







本文旨在记录工作、学习过程中遇到的性能优化技巧,会不停的添加内容
优秀文章
常规手段
1.sync.Pool
临时对象池应该是对可读性影响最小且优化效果显著的手段。基本上,业内以高性能著称的开源库,都会使用到。
最典型的就是fasthttp了,它几乎把所有的对象都用sync.Pool维护。但这样的复用不一定全是合理的。比如在fasthttp中,传递上下文相关信息的RequestCtx就是用sync.Pool维护的,这就导致了你不能把它传递给其他的goroutine。如果要在fasthttp中实现类似接受请求->异步处理的逻辑,必须得拷贝一份RequestCtx再传递。这对不熟悉fasthttp原理的使用者来讲,很容易就踩坑了。
还有一种利用sync.Pool特性,来减少锁竞争的优化手段,也非常巧妙,有些在优化随机数的文章有讲【待补充】。另外,在优化前要善用go逃逸检查分析对象是否逃逸到堆上,防止负优化。
2.string2bytes & bytes2string
这也是两个比较常规的优化手段,核心还是复用对象,减少内存分配。在 go 标准库中也有类似的用法gostringnocopy,要注意string2bytes后,不能对其修改。
unsafe.Pointer经常出现在各种优化方案中,使用时要非常小心。这类操作引发的异常,通常是不能recover的。
3.协程池
绝大部分应用场景,go 是不需要协程池的。当然,协程池还是有一些自己的优势:
- 可以限制goroutine数量,避免无限制的增长。
- 减少栈扩容的次数。
- 频繁创建goroutine的场景下,资源复用,节省内存。(需要一定规模。一般场景下,效果不太明显)
go 对goroutine有一定的复用能力。所以要根据场景选择是否使用协程池,不恰当的场景不仅得不到收益,反而增加系统复杂性。
参考分析
开源协成池
4.反射
go 里面的反射代码可读性本来就差,常见的优化手段进一步牺牲可读性。而且后续马上就有泛型的支持,所以若非必要,建议不要优化反射部分的代码
比较常见的优化手段有:
缓存反射结果,减少不必要的反射次数。例如json-iterator
直接使用unsafe.Pointer根据各个字段偏移赋值
消除一般的struct反射内存消耗go-reflect
避免一些类型转换,如interface->[]byte。可以参考zerolog
5.减小锁消耗
并发场景下,对临界区加锁比较常见。带来的性能隐患也必须重视。常见的优化手段有:
- 减小锁粒度: go 标准库当中,
math.rand就有这么一处隐患。当我们直接使用rand库生成随机数时,实际上由全局的globalRand对象负责生成。globalRand加锁后生成随机数,会导致我们在高频使用随机数的场景下效率低下。可以参考北极星 polaris-go 优化随机数 - atomic: 适当场景下,用原子操作代替互斥锁也是一种经典的
lock-free技巧。
标准库中sync.map针对读操作的优化消除了rwlock,是一个标准的案例。对它的介绍文章也比较多,不在赘述。
prometheus里的组件histograms直方图也是一个非常巧妙的设计。
一般的开源库,比如**go-metrics,trpc-go-metrics都是直接在这里使用了互斥锁。指标上报作为一个高频操作,在这里加锁,对系统性能影响可想而知。
