







 该博客围绕概率论与数理统计展开,介绍了基本概念,如随机现象、事件关系等。阐述了随机变量及其分布,包括离散型和连续型。还讲解了随机变量的数字特征,如期望、方差等。最后介绍了大数定律和中心极限定理,及其在实际问题中的应用。
该博客围绕概率论与数理统计展开,介绍了基本概念,如随机现象、事件关系等。阐述了随机变量及其分布,包括离散型和连续型。还讲解了随机变量的数字特征,如期望、方差等。最后介绍了大数定律和中心极限定理,及其在实际问题中的应用。
Table of Contents
概率论与数理统计(Probability & Statistics I)
概率论与数理统计(Probability & Statistics II)
Cheat Sheets:
Probability Cheatsheet v2.0
Probability Cheat Sheet
概率论的基本概念(The Basic Concept of Probability Theory)
-
基本概念
概率论 (Theory of Probability): 是一门揭示随机现象统计规律性的数学学科
统计学 (Statistics):是一门通过收集、整理、分析数据等手段以达到推断或预测考察对象本质或未来的学科.
随机现象(random phenomenon):个别实验结果呈现不确定性,大量重复实验又具有统计规律性的现象
随机试验(random experiment):对随机现象的观测
样本和样本空间:试验的每一个结果称为一个样本(sample),记为s
所有可能出现的结果的集合称为样本空间 (sample space),记为S
随机事件(random event):实际问题中,通常会关心随机试验一些特定的结果,它们是S的(可测)子集,称为事件(event),通常用大写字母A, B,…表示。
可列集(countable):是指一个无穷集S,其元素可与自然数形成一一对应,因此可表为 S = { s 1 , s 2 , … } S=\{s_1,s_2,…\} S={s1,s2,…} -
事件的关系与运算:设以下大写英文字母均为样本空间S中的事件
s ∈ A ⟺ s\in A\iff s∈A⟺事件A发生
A ⊂ B ⟺ A⊂ B\iff A⊂B⟺指事件A必然导致事件B发生
A = B ⟺ A ⊂ B 且 B ⊂ A A=B\iff A⊂ B且B⊂ A A=B⟺A⊂B且B⊂A
A ∪ B ⟺ A∪ B\iff A∪B⟺称为事件A与B的和事件(union of events),表示事件A与B至少有一个发生
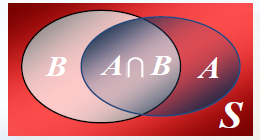
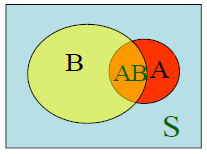
A ∩ B ⟺ A∩ B\iff A∩B⟺称为事件A与B的积事件(intersection of events),表示事件A与B同时发生,也常记为AB
A − B ⟺ A-B\iff A−B⟺称为事件A与B的差事件(difference of events),表示事件A发生且B不发生
A ˉ = S − A ⟺ \bar A=S-A \iff Aˉ=S−A⟺称为A的对立事件(complementary events),表示事件A不发生
特别的, S S S 称为必然事件(certain event), ∅ \varnothing ∅称为不可能事件(impossible event),单点集 { s } \{s\} {s} 称为基本事件(elementary event)
若 A B = ∅ AB=\varnothing AB=∅,则称事件A与B互斥(mutually exclusive events)

| 交换律 | A ∪ B = B ∪ A A ∩ B = B ∩ A A∪ B=B∪ A\\ A∩ B=B∩ A A∪B=B∪AA∩B=B∩A |
|---|---|
| 结合律 | ( A ∪ B ) ∪ C = A ∪ ( B ∪ C ) ( A ∩ B ) ∩ C = A ∩ ( B ∩ C ) (A∪ B)∪ C=A∪ (B∪ C)\\ (A∩ B)∩ C=A∩ (B∩ C) (A∪B)∪C=A∪(B∪C)(A∩B)∩C=A∩(B∩C) |
| 分配律 | A ∪ ( B ∩ C ) = ( A ∪ B ) ∩ ( A ∪ B ) A ∩ ( B ∪ C ) = ( A ∩ B ) ∪ ( A ∩ B ) A∪ (B∩ C)=(A∪ B)∩ (A∪ B)\\ A∩ (B∪ C)=(A∩ B)∪ (A∩ B) A∪(B∩C)=(A∪B)∩(A∪B)A∩(B∪C)=(A∩B)∪(A∩B) |
| 对偶律(De Morgan) | A ∪ B ‾ = A ˉ ∩ B ˉ , A ∩ B ‾ = A ˉ ∪ B ˉ ⋃ i = 1 n A i ‾ = ⋂ i = 1 n A i ˉ , ⋂ i = 1 n A i ‾ = ⋃ i = 1 n A i ˉ \overline{ A∪ B}=\bar A∩\bar B ,\quad \overline{ A∩ B}=\bar A∪\bar B \\ \overline{\displaystyle\bigcup_{i=1}^{n}A_i}=\displaystyle\bigcap_{i=1}^{n}\bar{A_i} ,\quad \overline{\displaystyle\bigcap_{i=1}^{n}A_i}=\displaystyle\bigcup_{i=1}^{n}\bar{A_i} A∪B=Aˉ∩Bˉ,A∩B=Aˉ∪Bˉi=1⋃nAi=i=1⋂nAiˉ,i=1⋂nAi=i=1⋃nAiˉ |
