







文章目录
【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
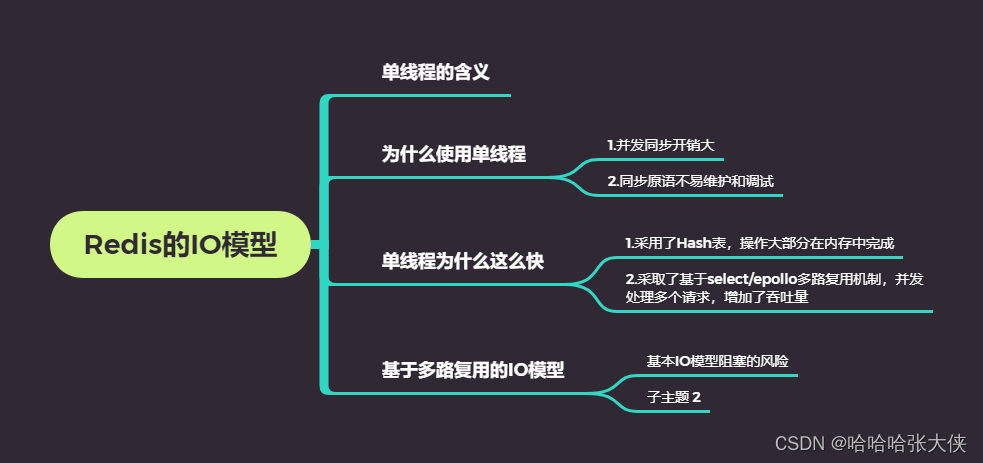
首先,先回顾下什么是I/O模型
I/O模型设计:
概念:网络请求的解析,以及数据存取的处理,是用一个线程、多个线程,还是多个进程来交互处理呢?该如何进行设计和取舍呢?我们一般把这个问题称为I/O模型设计。不同的I/O模型对键值数据库的性能和可扩展性会有不同的影响
套接字:
概念:应用层通过传输层进行数据通信时候,TCP和UDP会遇到同时为多个应用提供并发服务的问题,多个TCP连接或多个应用程序进程可能会通过一个TCP协议端口进行通信,为了区分不同的应用程序和连接,操作系统为不同应用程序提供了套接字接口,用于区分不同应用程序间的网络通信和连接
套接字:主要三个参数,目标IP、使用的传输层协议TCP/UDP和使用的端口号
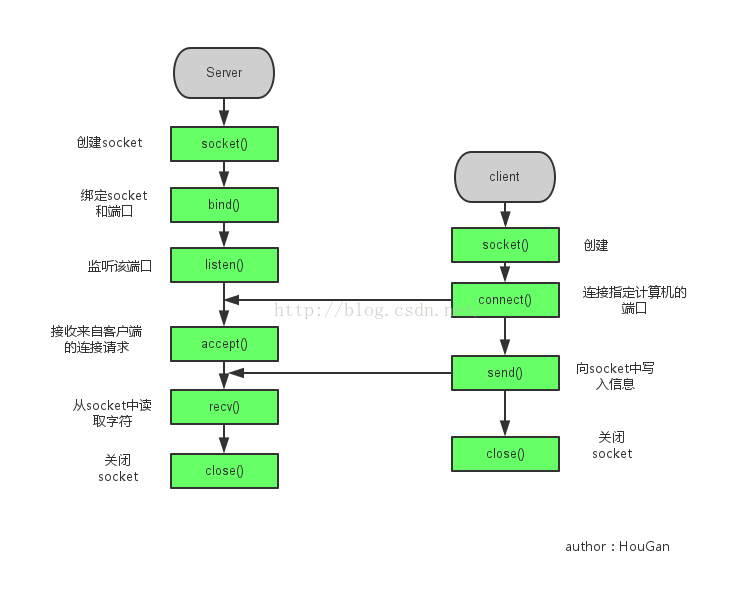
要通过互联网进行通信,至少需要一对套接字,服务端和客户端各一个,运行于客户机端,称之为ClientSocket,另一个运行于服务器端,称之为serverSocket。
套接字之间的连接过程分为三个步骤,服务端监听、客户端请求、连接确认
服务端监听:服务端套接字进入等待连接状态,实时监控网络状态
客户端请求:客户端的套接字提出连接请求,客户端的套接字描述指定目标服务端的地址和端口,发送连接请求
连接确认:服务端的套接字监听或接受到客户端的连接请求,则另起线程将服务端的套接字描述发送给客户端,此时连接建立完成。服务端的套接字继续处于监听状态,用于监听其他客户端的连接请求
通信流程如下图:
先思考三个问题:
(1)redis真的是单线程吗?
