







OLBSO:通过正交学习设计提高头脑风暴优化的学习效率
参考文献
《Enhancing Learning Efficiency of Brain Storm Optimization via Orthogonal Learning Design》
要点
在BSO中,收敛操作利用聚类策略将种群分成多个聚类,而发散操作则利用这些聚类信息产生新的个体。然而,这一机制在规范探索和开发搜索方面效率低下。
本文首先分析了影响BSO算法性能的主要因素,然后提出了一种正交学习框架来改进BSO算法的学习机制。在这个框架中,引入了两个正交设计引擎(即探索引擎和开发引擎)来发现和利用有用的搜索经验来提高性能。此外,还保留了一组具有不同特征的辅助传输向量,并通过OD决策机制平衡了它们的偏差。
OLBSO主要贡献
- 提出OL框架,分析和实验表明,该框架对提高探索和开发搜索效率是有效的。
- 为了减少计算量,该方法在每次迭代中以较小的概率触发OD算子。
- 在失效处理中,提出了一种局部重初始化策略,以增强种群多样性,帮助个体跳出局部最优解。
一、背景和动机(BACKGROUND AND MOTIVATION)
正交设计-OD(Orthogonal Design)
OD用于对一小部分具有代表性的组合进行取样,以进行多因素和多水平的试验。这些因素是一组需要调整的实验变量,每个因素可以设置为几个水平中的一个。在一个实验中,如果实验结果取决于 N N N个因子,并且每个因子都有 Q Q Q个水平,则存在 Q N Q^N QN个测试组合,其数量呈指数增长,因此建议使用OD来提供因子水平的最佳组合,并进行少量的测试。
正交数组-OA(Orthogonal Array)
OA是一种构造相互正交的拉丁方的图形方法,表示为 L M ( Q N ) L_M{(Q^N)} LM(QN),其中 M M M是组合的数目, L L L是具有 N N N个因子且每个因子具有 Q Q Q个水平的OA。例如, L 9 ( 3 4 ) L_9{(3^4)} L9(34)表示为:

其中有4个因素,每个因素3个水平,9个水平组合。注意,OA的任何子列也是OA。这意味着我们只能用 L 9 ( 3 4 ) L_9{(3^4)} L9(34)的前3列(或任意3列)来构造 L ′ {L'} L′的三因子OA。
然后,我们给出了一个使用OD的例子。在一个实验中,有三个因素 ( A 、 B 、 C ) (A、B、C) (A、B、C)会影响实验结果,每个因素有三个水平 ( 1 、 2 、 3 ) (1、2、3) (1、2、3),我们的目的是确定最佳水平组合,使实验结果最小化。我们可以使用从 L 9 ( 3 4 ) L_9{(3^4)} L9(34)导出的三因子数组 L ′ {L'} L′来指定要测试的九个代表性组合,如表1所示。