-
频率(frequency): f n ( A ) = n A n f_n(A)=\dfrac{n_A}{n} fn(A)=nnA
其中 n A n_A nA 是A发生的次数(频数),n 是总试验次数,称 f n ( A ) f_n(A) fn(A) 为A在这 n 次试验中发生频率。
频率的性质
1 ° 0 ⩽ f n ( A ) ⩽ 1 1\degree\quad 0⩽ f_n(A) ⩽ 1 1°0⩽fn(A)⩽1
2 ° f n ( S ) = 1 2\degree\quad f_n(S)= 1 2°fn(S)=1
3 ° f n ( ⋃ i = 1 k A i ) = ∑ i = 1 k f n ( A i ) , A 1 , A 2 , ⋯ , A k 3\degree\quad f_n(\displaystyle\bigcup_{i=1}^{k}A_i)=\displaystyle\sum_{i=1}^{k}f_n(A_i),\ A_1,A_2,\cdots,A_k 3°fn(i=1⋃kAi)=i=1∑kfn(Ai), A1,A2,⋯,Ak两两互斥 -
概率(probability)
(统计性定义)当试验的次数增加时,随机事件A发生的频率的稳定值p称为概率,记为 P ( A ) = p P(A)=p P(A)=p
(公理化定义)设随机试验对应的样本空间为S,定义P(A)满足以下性质,称P(A)为A的概率
非负性: P ( A ) ⩾ 0 P(A)⩾ 0 P(A)⩾0
规范性: P ( S ) = 1 P(S)=1 P(S)=1
可列可加性: A i A j = ∅ , ( i ≠ j ) ⟹ P ( ⋃ i = 1 ∞ A i ) = ∑ i = 1 ∞ P ( A i ) A_iA_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{∞}A_i)=\displaystyle\sum_{i=1}^{∞}P(A_i) AiAj=∅,(i=j)⟹P(i=1⋃∞Ai)=i=1∑∞P(Ai)
概率的性质
1 ° P ( ∅ ) = 0 1\degree\quad P(\varnothing)= 0 1°P(∅)=0
2 ° P ( A ) = 1 − P ( A ˉ ) 2\degree\quad P(A)=1-P(\bar A) 2°P(A)=1−P(Aˉ)
3 ° A i A j = ∅ , ( i ≠ j ) ⟹ P ( ⋃ i = 1 k A i ) = ∑ i = 1 k P ( A i ) 3\degree\quad A_iA_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{k}A_i)=\displaystyle\sum_{i=1}^{k}P(A_i) 3°AiAj=∅,(i=j)⟹P(i=1⋃kAi)=i=1∑kP(Ai)
4 ° A ⊂ B ⟹ P ( B − A ) = P ( B ) − P ( A ) , P ( B ) ⩾ P ( A ) 4\degree\quad A⊂ B\implies P(B-A)=P(B)-P(A),\ P(B)⩾ P(A) 4°A⊂B⟹P(B−A)=P(B)−P(A), P(B)⩾P(A)
5 ° P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A B ) 5\degree\quad P(A∪ B)=P(A)+P(B)-P(AB) 5°P(A∪B)=P(A)+P(B)−P(AB) -
等可能概型(classical probability):若试验满足,样本空间S中样本点有限(有限性),出现每一个样本点的概率相等(等可能性),称这种试验为等可能概型(或古典概型)。
P ( A ) = k n P(A)=\dfrac{k}{n} P(A)=nk,其中k为A中所包含的样本点数,n为S中的样本点数。 -
几何概型(geometric probability):(将等可能的原理进一步拓广)
当样本空间 S 为 R n \R^n Rn 中的某个区域,如果没有特别的信息,则认为 R n \R^n Rn 中每一点的出现都是等可能的。因此如果事件A为S中的某个子区域,则认为A发生的概率为A与S 体积(或面积、长度)之比。 -
条件概率(conditional probability):设A,B为事件,P(A)>0,定义 P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB)称为是A发生条件下B发生的概率
条件概率空间:原样本空间的缩减 S → A S\to A S→A
条件概率:原概率的限制 P ( ⋅ ) → P ( ⋅ ∣ A ) P(\cdot)\to P(\cdot|A) P(⋅)→P(⋅∣A)
-