(2)redis为什么用单线程?
(3)单线程为什么这么快?
1.Redis的单线程的具体含义?
实际来说,redis的单线程是指网络IO和键值对的读写是单线程的,但是持久化、集群数据同步、异步删除其实是由额外的线程完成
2.Redis为什么使用单线程?
多线程的并发控制:
因为多线程并不一定就代表线程越多速度越快,再多线程的场景下,我们不得不去考虑针对共享变量的管理,也就是说针对并发所需要进行的处理往往会导致额外的开销或者说通过互斥锁等机制让并行变串行,因此增加线程并未让系统的吞吐率变高,反而因为加入了同步的机制,往往造成程序难于维护和调试
3.Redis为什么这么快?
原因如下:
(1)redis采取hash表、跳表等高效的存储结构,及redis的操作大部分在内存中完成
(2)Redis采取了基于select/epoll的多路复用机制,能够使其再网络IO中并发处理大量请求,增加了吞吐量
4.基于多路复用的高性能I/O模型
基本I/O模型和阻塞风险点:
前面说了redis的单线程是指针对网络I/O和键值的读写是单线程的,那么实际的一个请求从发送请求到返回结果客户端与服务端需要经过几个过程呢?
首先服务端会调用socket(),监听客户端的请求(bind/listen),然后和客户端建立连接(accept),再从socket中读取请求(recv),解析请求(parse),根据请求类型处理数据(读/写),最后返回给客户端结果,大概流程如下图:
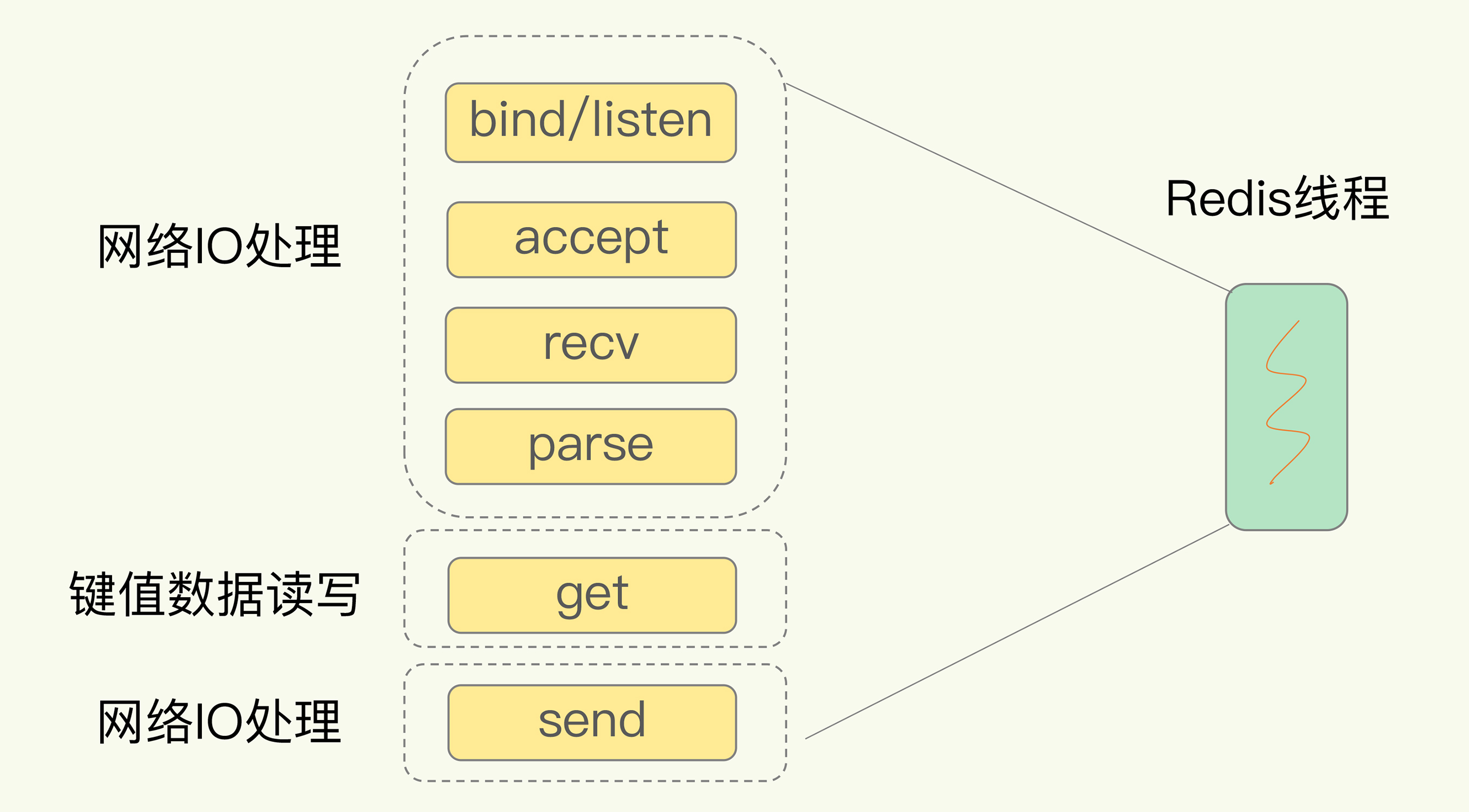
我们知道redis针对I/O请求是单线程处理了,就是说在上图请求过程,如果客户端与服务端一直都未建立连接,那么就会堵塞在accept()
或者建立了连接一直都未接收到请求,就会堵塞在recv(),不管哪一种堵塞,都可能会导致单线程下的redis的堵塞
