





大数据开发环境搭建
安装Java环境
下载jdk-8u191-linux-x64.tar.gz(我的电脑64位),解压到/opt/目录下,
sudo tar -zxvf jdk-8u191-linux-x64.tar.gz -C /opt/
配置Java环境变量, sudo vi /etc/profile,输入如下内容:

使用 source /etc/profile使之生效,然后输入java -version可以看到java版本信息就成功了。
eclipse安装
eclipse官网下载
下载完成后会有一个eclipse-inst-linux64.tar.gz压缩包,解压到主用户目录下。
解压后会生成一个eclipse-installer目录,其下有一个可执行文件eclipse-inst,执行这个命令就进入图形化安装了。



配置maven
1.maven下载地址
2.在主目录下新建tools文件夹,将maven解压到该目录下,

3.配置maven的环境变量,sudo vim /etc/profile,在文件下追加如下内容:

4.source /etc/profile 使配置生效,然后输入mvn -version检验是否成功,如图就是OK了 :

5.在apache-maven-3.6.0/conf/settings.xml中配置阿里的镜像源,加入如下内容
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>

6.再配置下jar包下载在本地的什么位置,依旧在settins.xml中的localrepositroy处,添加如下内容:

7.命令行下执行 mvn help:system ,下载一些必须的包。
8.配置eclips中maven插件。
因为我们这里已经安装好maven了,所有直接在eclipse中导入就好了。窗口Window->preferences–>maven–>Installations。如图选择add,然后把你maven安装的目录导进来并apply就好了。

下面这个也要配置一下,maven->user settings

9.eclipe git教程
eclipse使用git图解教程
eclipse提交项目到github上
Mysql安装
sudo apt-get install mysql-server mysql-client
VMWare安装
deepin商店可直接安装。

安装完成后,在启动器内启动,一直下一步就行,最后可能要输入激活码,分享激活码如下:
vmware15pro激活码
VMware最小化安装centos搭建集群
参考链接
1.打开vmwarestation,点击create a new virtual machine

2.选择custom(自定义安装)

3.下一步
4.选择稍后安装。

5.选择linux,centos64位

6.设置虚拟机安装目录及名字,最好安装在主目录下。
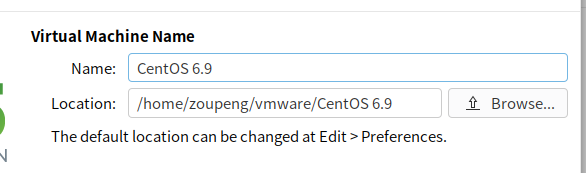
7.设置处理器和cpu数量,

8.为虚拟机设置内存大小

9.设置网络为使用桥接网络,在虚拟机安装过程中会桥接到宿主机当前上网的网卡,以实现网络连接。

10.i/o控制器类型和虚拟磁盘类型选择默认。


11.选择创建新虚拟磁盘。

12,指定磁盘容量。

13.指定磁盘文件名称,选择默认。

14.按默认配置一直点击下一步,直到完成。
15.完成后,打开vmware,点击虚拟机设置。

16.点击cd/dvd,选中centos镜像安装目录。

17.配置保存后,点击启动虚拟机开始安装。

18.安装完成后,输入root用户和上面设置的root密码,进入系统。
19.给系统新增用户hadoop:
useradd hadoop
passwd hadoop
然后切换至root用户,给hadoop用户赋予sudo权限。
vi /etc/sudoers
找到这一行:‘root ALL=(ALL)ALL’,在下面添加:
hadoop ALL=(ALL) ALL
20.不能上网问题解决(虚拟机要配置为NAT模式)。
激活网卡
vi /etc/sysconfig/network-scripts/ifcfg-enp0s3
将 ONBOOT=no 改为 ONBOOT=yes
重启network服务
service network restart
然后还需要安装net-tools包,否则ifconfig不起作用
yum install net-tools

21,.
避免网络原因导致下载速度慢,还需配置下Centos的源
0、先下载wget工具 yum -y install wget
1、备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2、下载新的CentOS-Base.repo 到/etc/yum.repos.d/
CentOS 6
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-6.repo
3.清理yum缓存 yum clean all 4、重建缓存 yum makecache 5、升级yum -y update
Scala下载及安装
我选择Spark2.4.0,所以 scala选择2.11.12版本
sacla下载地址
解压到用户目录下,

