pip install segmentation- models- pytorch - i https: / / pypi. tuna. tsinghua. edu. cn/ simple
import segmentation_models_pytorch as smp
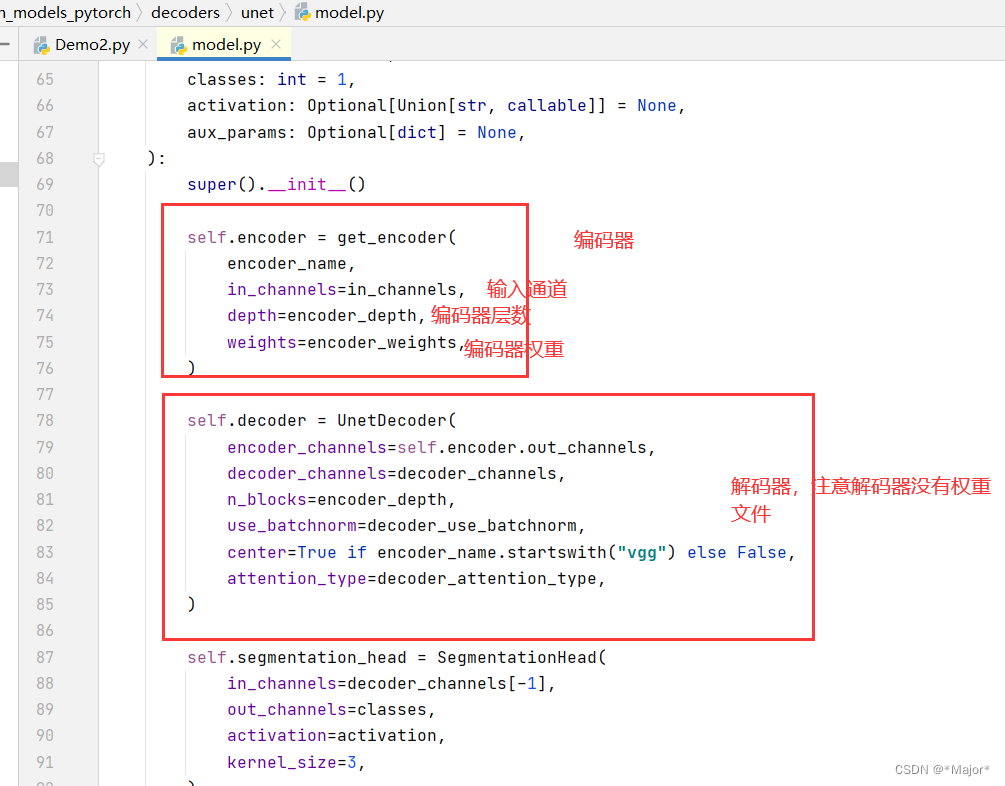
model = smp. Unet (
encoder_name= "resnet34" , # choose encoder, e. g. mobilenet_v2 or efficientnet- b7
encoder_weights= "imagenet" , # use ` imagenet ` - trained weights for encoder initialization
in_channels= 1 , # model input channels ( 1 for gray- scale images, 3 for RGB , etc. )
classes= 3 , # model output channels ( number of classes in your dataset)
)
from segmentation_models_pytorch. encoders import get_preprocessing_fn
preprocess_input = get_preprocessing_fn ( 'resnet18' , pretrained= 'imagenet' )
import segmentation_models_pytorch as smp
output = torch.rand( [ 10 , 3 , 256 , 256 ] )
target = torch.rand( [ 10 , 3 , 256 , 256 ] ) .round( ) .long( )
tp, fp, fn, tn = smp.metrics.get_stats( output, target, mode = 'multilabel' , threshold = 0.5 )
iou_score = smp.metrics.iou_score( tp, fp, fn, tn, reduction = "micro" )
f1_score = smp.metrics.f1_score( tp, fp, fn, tn, reduction = "micro" )
f2_score = smp.metrics.fbeta_score( tp, fp, fn, tn, beta = 2 , reduction = "micro" )
accuracy = smp.metrics.accuracy( tp, fp, fn, tn, reduction = "macro" )
recall = smp.metrics.recall( tp, fp, fn, tn, reduction = "micro-imagewise" )
def load_img ( path) :
img = cv2. imread ( path, cv2. IMREAD_UNCHANGED )
img = np. tile ( img[ ... , None] , [ 1 , 1 , 3 ] ) # gray to rgb
img = img. astype ( 'float32' ) # original is uint16
mx = np. max ( img)
if mx :
img/= mx # scale image to [ 0 , 1 ]
return img
def load_msk ( path) :
msk = cv2. imread ( path, cv2. IMREAD_UNCHANGED )
msk = msk. astype ( 'float32' )
msk/= 255.0
return msk
def build_model ( backbone, num_classes, device) :
model = smp. Unet (
encoder_name= backbone, # choose encoder, e. g. mobilenet_v2 or efficientnet- b7
encoder_weights= "imagenet" , # use ` imagenet ` - trained weights for encoder initialization
in_channels= 3 , # model input channels ( 1 for gray- scale images, 3 for RGB , etc. )
classes= num_classes, # model output channels ( number of classes in your dataset)
activation= None,
)
model. to ( device)
return model
model = build_model ( CFG . backbone, CFG . num_classes, CFG . device)
DiceLoss = smp. losses. DiceLoss ( mode= 'binary' )
BCELoss = smp. losses. SoftBCEWithLogitsLoss ( )
def criterion ( y_pred, y_true) :
if CFG . loss_func == "DiceLoss" :
return DiceLoss ( y_pred, y_true)
elif CFG . loss_func == "BCELoss" :
y_true = y_true. unsqueeze ( 1 )
return BCELoss ( y_pred, y_true)
def dice_coef ( y_true, y_pred, thr= 0.5 , dim= ( 2 , 3 ) , epsilon= 0.001 ) :
y_true = y_true. unsqueeze ( 1 ) . to ( torch. float32)
y_pred = ( y_pred> thr) . to ( torch. float32)
inter = ( y_true* y_pred) . sum ( dim= dim)
den = y_true. sum ( dim= dim) + y_pred. sum ( dim= dim)