条件概率性质: P ( ⋅ ∣ A ) P(\cdot|A) P(⋅∣A) 是概率,具有概率的所有性质
非负性: P ( B ∣ A ) ⩾ 0 P(B|A)⩾ 0 P(B∣A)⩾0
规范性: P ( S ∣ A ) = 1 P(S|A)=1 P(S∣A)=1
可列可加性: B i B j = ∅ , ( i ≠ j ) ⟹ P ( ⋃ i = 1 ∞ B i ∣ A ) = ∑ i = 1 ∞ P ( B i ∣ A ) B_iB_j=\varnothing,(i\neq j)\implies P(\displaystyle\bigcup_{i=1}^{∞}B_i|A)=\displaystyle\sum_{i=1}^{∞}P(B_i|A) BiBj=∅,(i=j)⟹P(i=1⋃∞Bi∣A)=i=1∑∞P(Bi∣A)
乘法公式
P ( A B ) = P ( A ) P ( B ∣ A ) = P ( B ) P ( A ∣ B ) P(AB)=P(A)P(B|A)=P(B)P(A|B) P(AB)=P(A)P(B∣A)=P(B)P(A∣B)
P ( A B C ) = P ( A ) P ( B ∣ A ) P ( C ∣ A B ) P(ABC)=P(A)P(B|A)P(C|AB) P(ABC)=P(A)P(B∣A)P(C∣AB)
P ( A 1 A 2 ⋯ A n ) = P ( A 1 ) P ( A 2 ∣ A 1 ) P ( A 3 ∣ A 1 A 2 ) ⋯ P ( A n ∣ A 1 A 2 ⋯ A n − 1 ) P(A_1A_2\cdots A_n)=P(A_1)P(A_2|A_1)P(A_3|A_1A_2)\cdots P(A_n|A_1A_2\cdots A_{n-1}) P(A1A2⋯An)=P(A1)P(A2∣A1)P(A3∣A1A2)⋯P(An∣A1A2⋯An−1) -
事件独立性(independent):设A,B是两随机事件,若 P ( A B ) = P ( A ) P ( B ) P(AB)=P(A)P(B) P(AB)=P(A)P(B),称事件A,B独立
A A A与 B B B独立 ⟺ A ˉ \iff \bar A ⟺Aˉ与 B B B独立 ⟺ A \iff A ⟺A与 B ˉ \bar B Bˉ独立 ⟺ A ˉ \iff \bar A ⟺Aˉ与 B ˉ \bar B Bˉ独立
事件 A , B , C 独立,指下式同时成立。若只有前三个式子成立,称为两两独立。两两独立并不能决定三个事件独立。
{ P ( A B ) = P ( A ) P ( B ) P ( B C ) = P ( C ) P ( C ) P ( A C ) = P ( A ) P ( C ) P ( A B C ) = P ( A ) P ( B ) P ( C ) \begin{cases} P(AB)=P(A)P(B) \\ P(BC)=P(C)P(C) \\ P(AC)=P(A)P(C) \\ P(ABC)=P(A)P(B)P(C) \end{cases} ⎩⎪⎪⎪⎨⎪⎪⎪⎧P(AB)=P(A)P(B)P(BC)=P(C)P(C)P(AC)=P(A)P(C)P(ABC)=P(A)P(B)P(C)
推广:事件 A 1 , A 2 , ⋯ , A n A_1,A_2,\cdots,A_n A1,A2,⋯,An 相互独立,则对 2 ⩽ k ⩽ n 2⩽ k ⩽ n 2⩽k⩽n均有
P ( A i 1 A i 2 ⋯ A i k ) = ∏ j = 1 k P ( A i j ) P(A_{i_1}A_{i_2}\cdots A_{i_k})=\displaystyle\prod_{j=1}^{k}P(A_{i_j}) P(Ai1Ai2⋯Aik)=j=1∏kP(Aij)
实际问题中,常常不是用定义去验证事件的独立性,而是由实际情形来判断其独立性.
一旦确定事件是相互独立的,在计算概率时,尽可能转化为事件的乘积进行计算 -
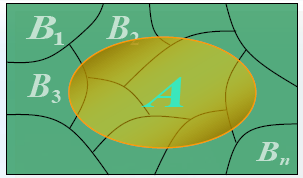
全概率公式 (complete probability formula):一个用于计算概率的公式,先化整为零,再聚零为整
设 B 1 , ⋯ , B n B_1,\cdots,B_n B1,⋯,Bn 是 S S S 的一个划分, A A A为事件,则 P ( A ) = ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(A)=\displaystyle\sum_{i=1}^{n}P(A|B_i)P(B_i) P(A)=i=1∑nP(A∣Bi)P(Bi)称 S S S 的事件 B 1 , ⋯ , B n B_1,\cdots,B_n B1,⋯,Bn 为一个划分,指它们满足
( 1 ) ⋃ i = 1 n B i = S ( 2 ) B i B j = ∅ , ( i , j = 1 , 2 , ⋯ , n ; i ≠ j ) (1)\ \displaystyle\bigcup_{i=1}^{n}B_i=S\quad (2)\ B_iB_j=\varnothing,(i,j=1,2,\cdots,n;\ i\neq j) (1) i=1⋃nBi=S(2) BiBj=∅,(i,j=1,2,⋯,n; i=j)