参考sync.map里冗余 map 的做法,prometheus把原来histograms的计数器也分为两个:cold和hot,还有一个hotIdx用来表示哪个计数器是hot。业务代码上报指标时,用atomic原子操作对hot计数器累加向prometheus服务上报数据时,更改hotIdx,把原来的热数据变为冷数据,作为上报的数据。然后把现在冷数据里的值,累加到热数据里,完成一次冷热数据的更新替换。还有一些状态等待,结构体内存布局的介绍,不再赘述。具体可以参考Lock-free Observations for Prometheus Histograms**
6.字符串操作规避反射
参考zap的设计,尽可能规避反射操作,如果需要进行类型转换 使用strconv的操作,性能会更优异
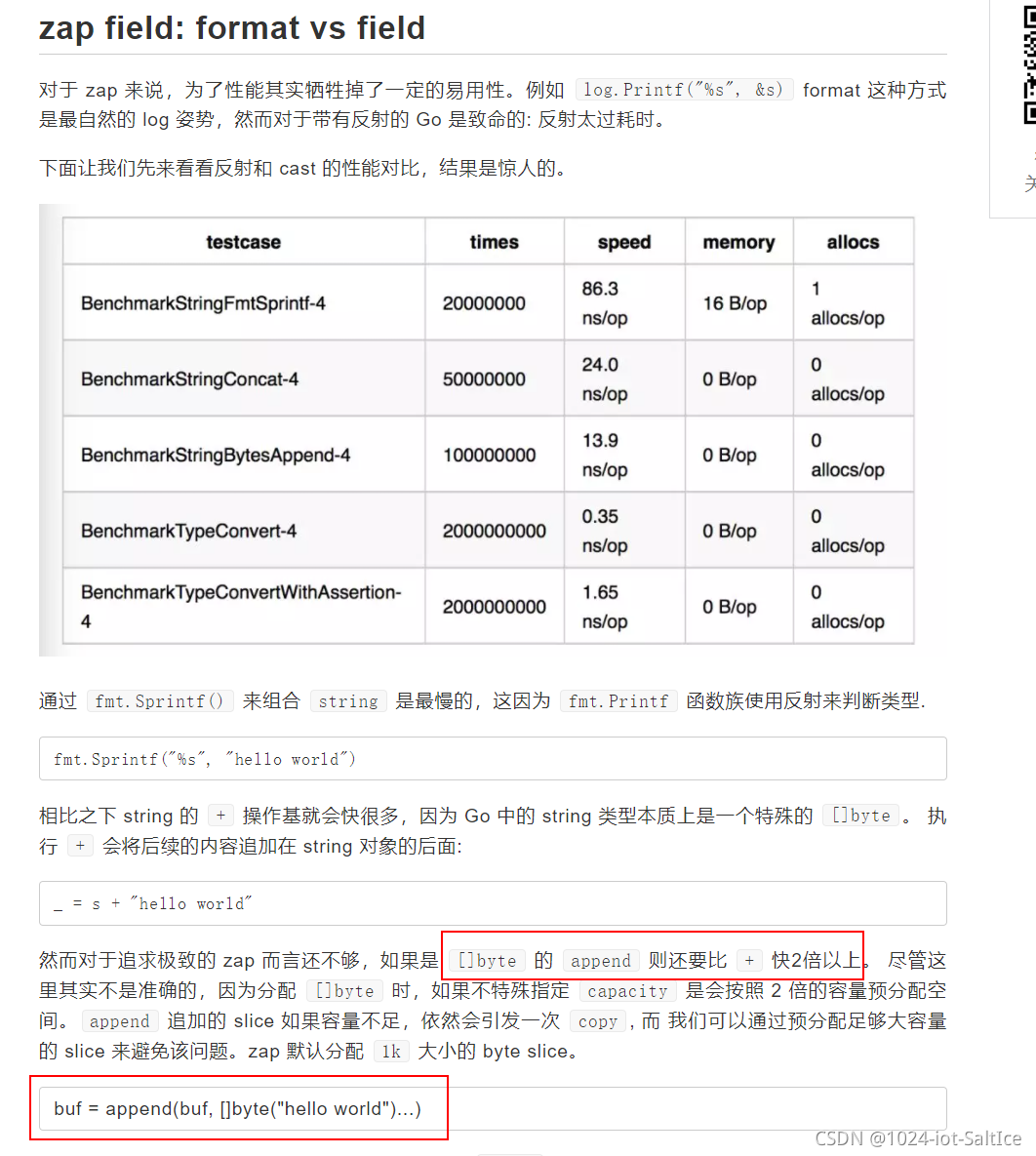
7.参数逃逸加大GC负担
指针必然逃逸的情况(go 1.13.4 darwin/amd64)
- 在某个函数中new或者字面量创建出的变量,将其指针作为函数返回值,则该变量逃逸(构造函数返回的指针变量必然逃逸)
- 被已经逃逸的变量引用的指针,发送逃逸
- 被指针类型的silce、map和chan引用的指针,发送逃逸
指针必然不逃逸的情况
- 指针被未发生逃逸的变量引用
- 仅仅在函数内对变量做取址操作,未将指针传出
可能逃逸情况
- 将指针作为入参传给别的函数;这里还是要看指针在被传入的函数中的处理过程,如果发生了上边三种情况,则也会逃逸
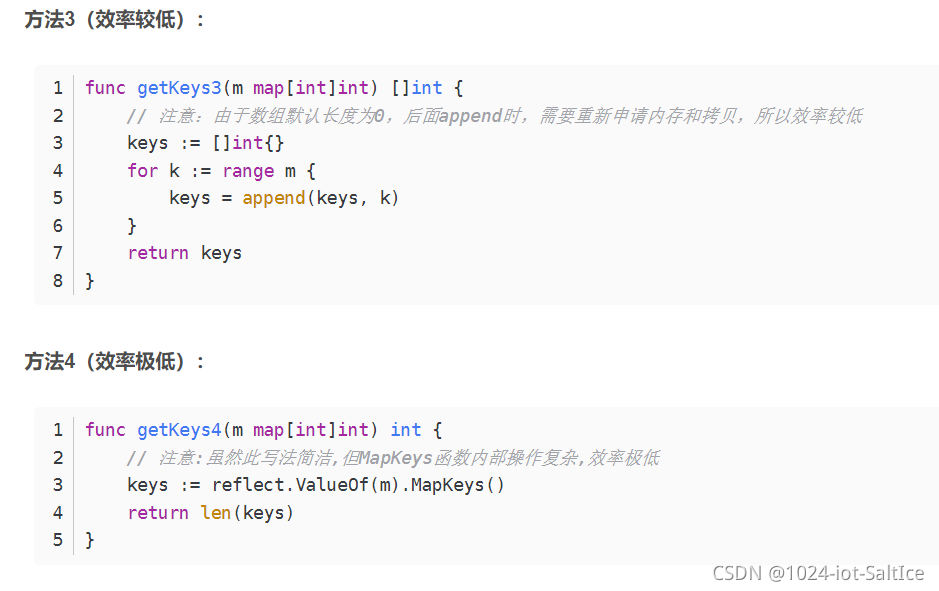
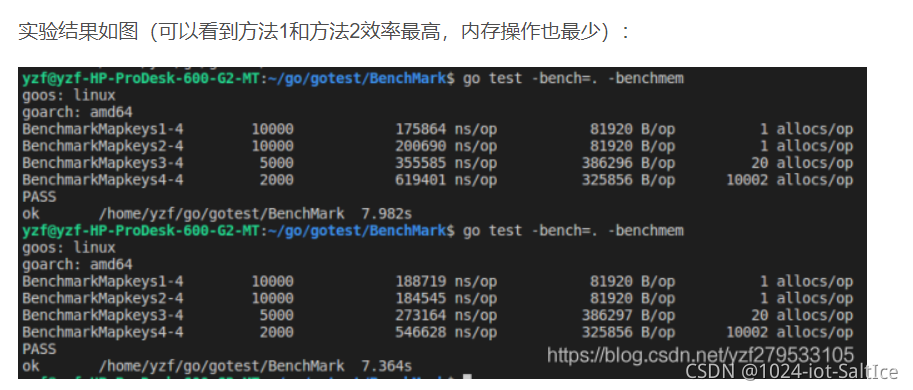
8.避免使用MapKeys获取map key值

9.复杂迭代 for 循环效率 > range 效率
主要是值拷贝的耗时情况

10.使用 []byte 当做 map 的 key
使用string作为 map 的 key 是很常见的,但有时你拿到的是一个[]byte。
编译器为这种情况实现特定的优化,编译器会避免将字节切片转换为字符串到map查找
var m map[string]string
v, ok := m[string(bytes)]
但,如果你这样写,编译器就不会优化
key := string(bytes)
val, ok := m[key]
11.数组复制 使用copy取代原数组操作

12.使用流式 IO 接口
尽可能避免将数据读入[]byte并传递使用它。
根据请求的不同,你可能会将兆字节(或更多)的数据读入内存。这会给GC带来巨大的压力,并且会增加应用程序的平均延迟。
这种情况最好使用io.Reader和io.Writer构建数据处理流,以限制每个请求使用的内存量。
如果你使用了大量的io.Copy,那么为了提高效率,可以考虑实现io.ReaderFrom/io.WriterTo。 这些接口效率更高,并避免将内存复制到临时缓冲区。
13.超时,超时,还是超时
永远不要在不知道需要多长时间才能完成的情况下执行 IO 操作。
你要在使用SetDeadline,SetReadDeadline,SetWriteDeadline进行的每个网络请求上设置超时。
您要限制所使用的阻塞IO的数量。 使用 goroutine 池或带缓冲的 channel 作为信号量。
