








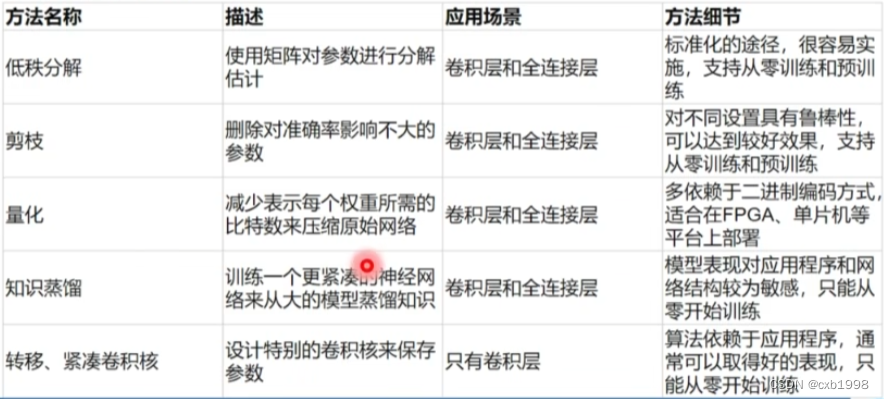
业界常用的方法一般是剪枝和量化。
知识蒸馏
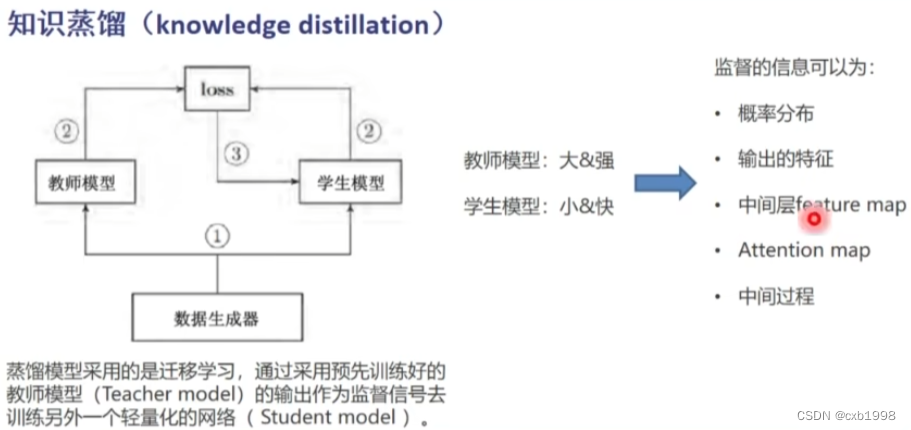
以分类网络为例:
假设下为老师,上为学生。
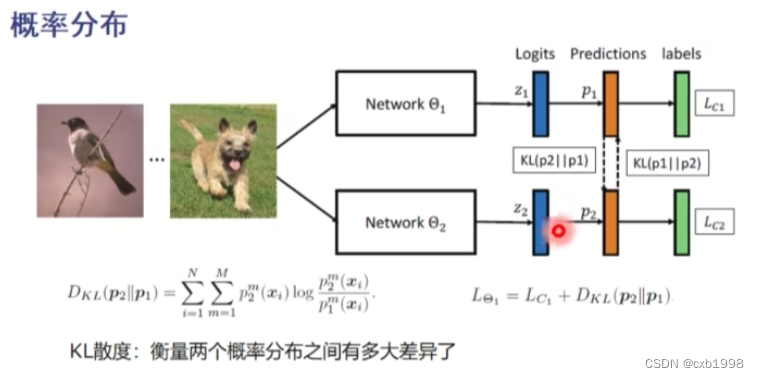
传输概率分布,即学生以老师的预测分布为学习目标,则老师的损失函数为分类损失,学生的损失函数除了分类损失,还需要计算自身的预测概率分布和老师概率分布做kl散度loss,从而使学生的预测分布与老师一致。

