







关系
bert是unsupervise-train 的transformer
transformer是seq2seq model with “self-attention”

- RNN:不能并行运算,得到b4之前要先算b3,但b4能结合前面的信息。
- CNN:能同时处理a1至a4的word vector。但对于前面的层,filter只能扫描一部分词语,后面的层才能结合更长的词语。
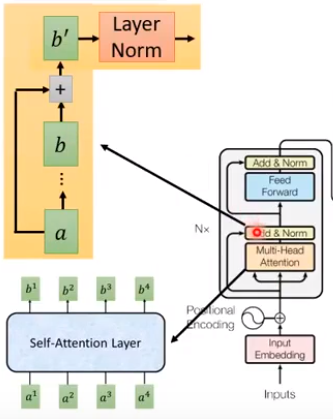
- Self-attention Layer的出现就是为了替代RNN,它的目的与RNN一样:input一个sequence,output一个sequence。优势:(1)b1至b4同时计算(2)能力与bi-RNN相等。
- 结论:you can try to replace any thing that has been done by RNN with self-attention.
self-attention
组成

- x1…x4:word sequence,这里假设4个词汇。
- a1…a4:word embedding,即将input乘上一个metric。李宏毅说这是type step。
- Q、K、V:由a分别乘上metric W q W^q Wq、 W k W^k Wk、 W v W^v Wv得到,这里a总共需要进行3*4=12次矩阵变换。
- Q:匹配其他词; K:被匹配的词; V:存储了词与词之间的信息。
结构
- step1
关于attention有各种各样的算法,思想是输入两个向量,输出一个分数,分数告诉我们这两个向量有多匹配。

q1要对k1…k4分别做attention得到 α 1 , 1 α_{1,1} α1,1… α 1 , 4 α_{1,4} α1,4,共有4*4=16个。公式如上图,但论文没有提到公式不一致会有何影响。q和k的形状相同,d用点积来控制大小。 - step2
α 1 , 1 α_{1,1} α1,1、 α 1 , 2 α_{1,2} α1,2、 α 1 , 3 α_{1,3} α1,3、 α 1 , 4 α_{1,4} α1,4四个vector进行softmax function。得到 α ^ 1 , 1 \hat{α}_{1,1} α^1,1、 α ^ 1 , 2 \hat{α}_{1,2} α^1,2、 α ^ 1 , 3 \hat{α}_{1,3} α^1,3、 α ^ 1 , 4 \hat{α}_{1,4} α^1,4,我感觉是标量。

- step3
α ^ 1 , 1 \hat{α}_{1,1} α^1,1… α ^ 1 , 4 \hat{α}_{1,4} α^1,4分别与v1…v4相乘,得到vector b1。b1 considering the whole sequence。


b1可以通过权值来控制,可以忽略远处,只考虑local information;也可以考虑global information。
- step4
同理并同时可算出output sequence的第2,3,4个vector b2,b3,b4。

实际运算中我们将a1…a4合并成矩阵,进行并行运算。从下图中可以看出, W q W^q Wq对于a1…a4是共享的。

q和k先点乘再除以根号d

A就是attention矩阵,每个type step(input sequence中每个位置)两两之间都有attention。A的大小由input sequence决定。

V:d * 4 A ^ \hat{A} A^:4 * 4 O O O:就是attention layer的输出。

延伸
普通的self-attention

Multi-head self-attention


- Multi-head指的是将 q i q^i qi进行矩阵变换分成 q i , 1 q^{i,1} qi,1(head1)和 q i , 2 q^{i,2} qi,2(head2)。
- q i , 1 q^{i,1} qi,1只与head1的K进行内积得到 b i , 1 b^{i,1} bi,1, q i , 2 q^{i,2} qi,2只与head2的K进行内积得到 b i , 2 b^{i,2} bi,2。
- 将
b
i
,
1
b^{i,1}
bi,1和
b
i
,
2
b^{i,2}
bi,2拼接(concatenate),可以通过矩阵变换
W
o
W^o
Wo得到想要的维度
b
i
b^i
bi。
Multi-head的作用
如果只有一个head就是原始的self-attention。多个head,有的可以关注local,有的可以关注global。
Positional Encoding
self-attention layer的问题:每个type step两两之间都有attention,那么词语的顺序就没有利用到,即a->b和b->a的attention是一样的,只需位置不同。