配置环境变量、
sudo vi /etc/profile
在末尾添加如下:

eclipse 安装scala-ide插件
scala 插件下载
选择和你eclipse、Scala适配的版本,下载相应的zipfile,
解压zipfile后,将解压文件放到eclipse文件夹下的dropins目录下,重启eclipse,然后按提示默认安装即可。
hadoop完全分布集群搭建
以下操作均在虚拟机上完成。
1.把本地的jdk上传到centos系统下的随便哪个目录下(我是主目录),首先配置centos上的ssh.参考这个ssh server配置,然后在centos上安装ssh-client.
sudo yum -y install openssh-clients
2.把jdk压缩包解压到主目录下:
tar -zxvf (jdk压缩包名称)
3.虚拟机环境配置,在/etc/profile文件中添加如下变量。sudo vi /etc/profile

source /etc/profile后,输入java -v,有版本信息出现则证明配置成功。
4.配置虚拟机网络环境
- 设置静态ip
同样是在/etc下(这是配置文件所在地)如下命令打开配置文件:

配置如下,ip应和vm的NAT在同一网段:

设置主机名:

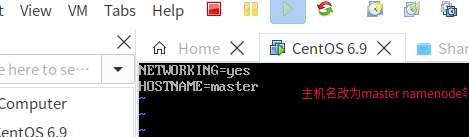
绑定IP地址到主机名的映射:sudo vi /etc/hosts
添加如下内容:
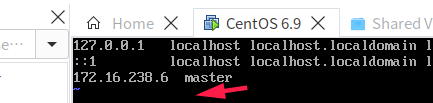
关闭防火墙:

重启网络:

ping以下主机名,可以ping通就ok.

配置hadoop的环境
下载hadoop
1)hadoop下载地址
下载hadoop-2.6.0-cdh5.12.1.tar.gz 版本。
2)deepin命令行 ctrl+/打开远程服务器配置,填入参数,就可以在本地命令行远程操作上面搭的虚拟机。

3)上传文件到centos服务器,上传到主目录下(在本地命令行中输入)
scp hadoop-2.6.0-cdh5.12.1.tar.gz hadoop@172.16.238.6:/home/hadoop

4)解压安装到主目录下,

5)hdfs在运行时需要name,data,logs,tmp文件夹用来存放原数据,实际数据,日志,临时文件
mkdir -p hdfs hdfs/name hdfs/data logs tmp //在hadoop目录中创建
6)修改hadoop配置文件
下载这个配置文件 ,提取码:ixfq ,
上传到/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop目录下,覆盖原文件即可。
sudo scp -r hadoop完全分布式配置文件 hadoop@172.16.238.6:/home/hadoop

连上虚拟机,将文件复制到/home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop目录下。
sudo cp -r hadoop完全分布式配置文件/* /home/hadoop/hadoop-2.6.0-cdh5.12.1/etc/hadoop

7)配置Hadoop环境变量
sudo vi .bash_profile
在bash_profile 里添加如下:
export HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
复制生成另外两台虚拟机
配置好后关闭虚拟机,进入文件系统将该虚拟机复制两份,(建议用cp命令复制)
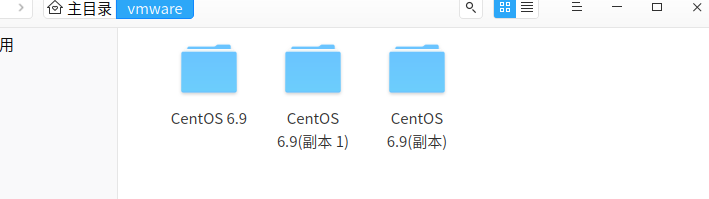
然后在虚拟机中导入并重命名,open->打开下面这个文件。
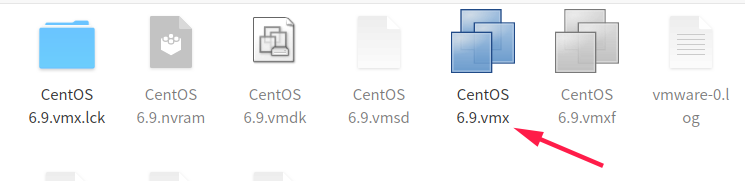


同样重命名第二台虚拟机。
问题:复制后发现三台虚拟机都无法上网,参考这个解决问题:网卡激活
重启虚拟机,分别修改slave1,slave2的IP地址和主机名及ip与主机名的映射,参见前面第4步,并重启。
全部完成后,用命令行工具来连接虚拟机,如图:

用exit命令可退出服务器的连接。
设置集群间ssh免密登录
1.分别在三台虚拟机上设置秘钥,ssh-keygen -t rsa,然后三下回车,如图:

2.将slave1、slave2节点的公钥汇总到master 的 .ssh/authorized_keys文件中。
问题 :

在三个虚拟机的/etc/hosts中分别加入 主机名和ip的映射.

