







论文地址:
https://arxiv.org/abs/2204.07143
代码地址(刚刚开源):
https://github.com/SHI-Labs/Neighborhood-Attention-Transformer
动机
受卷积如何引入邻域偏差和局部性的启发,本文通过引入了邻域注意,允许特征图中的每个像素仅关注其相邻像素。以此在不需要额外操作的情况下引入局部归纳偏差。
内容总览
本文提出了Neighborhood Attention Transformer(NAT),NAT是一种集高效、准确和可扩展的分层Transformer,Neighborhood Attention是一种简单而灵活的Self Attention机制,它将每个query的感受野扩展到其最近的邻近像素,并随着感受野的增大而接近Self-Attention。
首先,可以通过下图直观的了解一下ViT,SwinT和NAT的区别。ViT的感受野和token是一样大的,SwinT由Window Self Attention和Shifted Window Self Attention两种自注意,通过像素移位实现两种划分并降低计算复杂度。本文提出的NAT可以自适应地将接收域定位到每个token周围的一个邻域,在不需要额外操作的情况下引入局部归纳偏差。
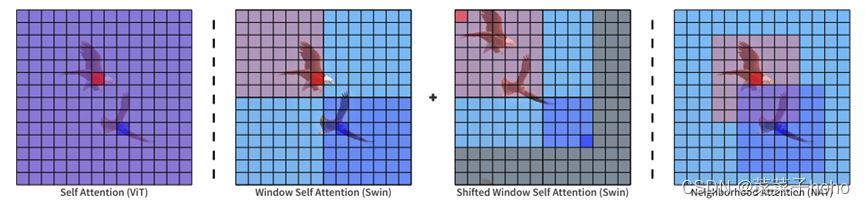
邻域关注度与自我关注度的查询键值结构图对比:
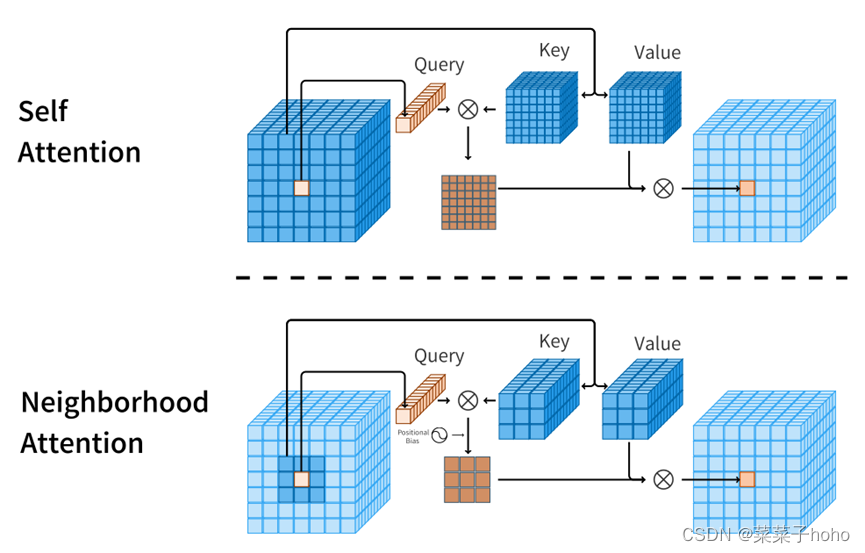
自我注意允许每个标记关注所有其他标记,而邻居注意将每个标记的接收域局限于其周围的邻居。
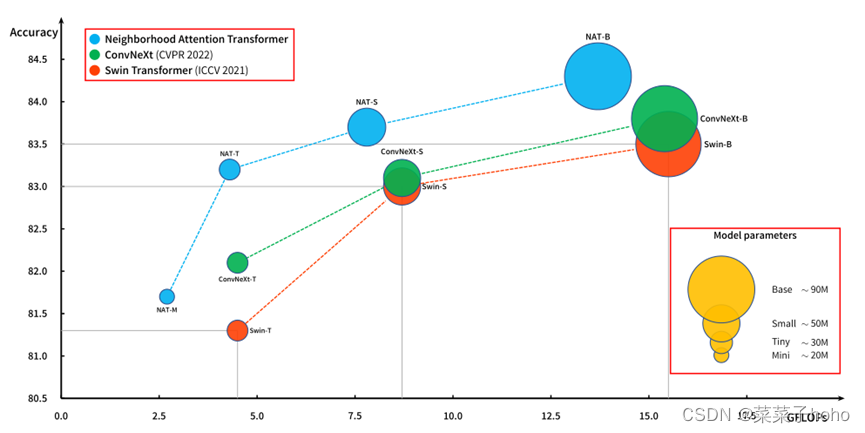
ImageNet-1k分类性能与计算比较图,气泡大小代表参数数量。
具体方法
与Self Attention相比,Neighborhood Attention不仅减少了计算成本,而且引入了类似于卷积的局部归纳偏差。该操作适用于邻域大小L,当每个像素最小时,它只关注自身周围的1个像素邻域(创建一个3×3方形窗口)。
作者还表明,当邻域大小达到最大值(即输入的大小)时,Neighborhood Attention等于Self Attention。因此,如果邻域大小超过或匹配feature map的大小,在相同的输入下,Neighborhood Attention和Self Attention的输出是相等的。