-
贝叶斯公式(Bayes formula):全概率公式通过划分 { B i ∣ i = 1 , ⋯ , n } \{B_i |i=1,\cdots,n\} {Bi∣i=1,⋯,n} 来计算一个事件 A A A 的概率,有时候需要弄清楚在A发生的条件下,每个 B i B_i Bi 发生的条件概率
设 B 1 , ⋯ , B n B_1,\cdots,B_n B1,⋯,Bn 是 S S S 的一个划分, A A A为事件,则对于 i = 1 , ⋯ , n i=1,\cdots,n i=1,⋯,n,有 P ( B i ∣ A ) = P ( A ∣ B i ) P ( B i ) ∑ i = 1 n P ( A ∣ B i ) P ( B i ) P(B_i|A)=\dfrac{P(A|B_i)P(B_i)}{\displaystyle\sum_{i=1}^{n}P(A|B_i)P(B_i)} P(Bi∣A)=i=1∑nP(A∣Bi)P(Bi)P(A∣Bi)P(Bi)
贝叶斯公式是关于随机事件 A A A和 B B B的条件概率和边缘概率的。
随机变量及其分布(Random Variable and Its Distribution)
随机变量(Random variable)
- 随机变量:设随机试验的样本空间为
S
S
S,若
X
=
X
(
e
)
X=X(e)
X=X(e)为定义在
S
S
S上的实值单值函数,则称
X
(
e
)
X(e)
X(e) 为随机变量, 简写为
X
X
X
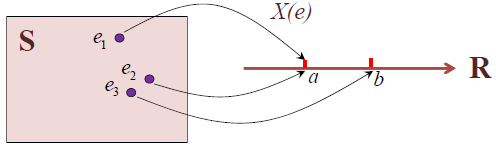
说明:
(1) 随机变量 X ( e ) : S → R X(e):S\to R X(e):S→R 为一映射,其自变量具有随机性;
(2) 随机事件可以表示为 A = { e : X ( e ) ∈ I } = { X ∈ I } , I ⊂ R A=\{e : X(e)\in I\}=\{X\in I\}, I⊂ \R A={e:X(e)∈I}={X∈I},I⊂R
如:将一枚均匀的硬币抛掷3次, 样本空间为
S = { H H H , H H T , H T H , H T T , T H H , T H T , T T H , T T T } S=\{HHH,HHT,HTH,HTT,THH,THT,TTH,TTT\} S={HHH,HHT,HTH,HTT,THH,THT,TTH,TTT}
若随机变量 X X X 表示3次中出现正面(H)的次数, 则
随机事件 A={正面出现了一次}={X=1}
随机事件 B={3次出现的情况相同}={X=0或3}
随机事件 C={正面至少出现了一次}={ X ⩾ 1 X⩾ 1 X⩾1}
(3) 对于 i ≠ j i\neq j i=j,则必有 { X = i } ∩ { X = j } = ∅ \{X=i\}∩\{X=j\}=\varnothing {X=i}∩{X=j}=∅
(4) 一般用大写英文字母 X,Y,Z 或希腊字母 ξ , η ξ,η ξ,η 等来表示随机变量
离散型随机变量及分布律(Discrete random variable & distribution law)
- 定义:若随机变量X的取值为有限个或可数 , 则称 X 为离散(discrete)型随机变量。
- 分布律 (distribution law):离散随机变量在各特定取值上的概率,也称概率质量函数(probability mass function, PMF)
P { X = x k } = p k , k = 1 , 2 , ⋯ P\{X=x_k\}=p_k,\ k=1,2,\cdots P{X=xk}=pk, k=1,2,⋯
| X X X | x 1 x 2 ⋯ x k ⋯ x_1\quad x_2 \quad \cdots\quad x_k\quad \cdots x1x2⋯xk⋯ | 随机变量的所有可能取值 |
|---|---|---|
| P P P | p 1 p 2 ⋯ p k ⋯ p_1\quad p_2 \quad \cdots\quad p_k\quad \cdots p1p2⋯pk⋯ | 取每个可能取值相应的概率 |
分布律满足: p k ⩾ 0 , ∑ k = 1 + ∞ p k = 1 p_k⩾ 0,\ \displaystyle\sum_{k=1}^{+∞}p_k=1 pk⩾0, k=1∑+∞pk=1
- 几种重要的离散型随机变量
0-1分布:随机变量X只能取0和1,又称两点分布或伯努利(Bernoulli)分布,记为 X ∼ B ( 1 , p ) X∼ B(1,p) X∼B(1,p)
P { X = k } = p k ( 1 − p ) 1 − k , k = 0 , 1 P\{X=k\}=p^k(1-p)^{1-k},\ k=0,1 P{X=k}=pk(1−p)1−k, k=0,1
常用它来表示两个状态的问题(即随机试验的结果只有两个,称为伯努利试验):
S = { s 1 , s 2 } , X ( s 1 ) = 1 , X ( s 2 ) = 0 S=\{s_1,s_2\},\quad X(s_1)=1,X(s_2)=0 S={s1,s2},X(s1)=1,X(s2)=0