in other word:解释为什么要
e
i
e^i
ei+
a
i
a^i
ai,是相加,而不是拼接。我们需要位置信息,很明显
p
i
p^i
pi有这个信息。通过拼接
x
i
x^i
xi与
p
i
p^i
pi,然后进行矩阵变换,
W
p
W^p
Wp *
p
i
p^i
pi就等同于
e
i
e^i
ei。李宏毅说,
W
p
W^p
Wp可以训练,也有人工设置。(没细讲)
seq2seq with attention
seq2seq model
input:x1…x4,output:o1…o3;应用:翻译器…
x1…x4 ——>Encoder(bi-RNN、self-attention Layer)——>h1…h4
c1…c3——>Decoder(bi-RNN、self-attention Layer)——>o1…o3

视频中有展示google描述encoder-decoder的动态图,图中信息有
(1)attention-layer不止一层,encoder同一层是并行计算的
(2)decoder是按序列输出的,非并行输出。
(3)decoder的输入为:encoder的全部输出值加上decoder已经输出的值,如decode第三个词时,输入是c1+c2+c3+c4+o1+o2。如果decoder layer是多层的,只是用同一层进行相加。即要输出O(2,3),3是层数,2是序列,则输入是c1+c2+c3+c4+O(2,1)+O(2,2)。
题外话—BN与LN
对于BN(针对二维卷积),通过查阅其他csdn,还有代码:
x_mean = np.mean(x, axis=(0, 2, 3), keepdims=True)
x_var = np.var(x, axis=(0, 2, 3), keepdims=True)
#x_shape:[B, C, H, W],它利用3个维度的数据得到一个维度的均值和方差
我的观点如图,对于一层CNN,batch里面的二维矩阵求一个均值,有多少层就有多少个均值。

李宏毅说法:假设batchszie=4,
BN:对于同一个batch=4里面的不同data的同样的dimension作normalization。下图中,使横条的均值为0,方差为1。
LN:与batch无关,对一个data的同一层作normalization,即竖条的均值为0,方差为1。

我也很迷,难道是编程与理论的差距吗?求救sos
Transformer
上图,熟悉又不熟悉,use Chinese to English translation as example。
左块是编码,右边块是解码。注意上述的信息(3),即decoder需要前一次decoder的输出,初始值为 <BOS>。