当然,socket网络模型是支持非堵塞模式的
在socket模型中,不同的操作会返回不同类型的套接字(套接字是什么再上面讲解了,其实就是基于TCP/UDP等协议下传输数据区分不同的应用),并且不同的方法可以设置相应的非堵塞模式,设置之后如下图:

由上图可以知道针对不同的套接字类型可以设置非阻塞模式,因此就不会因为阻塞点的阻塞导致单线程下的redis阻塞。
我们也可以针对已连接套接字设置非阻塞模式:Redis调用recv()后,如果已连接套接字上一直没有数据到达,Redis线程同样可以返回处理其他操作。我们也需要有机制继续监听该已连接套接字,并在有数据达到时通知Redis
所以才产生了基于多路复用的IO模型(其实就是为了针对非阻塞场景下的回调的后续处理)
4.1.基于多路复用的IO模型:
Linux下的多路复用机制是指一个线程处理多个I/O流,就是常说的select/epoll机制。就是redis再单线程的场景下,该机制运行再内核中存在多个监听套接字和连接套接字(FD)。内核会一直监听这些套接字的数据请求,并且基于事件回调机制,不同的事件调用不同的函数处理,当有请求到达时就放入事件队列,然后redis再有序对该队列的请求进行处理。
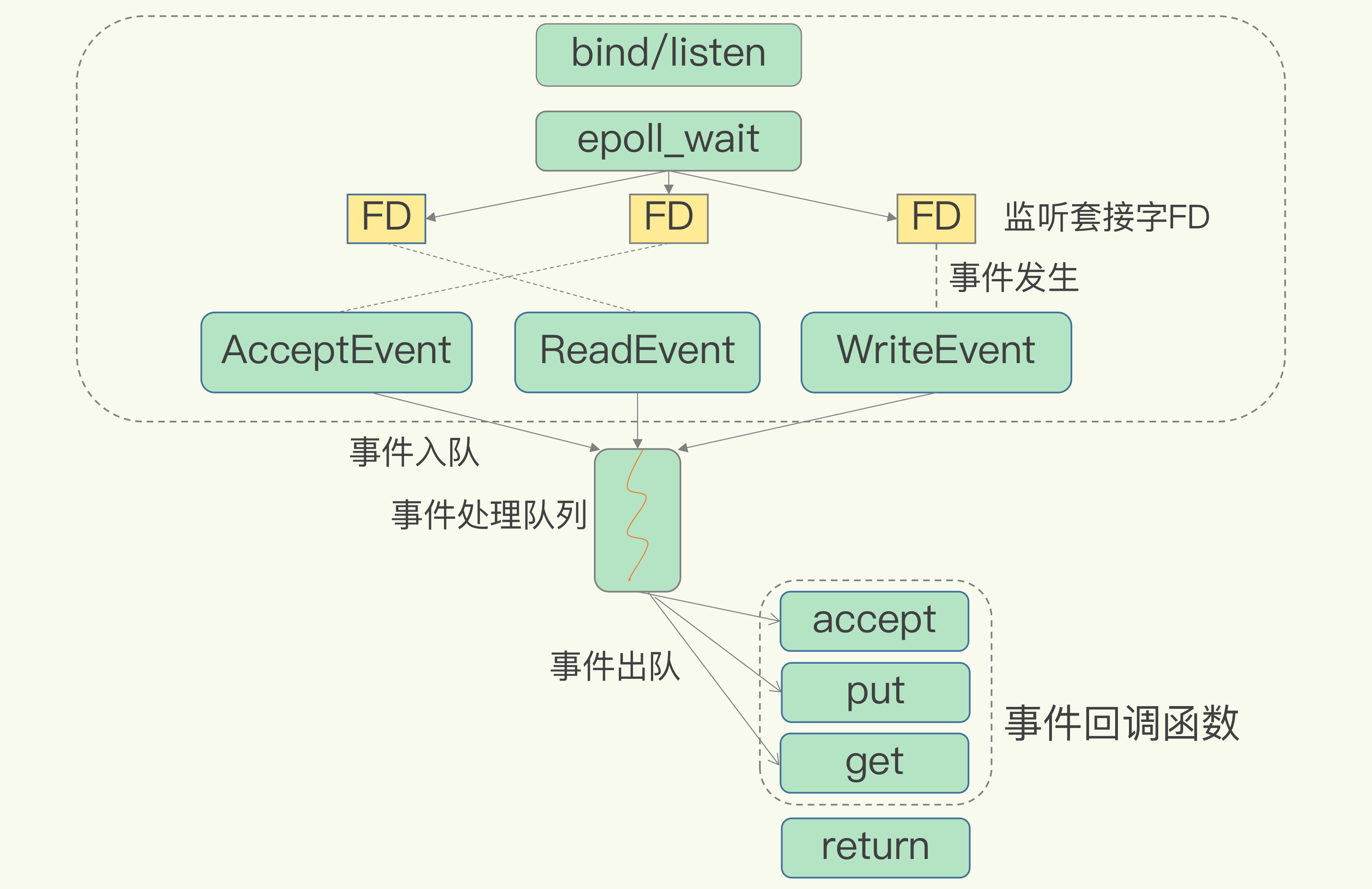
redis网络框架调用epollo机制,就不会出现上面所说的阻塞点的情况的产生,因为redis不会阻塞在一个特定的连接/监听套接字上,所以不会因为一个客户端的请求而堵塞其他客户端的请求,提高了并发性
在不用的操作系统下,有不同的多路复用机制
4.2.除此之外,redis会有哪些性能瓶颈呢?
由于redis针对事件队列的处理是单线程的,因此如果某个事件耗时较高,这样也会影响其他的事件请求