应用:检查产品的质量是否合格;对新生婴儿的性别进行登记
二项分布(Binomial):将上述伯努利试验独立地做n次,称为n重伯努利试验。设状态 s 1 , s 2 s_1, s_2 s1,s2 在每次试验中出现的概率是不变的。设X为n次试验中状态 s 1 s_1 s1出现的次数,则X的取值为 0 , 1 , ⋯ , n 0, 1, \cdots , n 0,1,⋯,n ,而 X = k X=k X=k 的不同情况共有 ( n k ) {n \choose k} (kn) 种,他们是互斥的,于是 P { X = k } = ∁ n k p k ( 1 − p ) n − k , k = 1 , 2 , ⋯ , n P\{X=k\}=∁^k_np^k(1-p)^{n-k},k=1,2,\cdots,n P{X=k}=∁nkpk(1−p)n−k,k=1,2,⋯,n称具有上述分布律的随机变量为服从参数为n, p的二项分布, 记为 X ∼ B ( n , p ) X∼ B(n,p) X∼B(n,p)
应用:有放回抽样
泊松分布(Poisson):若的概率分布律为 P { X = k } = λ k e − λ k ! , k = 0 , 1 , 2 , ⋯ P\{X=k\}=\dfrac{λ^ke^{-λ}}{k!},k=0,1,2,\cdots P{X=k}=k!λke−λ,k=0,1,2,⋯其中 λ > 0 λ>0 λ>0,就称服从参数为 λ λ λ的泊松分布,记为 X ∼ π ( λ ) X∼ π(λ) X∼π(λ) 或 X ∼ P ( λ ) X∼ P(λ) X∼P(λ)
应用:一段时间内物理试验仪器捕获的粒子数;一本书中的错字数;
几何分布(geometric):在重复多次的伯努利试验中, 试验进行到某种结果首次出现为止, 此时X 的分布律为 P { X = k } = p ( 1 − p ) k − 1 , k = 1 , 2 , ⋯ P\{X=k\}=p(1-p)^{k-1},k=1,2,\cdots P{X=k}=p(1−p)k−1,k=1,2,⋯X 的这种分布由此等比数列(几何级数)表达, 故称为参数为p的几何分布。记为 X ∼ Geom ( p ) X∼ \text{Geom}(p) X∼Geom(p)
连续型随机变量及概率密度(Continuous random variable & probability density)
-
分布函数(distribution function):对于随机变量X,定义函数 F ( x ) = P { X ⩽ x } , ∀ x ∈ R F(x)=P\{X⩽ x\},∀ x\in \R F(x)=P{X⩽x},∀x∈R 称为X的累积分布函数(cumulative distribution function ,CDF) 。
任何随机变量都有相应的分布函数,分布函数可以给出随机变量落入任意一个范围的可能性。
一般地,离散型随机变量的分布函数为阶梯函数。
分布函数的基本性质:
(1) 0 ⩽ F ( x ) ⩽ 1 0⩽ F(x) ⩽ 1 0⩽F(x)⩽1
(2) F ( x ) F(x) F(x)是单调不减函数
(3) F ( − ∞ ) = lim x → − ∞ F ( x ) = 0 F ( + ∞ ) = lim x → + ∞ F ( x ) = 1 F(-∞)=\lim\limits_{x\to-∞}F(x)=0\\ F(+∞)=\lim\limits_{x\to+∞}F(x)=1 F(−∞)=x→−∞limF(x)=0F(+∞)=x→+∞limF(x)=1
(4) F ( x ) F(x) F(x)是右连续函数,即 F ( x ) = F ( x + 0 ) = lim y → x + F ( y ) F(x)=F(x+0)=\lim\limits_{y\to x^+}F(y) F(x)=F(x+0)=y→x+limF(y) -
连续型随机变量(continuous random variable):设随机变量 X 的分布函数 F(x) 可表成其中 F ( x ) = ∫ − ∞ x f ( t ) d t F(x)=\int_{-∞}^{x}f(t)\mathrm{d}t F(x)=∫−∞xf(t)dt其中 f ( x ) ⩾ 0 f(x)⩾ 0 f(x)⩾0, 则称X是连续型随机变量, f ( x ) f(x) f(x) 称为是 X 的概率密度函数(probability density function ,PDF),简称概率密度。
概率密度的性质:
(1) f ( x ) ⩾ 0 f(x)⩾ 0 f(x)⩾0
(2) ∫ − ∞ + ∞ f ( t ) d t = 1 \int_{-∞}^{+∞}f(t)\mathrm{d}t=1 ∫−∞+∞f(t)dt=1
(3) ∀ x 1 < x 2 , P { x 1 < X ⩽ x 2 } = F ( X 2 ) − F ( x 1 ) = ∫ x 1 x 2 f ( t ) d t ∀ x_1<x_2,P\{x_1<X⩽ x_2\}=F(X_2)-F(x_1)=\int_{x_1}^{x_2}f(t)\mathrm{d}t ∀x1<x2,P{x1<X⩽x2}=F(X2)−F(x1)=∫x1x2f(t)dt
