










很多是用我们用到LCD显示的时候都会用到LCD取模软件,但是对于这个软件的具体使用方法,我相信大家都会使用,但是有一些细节点还不是很清楚,可能只是跟着人家怎么取模,自己也怎么取模。这篇文章将详细讲解这个取模软件的使用,并通过串口模拟LCD显示的原理,将字模打印出来。
实验平台STM32F103+Keil5
下载地址:PCto2002工具
一、使用串口模拟LCD显示原理打印字模
首先,我们需要使用PCtoLCD,进行汉字取模


然后,我们想通过串口打印出我们取到的字模。
实现这一步我们需要:
1、配置好串口。
2、将取到的字模使用数组存储起来。
3、编写字模解析函数void Print_char_16X16(void)。
其中字模解析函数原理,根据取到汉字的方法为1616的字模。我们需要遍历1616个像素点,如果像素点为1,我们通过“ * ”号显示,否则显示为空格。通过定义两个变量row、column,表示我们要用到的行和列。先通过for循环显示16行像素点。然后将每一行(16像素点)分为两个字节(1B = 8bit)。这样就可以遍历到一个字符的每个像素点。
费话不多少,上代码
//16*16
//16*16
uint8_t charer[] =
{
0x08,0x20,0x04,0x40,0x7F,0xFC,0x01,0x00,0x01,0x00,0x3F,0xF8,0x01,0x00,0x01,0x00,
0xFF,0xFE,0x01,0x00,0x01,0x00,0x7F,0xFC,0x02,0x80,0x04,0x40,0x18,0x30,0xE0,0x0E/*"美",0*/
};
//16*16字模
void Print_char_16X16(void)
{
uint16_t row,column;//定义行和列
uint8_t ch = 0;
//1、16行字符
for(row = 0; row <16 ; row++)
{
for(column = 0; column <8 ;column++) //每行中第一个字节(每字节8bit)
{
ch = (charer[row*2+0]<<column); //第一个字节对应字符
if((ch & 0x80) == 0) //如果相与为0 则打印空格表示无效数据 ,否则打印 * 表示有效数据
{
printf(" ");
}else{
printf("*");
}
}
for(column = 0; column <8 ;column++)
{
ch = (charer[row*2+1]<<column); //第二个字节对应字符
if((ch & 0x80) == 0) //如果相与为1 则打印*表示有效数据 ,否则打印空格 表示无效数据
{
printf(" ");
}else{
printf("*");
}
}
printf("\r\n"); //一行数据处理完成,换行
}
}
int main(void)
{
/*初始化USART 配置模式为 115200 8-N-1,中断接收*/
USART_Config();
printf("通过串口打印LCD取模显示原理\r\n");
printf("\r\n");
Print_char_16X16();
while(1)
{
}
}
实验效果:

家伙事都准备好了,接下来准备上才艺。

二、点阵格式(阴码与阳码)

点击界面选项(箭头1),会弹出第二界面的相关信息,我们找到点阵格式(箭头2)。
阴码、阳码:指字模点阵中有笔迹像素位的状态是“1”还是“0”。比如上面显示的美,使用的阴码取法,此时我们使用阳码取法,看看效果怎么样
//16*16
uint8_t charer[] =
{
#if 0 //阴码
0x08,0x20,0x04,0x40,0x7F,0xFC,0x01,0x00,0x01,0x00,0x3F,0xF8,0x01,0x00,0x01,0x00,
0xFF,0xFE,0x01,0x00,0x01,0x00,0x7F,0xFC,0x02,0x80,0x04,0x40,0x18,0x30,0xE0,0x0E/*"美",0*/
#endif
//阳码
0xF7,0xDF,0xFB,0xBF,0x80,0x03,0xFE,0xFF,0xFE,0xFF,0xC0,0x07,0xFE,0xFF,0xFE,0xFF,
0x00,0x01,0xFE,0xFF,0xFE,0xFF,0x80,0x03,0xFD,0x7F,0xFB,0xBF,0xE7,0xCF,0x1F,0xF1/*"美",0*/
};

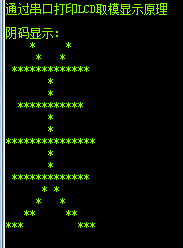
是不是太美了,难以直视。我们可以看到,有汉字笔迹的地方为空(我们想显示的),根据选择的阴码、阳码不同,所取的字模像素位状态也不同。
三、取模方式

取模方式:指字模图形的扫描方向,对此部分进行修改后,会在右侧取模演示中,有相应的动画演示。动画显示其实很详细,把它的原理体现的淋漓尽致。
为了体验取模方式到底如何,我们其他参数不变(“美”,“16*16“,”阴码“,“顺向”),分别取不同的取模方式,然后通过串口打印出来,看看效果如何。


