






v1版本:
import pandas as pd
# 读取包含a, b, c, d 列的Excel文件
import pandas as pd
# 读取包含a, b, c, d 列的Excel文件
excel_file = 'result_excel_file.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(excel_file)
# 提取问题a, b, c, d 的值
a_values = df['a'].tolist()
b_values = df['b'].tolist()
c_values = df['c'].tolist()
d_values = df['d'].tolist()
# 初始化结果存储的数据结构
result_data = []
# 遍历每行计算顺序系数,从第一行开始算顺序系数,i代表Excel行数
i=1
for a, b, c, d in zip(a_values, b_values, c_values, d_values):
i = i + 1
if (c + d) * (a + c) != 0:
sequence_coefficient = 1 - c/ ((c + d) * (a + c))
print(i)
print(a)
print(b)
print(c)
print(d)
#print(sequence_coefficient)
result_data.append(sequence_coefficient)
else:
result_data.append(None)
# 创建一个包含顺序系数的新DataFrame
print(result_data)
# 保存结果到Excel文件
df_result = pd.DataFrame(result_data, columns=['顺序系数'])
df_result.to_excel('3.xlsx', index=False)
热力图 没有各种乱码之类的
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#通过下面这行解决中文乱码问题
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_style('whitegrid',{'font.sans-serif':['simhei','Arial']})
# 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 读取Excel文件
excel_file_path = 'result_excel_file.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(excel_file_path)
# 提取问题i、问题j和顺序系数列数据
data = df[['问题i', '问题j', '顺序系数']]
# 创建数据透视表,以便于绘制热力图
pivot_data = data.pivot(index='问题i', columns='问题j', values='顺序系数')
# 使用Seaborn绘制热力图
plt.figure(figsize=(20, 15))
sns.heatmap(pivot_data, cmap='viridis', annot=True, fmt=".2f", linewidths=.5)
plt.title('热力图', fontsize=16) # 调整标题字体大小
plt.xlabel('问题j', fontsize=14) # 调整 x 轴标签字体大小
plt.ylabel('问题i', fontsize=14) # 调整 y 轴标签字体大小
plt.show()
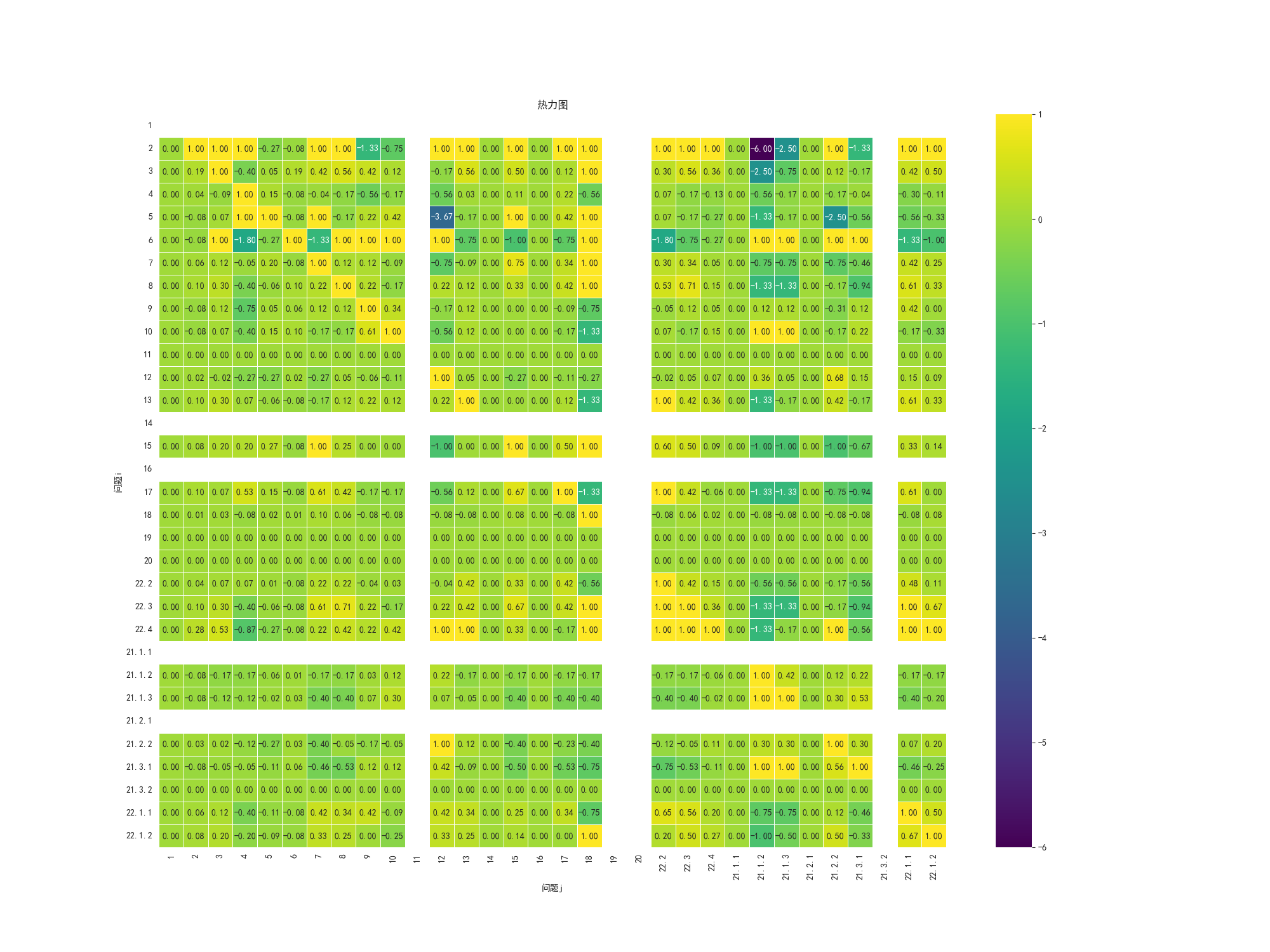
IRS图 abcd 的计算
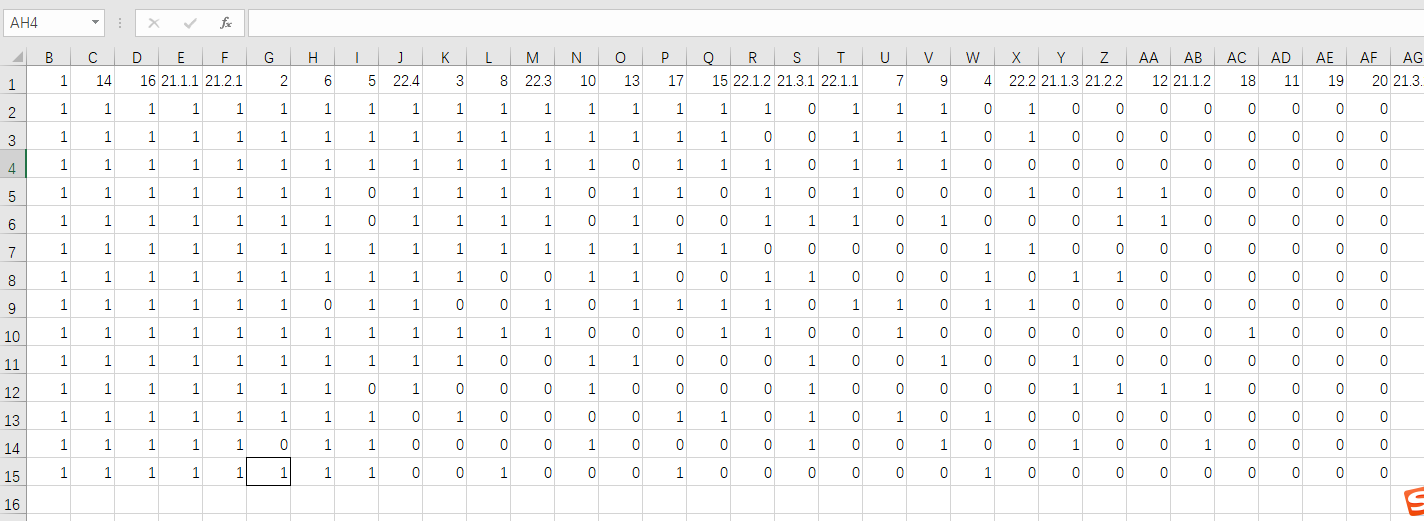
Excel长这样,标题是题号

import pandas as pd
# 读取Excel文件
excel_file = 'sp.xlsx' # 替换为你的Excel文件路径
df = pd.read_excel(excel_file)