此外,NAT利用了一个多级分层设计,类似于Swin-Transformer,这意味着特征映射在级别之间被向下采样,而不是一次性全部采样。然而,与Swin-Transformer不同的是,NAT使用重叠卷积来向下采样特征映射,而不是不重叠的映射。这略微增加了计算量和参数,作者也通过提出计算成本较低的配置来弥补这一点。
Neighborhood Attention
我们用ρ(i,j)表示(i,j)处像素的邻域,ρ(I,j)是最接近(i,j)的像素的索引的固定长度集合。大小为:
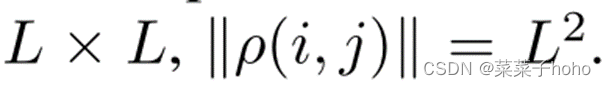
因此,在单个像素上的Neighborhood Attention可以定义如下:
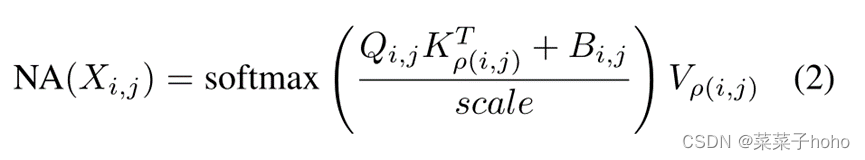
其中,其中Q、K、V是X的线性投影,Bi,j为相对位置偏差,根据相对位置将其添加到每个注意力权重中。这个操作可以进一步扩展到所有像素,从而形成一种局部注意力的形式。
然而,如果ρ函数将每个像素映射到所有像素,这将等同于Self Attention(带有额外的位置偏差)。这是因为当邻域边界超过输入大小时,ρ(i,j)将包括所有可能的像素。结果
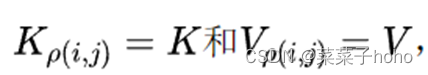
通过去除偏置项,推导出Self Attention的表达形式
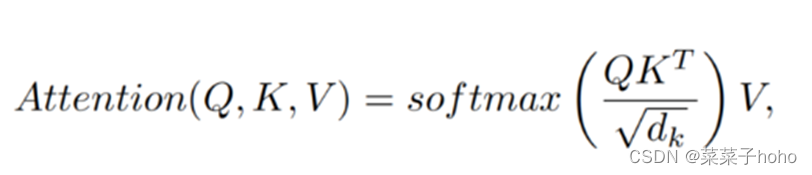
Neighborhood Attention在计算上是很廉价的。它的复杂性相对于分辨率是线性的,不像Self Attention是二次的。此外,其复杂度也与邻域大小呈线性关系。ρ函数将一个像素映射到一组相邻的像素,可以很容易地通过Raster-Scan Sliding Window操作产生,原理类似于卷积。
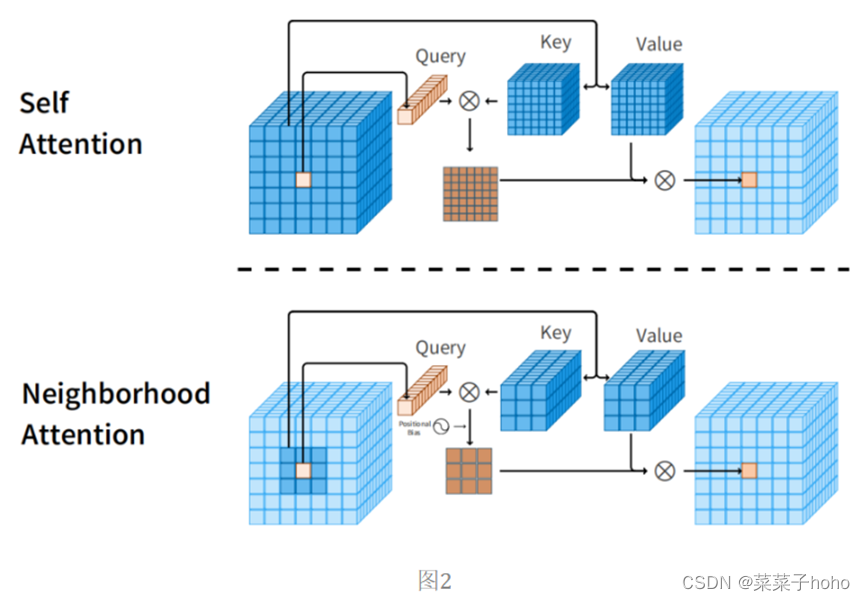
每个像素被简单地映射到一组相邻的像素和自身。图2展示了该操作的示例。对特征图中的每个像素重复此操作。对于不能居中的角像素,扩展邻域以保持感受野的大小。这是一个关键的设计选择,它允许NA随着邻域大小向特征图分辨率增长而一般化到Self Attention。
扩展邻域是通过简单持续选择L2中最接近原始邻域的像素来实现的。例如,对于L=3,每个query将以围绕它的9个key-value像素结束(query位于中心的3×3网格)。
对于角像素,邻域是另一个3×3网格,但query没有定位在中心。图6展示了这个想法的说明。

