







【关于作者】
关于作者,目前在蚂蚁金服搬砖任职,在支付宝营销投放领域工作了多年,目前在专注于内存数据库相关的应用学习,如果你有任何技术交流或大厂内推及面试咨询,都可以从我的个人博客(https://0522-isniceday.top/)联系我
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-kltXyZTm-1681039806327)(https://zhangyuxiangplus.oss-cn-hangzhou.aliyuncs.com/boke/缓存污染.png)]](https://img-blog.csdnimg.cn/03cc90c2162149c297e28fd2b83e0989.png)
1.什么是缓存污染
缓存污染指的是缓存中存在很多冷数据或者说查询频次很少的数据,如果这些数据占用的内存过大,会引发缓存的淘汰,会影响其性能
2.如何解决缓存污染
根据缓存的淘汰策略,
-
按照redis的淘汰策略而言,volatile-random和allkeys-random采取的是随机淘汰,而volatile-ttl则是只能在知道数据多长时间之后不再被访问之后才有效
-
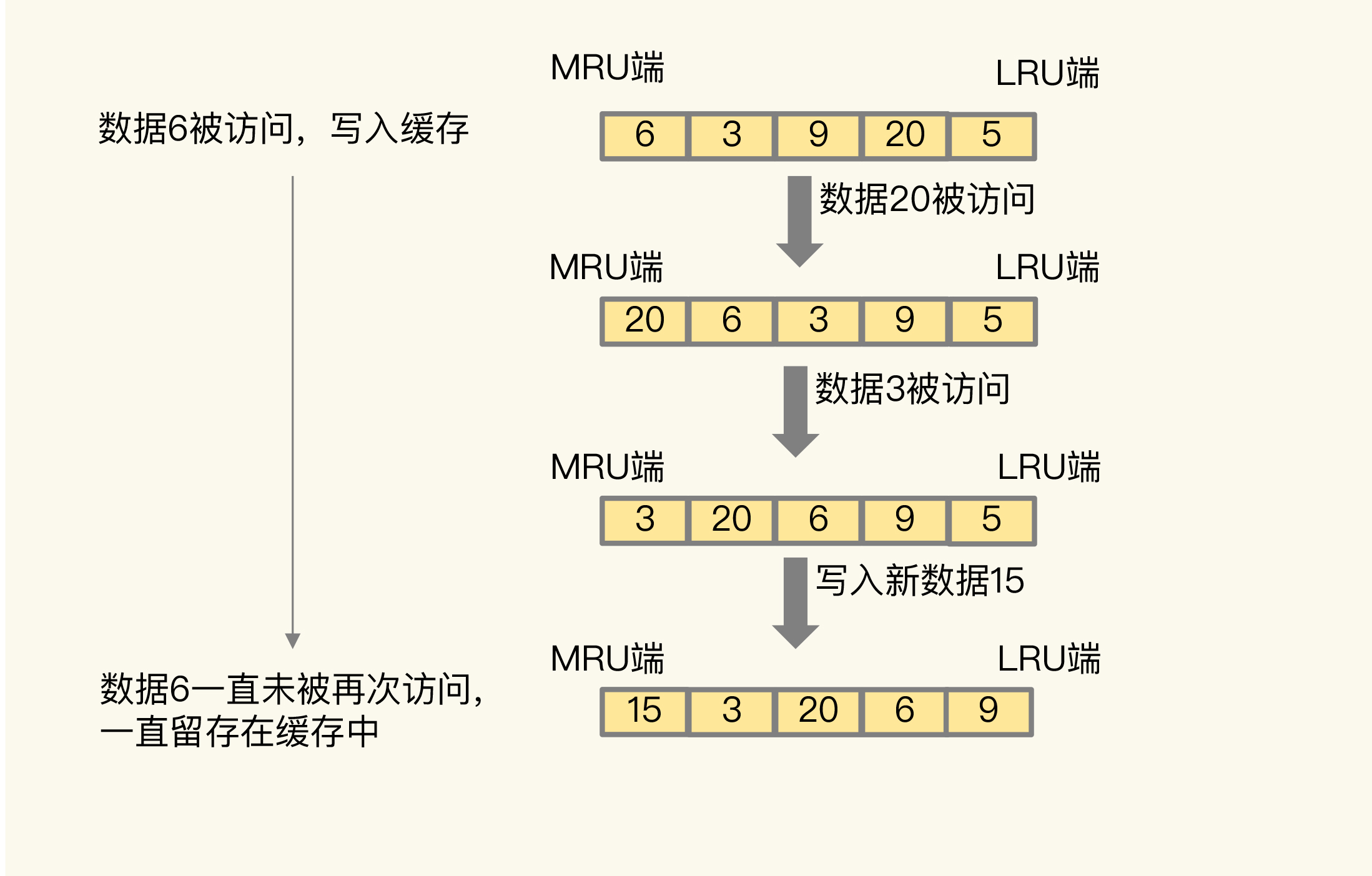
LRU是否能够避免缓存污染?
LRU:其核心思想是当一个数据刚被访问,那么这个数据一定是热数据,就会很久之后才会淘汰
但是真的是热数据吗?
由于只看访问时间,没有查看访问次数,可能会出现扫描单次查询操作时,无法解决缓存污染,如果这个单次扫描的数据量很大,那么这些数据的lru值都会很大,但是这些数据又不会再被访问,则会导致缓存污染
-
Redis 4.0新增的LFU
LFU会从两个维度淘汰数据:1.数据访问时间 2.数据访问次数
3.LFU缓存策略的优化
LFU在LRU的基础上加了个计数器,淘汰时会现将访问次数较少的数据淘汰,当数据访问次数一致时,再比较访问时间,访问时间小的先淘汰。
详情见Redis学习(十九)
















 520
520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