因子分析-FA(Factor Analysis)
根据OA的表格,FA评估每个水平对每个因素的影响,并确定每个因素的最佳水平。FA结果见表2。

计算过程如下。首先,假设 f m f_m fm是第 m ( m = 1 , 2 , … , M ) m(m=1,2,…,M) m(m=1,2,…,M)组合的实验结果, S i j S_{ij} Sij是第 j ( j = A , B , C ) j(j=A,B,C) j(j=A,B,C)因子中第 i ( i = 1 , … , Q ) i(i=1,…,Q) i(i=1,…,Q)水平的影响,定义为:
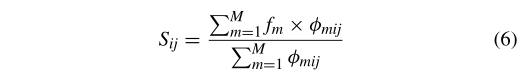
若第 m m m个组合的第 i i i个系数为 j j j,则 ϕ m i j = 1 \phi_{mij}=1 ϕmij=1;否则, ϕ m i j = 0 \phi_{mij}=0 ϕmij=0。然后,通过使用(6),我们可以评估和比较每个水平对不同因子的影响,如表2所示。例如,水平1对因子 A A A的影响称为 A 1 A1 A1,依此类推。由于表2中的例子是一个最小化问题, S i j S_{ij} Sij越小第 j j j因子的第 i i i水平越好。因此,确定了 ( A 3 、 B 2 、 C 2 ) (A3、B2、C2) (A3、B2、C2)的最佳组合。
研究动机(Motivation)
首先,个体进化退化问题很可能是由公式(4)引起的。
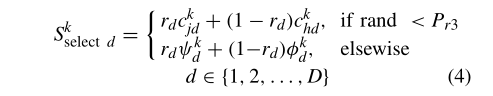
也就是说,新的选择比方程中两个被选择的个体中的任何一个有更差的适应度,这意味着选择的某些维度被他们恶化了。为了说明这一点,我们使用了一个简化的方程来代替(4),即:
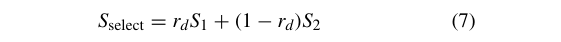
其中 S 1 S_1 S1和 S 2 S_2 S2是两个群内个体, r d r_d rd是均匀分布在 [ 0 , 1 ] [0,1] [0,1]中的随机值。
给定最小化目标函数 f ( S ) = Σ i = 1 D ∣ 2 S i + 3 / S i ∣ f(S)=\Sigma_{i=1}^{D}|2Si+3/Si| f(S)=Σi=1D∣2Si+3/Si∣,(7)中的 S 1 S_1 S1和 S 2 S_2 S2分别属于 [ − 3 , − 0.5 ] [−3,−0.5] [−3,−0.5]和 [ 0 , 3 ] [0,3] [0,3]。这里,我们只考虑一维优化情况 ( D = 1 ) (D=1) (D=1), f ( S ) f(S) f(S)的情况如图1所示。

从图中我们可以观察到,一旦 S 1 S_1 S1和 S 2 S_2 S2落入红色箭头标记的特定间隔内,新的 S s e l e c t S_{select} Sselect将比它们中的任何一个都差。
例如,当
S
1
=
−
2.5
S_1=−2.5
S1=−2.5和
S
2
=
1.5
S_2=1.5
S2=1.5时,根据(7)我们可以得到:
S
s
e
l
e
c
t
=
0.2
∗
(
−
2.5
)
+
(
1
−
0.2
)
∗
1.5
=
0.06
S_{select}=0.2∗(−2.5)+(1−0.2)∗1.5=0.06
Sselect=0.2∗(−2.5)+(1−0.2)∗1.5=0.06,
f
(
S
s
e
l
e
c
t
)
=
50.12
f(S_{select})=50.12
f(Sselect)=50.12,
f
(
S
1
)
=
6.2
f(S_1)=6.2
f(S1)=6.2,
f
(
S
2
)
=
5
f(S_2)=5
f(S2)=5,
然后,可以看到
f
(
S
s
e
l
e
c
t
)
>
f
(
S
1
)
>
f
(
S
2
)
f(S_{select})>f(S_1)>f(S_2)
f(Sselect)>f(S1)>f(S2)。
因此,在这一代中, S s e l e c t S_{select} Sselect不受益于所选择的两个个体 S 1 S_1 S1和 S 2 S_2 S2。另外,随着世代的增加,两个个体 S 1 S_1 S1和 S 2 S_2 S2也趋于相似。这种现象将进一步降低生成更好的 S s e l e c t S_{select} Sselect的概率。
第二,思想想法(5)是一个盲搜索算子,只在 S s e l e c t S_{select} Sselect的每个维上产生一个随机扰动。
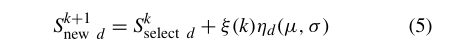
在(5)中,高斯随机函数用于在 S s e l e c t S_{select} Sselect周围执行随机局部搜索。然而, S s e l e c t S_{select} Sselect维数的最优搜索方向往往不同。式(5)由于缺乏必要的方向引导,开发能力较差。这种观察激励我们发现最佳的组合方向来指导局部搜索。
关于 S s e l e c t S_{select} Sselect构造的另一个相关问题是(3)中简单地使用先验概率来选择聚类间想法所引起的种群进化衰减。
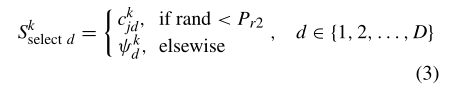
为了说明这一点,我们在球面函数上做了一个实验,其中在搜索空间中有两个聚类A和B,两种情况如图2(a)和(b)所示。