在slave1和slave2中输入
ssh-copy-id -i ~/.ssh/id_rsa.pub master

3.把master的公钥也汇总到authorized_keys文件中。
在master节点中执行:
cd .ssh/
cat id_rsa.pub >> authorized_keys
chmod 600 authorized_keys //有必要赋予访问权限
4.把汇总后的authorized_keys文件分别发送到slave1、slave2的.ssh目录下
#master节点上执行
scp authorized_keys slave1:.ssh
scp authorized_keys slave2:.ssh
5.测试ssh免密登录
ssh 主机名 //第一次连接时如有提示,输入yes,以后则没有提示也不需要密码即可连接
下图是slave1 ssh slave2和master,显示已经成功。

启动hadoop
以下操作全在master上进行:
1)格式化hdfs文件系统
hdfs namenode -format
出现问题:

是因为我们把jdk安装在了主目录;使用依下命令复制到/opt目录下并重命名,三台虚拟机都这样将jdk复制到/opt目录下,并 相应修改/etc/profile中的java环境配置
cp -R jdk1.8.0_191 /opt
sudo mv jdk1.8.0_191 jdk1.8.0_201


在执行: hdfs namenode -format,就成功了

2)启动hdfs和yarn
start-dfs.sh //启动hdfs
start-yarn.sh //启动yarn
jps //查看启动进程

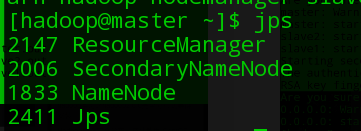
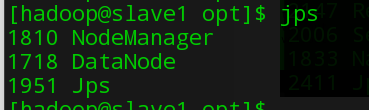
浏览器查看hdfs:http://172.16.238.6:50070(master IP地址),yarn:http://172.16.238.6:8088
注意:master下只能看到NameNode、SecondaryNameNode(未配置但依然会启动,配置的话还需要一台虚拟机)、ResourceManager;slave下有Datanode、NodeManager
基于Hadoop集群的Hive安装配置
Hive可以安装在任一节点或集群之外,我这里是计划装在Master节点上。 其次Hive也就是在hadoop上加了一层SQL接口,便于通过简单的SQL语言翻译成MapReduce作业。而hdfs的特性是可追加不可修改,但数据库表是可以修改删除的,所以Hive的所存储的数据应当分成两部分,表的元数据外部存储以便修改,表中数据存储在hdfs上即可。 hive是默认将元数据保存在本地内嵌的 Derby 数据库中,但Derby不支持多会话连接,所以我这里选择mysql来存储metadata元数据。
1)准备
- Hive CDH发行版本(hive下载),为了和Hadoop、HBase、flume等版本对应,这里限定使用cdh5.12.1结尾的hive-1.1.0-cdh5.12.1.tar.gz
- 下载mysql驱动(mysql驱动下载)

2)在线安装并配置Mysql
参考: linux CentOS6.5 yum安装mysql 5.6
1.新开的云服务器,需要检测系统是否自带安装mysql
yum list installed | grep mysql
2.如果发现有系统自带mysql,果断这么干
yum -y remove mysql-libs.x86_64
3.随便在你存放文件的目录下执行,这里解释一下,由于这个mysql的yum源服务器在国外,所以下载速度会比较慢,还好mysql5.6只有79M大,而mysql5.7就有182M了,所以这是我不想安装mysql5.7的原因
wget http://repo.mysql.com/mysql-community-release-el6-5.noarch.rpm
4.接着执行这句,解释一下,这个rpm还不是mysql的安装文件,只是两个yum源文件,执行后,在/etc/yum.repos.d/ 这个目录下多出mysql-community-source.repo和mysql-community.repo
rpm -ivh mysql-community-release-el6-5.noarch.rpm
5.这个时候,可以用yum repolist mysql这个命令查看一下是否已经有mysql可安装文件
yum repolist all | grep mysql
6.安装mysql 服务器命令(一路yes):
yum install mysql-community-server
7.安装成功后,查看MySQL各组件是否成功安装
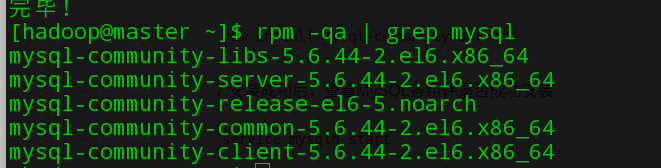
如下命令启动mysql
sudo service mysqld start
8.由于mysql刚刚安装完的时候,mysql的root用户的密码默认是空的,所以我们需要及时用mysql的root用户登录(第一次回车键,不用输入密码)
mysql -u root

9.查看数据库
mysql> show databases; (注意:必须以分号结尾,否则会出现续行输入符“>”)
10.创建hive元数据数据库(metastore)
mysql> create database hive;
创建用户hive,密码是123456
mysql> CREATE USER 'hive'@'%' IDENTIFIED BY '123456';
注意:删除用户是DROP USER命令 ,%代表可以在任一台主机(IP地址)上使用hive用户
授权用户hadoop拥有数据库hive的所有权限
mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' WITH GRANT OPTION;
查看新建的MySQL用户(数据库名:mysql,表名:user)
mysql> select host,user,password from mysql.user;