# 提取学生姓名和问题序号,此部分测试正常,注释掉
# students = df.iloc[:, 0].tolist()
# print(students)
# questions = df.columns[1:].tolist()
# print(questions)
# # 提取每个学生的答题情况
# for student in students:
# student_data = df[df.iloc[:, 0] == student]
# student_answers = student_data.iloc[0, 1:].tolist()
# print(f"学生: {student}")
# for i, answer in enumerate(student_answers):
# print(f"问题 {questions[i]}: {answer}")
# 提取学生姓名和问题序号
students = df.iloc[:, 0].tolist()
questions = df.columns[1:].tolist()
# 初始化结果存储的数据结构
result_data = []
# 遍历问题序号i和j的组合
for i in range(len(questions)):
for j in range(len(questions)):
q_i = questions[i]
q_j = questions[j]
# 计算情况a(问题i答对,问题j答对的学生数量)
a = ((df[q_i] == 1) & (df[q_j] == 1)).sum()
# 计算情况b(问题i答对,问题j答错的学生数量)
b = ((df[q_i] == 1) & (df[q_j] == 0)).sum()
# 计算情况c(问题i答错,问题j答对的学生数量)
c = ((df[q_i] == 0) & (df[q_j] == 1)).sum()
# 计算情况d(问题i答错,问题j答错的学生数量)
d = ((df[q_i] == 0) & (df[q_j] == 0)).sum()
# 计算总和
total = a + b + c + d
result_data.append([q_i, q_j, a, b, c, d, total])