在情形1中,个体数较多的聚类A比聚类B离全局最优解较远。实例2与实例1相反,根据(3)所述,来自较大聚类的个体由于其较大的选择概率而可能优先被选择来构建 S s e l e c t S_{select} Sselect。因此,如图2(c)所示,情况1的演化比情况2的演化差,这表明一个具有较多个体的坏聚类会破坏探索能力。而且,一旦一组个体聚集到这样一个小的区域中,新生成的个体之间就会非常相似,这很容易导致过早收敛。
从以上的观察,我们因此有动机使用OD来设计一组引导向量,有效地利用来自多个聚类的搜索信息。这一概念旨在获得更多有用的信息,以有效地规范探索和开发搜索。特别地,为了加强探索,利用OD来发现由两种策略产生的两种群内搜索经验的最佳组合[即图3(a)中的old1和old2]。一种策略是从所选的两个聚类中选择最佳的思想作为两个样本,这有利于收敛。另一种策略是从两个聚类中随机选择两个普通的想法,这有助于保持解决方案的多样性。这样,两个示例的最佳组合产生了更好的 S s e l e c t S_{select} Sselect。然后,利用OD法确定 S s e l e c t S_{select} Sselect的各维上的最佳扰动方向,以提高开发能力。因此,每个维度上的两个搜索方向示例(即向前或向后)的最佳组合可以引导 S n e w S_{new} Snew沿着更好的方向移动,如图3(b)所示。

二、提议的算法-OLBSO(PROPOSED APPROACH)
主框架(Main Framework)
OLBSO的主要框架如算法1所示。其关键组成部分包括:
- 1)基本BSO操作,包括聚类(行6)、聚类中心打断(行7)、更新(行13和19);
- 2)OD决策操作(行8);
- 3)探索OD策略(行11);
- 4)开发OD策略(行17);
- 5)失效处理(行27)。
其中,基于OD的学习策略是提高学习效率的关键。使用辅助传输向量池来构造有效的样本。

在探索OD阶段,可以随机选择任何个体探索其邻近区域(第10行)。在开发OD阶段,选择全局最优个体开发其邻域(第16行),因为它更可能接近全局最优,从而引导搜索向更好的方向发展。为了降低计算成本,OD决策只允许在每一代中激活一个OD引擎。
OD决策(OD Decision)
OD决策机制(算法1中的第8行)用于决定激活哪个OD引擎以及使用哪个示例。事实上,基于指导范例库的OD操作有利于搜索的不同方面,例如探索和开发。如算法2所示,在每一代中,将使用小概率 p u pu pu选择一个OD引擎进行勘探或开发(第3-7行)。相对较大的 p u pu pu有利于勘探,而相对较小的 p u pu pu有利于开发。因此, p u pu pu被设置为随着世代数的增加而线性减小(第2行)。如果 S s e l e c t S_{select} Sselect的最佳值在一定的生成次数内没有得到改进,则应激活探索OD引擎(算法3)以重新定位 S s e l e c t S_{select} Sselect的位置(第4行)。否则,如果一个个体在若干代中没有得到改进,则应该激活开发OD引擎(算法4),以便围绕这个 S s e l e c t S_{select} Sselect(第6行)找到更好的搜索方向。最后,对于探索OD引擎,从辅助传输向量池中选择一个示例(第9-18行)。注意,从第3-7行可以看出,每一代中只触发一个OD操作,这大大降低了计算成本。

