






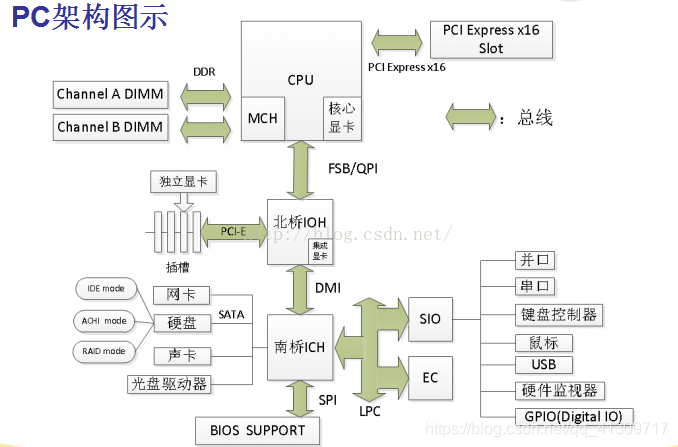
ICH(I/O controller hub意思是“输入/输出控制器中心”,负责连接PCI总线,IDE设备,I/O设备等,是英特尔的南桥芯片系列名称
BIOS(basic input output system):基础输入输出系统。
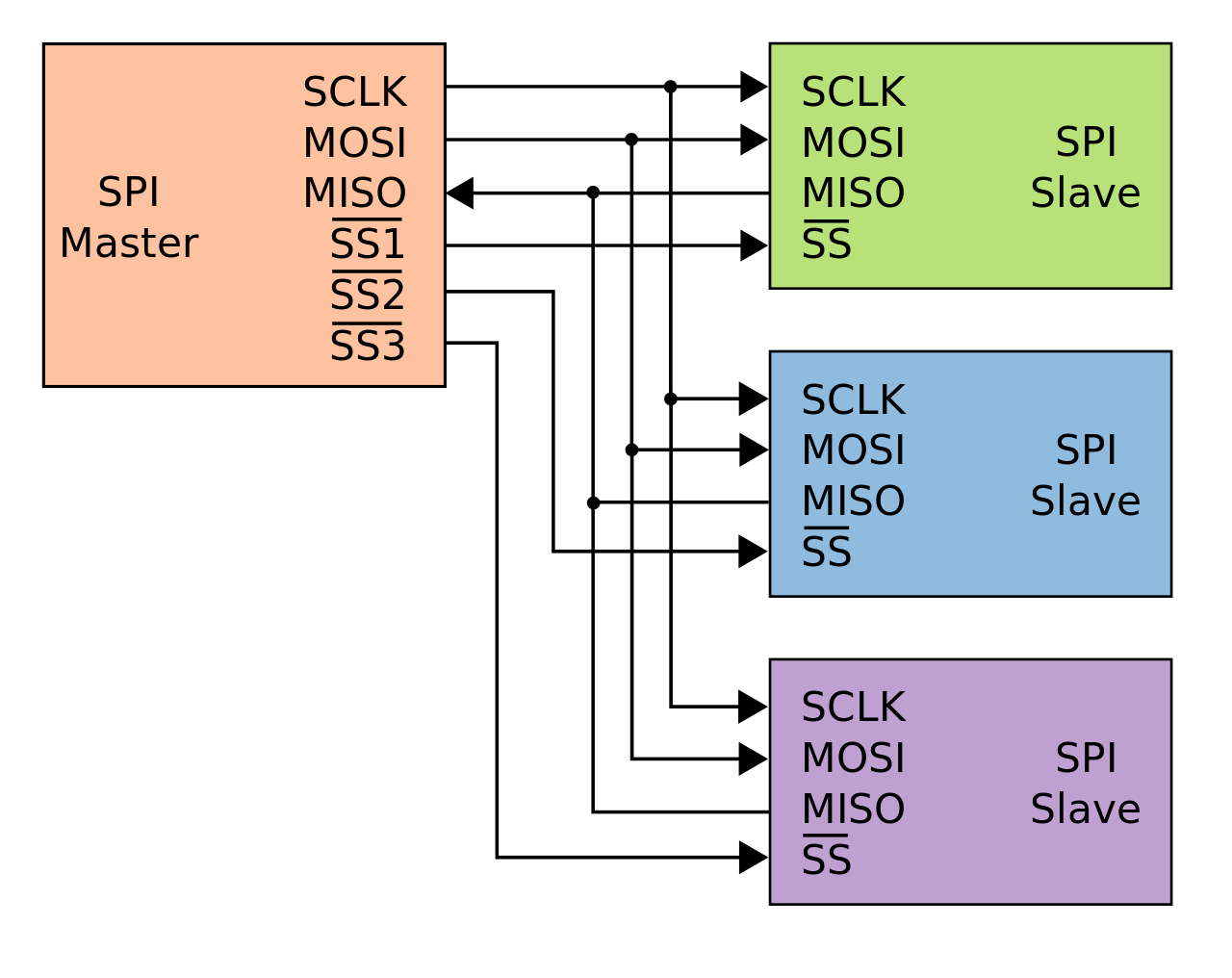
SPI(Serial Peripheral Interface BUS):串行外设备接口,是一种用于短程通信的同步串行接口规范,SPI设备之间使用全双工通信,一个主机多个从机的主从模式通信。主机产生待读或者待写的帧数据,多个从机通过一个片选(chip select)线路决定那个来响应主机的请求。原理如下图所示
SIO:超级IO,连接鼠标usb等外接设备
LPC(Low pin count Bus):是在IBM PC兼容机中用于把低带宽装置,尤其是Super I/o装置连接到CPU上。这些常见的低速设备有:BIOS,串口,并口,PS/2界面的键盘和鼠标,软驱控制器,TPM。LPC通常和主板上的南桥相连接。
SATA(Serial ATA: Serial Advanced Technology Attachment)是一种计算机总线,负责主板和大容量存储设备(如硬盘及光盘驱动器)之间的数据传输,主要用于个人计算机。串行ATA与串列SCSI(SAS: Serial Attached SCSI)的两者排线兼容,SATA硬盘可接上SAS接口。
DMI(Direct Media Interface):直接媒体接口,DMI是Intel(英特尔)公司开发用于连接主板南北桥的总线,取代了以前的Hub-Link总线。DMI采用点对点的连接方式,时钟频率为100MHz,由于它是基于PCI-Express总线,同样采用8bit/10bit(有效位宽8bit)编码因此具有PCI-E总线的优势。