这四种方式的“美”,我简称天涯四美。
其实上面的工程是串口以逐行式进行编写的。对于逐列,行列式、列行式显示是不正常的。需要重新编写对应的解析函数。如果使用LCD的话,可以通过设置液晶LCD的参数去设置对应的扫描方向显示。
四、取模走向

逆向:低位在前,如果是逐行式取模方式,是一行一行的以最低位开始,向最高位进行扫描(可对应取模软件的动画显示理解)
顺向:高位在前。
对于本工程的串口打印函数。如果使用逆向,即低位在前,需要将解析函数中修改为 字符数组右移,对0x01相与。
for(row = 0; row <16 ; row++)
{
for(column = 0; column <8 ;column++) //每行中第一个字节(每字节8bit)
{
ch = (charer[row*2+0]>>column); //第一个字节对应字符,没处理完一位,需要右移处理下一位
if((ch & 0x01) == 0) //逆向,低位在前,所以与0x01 (0000 0001)相与 /
{
printf(" ");
}else{
printf("*");
}
}
for(column = 0; column <8 ;column++)
{
ch = (charer[row*2+1]>>column); //第二个字节对应字符
if((ch & 0x01) == 0) //逆向,低位在前,所以与0x01 (0000 0001)相与
{
printf(" ");
}else{
printf("*");
}
}
printf("\r\n"); //一行数据处理完成,换行
}
五、字模大小设置
我们要设置88、1616、2424的字模大小时,需要设置三个地方,如下图:

比如我们设置1616字体大小。对应箭头1、2、3处就要设置为16
六、自定义格式输出
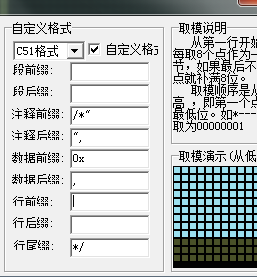
我们可以根据自己想要的格式,对字模输出部分进行自定义。
1、段前缀、段后缀。
我们设置段前缀:a。段后缀:b。
显示如下:
a
0x10,0x04,0x20,0x02,0xFE,0x3F,0x80,0x00,0x80,0x00,0xFC,0x1F,0x80,0x00,0x80,0x00
0xFF,0x7F,0x80,0x00,0x80,0x00,0xFE,0x3F,0x40,0x01,0x20,0x02,0x18,0x0C,0x07,0x70/*"美",0*/
b
2、注释前缀、注释后缀
我们设置 注释前缀:/*" 注释后缀 ",
a
0x10,0x04,0x20,0x02,0xFE,0x3F,0x80,0x00,0x80,0x00,0xFC,0x1F,0x80,0x00,0x80,0x00
0xFF,0x7F,0x80,0x00,0x80,0x00,0xFE,0x3F,0x40,0x01,0x20,0x02,0x18,0x0C,0x07,0x70 c美d0*/
b
这部分我们一般不更改,默认注释前缀:/*" 注释后缀 ",
3、数据前缀、数据后缀
如果我们需要输出十六进制数,假如为0xFF。则数据前缀:0x (修饰数据格式) 数据后缀:,(将每一个数据隔开)
4、行前缀、行后缀、行尾缀
我们设置行前缀:eee 行后缀:fff 行尾缀:ggg 便于观察
a
eee0x10,0x04,0x20,0x02,0xFE,0x3F,0x80,0x00,0x80,0x00,0xFC,0x1F,0x80,0x00,0x80,0x00fff
eee0xFF,0x7F,0x80,0x00,0x80,0x00,0xFE,0x3F,0x40,0x01,0x20,0x02,0x18,0x0C,0x07,0x70fff/*" 美 ",0ggg
b
我们一般将行前缀设置为空,行后缀设置为空,行尾缀设置为*/
//-------------------------------------------------未完待续:2020.05.17----------------------------------------------------
续:
2021.01.06
今天做了一个stm8驱动IIC OLED0.96的小物件,需要用到字符集,上面介绍的是汉字取模,并没有提到生成ASCII字符点阵集。看了原子哥的oled,只有字符集,没有取模过程(我也想白嫖,想直接知道方法,然后生成就完事了,找了文档教程,木得,又找了视频,原子哥居然说涉及版权,不多做介绍,淦,小丑竟是我)只能默默自己再回忆一下怎么使用PCtoLCD2002,然后生成字符集。
首先我想生成这样的:
!"#$%&'()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ[\]^_`abcdefghijklmnopqrstuvwxyz{|}~
(记住,!之前是空格)。这些都是常用的ASCII字符。
方法一:在字符输入处,输入要生成的字符集
不要超过100个字符:



生成一致。
方法二:通过txt文档,导入生成字模(可超过100个字符限制)
1、在txt文档中输入要生成的字符集

2、导入TXT文档。


//-------------------------------------------------未完待续:2021.01.06----------------------------------------------------
















 2059
2059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