(4) 在 F ( x ) F(x) F(x)的连续点, f ( x ) = F ′ ( x ) f(x)=F'(x) f(x)=F′(x)
几种重要的连续型分布
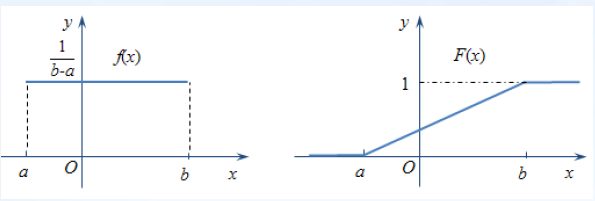
均匀分布(uniformly):若X的概率密度函数为 f ( x ) = { 1 b − a , x ∈ [ a , b ] 0 , x ∈ ( − ∞ , a ) ∪ ( b , + ∞ ) f(x)=\begin{cases}\dfrac{1}{b-a},x\in[a,b] \\ 0,x\in(-∞,a)∪(b,+∞) \end{cases} f(x)=⎩⎨⎧b−a1,x∈[a,b]0,x∈(−∞,a)∪(b,+∞)其中 a < b a<b a<b,就称X服从 [ a , b ] [a,b] [a,b]上的均匀分布,记为 X ∼ U ( a , b ) X∼ U(a,b) X∼U(a,b)
分布函数为 F ( x ) = { 0 , x < a x − a b − a , x ∈ [ a , b ] 1 , x > b F(x)=\begin{cases} 0,\quad x<a \\ \dfrac{x-a}{b-a},x\in[a,b] \\ 1,\quad x>b \end{cases} F(x)=⎩⎪⎪⎨⎪⎪⎧0,x<ab−ax−a,x∈[a,b]1,x>b
均匀分布具有等可能性:取值的概率只与小区间的长度有关,而与其位置无关。
指数分布(exponential):若X的概率密度函数为 f ( x ) = { 1 θ e − x / θ , x > 0 0 , x ⩽ 0 f(x)=\begin{cases} \frac{1}{θ}e^{-x/θ},x>0 \\ 0,\quad x⩽ 0 \end{cases} f(x)={θ1e−x/θ,x>00,x⩽0其中 θ > 0 θ>0 θ>0,就称X服从参数 θ θ θ的指数分布,记为 X ∼ E ( θ ) X∼ E(θ) X∼E(θ) 或 X ∼ E x p ( θ ) X∼ Exp(θ) X∼Exp(θ)
分布函数为 F ( x ) = { 1 − e − x / θ , x > 0 0 , x ⩽ 0 F(x)=\begin{cases} 1-e^{-x/θ},&x>0 \\ 0,&x⩽ 0 \end{cases} F(x)={1−e−x/θ,0,x>0x⩽0
指数分布具有无记忆性:对于 t 0 > 0 , t > 0 , P { X > t 0 + t ∣ X > t 0 } = P { X > t } t_0>0,t>0,P\{X>t_0+t|X>t_0\}=P\{X>t\} t0>0,t>0,P{X>t0+t∣X>t0}=P{X>t}
应用:通常用来描述生命周期;表示独立随机事件发生的时间间隔;
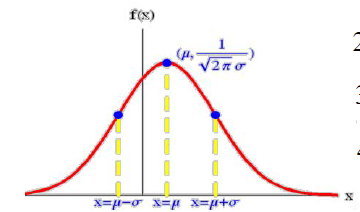
正态分布(normal distribution):连续型随机变量 X 如果有如下形式的概率密度函数 f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 ( μ ∈ R , σ > 0 ) f(x)=\dfrac{1}{\sqrt{2π}σ}e^{-\frac{(x-μ)^2}{2σ^2}}\quad (μ\in\R,σ>0) f(x)=2πσ1e−2σ2(x−μ)2(μ∈R,σ>0)则称 X 服从参数为 ( μ , σ 2 ) (μ,σ^2) (μ,σ2) 的正态分布 或高斯分布,记为 X ∼ N ( μ , σ 2 ) X∼ N(μ,σ^2) X∼N(μ,σ2)
特征:(1) f ( x ) f(x) f(x)关于 x = μ x=μ x=μ对称, f max = f ( μ ) = 1 2 π σ f_{\max}=f(μ)=\dfrac{1}{\sqrt{2π}σ} fmax=f(μ)=2πσ1
(2) 当 x ⩽ μ x⩽ μ x⩽μ时, f ( x ) f(x) f(x)是严格单调递增函数
(3) x = μ ± σ x=μ± σ x=μ±σ是 f ( x ) f(x) f(x)的拐点
(4) lim ∣ x − μ ∣ → + ∞ f ( x ) = 0 \lim\limits_{|x-μ|\to+∞}f(x)=0 ∣x−μ∣→+∞limf(x)=0
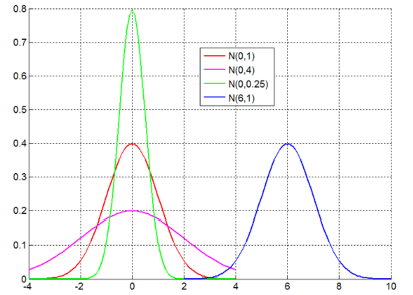
两个参数的含义:
(1) 当固定 σ 改变 μ 的大小时,图形的形状不变,只是沿着 x 轴作平移变换;
μ 称为位置参数,决定对称轴位置
(2) 当固定 μ 改变 σ 的大小时,图形的对称轴不变,而形状在改变, σ 越小图形越高越瘦,σ 越大图形越矮越胖;
σ 称为尺度参数,决定曲线分散程度
应用:测量值与实际值的误差;分子热运动时每个分子的运动速率;
若 X ∼ N ( μ , σ 2 ) , X X∼ N(μ,σ^2), X X∼N(μ,σ2),X的分布函数 F ( x ) = P { X ⩽ x } = ∫ − ∞ x f ( t ) d t F(x)=P\{X⩽ x\}=\int_{-∞}^{x}f(t)\mathrm{d}t F(x)=P{X⩽x}=∫−∞xf(t)dt一般无解析解。