var semaphore = make(chan struct{}, 10)
func processRequest(work *Work) {
semaphore <- struct{}{} // 持有信号量
// 执行请求
<-semaphore // 释放信号量
}
另类手段
1. golink
**golink**在官方的文档里有介绍,使用格式:
//go:linkname FastRand runtime.fastrand
func FastRand() uint32
主要功能就是让编译器编译的时候,把当前符号指向到目标符号。上面的函数FastRand被指向到runtime.fastrand
runtime包生成的也是伪随机数,和math包不同的是,它的随机数生成使用的上下文是来自当前goroutine的,所以它不用加锁。正因如此,一些开源库选择直接使用runtime的随机数生成函数。性能对比如下:
Benchmark_MathRand-12 84419976 13.98 ns/op
Benchmark_Runtime-12 505765551 2.158 ns/op
还有很多这样的例子,比如我们要拿时间戳的话,可以标准库中的time.Now(),这个库在会有两次系统调用runtime.walltime1和runtime.nanotime,分别获取时间戳和程序运行时间。大部分场景下,我们只需要时间戳,这时候就可以直接使用runtime.walltime1。性能对比如下:
Benchmark_Time-12 16323418 73.30 ns/op
Benchmark_Runtime-12 29912856 38.10 ns/op
同理,如果我们需要统计某个函数的耗时,也可以直接调用两次runtime.nanotime然后相减,不用再调用两次time.Now,go:linkname需要引入unsafe包,并且目录下要有.s文件
//go:linkname nanotime1 runtime.nanotime1
func nanotime1() int64
func main() {
defer func( begin int64) {
cost := (nanotime1() - begin)/1000/1000
fmt.Printf("cost = %dms \n" ,cost)
}(nanotime1())
time.Sleep(time.Second)
}
运行结果:cost = 1000ms
系统调用在 go 里面相对来讲是比较重的。runtime会切换到g0栈中去执行这部分代码,time.Now方法在go<=1.16中有两次连续的系统调用。
不过,go 官方团队的 lan 大佬已经发现并提交优化**pr**。优化后,这两次系统调将会合并在一起,减少一次g0栈的切换。
g0栈切换背景可以参考GMP调度相关知识,不再赘述
linkname 为我们提供了一种方法,可以直接调用 go 标准库里的未导出方法,可以读取未导出变量。使用时要注意 go 版本更新后,是否有兼容问题,毕竟 go 团队并没有保证这些未导出的方法变量后续不会变更。
还有一些其他奇奇怪怪的用法:
- **reflect2**包,创建
reflect.typelinks的引用,用来读取所有包中struct的定义 - 创建