结构
- Add:将attention layer的输入a与输出b相加
- Norm:进行Layer Norm,LN多用于RNN网络
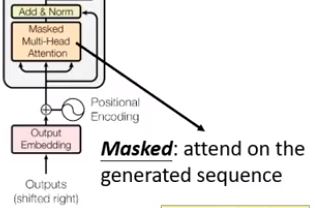
- Masked:因为attention矩阵A是由sequence的长度决定,包含了每个词两两之间的attention。因为decoder只会关注已经output的词,没有生成出来的词无法进行attention,所以要把没出现的词的位置进行mask(掩盖)掉。具体要看博客举的实例
李宏毅的视频到这了,流程介绍完,但是实际一点的例子却没有。接下来看看view数比较多的博客。感谢梁同学和宋同学关于transformer介绍,让我没那么懵逼。
博客
作者: 龙心尘
时间:2019年1月
出处:https://blog.csdn.net/longxinchen_ml/article/details/86533005
提炼
摘录
总体结构
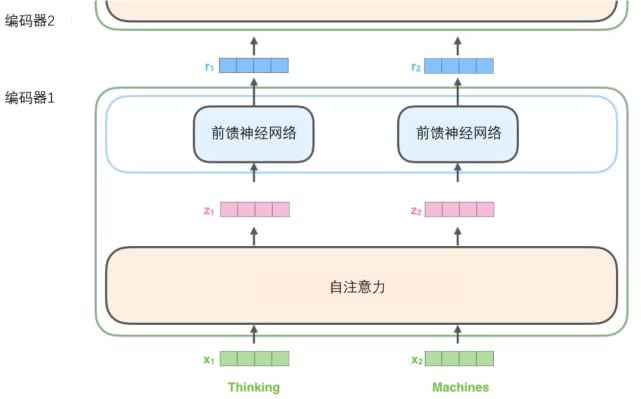
论文中是将6个编码器叠在一起,每个编码器不共享参数,且可以分解成两个子层:self-attention,feed-forward。
self-attention:帮助编码器在对每个单词编码时关注输入句子的其他单词。
feed-forward:每个位置的单词对应的前馈神经网络都完全一样。词于词之间没有依赖关系,所以可以并行执行。(一维卷积神经网络)
解码器在两层之间还有一个注意力层,用来关注输入句子的相关部分
Encoder输入—>输出
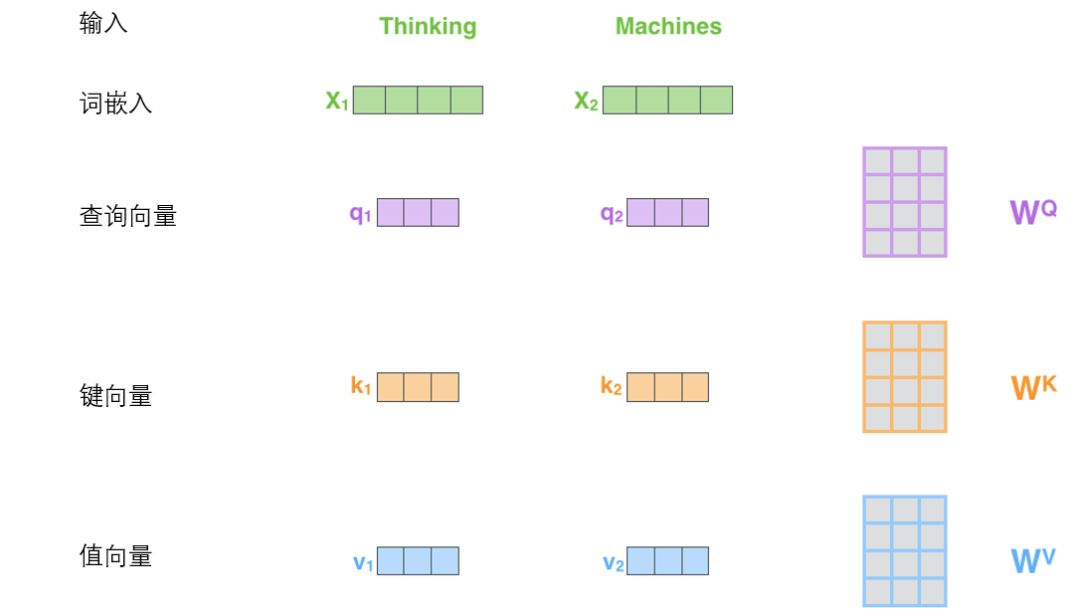
