







Python安装文件可以直接去官网上下载 Python官网链接
在我们安装好python环境之后,需要安装一些爬虫时用到的库,最基本的有requests库,BeautifulSoup库
使用pip命令可以安装这两个库,点击链接可以看到添加pip命令到dos中的操作:pip命令添加到dos命令集
安装requests库命令:pip install requests
安装BeautifluSoup库命令:pip install bs4
如果显示当前pip版本过低,可以通过 pip install --upgrade pip命令来更新pip
安装后如果显示Successfully installed …等,表示已经安装成功,如果显示了很多红色的错误提示,则可以将刚才的更新命令重新执行几次,会成功的。
接下来分析网易云的歌手界面

URL中的id后面的属性值对应不同的歌手类型,其对应关系如下所示
| id | 对应歌手类型 |
|---|---|
| 1001 | 华语男歌手 |
| 1002 | 华语女歌手 |
| 1003 | 华语组合/乐队 |
| 2001 | 欧美男歌手 |
| 2002 | 欧美女歌手 |
| 2003 | 欧美组合/乐队 |
| 6001 | 日本男歌手 |
| 6002 | 日本女歌手 |
| 6003 | 日本组合/乐队 |
| 7001 | 韩国男歌手 |
| 7002 | 韩国女歌手 |
| 7003 | 韩国组合/乐队 |
| 4001 | 其他男歌手 |
| 4002 | 其他女歌手 |
| 4003 | 其他组合/乐队 |
而在每一个歌手类型界面,通过26个字母与其他进行分组

分组对应的是initial的属性值,其对应关系如下所示
| initial | 对应分组 |
|---|---|
| A | 65 |
| B | 66 |
| … | … |
| Z | 90 |
| 其他 | 0 |
可以看到其具有明显的对应关系
根据以上的,我们的各个URL就确定了,接下来我们在每个界面上爬取歌手的名字与歌手的id
右键点击检查,查看我们的界面html代码
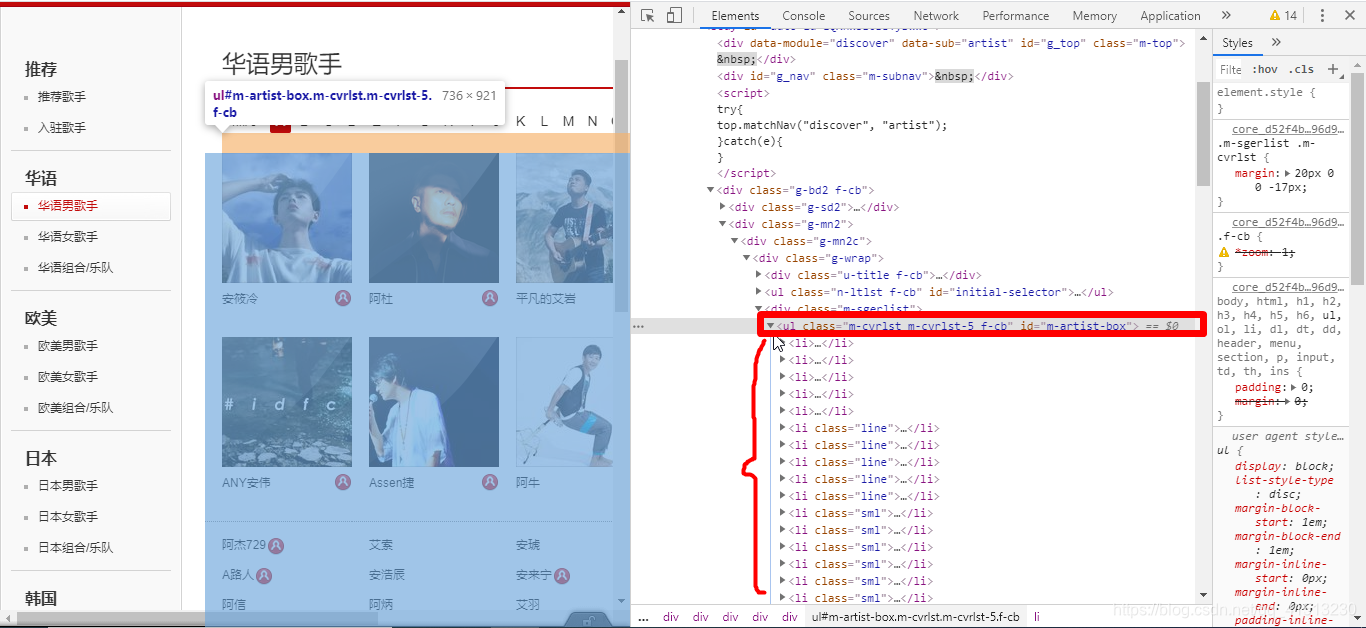
可以看到,歌手的信息都是存储在ul标签的li标签下,我们只需要先得到ul标签,再将li标签里面的数据爬取出来,就可以得到我们需要的数据
可以看到该ul标签中class属性值是m-cvrlst m-cvrlst-5 f-cb, id属性是m-artist-box
在给ul标签的li标签的a标签中我们可以得到该歌手的id和姓名

其class属性值为nm nm-icn f-thide s-fc0
具体代码如下所示
import csv
import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
key_ids = {1001:"华语男歌手", 1002:"华语女歌手",1003:"华语组合或乐队", 2001:"欧美男歌手", 2002:"欧美女歌手", 2003:"欧美组合或乐队",6001:"日本男歌手",6002:"日本女歌手",6003:"日本组合或乐队",7001:"韩国男歌手",7002:"韩国女歌手",7003:"韩国组合或乐队",4001:"其他男歌手",4002:"其他女歌手", 4003:"其他组合或乐队"}
ids = [1001, 1002, 1003, 2001, 2002, 2003, 6001, 6002, 6003, 7001, 7002, 7003, 7004]
initials = [65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 0]
base_url = "https://music.163.com/discover/artist/cat?id={}&initial={}"
for id in key_ids.keys():
with open(file = r'{}.csv'.format(key_ids[id]), encoding = "utf-8", mode = "a") as f:
writer = csv.writer(f, lineterminator='\n')
writer.writerow(["歌手ID", "歌手姓名"])
f.close()
print("正在爬取{}的信息".format(key_ids[id]))
for initial in initials:
try:
with open(file=r'{}.csv'.format(key_ids[id]), encoding="utf-8", mode="a") as f:
url = base_url.format(str(id), str(initial))
response = requests.get(url, headers = headers)
response.encoding = "utf-8"
soup = BeautifulSoup(response.text, "html.parser")
ul = soup.find("ul", class_ = "m-cvrlst m-cvrlst-5 f-cb")
a_s = ul.find_all("a", class_ = "nm nm-icn f-thide s-fc0")
for a in a_s:
singer_id = a['href'].split('=')[1]
singer_name = a.text
writer = csv.writer(f, lineterminator='\n')
writer.writerow((singer_id, singer_name))
print("正在写入{}{}的信息".format(key_ids[id],singer_name))
f.close()
except Exception as e:
print(e)
continue
生成的csv文件与py文件在同一个文件夹下















 1111
1111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









