







ASBSO:具有灵活搜索长度和基于记忆选择的改进头脑风暴优化
参考文献
《ASBSO: An Improved Brain Storm Optimization With Flexible Search Length and Memory-Based Selection》
要点
本文提议将适应步长结构与成功的记忆选择策略结合到BSO中。所提出的方法是基于记忆选择的适应步长的BSO,即ASBSO,它用多个步长来修改新解的生成过程,从而根据相应的问题和收敛周期提供了灵活的搜索。该新颖的记忆机制能够评估和存储解的改进程度,用于确定步长的选择概率。
一、引言
本文的研究成果概括如下:
- (1)提出了一种基于记忆选择方法的自适应步长机制,以提高BSO的鲁棒性,使其更适合于各种应用。
- (2)第一次使用两个比较的适应度值之差,而不是将0和1之类的简单数字存储在记忆中。此修改可以提高选择方法的效率,从而可观地提高解的质量。
二、关于BSO的简要介绍
略。参考BSO
三、ASBSO
A、研究动机
在新的BSO个体生成操作中,搜索步长仅随当前迭代次数而变化,并且缺乏灵活性,因此使搜索效率和鲁棒性较差。BSO仅应用不变的比例参数K = 20来使搜索范围在迭代过程中缩小,因此缩小是有限且不灵活的。
在ASBSO中,采用了一种自适应步长机制来缓解这一问题。各种可选的比例参数使BSO具有可调整的搜索范围,而不是仅根据当前迭代次数而变化的传统步长。由于ASBSO在搜索过程中应用了多个步长,因此可以大大增加进入搜索情形的低谷或从低谷中跳出的可能性。
B、多步长
公式中的参数K用于更改logsig()的缩放。在多步长策略中,使用表1中列出的不同K值来提供不同的比例来调整搜索步长。 K值相对较小的策略表明,它们可以为搜索半径提供扩散。 BSO可以有效地探索目标空间并加速收敛。

在早期搜索阶段,当面对未知搜索空间时,需要优化算法来具有有效的探索能力,因此,有必要提供较大的搜索步长。在开发阶段,需要应用短步长的局部搜索来挖掘高精度的解决方案,因此,具有较大K值的策略可以提高开发阶段的解质量,因为大K值通常会引起局部搜索。
C、新记忆力机制
为了自适应地执行多个步长,我们引入了一种改进的记忆存储机制(IMS),该机制源自基于成功失败的记忆结构(SFMS),在SFMS中,表2中所示的成功记忆和表3中所示的失败记忆分别用于存储成功或失败生成更好解的次数。


首先,通过轮盘选择法随机选择M个策略以产生新的个体。如等式(3)和(4)所示,如果迭代次数超过预设的迭代长度L(根据经验设置L = 50),表2和表3的第一行将被删除,以腾出空间来存放最新的迭代时间。策略的选择描述如下。
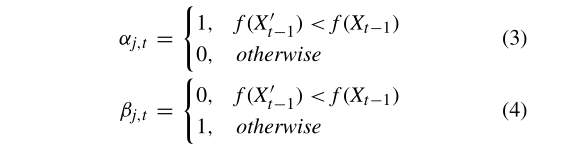
每种策略的选择概率如等式(5)和(6)记忆记录之后的结果。
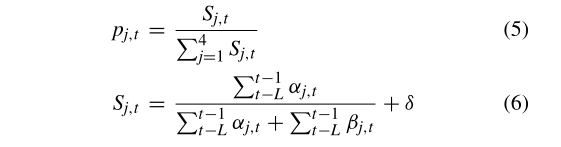
其中,p表示当t > L时在当前代t中使用第j个策略的概率。等式(6)计算成功率,δ= 0.01用来避免空值。显然,成功率更高的策略更有可能被选出以产生新的个体。
但是,SFMS机制有一个缺点,即无论某策略获得的新个体有多好,它都只会在成功内存中记录1。
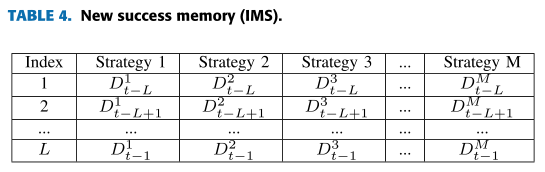
为了缓解此问题,在IMS中,将改进值适应度Dj(表示执行的策略)记录到成功内存中以替换数字0和1。同时,由于我们专注于每种策略获得的质量而不是数量,因此在新机制中未记录失败记忆。如果应用失败记忆,搜索尝试不当可能会降低解的质量并阻碍算法的发展方向。
表4显示了IMS的结构。由策略j获得的适合度的每个改进值Djt被存储在其中。
可以通过等式(7)计算出在迭代时策略选择的概率。
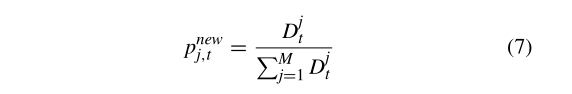
算法1说明了ASBSO的主要过程。

四、参数设置
- M = 4
- k = 10
- H = 20















 1759
1759











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









