







在正态分布中:
- 约68%的数据点会落在均值±1σ的范围内
- 约95%的数据点会落在均值±2σ的范围内
- 约99.7%的数据点会落在均值±3σ的范围内
这称为68-95-99.7法则(Empirical Rule)。
假设我们有一组数据,其均值为μ,标准差为σ。某个数据点x的n-sigma计算公式如下:
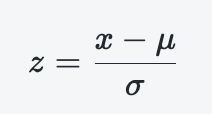
若z=1.2,说明该数据点在1σ和2σ之间(位于均值 μ 加上 1.2 个标准差)
算法缺点:
不能用于预测趋势:随着数据点的绝对值增大,通常会使得数据点相对于均值的n-sigma值增大,从而使得这个数据点所在的范围(即n-sigma的上下界)也相应变宽
异常检测逻辑

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











