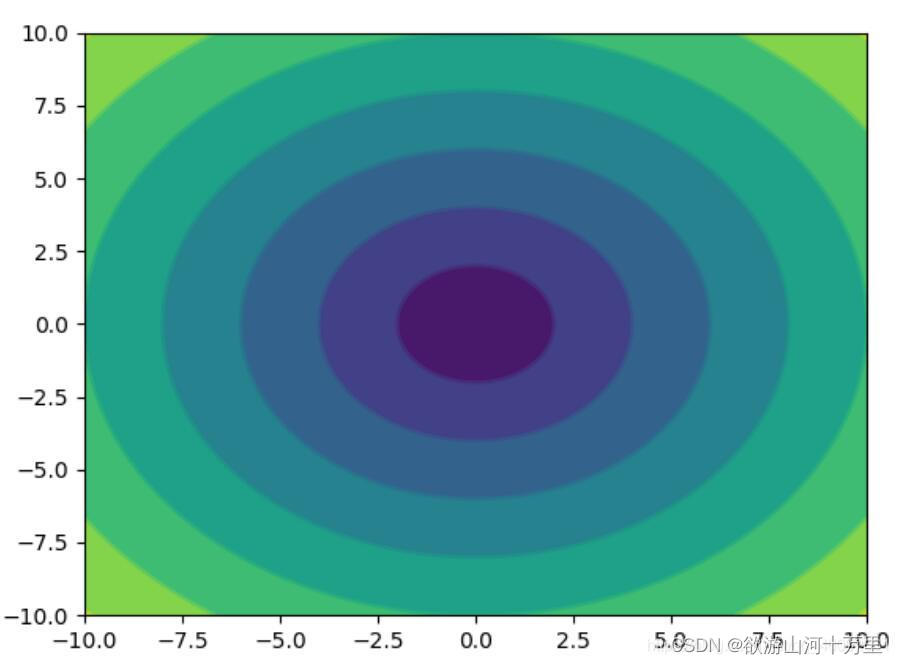
3.7绘制三维图
使用pyplot包和Matplotlib绘制三维图。
#导入3D包
from mpl_toolkits.mplot3d import Axes3D
from pylab import mpl#设置中文乱码问题
mpl.rcParams["font.sans-serif"] = ['SimHei']# 设置显示中文字体
mpl.rcParams["axes.unicode_minus"] = False# 设置正常显示符号
#创建X、Y、Z坐标
X=[1,1,2,2]
Y=[3,4,4,3]
Z=[1,100,1,1]
# 创建画布
fig = plt.figure()
# 创建了一个Axes3D的子图放到figure画布里面
ax = Axes3D(fig)
ax.plot_trisurf(X, Y, Z)
plt.show()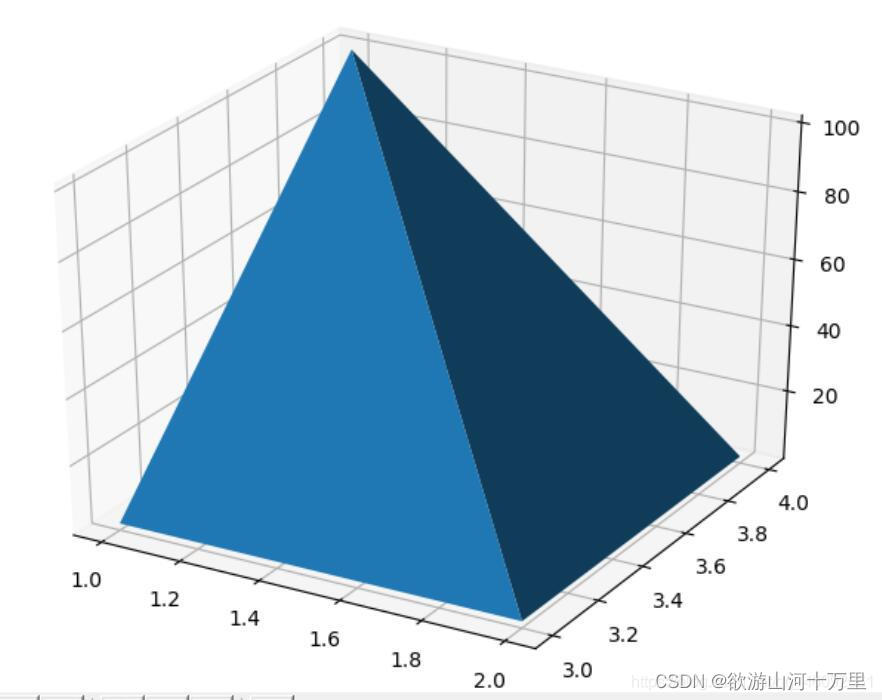
4.案列介绍
eg1:假设一天中每间隔两个小时的气温分别是
[15,13,14.5,17,20,25,26,25,27,22,18,15]请绘制图形
# coding = utf-8
from matplotlib import pyplot as plt
fig = plt.figure(figsize=(20,8),dpi=80)
# figsize=(20,8)代表着设置图像的大小是长20,宽80,dpi设置是每个英寸上的像素是80
# 在图像模糊的时候可以传入dpi参数,让图片更加清晰
x = range(2,26,2)
y = [15,13,14.5,17,20,25,26,26,27,22,18,15]
plt.plot(x,y) #绘图
plt.show()
三、Pandas介绍
参考文献
本文的博文在记录的时候参考了网上部分网友的博文,在此表示感谢。
Python可视化库matplotlib(超详细)_ZSYL的博客-CSDN博客_matplotlib python

















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