# 创建一个包含结果的新DataFrame
result_df = pd.DataFrame(result_data, columns=['问题i', '问题j', 'a', 'b', 'c', 'd', '总和'])
# 将结果写入新的Excel文件
result_excel_file = 'result_excel_file.xlsx' # 替换为新Excel文件的路径
result_df.to_excel(result_excel_file, index=False)
print("结果已写入新Excel文件:", result_excel_file)
IRS图 0 1 序列
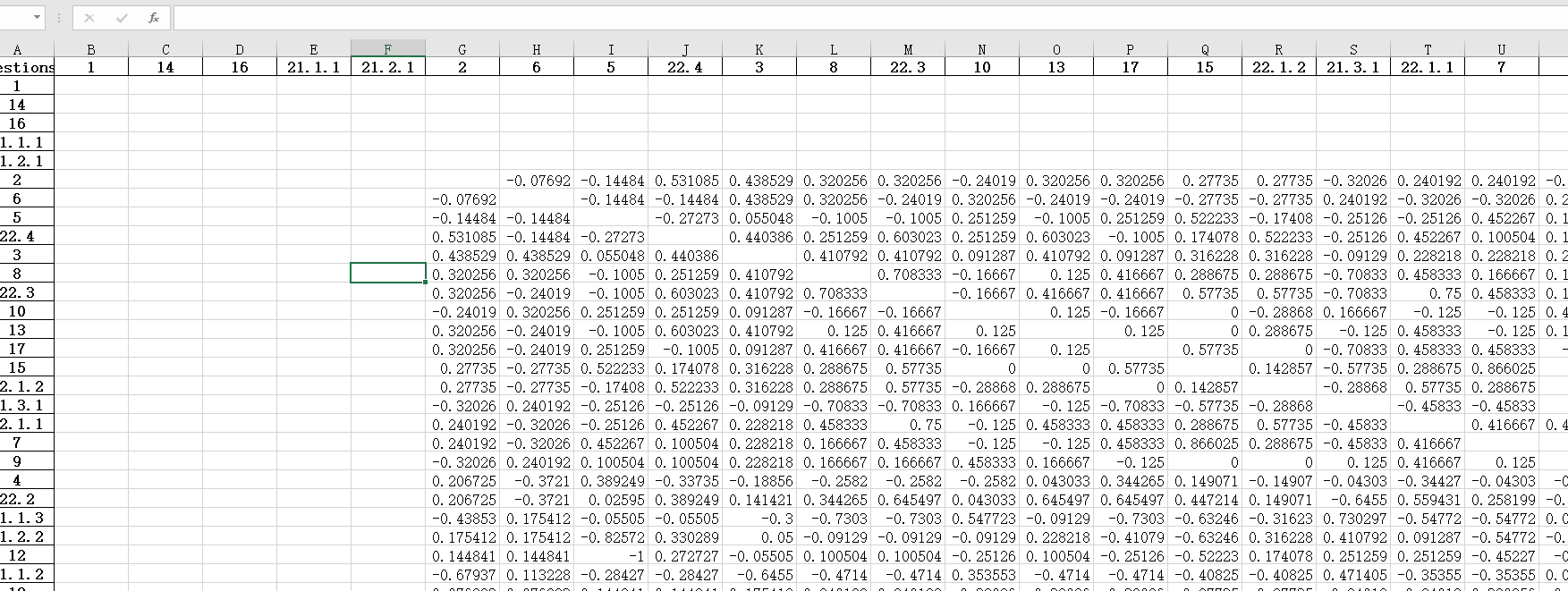
斯皮尔曼相关系数
import pandas as pd
from scipy.stats import spearmanr
# 读取 Excel 文件
excel_file = 'sp.xlsx' # 替换为你的 Excel 文件名
df = pd.read_excel(excel_file)
# 示例数据列名称,根据实际情况替换
question_columns = df.columns.tolist()[1:] # 假设第一列为索引,后续列为题号
# 创建一个空的 DataFrame 存储系数结果
results = []
# 计算任意两个问题之间的系数,并存入 DataFrame
for col1 in question_columns:
for col2 in question_columns:
if col1 != col2: # 避免计算同一列的系数
# 计算 Spearman 相关系数
spearman_corr, _ = spearmanr(df[col1], df[col2])
results.append([col1, col2, spearman_corr])
# 创建包含相关系数的 DataFrame
result_df = pd.DataFrame(results, columns=['问题i', '问题j', '相关系数'])