1.任意一个请求在server中一旦发生耗时,都会影响整个server的性能,也就是说后面的请求都要等前面这个耗时请求处理完成,自己才能被处理到。耗时的操作包括以下几种
(1)操作bigkey:写入一个bigkey在分配内存时需要消耗更多的时间,同样,删除bigkey释放内存同样会产生耗时
(2)使用复杂度过高的命令:例如SORT/SUNION/ZUNIONSTORE,或者O(N)命令,但是N很大,例如lrange key 0 -1一次查询全量数据
(3)淘汰策略:淘汰策略也是在主线程执行的,当内存超过Redis内存上限后,每次写入都需要淘汰一些key,也会造成耗时变长
(4)AOF刷盘开启always机制:每次写入都需要把这个操作刷到磁盘,写磁盘的速度远比写内存慢,会拖慢Redis的性能
(5)主从全量同步生成RDB:虽然采用fork子进程生成数据快照,但fork这一瞬间也是会阻塞整个线程的,实例越大,阻塞时间越久
2.并发量非常大时,单线程读写客户端IO数据存在性能瓶颈,虽然采用IO多路复用机制,但是读写客户端数据依旧是同步IO,只能单线程依次读取客户端的数据,无法利用到CPU多核。
针对问题1,一方面需要业务人员去规避,一方面Redis在4.0推出了lazy-free机制,把bigkey释放内存的耗时操作放在了异步线程中执行,降低对主线程的影响。
针对问题2,Redis在6.0推出了多线程,可以在高并发场景下利用CPU多核多线程读写客户端数据,进一步提升server性能,当然,只是针对客户端的读写是并行的,每个命令的真正操作依旧是单线程的















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