- 序列中的每个输入单词通过词嵌入算法转换为词向量,假设嵌入为512维的向量。编码器接受一个向量列表,列表中的每个向量大小为512维。向量列表大小是我们可以设置的超参数——一般是我们训练集中最长句子的长度。
- 每个词通过embedding得到词向量后,与三个权重矩阵相乘得到三个新向量Q,K,V。新向量在维度上比词向量更低。他们的维度是64,而词向量和编码器的输入/输出向量的维度是512。实际上不强求维度更小,这只是一种基于架构上的选择,它可以使multi-head self-attention的大部分计算保持不变。
- 需要拿输入句子中的每个单词对“Thinking”(某一个词)打分,这些分数决定了在编码单词“Thinking”的过程中有多重视句子的其它部分。Q与K做点积,再除以向量维度k的平方根,再通过softmax传递结果。 d k \sqrt{d_k} dk让梯度更稳定,softmax使所有单词的分数归一化,得到的分数都是正值且和为1。
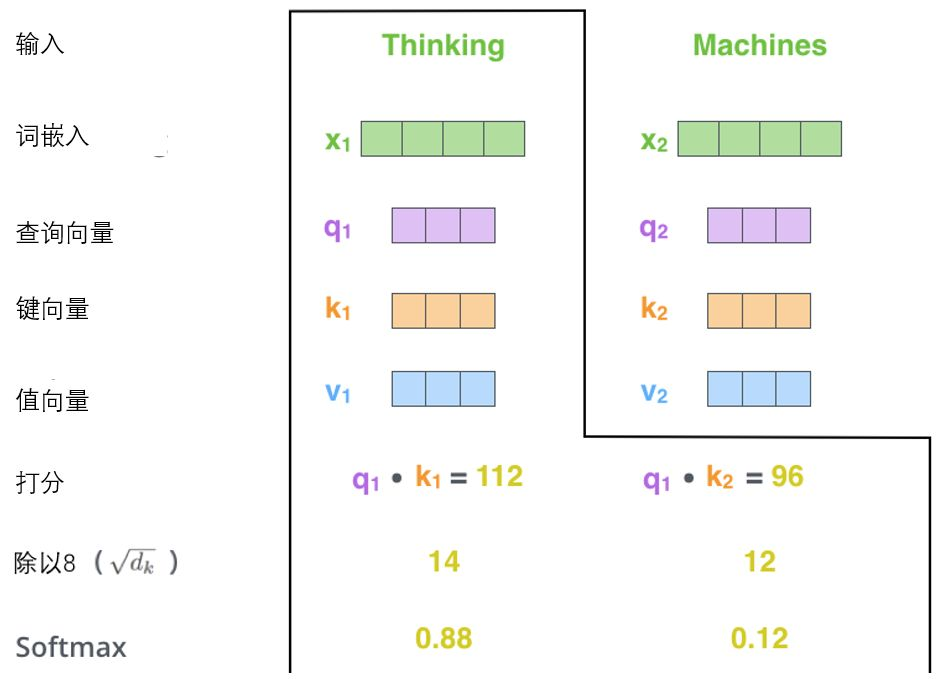
- 将每个向量V乘以softmax分数,分数的作用是关注语义上相关的单词,并弱化不相关的单词。然后对加权后的向量V求和,得到输出向量O。
自注意力机制
理论
The animal didn’t cross the street because it was too tired.
“it”在这个句子中代指那个名词?它指的是street还是animal还是others呢?
注意力的任务是允许“it”与“animal”建立联系。随着模型处理输入序列的每个单词,自注意力会关注整个输入序列的所有单词,帮助模型对本单词更好地进行编码。
与RNN区别:自注意力机制会将所有相关单词的理解融入到我们正在处理的单词中。