标准正态分布(standard normal distribution):若
Z
∼
N
(
0
,
1
)
Z∼ N(0,1)
Z∼N(0,1) 称 Z 服从标准正态分布
Z 的概率密度函数:
ϕ
(
z
)
=
1
2
π
e
−
z
2
2
ϕ(z)=\dfrac{1}{\sqrt{2π}}e^{-\frac{z^2}{2}}
ϕ(z)=2π1e−2z2
Z 的分布函数:
Φ
(
z
)
=
∫
−
∞
z
1
2
π
e
−
t
2
2
d
t
Φ(z)=\int_{-∞}^{z}\dfrac{1}{\sqrt{2π}}e^{-\frac{t^2}{2}}\mathrm{d}t
Φ(z)=∫−∞z2π1e−2t2dt
重要性质:关于 轴的对称
Φ
(
−
z
0
)
=
1
−
Φ
(
z
0
)
Φ(-z_0)=1-Φ(z_0)
Φ(−z0)=1−Φ(z0)
当
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X∼N(μ,σ2)时,
X
−
μ
σ
∼
N
(
0
,
1
)
\frac{X-μ}{σ}∼ N(0,1)
σX−μ∼N(0,1),由此可知
∀
a
∈
R
,
F
X
(
a
)
=
P
{
X
⩽
a
}
=
P
{
X
−
μ
σ
⩽
a
−
μ
σ
}
=
Φ
(
a
−
μ
σ
)
∀ a\in\R,F_X(a)=P\{X⩽ a\}=P\{\frac{X-μ}{σ} ⩽ \frac{a-μ}{σ}\}=Φ(\frac{a-μ}{σ})
∀a∈R,FX(a)=P{X⩽a}=P{σX−μ⩽σa−μ}=Φ(σa−μ)
常采用的3σ原则: P { ∣ X − μ ∣ ⩽ 3 σ } ≈ 0.9974 P\{|X-μ|⩽ 3σ\}\approx 0.9974 P{∣X−μ∣⩽3σ}≈0.9974
随机变量的函数(Random variable function)
有时我们关心的随机变量不是直接观测得到的随机变量,而是它的函数。
如要得到一个圆的面积 Y,总是测量其半径,半径的测量值可看作随机变量X,若
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X∼N(μ,σ2),则 Y 的分布是什么?
一般地,设 X 为一随机变量, 分布已知.。
Y
=
g
(
X
)
Y=g(X)
Y=g(X), 其中 g 为一确定的实函数, 要求 Y 的分布。仍讨论离散型与连续型两种情况:
(1) 设 X 为离散型,求 Y 的分布律
先逐个算出 Y 的取值
g
(
x
1
)
,
g
(
x
2
)
,
⋯
g(x_1), g(x_2), \cdots
g(x1),g(x2),⋯, 每个
g
(
x
k
)
g(x_k)
g(xk)对应的概率为
p
k
p_k
pk;再合并所有相同的
g
(
x
k
)
g(x_k)
g(xk), 并将对应的
p
k
p_k
pk 相加。
(2) 设 X 为连续型随机变量, 具有概率密度
f
X
(
x
)
f_X (x)
fX(x), 又设
Y
=
g
(
X
)
Y=g(X)
Y=g(X)亦为连续型随机变量,求其概率密度
f
Y
(
y
)
f_Y(y)
fY(y)
先求分布函数
F
Y
(
y
)
=
P
{
Y
⩽
y
}
=
P
{
g
(
X
)
⩽
y
}
=
∫
D
f
X
(
x
)
d
x
F_Y(y)=P\{Y⩽ y\}=P\{g(X)⩽ y\}=\int_Df_X(x)\mathrm{d}x
FY(y)=P{Y⩽y}=P{g(X)⩽y}=∫DfX(x)dx,其中积分区域
D
=
{
x
∣
g
(
x
)
⩽
y
}
D=\{x|g(x)⩽ y \}
D={x∣g(x)⩽y},然后对分布函数求导, 得到概率概率密度。
定理:设随机变量 X ∼ F X ( x ) , x ∈ R , Y = g ( X ) , g ′ ( X ) > 0 或 g ′ ( X ) < 0 X∼ F_X(x),x\in\R,\ Y=g(X),g'(X)>0或g'(X)<0 X∼FX(x),x∈R, Y=g(X),g′(X)>0或g′(X)<0,则具有概率密度为 f Y ( y ) = { f X [ h ( y ) ] ⋅ ∣ h ′ ( y ) ∣ , y ∈ [ a , b ] 0 , y ∈ ( − ∞ , a ) ∪ ( b , + ∞ ) f_Y(y)=\begin{cases} f_X[h(y)]\cdot |h'(y)|,\ y\in[a,b] \\ 0,y\in(-∞,a)∪(b,+∞) \end{cases} fY(y)={fX[h(y)]⋅∣h′(y)∣, y∈[a,b]0,y∈(−∞,a)∪(b,+∞)其中 [ a , b ] [a,b] [a,b]是 Y 的取值范围,h是g 的反函数,即 h ( y ) = x h(y)=x h(y)=x
一般地,若随机变量
X
∼
N
(
μ
,
σ
2
)
X∼ N(μ,σ^2)
X∼N(μ,σ2)
则
Y
=
a
X
+
b
⟹
Y
∼
N
(
a
μ
+
b
,
a
2
σ
2
)
Y=aX+b\implies Y∼ N(aμ+b,a^2σ^2)
Y=aX+b⟹Y∼N(aμ+b,a2σ2)