panic的引用后,用一些hook函数重定向panic,这样你的程序panic后会走到你的自定义逻辑里 runtime.main_inittask保存了程序初始化时,init函数的执行顺序,之前版本没有init过程 debug 功能时,可以用它来打印程序init调用链。最新版本已经有官方的调试方案:GODEBUG=inittracing=1开启initruntime.asmcgocall是cgo代码的实际调用入口。有时候我们可以直接用它来调用cgo代码,避免goroutine切换,具体会在cgo优化部分展开
2. log-函数名称行号的获取
虽然很多高性能的日志库,默认都不开启记录行号。但实际业务场景中,我们还是觉得能打印最好。
在**runtime**中,函数行号和函数名称的获取分为两步:
runtime回溯goroutine栈,获取上层调用方函数的的程序计数器(pc)。- 根据 pc,找到对应的
funcInfo,然后返回行号名称
经过 pprof 分析。第二步性能占比最大,约 60%。针对第一步,我们经过多次尝试,并没有找到有效的办法。但是第二步很明显,我们不需要每次都调用runtime函数去查找pc和函数信息的,我们可以把第一次的结果缓存起来,后面直接使用。这样。第二步约 60%的消耗就可以去掉。
var(
m sync.Map
)
func Caller(skip int)(pc uintptr, file string, line int, ok bool){
rpc := [1]uintptr{}
n := runtime.Callers(skip+1, rpc[:])
if n < 1 {
return
}
var (
frame runtime.Frame
)
pc = rpc[0]
if item,ok:=m.Load(pc);ok{
frame = item.(runtime.Frame)
}else{
tmprpc := []uintptr{
pc,
}
frame, _ = runtime.CallersFrames(tmprpc).Next()
m.Store(pc,frame)
}
return frame.PC,frame.File,frame.Line,frame.PC!=0
}
压测数据如下,优化后稍微减轻这部分的负担,同时消除掉不必要的内存分配。
BenchmarkCaller-8 2765967 431.7 ns/op 0 B/op 0 allocs/op
BenchmarkRuntime-8 1000000 1085 ns/op 216 B/op 2 allocs/op
3.cgo
cgo的支持让我们可以在 go 中调用c++和c的代码,但cgo的代码在运行期间不受 go 调度器的管理,为了防止cgo调用引起调度阻塞,cgo调用会切换到g0栈执行,并独占m。由于runtime设计时没有考虑m的回收,所以运行时间久了之后,会发现有cgo代码的程序,线程数都比较多。
用 go 的编译器转换包含cgo的代码:
go tool cgo main.go
转换后看代码,cgo调用实际上是由runtime.cgocall发起,而runtime.cgocall调用过程主要分为以下几步:
- entersyscall(): 保存上下文,标记当前 m
incgo独占m,跳过垃圾回收, - osPreemptExtEnter:标记异步抢占,使异步抢占逻辑失效
- asmcgocall:真正的 cgo call 入口,切换到
