







云计算学习第一篇---在deepin上安装配置jdk,ssh,伪分布式hadoop,这一篇就够了
一、实验环境准备
Linux系统: deepin15.11
jdk: jdk-8u11-linux-x64
hadoop: hadoop-2.6.5
考虑到小伙伴们的需求,在这里免费提供了百度云的下载链接,有需要的小伙伴们可以自取噢。
jdk-8u11-linux-x64 密码: 9vcb
hadoop-2.6.5密码: v44j
二、jdk的环境配置
Linux下jdk的环境配置算是基础了,但本着一条龙讲解服务还是再说明下
1、下载解压jdk1.8
由于现在oracle下载jdk需要进行注册,并且下载速度往往不尽人意,文章开头提供了百度云的下载链接,有需要的小伙伴自取。
下载后通过 $ tar -zxvf jdk-8u11-linux-x64.tar.gz解压到当前目录。为了之后环境变量方便将文件夹更名为jdk
2、配置环境变量
在/etc/profile中添加如下:
# set java environment
JAVA_HOME=/home/chengzhijun/baidunetdiskdownload/jdk
JRE_HOME=$JAVA_HOME/jre
CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
注:第一行的JAVA_HOME记得改成自己jdk的解压目录
之后运行 $ source /etc/profile 使环境变量生效
运行 $ java -version 出现了Java的信息说明jdk配置成功!
三、ssh配置无密码登录
1、什么是ssh
ssh,即secure shell ,专为远程登录会话和其他网络服务提供安全性的协议。我们主要是配置基于密匙的安全验证,即创建一对秘钥,即公钥和私钥。公钥放在服务器端,发送数据时用公钥进行加密,而只有私钥才能解密,防止了数据被截取泄露。

2、如何在deepin上配置ssh
(1)、首先确定deepin上安装了ssh,现在的Linux基本上都默认安装了ssh,可以用ssh -V查看ssh版本。若没有则可以通过运行
$ sudo apt-get install ssh
进行安装
(2)、运行如下命令:
cd ~/.ssh # 首先进入主目录的.ssh目录下
ssh-keygen -t rsa -P '' -f id_rsa # -P后面的参数为两个单引号
cat id_rsa.pub >> authorized_keys
第二条命令是使用rsa秘钥算法生成一对秘钥,公钥和私钥分别保存在id_rsa和对应的id_rsa.pub文件里。
第三条命令是将公钥放入authorized_keys。
(3)、运行ssh localhost,无需输入密码成功连接说明ssh配置完成!
四、hadoop的安装配置
1、安装hadoop
(1)、首先下载hadoop-2.6.5.tar.gz文件
(2)、接着tar -zxvf hadoop-2.6.5.tar.gz -C /opt 命令将hadoop解压到/opt目录下
(3)、打开hadoop目录中的 etc/hadoop/hadoop-env.sh中设置Java环境,添加如下代码:
# 注:这里的JAVA_HOME即跟上面环境变量中的配置相同
export JAVA_HOME=/home/chengzhijun/baidunetdisk/jdk
2、配置hadoop
(1)配置core-site.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
<description>HDFS的URI,文件系统://namenode标识:端口号</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp</value>
<description>namenode上本地的hadoop临时文件夹</description>
</property>
</configuration>
(2)配置hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp/dfs/name</value>
<description>namenode上存储hdfs名字空间元数据 </description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp/dfs/data</value>
<description>datanode上数据块的物理存储位置</description>
</property>
<property>
<name>dfs.checkpoint.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp/dfs/snn</value>
<description>secondary namenode 的位置</description>
</property>
<property>
<name>dfs.checkpoint.edits.dir</name>
<value>file:/opt/hadoop-2.6.5/tmp/dfs/snn</value>
<description>secondary namenode 的位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>副本个数,配置默认是3,应小于datanode机器数量</description>
</property>
</configuration>
(3)配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Yarn中通过shuffler来传递Map输出到Reduce</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
3、启动hadoop
(1)、首先进行hadoop的安装目录下
(2)、终端运行命令
sbin/start-dfs.sh
sbin/start-yarn.sh
# 或者 sbin/start-all.sh启动hdfs和yarn服务
由于前面配置了ssh免密码登录,此时无需输入密码
(3)、终端运行jps查看,有如下前面五个运行的Java程序,说明配置正确并成功启动。同时在浏览器进入localhost:9000与localhost:50070也可以出现页面
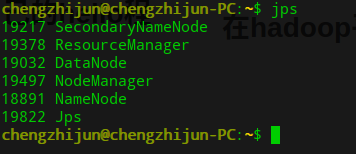
五、在hadoop平台运行自己的hello程序
在此以运行一个简单的hello程序为示例
1、配置CLASSPATH
在/etc/profile中添加如下配置
HADOOP_HOME=/opt/hadoop-2.6.5
PATH=$HADOOP_HOME/bin:$PATH
CLASSPATH=$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar:$HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.5.jar:$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.5.jar:$CLASSPATH
export HADOOP_CLASSPATH=.:$HADOOP_HOME/javabin
第三行将hadoop安装目录下的的几个jar包添加进class文件的查找目录中。
第四行使得我们可以直接使用hadoop运行安装目录下javabin里的.class文件。(javabin目录是我们自己创建的目录,我们将经过javac编译好的.class放置进去,因为配置好了环境变量,可以直接hadoop运行javabin里的.class文件)
source /etc/profile使得配置文件立即生效
2、编写java程序
首先编写一个简单的hello.java程序,打印出hello。
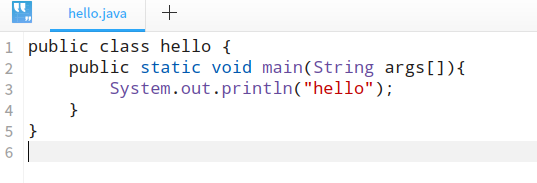
3、编译
javac hello.java -d /opt/hadoop-2.6.5/javabin 在javabin目录下生成hello.class文件(没有javabin的话自己先新建一个javabin目录)
4、hadoop运行.class文件
hadoop hello通过hadoop运行hello.class,成功在控制台打印hello信息。

仍有不清楚或不明白的地方可以联系我















 2416
2416











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