特征图分布,学生通过MMDloss与老师模型的feature map进行域相似度计算,从而拉近特征分布。
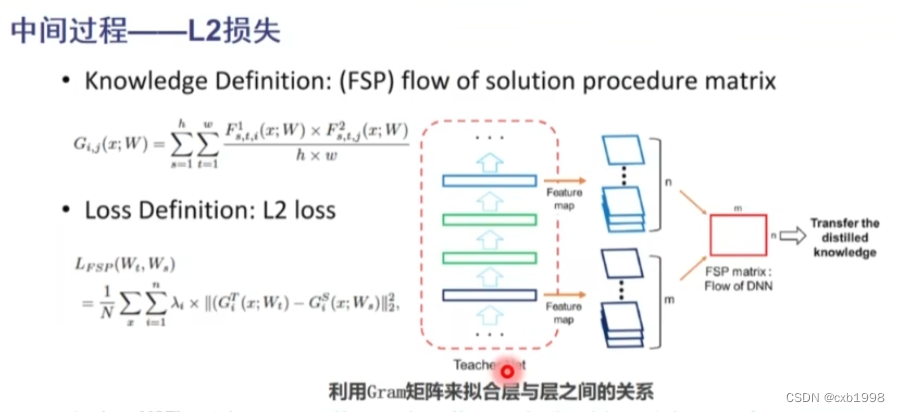
计算老师模型的feature map维度间的gram矩阵,同样计算学生模型的gram矩阵,将gram矩阵进行L2正则,个人理解是让学生学习老师feature map每个维度提取的都是些什么特征,怎么提取的特征。
压缩模型
1. SqueezeNet
核心是引入了一个FIRE MODULE:
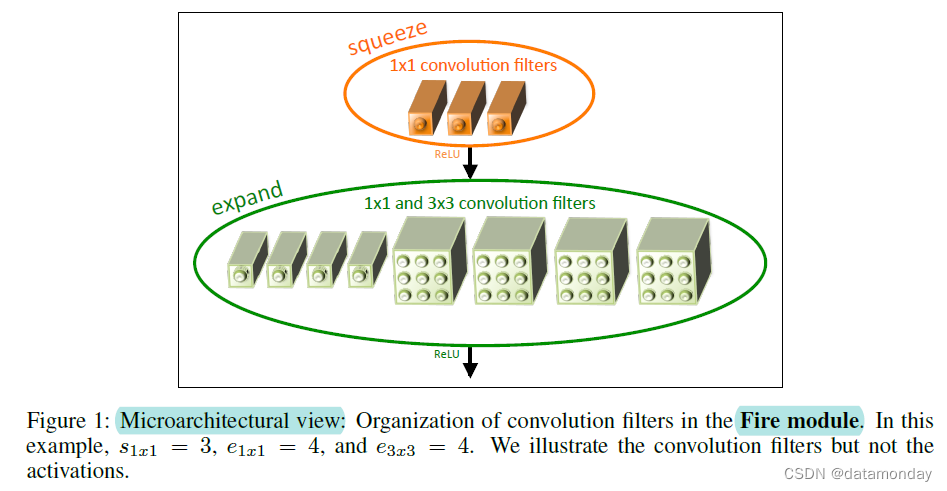
分为两个部分squeeze和expand, squeeze由1*1卷积构成,expand由部分1*1卷积核3*3卷积组成,整个SqueezeNet基于Fire Module堆叠组成,最后用1*1卷积代替全连接层。
2. MobileNet V1(28)
核心深度可分离卷积:

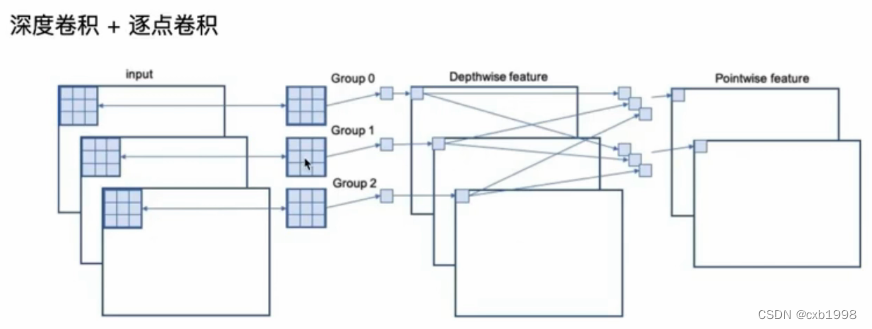
参数量:Dk*Dk*M+1*1*M*N
标准卷积:

参数量:Dk*Dk*M*N
深度可分离卷积和标准卷积的参数比:1/N + 1/(Dk*Dk),卷积核个数N通常为几百,1/N非常小,DK如果是3*3卷积,则该模块相比标准卷积参数压缩了9倍。
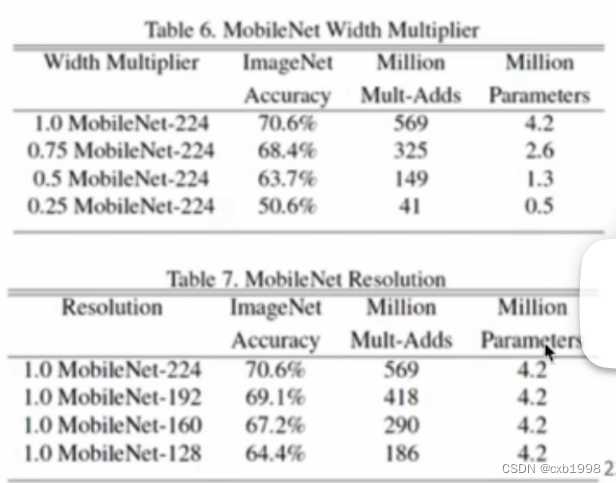
最后进一步叠加了宽度因子(作用在通道上)和分辨率因子(作用在输出特征图尺寸上)来压缩参数和计算。
MobileNet V2


