






optimizer
机器学习几乎所有算法都要利用损失函数loss function来检验算法模型的优劣,同时利用损失函数来提升算法模型的。
这个提升的过程就是优化的过程
关于深度学习优化器 optimizer 的选择,你需要了解这些
SGD 和 BGD 和 Mini-BGD
SGD 随机梯度下降
算法在每读入一个数据都会立刻计算loss function的梯度来update参数。假设loss function为w
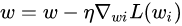
所以SGD的batchsize为1,收敛的速度快,但是不容易跳出局部最优解
BGD(batch gradient descent):批量梯度下降
算法在读取整个数据集后才去计算损失函数的梯度,batchsize为n
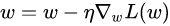
数据处理量加大,梯度下降较慢;训练过程中占内存
Mini - BGD(mini-batch gradient descent):批量梯度下降
选择小批量来进行梯度下降,这是一种折中的方法,采用训练子集的方法来计算loss
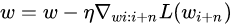
上面的方法都存在一个问题,就是update更新的方向完全依赖于计算出来的梯度.很容易陷入局部最优的马鞍点.能不能改变其走向,又保证原来的梯度方向.就像向量变换一样,我们模拟物理中物体流动的动量概念(惯性).
Momentum
Momentum参考了物理中动量的概念,前几次的梯度也会参与到当前的计算中,但是前几轮的梯度叠加在当前计算中会有一定的衰减。
若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度,若当前梯度与历史梯方向不一致,则梯度会衰减。一种形象的解释是:我们把一个球推下山,球在下坡时积聚动量,在途中变得越来越快,若球的方向发生变化,则动量会衰减。
提高收敛速度,增加稳定性而且还有摆脱局部最优的能力

第一个式子有两项。第一项是上一次迭代的梯度,乘上一个被称为「Momentum 系数」的值,可以理解为取上次梯度的比例。
我们设 v 的初始为 0,动量系数为 0.9,那么迭代过程如下:
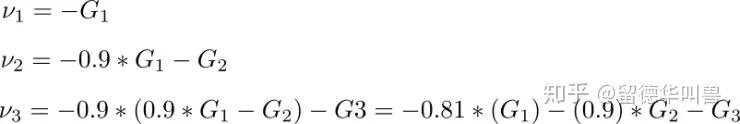
我们可以看到之前的梯度会一直存在后面的迭代过程中,只是越靠前的梯度其权重越小。
Adagrad:(adaptive gradient)自适应梯度算法
Adagard在训练的过程中可以自动变更学习的速率,设置一个全局的学习率,而实际的学习率与以往的参数模和的开方成反比。
一种改进的随机梯度下降算法.以前的算法中,每一个参数都是用相同的学习率,而深度学习模型中往往涉及大量的参数,不同参数的更新频率往往有区别,对于更新不频繁的参数,希望单次步长大些,多学习一些知识;对于更新频发到的参数,希望步长小一些,使得学习的参数更稳定。
Adagrad算法能够在训练中自动对learning_rate进行调整,出现频率较低参数采用较大的𝛼更新,出现频率较高的参数采用较小的𝛼更新.
RMSprop(root mean square propagation) 均方根传播
也是一种自适应学习率方法. 不同之处在于,Adagrad会累加之前所有的梯度平方,RMProp仅仅是计算对应的平均值.可以缓解Adagrad算法学习率下降较快的问题.
Adam (adaptive moment estimation) 自适应矩估计
是对RMSProp优化器的更新.利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
每一次迭代学习率都有一个明确的范围,使得参数变化很平稳.

计算了每个梯度分量的指数平均和梯度平方指数平均(方程 1、方程 2)。为了确定迭代步长我们在方程 3 中用梯度的指数平均乘学习率(如 Momentum 的情况)并除以根号下的平方指数平均(如 Momentum 的情况),然后方程 4 执行更新步骤
超参数 beta1 一般取 0.9 左右,beta_2 取 0.99。Epsilon 一般取1e-10。















 4557
4557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









