






决策树如何分裂?
信息增益公式ID3:
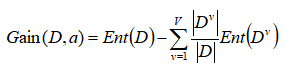
信息增益率公式c4.5:
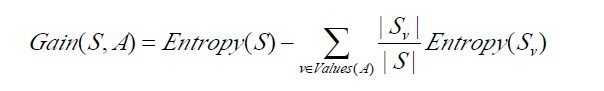
基尼系数:
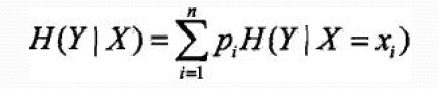
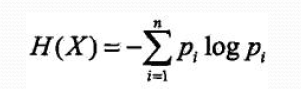
决策树过拟合?
控制模型复杂度
1.控制树的深度
2.把不重要的特征进行剪枝操作
3.正则化方法
集成算法是将多个弱分类器集成起来的强分类器
弱分类器可以理解为欠拟合的分类器,弱指的是对于全部数据的泛化能力弱,而对于某些数据比较准确。
bagging特点:
1.基于数据随机重抽样的分类器构建
2.可以并行
3.弱分类器之间几乎相互无关
典型 RF
booosting特点:
1.只能串行
2.弱分类器之间强相关
3.结果是所有分类器的加权求和
boosting是基于上一个分类器分类错误的数据进行模型训练校正。
典型 adaboost xgboost
bagging减少variance,而boosting是减少bias
Bagging对样本重采样,对每一重采样得到的子样本集训练一个模型,最后取平均。由于子样本集的相似性以及使用的是同种模型,因此各模型有近似相等的bias和variance(事实上,各模型的分布也近似相同,但不独立)。另一方面,若各子模型独立,则有,此时可以显著降低variance。若各子模型完全相同,则此时不会降低variance。bagging方法得到的各子模型是有一定相关性的,属于上面两个极端状况的中间态,因此可以一定程度降低variance。
boosting是在sequential地最小化损失函数,其bias自然逐步下降。但由于是采取这种sequential、adaptive的策略,各子模型之间是强相关的,于是子模型之和并不能显著降低variance。所以说boosting主要还是靠降低bias来提升预测精度。














 2572
2572
04-21
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