在MobileNetV1的深度可分离卷积前后加expansion(高维->低维)和projection(低维->高维),虽然单个block增加,但需要的block下降。
![]()
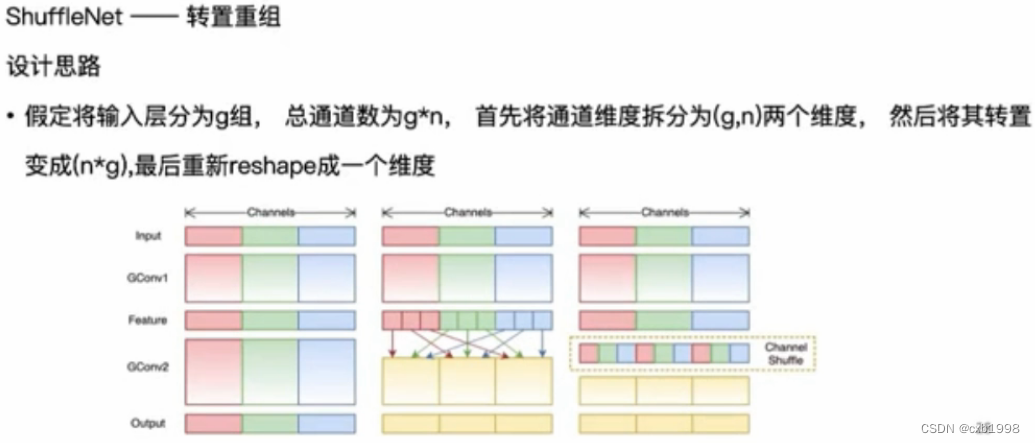
3. ShuffleNet
分组卷积(深度可分离就是其中之一)的弊端:组与组之间的信息流难以传递,通过1*1conv打通,此时参数基本在1*1conv上。
shufflenet通过转置数组的方式进行通道间的信息交互取代1*1conv,进一步减少参数。
模型压缩
剪枝:深度学习模型的参数大多有冗余,通过剪枝削减那些不重要的权重矩阵达到直接压缩模型的效果。

主流修剪策略:
1. 按权重大小修剪,例如接近0的权重对输入可能没什么影响,计算成本低但结果并不总是准确。
2. 迭代修剪,每个几个epoch对比设定阈值小的权重进行修剪。
无论如何,修剪后都是需要微调的。

可以通过剪枝层的参数标准差乘系数因子作为判断阈值,绝对值小于该阈值的参数对应的mask置0,将mask和参数相乘,此时参数矩阵只保留了大于阈值的参数,剪枝完成后再训练微调,注意微调时被减枝权重不再更新。
量化:剪枝删除不重要的权重参数,而量化则是减少存储权重的位数nit,将权重存储在更小的空间中,例如fp32->int8,然而简单的近似效果并不好,需要一些训练量化参数的技巧。
二值化是最简单的量化方式,其中确定性二值化表示权值为正则全为1,为负则全为0。速度大大提高但性能明显下降。确定性二值化的变体,不用0或1赋值权重而是采用两个训练获得的C1和C2常数。
三元量化:

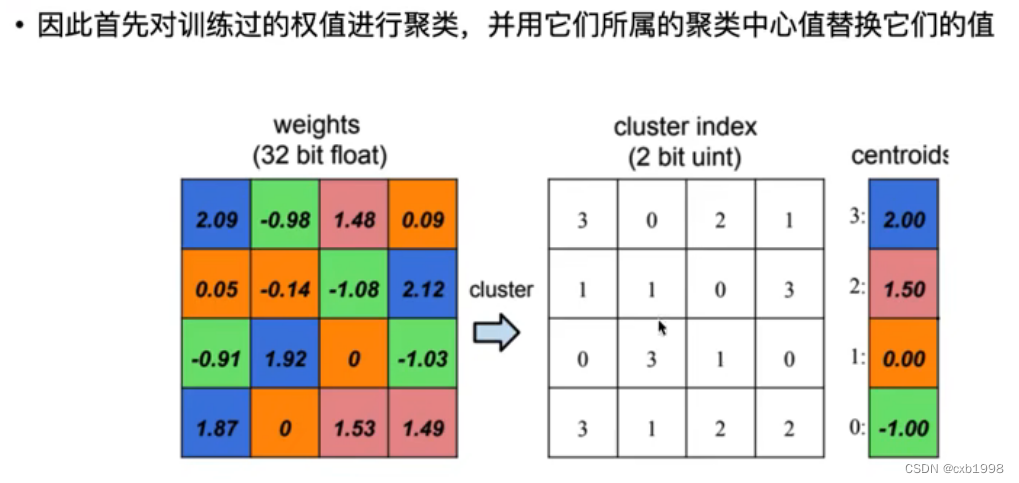
用参数聚类中心近似分布参数:

梯度训练方式:
















 5461
5461











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