dice = ( ( 2 * inter+ epsilon) / ( den+ epsilon) ) . mean ( dim= ( 1 , 0 ) )
return dice
def iou_coef ( y_true, y_pred, thr= 0.5 , dim= ( 2 , 3 ) , epsilon= 0.001 ) :
y_true = y_true. unsqueeze ( 1 ) . to ( torch. float32)
y_pred = ( y_pred> thr) . to ( torch. float32)
inter = ( y_true* y_pred) . sum ( dim= dim)
union = ( y_true + y_pred - y_true* y_pred) . sum ( dim= dim)
iou = ( ( inter+ epsilon) / ( union+ epsilon) ) . mean ( dim= ( 1 , 0 ) )
return iou
def fetch_scheduler ( optimizer) :
if CFG . scheduler == 'CosineAnnealingLR' :
scheduler = lr_scheduler. CosineAnnealingLR ( optimizer, T_max= CFG . T_max,
eta_min= CFG . min_lr)
elif CFG . scheduler == 'CosineAnnealingWarmRestarts' :
scheduler = lr_scheduler. CosineAnnealingWarmRestarts ( optimizer, T_0 = CFG . T_0 ,
eta_min= CFG . min_lr)
elif CFG . scheduler == 'ReduceLROnPlateau' :
scheduler = lr_scheduler. ReduceLROnPlateau ( optimizer,
mode= 'min' ,
factor= 0.1 ,
patience= 7 ,
threshold= 0.0001 ,
min_lr= CFG . min_lr, )
elif CFG . scheduer == 'ExponentialLR' :
scheduler = lr_scheduler. ExponentialLR ( optimizer, gamma= 0.85 )
elif CFG . scheduler == None:
return None
return scheduler
optimizer = optim. Adam ( model. parameters ( ) , lr= CFG . lr, weight_decay= CFG . wd)
scheduler = fetch_scheduler ( optimizer)
def train_one_epoch ( model, optimizer, scheduler, dataloader, device, epoch) :
model. train ( )
scaler = amp. GradScaler ( )
dataset_size = 0
running_loss = 0.0
pbar = tqdm ( enumerate ( dataloader) , total= len ( dataloader) , desc= 'Train ' )
for step, ( images, masks) in pbar :
images = images. to ( device, dtype= torch. float)
masks = masks. to ( device, dtype= torch. float)
batch_size = images. size ( 0 )
with amp. autocast ( enabled= True) :
y_pred = model ( images)
loss = criterion ( y_pred, masks)
loss = loss / CFG . n_accumulate
scaler. scale ( loss) . backward ( )
if ( step + 1 ) % CFG . n_accumulate == 0 :
scaler. step ( optimizer)
scaler. update ( )
# zero the parameter gradients
optimizer. zero_grad ( )
if scheduler is not None:
scheduler. step ( )
running_loss += ( loss. item ( ) * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
mem = torch. cuda. memory_reserved ( ) / 1E9 if torch. cuda. is_available ( ) else 0
current_lr = optimizer. param_groups[ 0 ] [ 'lr' ]
pbar. set_postfix ( epoch= f'{epoch}' ,
train_loss= f'{epoch_loss:0.4f}' ,
lr= f'{current_lr:0.5f}' ,
gpu_mem= f'{mem:0.2f} GB' )
torch. cuda. empty_cache ( )
gc. collect ( )
return epoch_loss
@torch. no_grad ( )
def valid_one_epoch ( model, dataloader, device, epoch) :
model. eval ( )
dataset_size = 0
running_loss = 0.0
val_scores = [ ]
pbar = tqdm ( enumerate ( dataloader) , total= len ( dataloader) , desc= 'Valid ' )
for step, ( images, masks) in pbar :
images = images. to ( device, dtype= torch. float)