在编码器#5(栈中最上层编码器)中编码“it”这个单词的时,注意力机制的部分会去关注“The Animal”,将它的表示的一部分编入“it”的编码中。
矩阵计算
(1) 假设sequence只有两个词,词向量4个格子,QKV3个格子。

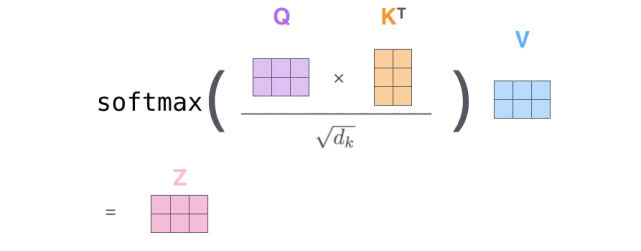
(2) 对于multi-head self-attention,有多个产生Q,K,V矩阵集weights,Transformer使用8个head(64*8=512),8个矩阵集合中的每一个weights都是随机初始化的,将词向量投影到不同的表示子空间中。

(3) self-attention的输出要传入前馈神经网络,所以需要把8个矩阵Z合并或压缩成一个矩阵。

位置编码表示序列的顺序 Positional Embedding
形式上是给词向量添加位置向量。位置向量遵循模型学习到的特定模式,这有助于确定每个单词的位置,或序列中不同单词之间的距离。大部分文章应该都没有给出位置向量怎么计算出来,李宏毅的间接解释有说服力一点

特定模式:每一行对应一个词向量的位置编码,所以第一行对应着输入序列的第一个词。每行包含512个值,每个值介于1和-1之间。
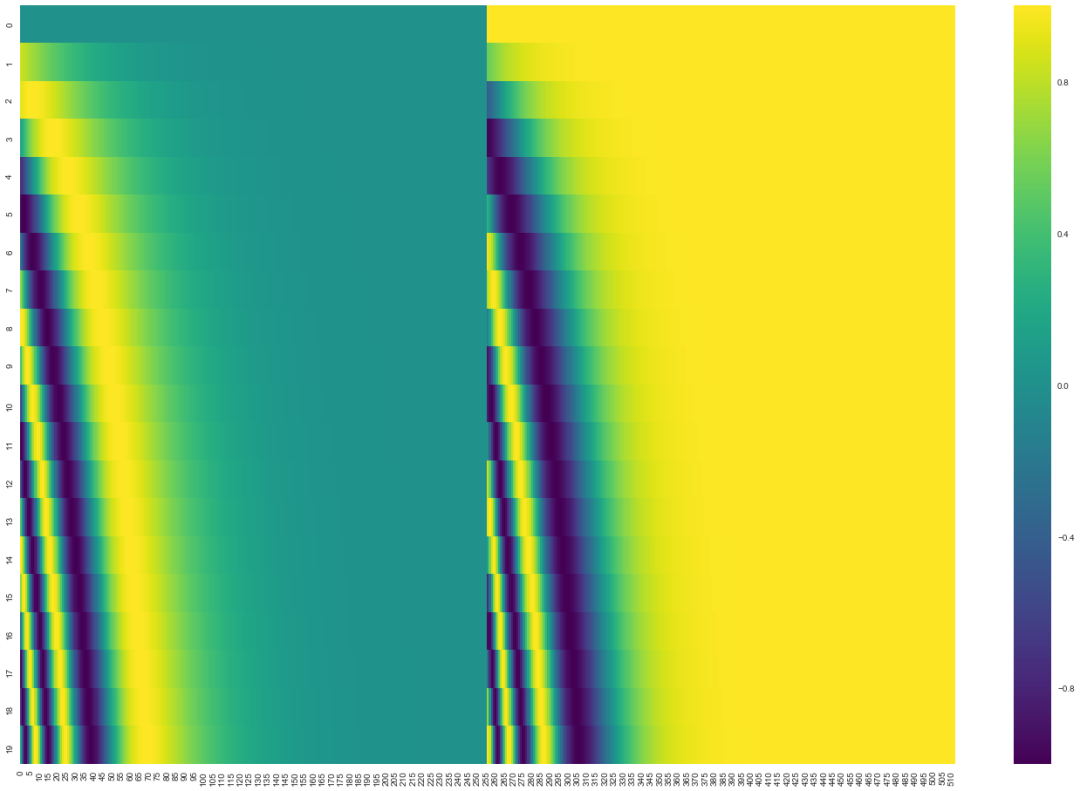
原始论文里描述了位置编码的公式(第3.5节)。你可以在 get_timing_signal_1d()中看到生成位置编码的代码。这不是唯一可能的位置编码方法。然而,它的优点是能够扩展到未知的序列长度(例如,当我们训练出的模型需要翻译远比训练集里的句子更长的句子时)。
Decoder部分
翻译过程
Decoder的第一次输入为起始符</s>的embedding + Positional Encoding,也可能是其他特殊的Token,目的是通过起始符预测“I”,也就是通过起始符预测实际的第一个输出。Shifted Right 意思是将输出整体右移一位。