复杂度和内存消耗表:

通过上表可以看出,Neighborhood Attention的复杂度和内存消耗和Swin相同。
整体架构
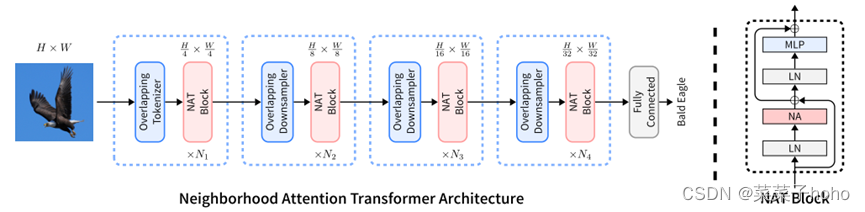
NAT通过使用2个连续的3×3卷积(stride=2)来嵌入输入,进而产生输入空间大小1/4的输入。这类似于使用patch和4×4 patch的嵌入层,但它使用的是重叠卷积而不是非重叠卷积。
另一方面,使用重叠卷积会增加成本,而2次卷积会引入更多的参数。然而,作者通过重新配置模型来处理这个问题,这将产生更好的权衡。
NAT由4个level组成,每个level后面都链接一个下采样器(最后一个除外)。下采样器将空间大小减少了为原来的一半,而通道数量增加了一倍。这里下采样使用的是3×3卷积(stride=2)。由于tokenizer的降采样倍数为4倍,因此模型生成了大小为H/4×W/4、H/8×W/8、H/16×W/16和H/32×W/32的特征图.使得NAT可以更容易地将预训练过的模型迁移到下游任务中。
此外,在训练较大的模型时,使用LayerScale来提高稳定性。在下表中总结了不同的NAT变体及其关键差异。所有模型都使用7 × 7的注意邻域。
















 665
665











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