IOH(Input Output Hub),也就是传统意义上部分北桥的功能,通过QPI总线与CPU相连,下方使用DMI总线连接南桥ICH芯片,主要负责I/O总线的传输,它同时提供了很多PCI-E 2.0总线连接作为标准的I/O接口。
FSB(Front Side Bus):是将CPU连接到北桥芯片的总线
QPI:由于FSB不够用,设计上先天不足(这个时候的内存控制器在北桥芯片组内,CPU和内存交换数据总要通过北桥,相当于两个人说话,总要通过第三方,很不方便),因此intel想了个办法,把内存控制器做到了CPU内部,让CPU通过PQI总线直接和内存通讯,不再通过北桥芯片组,这很明显加快了速度
MCH(memory controller hub):内存控制器中心负责连接CPU,AGP总线和内存。
DDR(Double Data Rat):双倍速率,DDR SDRAM=双倍速率同步动态随机存储器,人们习惯称为DDR,其中,SDRAM 是Synchronous Dynamic Random Access Memory的缩写,即同步动态随机存取存储器。而DDR SDRAM是Double Data Rate SDRAM的缩写,是双倍速率同步动态随机存储器的意思。DDR内存是在SDRAM内存基础上发展而来的,仍然沿用SDRAM生产体系,因此对于内存厂商而言,只需对制造普通SDRAM的设备稍加改进,即可实现DDR内存的生产,可有效的降低成本。
PCI-Express(peripheral component interconnect express):是一种高速串行计算机扩展总线标准,它原来的名称为“3GIO”,是由英特尔在2001年提出的,旨在替代旧的PCI,PCI-X和AGP总线标准。

















 6883
6883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