g0执行c代码 - 恢复之前的上下文,清理标记
对于一些简单的c函数,我们可以直接用asmcgocall调用,避免来回切换
package main
/*
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
struct args{
int p1,p2;
int r;
};
int add(struct args* arg) {
arg->r= arg->p1 + arg->p2;
return 100;
}
*/
import "C"
import (
"fmt"
"unsafe"
)
//go:linkname asmcgocall runtime.asmcgocall
func asmcgocall(unsafe.Pointer, uintptr) int32
func main() {
arg := C.struct_args{}
arg.p1 = 100
arg.p2 = 200
//C.add(&arg)
asmcgocall(C.add,uintptr(unsafe.Pointer(&arg)))
fmt.Println(arg.r)
}
压测数据如下:
BenchmarkCgo-12 16143393 73.01 ns/op 16 B/op 1 allocs/op
BenchmarkAsmCgoCall-12 119081407 9.505 ns/op 0 B/op 0 allocs/op
4.epoll
runtime对网络 io,以及定时器的管理,会放到自己维护的一个 epoll 里,具体可以参考runtime/netpool。在一些高并发的网络 io 中,有以下几个问题:
- 需要维护大量的协程去处理读写事件
- 对连接的状态无感知,必须要等待
read或者write返回错误才能知道对端状态,其余时间只能等待 - 原生的
netpool只维护一个epoll,没有充分发挥多核优势
基于此,有很多项目用x/unix扩展包实现了自己的基于 epoll 的网络库,比如潘神的**gnet,还有字节跳动的netpoll**。
在我们的项目中,也有尝试过使用。最终我们还是觉得基于标准库的实现已经足够。理由如下:
- 用户态的
goroutine优先级没有 gonetpool的调度优先级高。带来的问题就是毛刺多了。近期字节跳动也开源了自己的netpool,并且通过优化扩展包内epoll的使用方式来优化这个问题,具体效果未知 - 效果不明显,我们绝大部分业务的 QPS 主要受限于其他的 RPC 调用,或者 CPU 计算。收发包的优化效果很难体现。
- 增加了系统复杂性,虽然标准库慢一点点,但是足够稳定和简单。
5.包大小优化
我们 CI 是用蓝盾流水线实现的,有一次业务反馈说蓝盾编译的二进制会比自己开发机编译的体积大 50%左右。对比了操作系统和 go 版本都是一样的,tlinux2.2 golang1.15。我们在用 linux 命令size —A对两个文件各个section做对比时,发现了debug相关的section size明显不一致,而且section的名称也不一样:
size -A test-30MB
section size addr
.interp 28 4194928
.note.ABI-tag 32 4194956
... ... ... ...