删除空用户记录,如果没做这一步,新建的hive用户将无法登录,后续无法启动hive客户端
mysql>
delete from mysql.user where user='';
刷新系统授权表(不用重启mysql服务)
mysql> flush privileges;
11.测试hive用户登录
$ mysql -u hive -p
Enter password:123456
12…查看mysql是否自启动,并且设置开启自启动命令
chkconfig --list | grep mysqld
chkconfig mysqld on
3)安装hive
- 上传下载的hive压缩包

-
登录mastrer的Hadoop用户,解压到用户目录下
tar -zxvf hive-1.1.0-cdh5.12.1.tar.gz -
在.bash_profile文件中添加hive环境变量
export HIVE_HOME=/home/hadoop/hive-1.1.0-cdh5.12.1
export PATH=$HIVE_HOME/bin:$PATH
并使之生效 source .bash_profile
- 编辑$HIVE_HOME/conf/hive-env.sh文件,在末尾添加HADOOP_HOME变量
$ cd $HIVE_HOME/conf
$ cp hive-env.sh.template hive-env.sh (默认不存在,可从模板文件复制)
$ vi hive-env.sh
# 添加HADOOP_HOME=/home/hadoop/hadoop-2.6.0-cdh5.12.1

- 同样在conf目录下新建hive-site.xml

配置如下:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
# 下面几步指定使用创建的hive用户访问mysql
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.cj.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://172.16.238.6:3306/hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name> #指定仓库目录,在hdfs上
<value>/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>/hive/tmp </value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
</configuration>
如配置文件中指明了hive仓库在hdfs上,所以要创建/hive/warehouse和/hive/tmp目录
- 启动hdfs服务并创建所述目录
start-dfs.sh #起hdfs
hdfs dfs -mkdir -p /hive/warehouse /hive/tmp #创建多级目录
hdfs dfs -ls -R /hive #查看

- 将先前下载的mysql驱动上传并解压到$HIVE_HOME/lib目录下

解压:
tar -zxvf mysql-connector-java-8.0.16.tar.gz -C $HIVE_HOME/lib
将jar包复制到lib目录下(lib目录下只需要有解压目录中的jar包就行):
cp mysql-connector-java-8.0.16.jar ../

- 启动hive,前提确保hadoop集群启动了,命令行输入hive

hive简单使用
和mysql使用差不多的,类似SQL语句的HSQL
启动hive:hive
退出:quit;
查看数据库和表,同sql语句 show databases,show tables from xxx
创建表,我这里随便建了个create table user(name string,age int,id string);
查看表结构 desc user;
查看表详细信息 desc fromatted user;
插入数据 insert into user values(‘hadoop’,10,‘0x001’),(‘hbase’,6,‘0x002’),(‘josonlee’,20,‘0x003’);

查询数据:
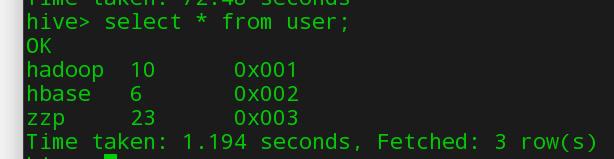
创建数据库
hive> create database testdb; //在默认位置创建DB(配置中指定的/hive/warehouse/)
hive> create database testdb location ‘/hive/testdb’ //在HDFS指定目录下创建DB
查看数据库结构 desc database testdb;
切换数据库 use testdb;
删除数据库
hive> drop database testdb; //只能删除空数据库(数据库中没表)
hive> drop database mydb cascade; //删除非空数据库
Hive就是这样简单搭建成功
可以再去MySQL下看看到底改变了存储了什么信息,如图:

其中上面创建的user表的字段信息存储在COLUMN_V2里,如图

其余表对应Hive数据库相关信息如下:
一、存储Hive版本的元数据表(VERSION)
二、Hive数据库相关的元数据表(DBS、DATABASE_PARAMS)
1、DBS
2、DATABASE_PARAMS
三、Hive表和视图相关的元数据表
1、TBLS
2、TABLE_PARAMS
3、TBL_PRIVS
四、Hive文件存储信息相关的元数据表
1、SDS
2、SD_PARAMS
3、SERDES
4、SERDE_PARAMS
五、Hive表字段相关的元数据表
1、COLUMNS_V2
六、Hive表分区相关的元数据表
1、PARTITIONS
2、PARTITION_KEYS
3、PARTITION_KEY_VALS
4、PARTITION_PARAMS















 1010
1010











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