辅助传输矢量(Auxiliary Transmission Vectors)
在探索OD引擎中,利用 S s e l e c t S_{select} Sselect信息和辅助传输向量构造了一个新的范例。如果OD仅使用单个固定传输向量(例如 S b e s t S_{best} Sbest),则其影响可随着搜索的进行而减小。原因如下。
- 首先,所使用的辅助向量容易与 S s e l e c t S_{select} Sselect相似,导致信息丢失恶化。
- 第二,单个引导向量可能有偏差,导致个体收敛到局部最优区域。
为此我们构造了辅助传输向量的四重结构,即 T S = { T S 1 , T S 2 , T S 3 , T S 4 } TS=\{TS_1,TS_2,TS_3,TS_4\} TS={TS1,TS2,TS3,TS4},其中 T S i = { T S i 1 , T S i 2 , T S i 3 , T S i 4 } , i = 1 , … , 4 TSi=\{TS_{i1},TS_{i2},TS_{i3},TS_{i4}\},i=1,…,4 TSi={TSi1,TSi2,TSi3,TSi4},i=1,…,4,定义如下。
- 具有全局最佳信息的收敛向量
T S 1 = S s e l e c t + r a n d ( ) × ( S b e s t − S s e l e c t ) TS_1= S_{select}+rand()× (S_{best}−S_{select}) TS1=Sselect+rand()×(Sbest−Sselect)
- 具有聚类中心信息的收敛向量
T S 2 = S s e l e c t + r a n d ( ) × ( C R − S s e l e c t ) TS_2= S_{select}+rand()× (C_R−S_{select}) TS2=Sselect+rand()×(CR−Sselect)
- 具有普通个体信息的多样性向量
T S 3 = P i TS_3= P_i TS3=Pi
- 基于对立学习(OBL)信息的多样性向量
T S 4 = r a n d ( ) × ( U + V ) − P i TS_4= rand()×(U +V)−P_i TS4=rand()×(U+V)−Pi
探索OD引擎(Exploration OD Engine)
算法3给出了主要步骤。

探索OD操作的目的是通过使用两个示范向量来更新 S s e l e c t S_{select} Sselect。具体地说,由 S s e l e c t = S e x a m p l e 1 ⊕ S e x a m p l e 2 S_{select}=S_{example1}\oplus S_{example2} Sselect=Sexample1⊕Sexample2生成的选择,其中 S e x a m p l e 1 S_{example1} Sexample1和 S e x a m p l e 2 S_{example2} Sexample2是示例性向量。这里,可以使用两种替代方法来形成用于更新 S s e l e c t S_{select} Sselect的示例向量。一种是在一个聚类时利用由算法2生成的辅助传输矢量(第2和第3行)。另一种方法是在两个聚类时使用两个选定想法的良好组合信息(第4行和第5行)。
在算法3中,每一个 D D D维都被看作一个因子,每个因子有两个层次,即1和2,因此,有 M = 2 ⌈ l o g 2 D + 1 ⌉ M=2^{\lceil log_2{D+1}\rceil} M=2⌈log2D+1⌉个正交组合在OA中的应用。在我们的实现中,如果OA中的 l e v e l level level值是1,那么相应的因子(维度)选择 S e x a m p l e 1 S_{example1} Sexample1的相应元素;否则,选择 S e x a m p l e 2 S_{example2} Sexample2。
具体而言,首先基于(第1行)构造两等级OA,即 L M ( 2 D ) L_M(2^D) LM(2D)。
如果 S s e l e c t S_{select} Sselect是从一个聚类导出的,则辅助传输向量 T S O − T S TS_{O−TS} TSO−TS中的 T S TS TS用作 S e x a m p l e 1 S_{example1} Sexample1,当前 S s e l e c t S_{select} Sselect被视为 S e x a m p l e 2 S_{example2} Sexample2(第2行和第3行)。
如果两个聚类参与生成 S s e l e c t S_{select} Sselect,则两个聚类内向量分别被用作 S e x a m p l e 1 S_{example1} Sexample1和 S e x a m p l e 2 S_{example2} Sexample2(第4行和第5行)。
然后,评估来自OA的每个候选样本以确定最佳解 S b S_b Sb(第7行和第8行),并且确定每个因子的最佳水平以导出预测解 S p S_p Sp(第9行和第10行)。
最后,使用 S b S_b Sb和 S p S_p Sp之间的较好的一个作为新的 S s e l e c t S_{select} Sselect(第11行)。
第5行的OD运算可以充分利用两个聚类内思想较好的维,引导搜索向更好的方向发展。这样可以避免个体进化的退化问题。
开发OD引擎(Exploitation OD Engine)
算法4给出了主要程序。