# 将结果存入 Excel 文件
result_df.to_excel('coefficients_result.xlsx', index=False, engine='openpyxl')
运行结果:
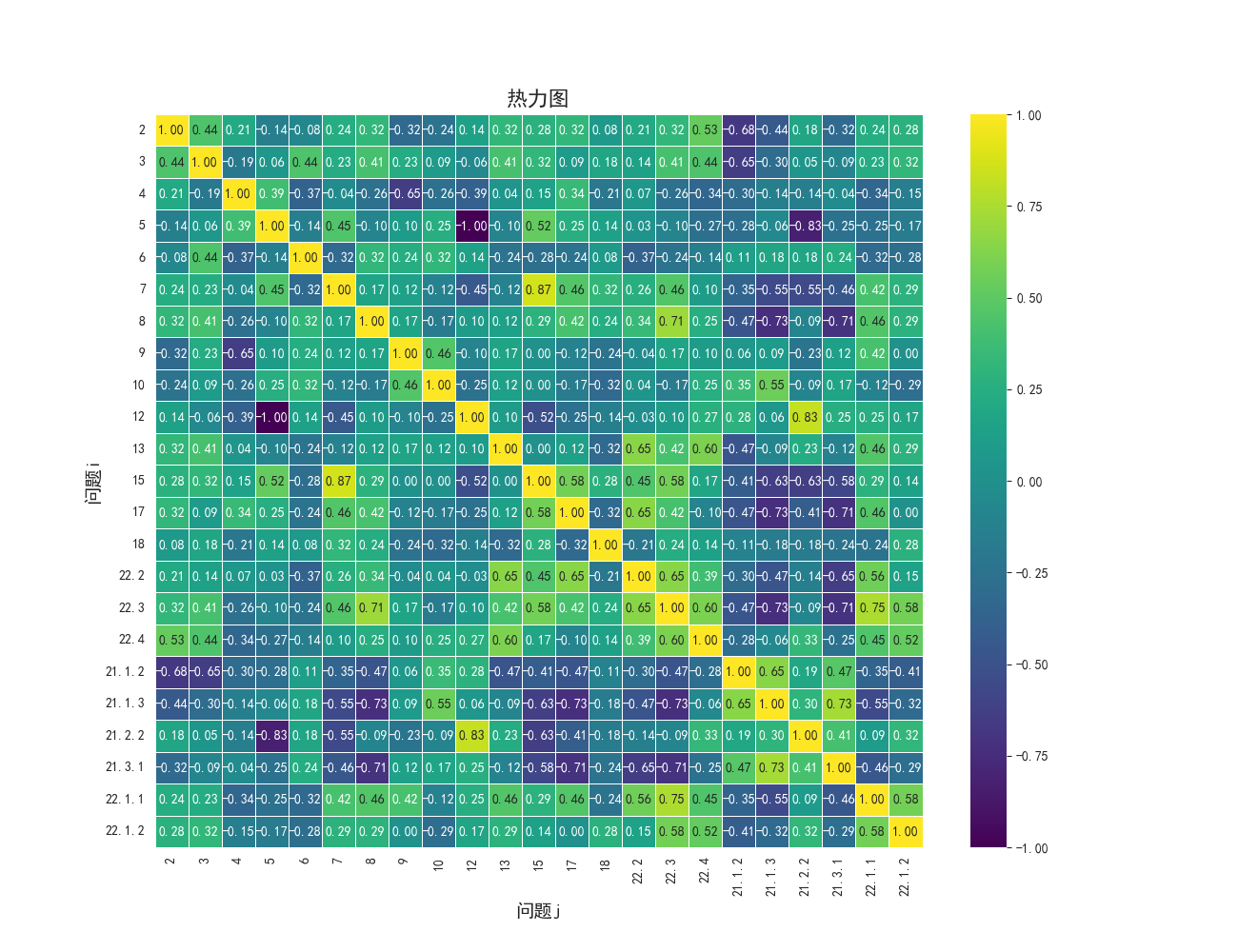
改成行列式显示二维结果(便于画热力图)
import pandas as pd
from scipy.stats import spearmanr
# 读取 Excel 文件
excel_file = 'sp.xlsx' # 替换为你的 Excel 文件名
df = pd.read_excel(excel_file)
# 示例数据列名称,根据实际情况替换
question_columns = df.columns.tolist()[1:] # 假设第一列为索引,后续列为题号
# 创建一个空的 DataFrame 存储系数结果
results = []
# 计算任意两个问题之间的系数,并存入 DataFrame
for col1 in question_columns:
for col2 in question_columns:
if col1 != col2: # 避免计算同一列的系数
# 计算 Spearman 相关系数
spearman_corr, _ = spearmanr(df[col1], df[col2])
results.append([col1, col2, spearman_corr])
# 创建包含相关系数的 DataFrame
result_df = pd.DataFrame(results, columns=['问题i', '问题j', '相关系数'])
# 将结果存入 Excel 文件
result_df.to_excel('coefficients_result.xlsx', index=False, engine='openpyxl')
绘制热力图















 453
453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