masks = masks. to ( device, dtype= torch. float)
batch_size = images. size ( 0 )
y_pred = model ( images)
loss = criterion ( y_pred, masks)
running_loss += ( loss. item ( ) * batch_size)
dataset_size += batch_size
epoch_loss = running_loss / dataset_size
y_pred = nn. Sigmoid ( ) ( y_pred)
val_dice = dice_coef ( masks, y_pred) . cpu ( ) . detach ( ) . numpy ( )
val_jaccard = iou_coef ( masks, y_pred) . cpu ( ) . detach ( ) . numpy ( )
val_scores. append ( [ val_dice, val_jaccard] )
mem = torch. cuda. memory_reserved ( ) / 1E9 if torch. cuda. is_available ( ) else 0
current_lr = optimizer. param_groups[ 0 ] [ 'lr' ]
pbar. set_postfix ( valid_loss= f'{epoch_loss:0.4f}' ,
lr= f'{current_lr:0.5f}' ,
gpu_memory= f'{mem:0.2f} GB' )
val_scores = np. mean ( val_scores, axis= 0 )
torch. cuda. empty_cache ( )
gc. collect ( )
return epoch_loss, val_scores
def run_training ( model, optimizer, scheduler, device, num_epochs) :
if torch. cuda. is_available ( ) :
print ( "cuda: {}\n" . format ( torch. cuda. get_device_name ( ) ) )
start = time. time ( )
best_model_wts = copy. deepcopy ( model. state_dict ( ) )
best_loss = np. inf
best_epoch = - 1
history = defaultdict ( list)
for epoch in range ( 1 , num_epochs + 1 ) :
gc. collect ( )
print ( f'Epoch {epoch}/{num_epochs}' , end= '' )
train_loss = train_one_epoch ( model, optimizer, scheduler,
dataloader= train_loader,
device= CFG . device, epoch= epoch)
val_loss, val_scores = valid_one_epoch ( model, valid_loader,
device= CFG . device,
epoch= epoch)
val_dice, val_jaccard = val_scores
history[ 'Train Loss' ] . append ( train_loss)
history[ 'Valid Loss' ] . append ( val_loss)
history[ 'Valid Dice' ] . append ( val_dice)
history[ 'Valid Jaccard' ] . append ( val_jaccard)
print ( f'Valid Dice: {val_dice:0.4f} | Valid Jaccard: {val_jaccard:0.4f}' )
print ( f'Valid Loss: {val_loss}' )
# deep copy the model
if val_loss <= best_loss:
print ( f"{c_}Valid loss Improved ({best_loss} ---> {val_loss})" )
best_dice = val_dice
best_jaccard = val_jaccard
best_loss = val_loss
best_epoch = epoch
best_model_wts = copy. deepcopy ( model. state_dict ( ) )
PATH = "best_epoch.bin"
torch. save ( model. state_dict ( ) , PATH )
print ( f"Model Saved{sr_}" )
last_model_wts = copy. deepcopy ( model. state_dict ( ) )
PATH = "last_epoch.bin"
torch. save ( model. state_dict ( ) , PATH )
print ( ) ; print ( )
end = time. time ( )
time_elapsed = end - start
print ( 'Training complete in {:.0f}h {:.0f}m {:.0f}s' . format (
time_elapsed
print ( "Best Loss: {:.4f}" . format ( best_loss) )
# load best model weights
model. load_state_dict ( best_model_wts)
return model, history
model, history = run_training ( model, optimizer, scheduler,
device= CFG . device,
num_epochs= CFG . epochs)

























 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









