






Hadoop的核心组件是HDFS和MapReduce
HDFS解决了海量数据的分布式存储
MapReduce解决了海量数据的分布式处理
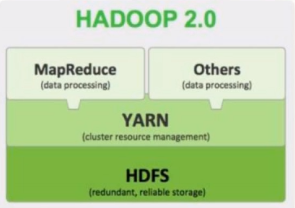
YARN 做资源调度管理
HDFS:NN Federation 、HA(NN-name node Federation 做数据目录服务,可设置多个name node 进行分区管理;HA:高可容性,热备份)

pig:轻量级脚本语言,简化了MapReduce的操作
sqoop 导入导出工具,将关系型数据库中的数据和hadoop相交流使用
Flume:日志收集
Zookeeper:挑出管理计算机
Hbase:分布式数据库
Oozie:作业流调度
Ambari:负责所有的安装部署
















 2628
2628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