.zdebug_aranges 1565 0
.zdebug_pubnames 56185 0
.zdebug_info 2506085 0
.zdebug_abbrev 13448 0
.zdebug_line 1250753 0
.zdebug_frame 298110 0
.zdebug_str 40806 0
.zdebug_loc 1199790 0
.zdebug_pubtypes 151567 0
.zdebug_ranges 371590 0
.debug_gdb_scripts 42 0
Total 93653020
size -A test-50MB
section size addr
.interp 28 4194928
.note.ABI-tag 32 4194956
.note.go.buildid 100 4194988
... ... ...
.debug_aranges 6272 0
.debug_pubnames 289151 0
.debug_info 8527395 0
.debug_abbrev 73457 0
.debug_line 4329334 0
.debug_frame 1235304 0
.debug_str 336499 0
.debug_loc 8018952 0
.debug_pubtypes 1072157 0
.debug_ranges 2256576 0
.debug_gdb_scripts 62 0
Total 113920274
通过查找debug和zdebug的区别了解到,zdebug是对debug段做了zip压缩,所以压缩后包体积会更小。查看**go 的源码**,发现链接器默认已经对debug段做了zip压缩。
看来,未压缩的debug段不是 go 自己干的。我们很容易就猜到,由于代码中引入了cgo,可能是c++的链接器没有压缩导致的。
代码引入
cgo后,go 代码由 go 编译器编译,c 代码由g++编译,后续由ld链接成可执行文件。所以包含cgo的代码在跨平台编译时,需要更改对应平台的 c 代码编译器,链接器。具体过程可以翻阅 go 编译过程相关资料,不再赘述。
但是我们再次寻找相关**源码**发现,go 在使用ld链接时,已经指定了参数--compress-debug-sections=zlib-gnu用来压缩debug相关信息。
再次寻找原因,我们猜测可能跟tlinux2.2支持go 1.16有关,之前我们发现升级 go 版本之后,在开发机上无法编译。最后发现是因为go1.16优化了一部分编译指令,导致我们的ld版本太低不支持。所以我们用yum install -y binutils升级了ld的版本。果然,在翻阅了ld的文档之后,我们确认了tlinux2.2自带的ld不支持--compress-debug-sections=zlib-gnu这个指令,升级后ld才支持。
总结:在包含cgo的代码编译时,将ld升级到2.27版本,编译后的体积可以减少约 50%。
6.simd
首先,go 链接器支持 simd 指令,但 go 编译器不支持simd指令的生成。所以在 go 中使用simd一般来说有三种方式:
- 手写汇编
llvmcgo(如果用cgo的方式来调用,会受限于cgo的性能,达不到加速的目的)
目前比较流行的做法是llvm:
- 用
c来写simd相关的函数,然后用llvm编译成 c 汇编 - 用工具把 c 汇编转换成 go 的汇编格式,保存为
.s文件 - 在 go 中调用
.s里的方法,最后用 go 编译器编译
以下开源库用到了 simd,可以参考:
合理的使用simd可以充分发挥 cpu 特性,但是存在以下弊端:
- 难以维护,要么需要懂汇编的大神,要么需要引入第三方语言
- 跨平台支持不够,需要对不同平台汇编指令做适配
- 汇编代码很难调试,作为使用方来讲,完全黑盒
7.jit
go 中使用 jit 的方式可以参考**Writing a JIT compiler in Golang**
目前只有在字节跳动刚开源的json解析库中发现了使用场景**sonic**
这种使用方式个人感觉在 go 中意义不大,仅供参考
总结
过早的优化是万恶之源,千万不要为了优化而优化
- pprof 分析,竞态分析,逃逸分析,这些基础的手段是必须要学会的
- 常规的优化技巧是比较实用的,他们往往能解决大部分的性能问题并且足够安全。
- 在一些着重性能的基础库中,使用一些非常规的优化手段也是可以的,但必须要权衡利弊,不要过早放弃可读性,兼容性和稳定性。
参考:
- https://zhuanlan.zhihu.com/p/403417640
- https://github.com/geektutu/high-performance-go
- https://mp.weixin.qq.com/s/i0bMh_gLLrdnhAEWlF-xDw
- https://github.com/sxs2473/go-performane-tuning/blob/master/5.%E6%8A%80%E5%B7%A7/%E6%8A%80%E5%B7%A7.md
- https://www.jianshu.com/p/662c8f8e5740


















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









