







文章目录
【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Bq0sTLOj-1680957245062)(https://zhangyuxiangplus.oss-cn-hangzhou.aliyuncs.com/boke/统计场景.png)]](https://img-blog.csdnimg.cn/9bf371e1a0f543b7b99d2c88658bcad7.png)
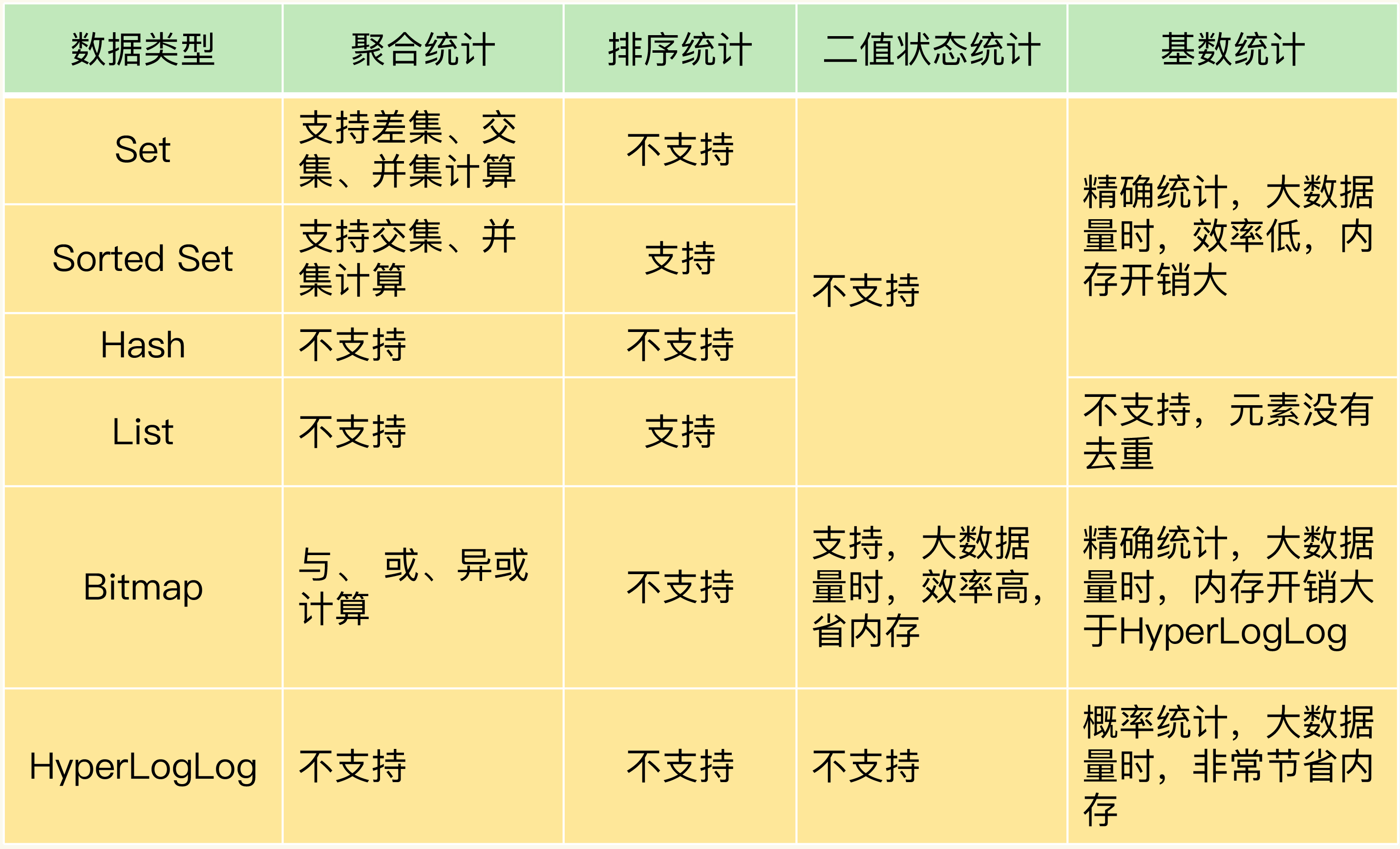
1.聚合统计
1.1.概念:
统计多个集合元素的聚合结果,集合之间的交集(公有)、并集(全部)、差集(独有)等
利用Set结构的聚合API进行聚合
2.排序统计
排序需要有序,两种有序结构:List和Zset、List是根据插入元素的顺序保证有序,而List是依据评分进行排序,评分可以再插入时候手动指定
需要展示最新列表、排行榜等场景时,如果数据更新频繁或者需要分页显示,建议你优先考虑使用Sorted Set
3.二值状态统计
3.1概念:
二值状态是指集合元素的取值只有0和1两种状态
3.2.Bitmap:
3.2.1.概念
String类型作为底层数据结构的一种统计二值类型的数据类型。String类型会保存为二进制数组,所以Redis把字节数组的每个bit位利用开来,bitmap实际就是一个bit数组
3.2.2.操作
bitmap提供了GETBIT/SETBIT,使用偏移量offset来对bit数组进行读写。offset从0开始计数,对bit位置进行写操作时该bit位会被设置为1,BITCOUNT操作会统计1的数量
Bitmap支持用BITOP命令对多个Bitmap按位做“与”“或”“异或”的操作,操作的结果会保存到一个新的Bitmap中。
所以,如果只需要统计数据的二值状态,例如商品有没有、用户在不在等,就可以使用Bitmap,因为它只用一个bit位就能表示0或1。在记录海量数据时,Bitmap能够有效地节省内存空间。
4.基数统计
4.1.概念:
基数统计就是统计一个元素中不重复的元素个数,例如统计网页UV(uv是unique visitor的简写,是指通过互联网访问、浏览这个网页的自然人,统计人数)
4.2.HyperLogLog
4.2.1.概念:
用于统计基数的数据集合类型,最大优势在于元素数量非常多的时候,它计算基数的空间总是固定的,而且很小
在Redis中,每个 HyperLogLog只需要花费 12 KB 内存,就可以计算接近 2^64 个元素的基数。你看,和元素越多就越耗费内存的Set和Hash类型相比,HyperLogLog就非常节省空间
不过,有一点需要你注意一下,HyperLogLog的统计规则是基于概率完成的,所以它给出的统计结果是有一定误差的,标准误算率是0.81%。这也就意味着,你使用HyperLogLog统计的UV是100万,但实际的UV可能是101万。虽然误差率不算大,但是,如果你需要精确统计结果的话,最好还是继续用Set或Hash类型。
















 1561
1561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