- 从图中可以看出,encoder是一次性处理输入,decoder是按时间顺序根据前面的词输出预测的下一个词。
- 顶端编码器的输出之后会变转化为一个包含向量K(key向量)和V(value向量)的注意力向量集 。这两个向量会输入到每个decoder的第二层,即multi-head attention,该层有助于解码器能够关注到输入句子的相关部分。
- 解码器的第一层,即masked multi-head attention与第二层不同,因为在解码器中,自注意力层只被允许处理输出序列中已经预测的那些位置。在softmax步骤前,它会把后面的位置给隐去(把它们设为-inf)。
- 线性变换作用:将实数向量(浮点数)变成一个单词。它是一个简单的全连接神经网络,它可以把解码组件产生的向量投射到一个比它大得多的、被称作对数几率(logits)的向量里。如果单词表有一万个单词,对数几率向量为一万个单元格长度的向量——每个单元格对应某一个单词的分数。
- Softmax 层便会把那些分数变成概率,概率最高的单元格对应的单词被作为这个时间步的输出。
【1】csdn链接Mask部分
【2】知乎链接decoder部分,attention机制没细看
【3】csdn链接mask代码,内容少
其他博客1
decoder输入->输出
这里只针对李宏毅没讲的和decode与encoder的区别这两点进行补充:
训练过程中,我们有输出结果(要翻译的结果),仍记为 X = ( x 1 , . . . , x m ) T X = (x_1,...,x_m)^T X=(x1,...,xm)T,但与encoder的参数是不共享的。对X做embedding,词嵌入矩阵与输入此的词嵌入矩阵也是不同的。
Mask技术
Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask,Padding Mask可以看链接【1】。
sequence mask:
- 为了使decoder不能看见未来的信息。在 time_step 为 t 的时刻,解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。所以要把 t 之后的信息给隐藏起来,在训练的时候我们只能看到当前词之前的信息。
- 做法:产生一个上三角矩阵,上三角的值全为0,把这个矩阵作用在每一个序列上。

Mask Multi-head attention的输出值为Z,作为下一层Multi-head attention的Q的输入值
我感觉了解到这应该对transformer有一个完整的流程,在细节一点就要看代码了。
其他博客2
还有一篇知乎,关于数据的shape如何变幻。下面只描述新的点
https://zhuanlan.zhihu.com/p/44731789
他讲到embedding完成了将一句话变为一个矩阵,矩阵的每一行代表一个特定的单词,但他用xaviers方法生成随机映射矩阵。
(1)encoder中V=K=Q=matEnc,首先分别对V,K,Q三者分别进行线性变换,即将三者分别输入到三个单层神经网络层,激活函数选择relu,输出新的V,K,Q(三者shape都和原来shape相同,即经过线性变换时输出维度和输入维度相同);
(2)然后将Q在最后一维上进行切分为num_heads(假设为8)段,然后对切分完的矩阵在axis=0维上进行concat链接起来;

(3)最后将outputs在axis=0维上切分为num_heads段,然后在axis=2维上合并, 恢复原来Q的维度;

(4)feedForward:
对outputs进行第一次卷积操作,结果更新为outputs(卷积核为11,每一次卷积操作的计算发生在一个词对应的向量元素上,卷积核数目即最后一维向量长度,也就是一个词对应的向量维数);
对最新outputs进行第二次卷积操作,卷积核仍然为11,卷积核数目为N;


总结
对于大的模型,我的学习效率有点滴,搞这么久一点代码都还没看。视频50分钟…视频讲的肯定不够。提高效率就要知道模型哪一个知识点不清楚然后去看其他博客,不要重复去看已经了解的知识点。
正常路线应该是:视频->英文论文->博客(不一定正确)->代码的实现->分析代码
如果您看到这,希望您有所收获














 9056
9056











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









