







flink实时流学习项目介绍:
目前在个某市商业银行做实时数据展示、数据处理;项目中使用到flink框架,进行数据加工处理。针对使用到的几个业务场景,和目前学习的flink阶段自己搭建了一个实时数据加工的处理项目。
目前处在学习、整理、分享的阶段,并不具备成型、系统的理念;本次介绍的是,在flink进行数据格式的转换,为数据的统计、对比、计算奠定基础。
使用maven构建进行项目管理,idea开发工具、JDK1.8的java环境、数据包采用的某培训机构使用的温度传感器模拟数据sensor.txt数据文件包。该项目已上传到码云,项目地址是:flink项目地址, https://gitee.com/wuzheyi520/flink_java_api_test.git
问题描述:
flink通过source加载的数据,一般是通过DataStream进行的数据接收;较早版本的flink使用的scala,java语言的示例比较少,所以就写一篇记录,供自己以后进行查阅;也分享出来,给需要的人使用。
一、项目目录结构:
项目目录结构如下图所示,目前只是对单个API进行介绍,所以写在不同main函数中,便于进行数据的调试、加工处理;划线的地方分别是:java类,数据文件。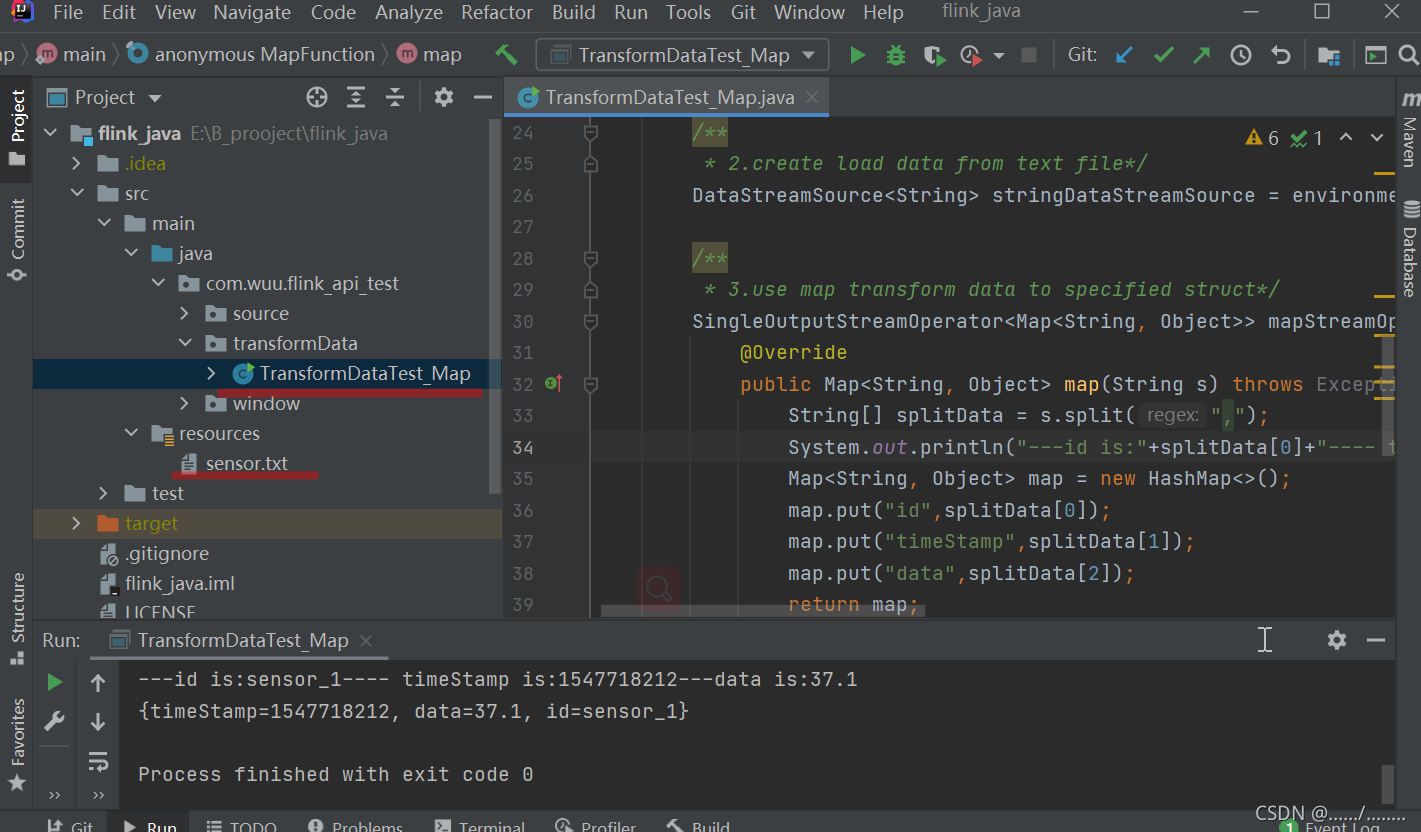
二、TransformDataTest_Map 类中的代码:
这里直接给出类中全部的代码,可以直接运行main函数,查看数据格式的转换。
1.其中readTextFile方法是加载数据源中的数据,该种方式能够减少搭建kafka的工作量,方便演示。
DataStreamSource<String> stringDataStreamSource = environment.readTextFile(filePath);
2.通过DataStream.map()方法进行数据格式的转换,在该方法中,通过MapFunction进行处理,重写类中的方法。其中MapFunction<String,Map<String,Object>>该方法中的第1个类型String,表示数据的输入类型,也就是DataStream<T>中的类型T;第2个类型Map<Stirng,Object>表示的是:目标类型,也可以是自定义类。
/**
*MapFunction(){},是转换成单条数据,
*FlatMapFunction(){},是将数据放到一个Collection集合中进行返回*/
SingleOutputStreamOperator<Map<String, Object>> mapStreamOperator = stringDataStreamSource.map(new MapFunction<String, Map<String, Object>>() {
@Override
public Map<String, Object> 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1110
1110











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