开发OD引擎就是在 S s e l e c t S_{select} Sselect的每个维度上寻找最佳的搜索方向,以便更深入地开发最有前景的区域。动机是通过调整搜索方向来补救缺陷搜索,如图3(b)所示。公式(5)只在所选思想的每个维度上产生一个随机扰动,利用率低。
在算法4中,将待更新候选解的每个维度视为一个因子,因此存在 D D D个因子,每个因子有两个层次,即1和2。然后,按照算法3(第1行)中相同的步骤构造一个两层OA,即 L M ( 2 D ) L_M(2^D) LM(2D)。这里,对于每个因子,级别值1表示向前搜索方向,即在候选解上添加正步,级别值2表示向后搜索方向,即在候选解上添加负步。为了说明这一点,我们给出了以下搜索公式:
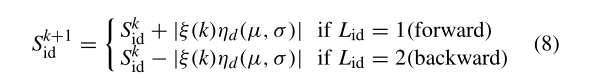
其中 L i d L_{id} Lid是组合 d d d与 L M ( 2 D ) L_M(2^D) LM(2D)中因子 i i i的水平值, S i d k S^k_{id} Sidk是组合 d d d的想法 S i S_i Si的第 d d d维, ∣ ξ ( k ) η d ( μ , σ ) ∣ |ξ(k)η_d(μ, σ )| ∣ξ(k)ηd(μ,σ)∣ 是步长。
接下来,通过选择相应的水平值并使用它们来生成基于公式(8)的解(第2行),从而组成 M = 2 ⌈ l o g 2 D + 1 ⌉ M=2^{\lceil log_2{D+1}\rceil} M=2⌈log2D+1⌉个被测解。然后,分别确定各因子水平最佳的最佳候选解 S b S_b Sb和预测解 S p S_p Sp(第3行和第4行)。最后,根据 S b S_b Sb和 S p S_p Sp(第7行)确定最终候选解 S n e w S_{new} Snew。
失效处理(Invalidation Processing)
如果OD在一定的代数内没有贡献,则部分解会重新初始化它们在整个搜索空间中的位置(算法1的第27行),目的是增加解“跳出”局部最优解的可能性。设计了一种自适应策略来调节重新初始化解 N r N_r Nr的数目,如下所示:
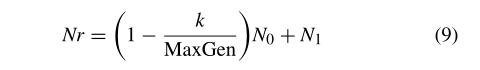
其中 k k k是当前的世代数, M a x G e n MaxGen MaxGen是最大世代数, N 0 N_0 N0是重新初始化解的初始数目,经验上等于人口的一半, N 1 N_1 N1是结果数,通常设置为1。
从(9)可以看出,在搜索过程中, N r N_r Nr是下降的。在搜索开始时有一半解重新初始化,然后 N r N_r Nr在每次重新初始化时线性减小。这一策略是先进行勘探,后期进行开发。















 2231
2231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