多维随机变量及其分布(Multiple Random Variable and Its Distribution)
二维随机变量(Two-dimensional random variable)
-
二维随机变量:设E是一个随机试验,样本空间 S = e S={e} S=e;设 X = X ( e ) X=X(e) X=X(e)和 Y = Y ( e ) Y=Y(e) Y=Y(e)是定义在S上的随机变量,由它们构成的向量 ( X , Y ) (X,Y) (X,Y)称为二维随机向量或二维随机变量。
二维随机变量分布函数:设 ( X , Y ) (X,Y) (X,Y) 是二维随机变量,对于任意 ( x , y ) ∈ R 2 (x,y)\in\R^2 (x,y)∈R2,二维函数 F ( x , y ) = P { { X ⩽ x } ∩ { Y ⩽ y } } ≜ P { X ⩽ x , Y ⩽ y } F(x,y)=P\{\{X⩽ x\}∩\{Y⩽ y\}\}\triangleq P\{X⩽ x,Y⩽ y\} F(x,y)=P{{X⩽x}∩{Y⩽y}}≜P{X⩽x,Y⩽y}称为二维随机变量的联合分布函数 ( joint distribution function,JDF)。
性质:
1。 F ( x , y ) F(x, y) F(x,y)为单调不减函数
2。 ∀ x , y , 0 ⩽ F ( x , y ) ⩽ 1 , F ( + ∞ , + ∞ ) = 1 , F ( − ∞ , y ) = F ( x , − ∞ ) = F ( − ∞ , − ∞ ) = 0 ∀ x,y,\ 0⩽ F(x, y) ⩽ 1, \\ F(+∞,+∞)=1,F(-∞,y)=F(x,-∞)=F(-∞,-∞)=0 ∀x,y, 0⩽F(x,y)⩽1,F(+∞,+∞)=1,F(−∞,y)=F(x,−∞)=F(−∞,−∞)=0
3。 F ( x , y ) F(x, y) F(x,y)关于 x , y x,y x,y右连续,即: lim ϵ → 0 + F ( x + ϵ , y ) = lim ϵ → 0 + F ( x , y + ϵ ) = F ( x , y ) \lim\limits_{ϵ\to 0^+}F(x+ϵ,y)=\lim\limits_{ϵ\to 0^+}F(x,y+ϵ)=F(x,y) ϵ→0+limF(x+ϵ,y)=ϵ→0+limF(x,y+ϵ)=F(x,y)
4。 x 1 < x 2 , y 1 < y 2 ⟹ P { x 1 < X ⩽ x 2 , y 1 < Y ⩽ y 2 } = F ( x 2 , y 2 ) − F ( x 1 , y 2 ) − F ( x 2 , y 1 ) + F ( x 1 , y 1 ) ⩾ 0 x_1<x_2,y_1<y_2\\ \implies P\{x_1<X ⩽ x_2,y_1<Y ⩽ y_2\}=F(x_2,y_2)-F(x_1,y_2)-F(x_2,y_1)+F(x_1,y_1) ⩾ 0 x1<x2,y1<y2⟹P{x1<X⩽x2,y1<Y⩽y2}=F(x2,y2)−F(x1,y2)−F(x2,y1)+F(x1,y1)⩾0

-
二维离散型随机变量:若二维随机变量 ( X , Y ) (X,Y) (X,Y)全部可能取到的不同值是有限对或可列无限对,则称 ( X , Y ) (X,Y) (X,Y)是二维离散型随机变量。
联合分布律:设 ( X , Y ) (X,Y) (X,Y)所有可能取值为 ( X i , Y i ) (X_i,Y_i) (Xi,Yi),称 P { X = x i , Y = y j } = p i j , i , j = 1 , 2 , ⋯ P\{X=x_i,Y=y_j\}=p_{ij},i,j=1,2,\cdots P{X=xi,Y=yj}=pij,i,j=1,2,⋯为二维离散型随机变量 ( X , Y ) (X,Y) (X,Y)的联合(概率)分布律。
联合分布律的性质: ( 1 ) 0 ⩽ p i j ⩽ 1 ; ( 2 ) ∑ i = 1 ∞ ∑ j = 1 ∞ p i j = 1 (1)\ 0 ⩽ p_{ij} ⩽ 1;\quad (2)\ \displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}p_{ij}=1 (1) 0⩽pij⩽1;(2) i=1∑∞j=1∑∞pij=1 -
二维连续型随机变量:设二维随机变量 ( X , Y ) (X, Y) (X,Y) 的分布函数 F ( x , y ) , ∃ f ( x , y ) ⩾ 0 , ∀ ( x , y ) ∈ R 2 F(x,y), ∃ f(x,y)⩾0,∀ (x,y)\in\R^2 F(x,y),∃f(x,y)⩾0,∀(x,y)∈R2有 F ( x , y ) = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v F(x,y)=\int_{-∞}^{x}\int_{-∞}^{y}f(u,v)\mathrm{d}u\mathrm{d}v F(x,y)=∫−∞x∫−∞yf(u,v)dudv则称 ( X , Y ) (X, Y) (X,Y) 为二维连续型随机变量, f ( x , y ) f(x,y) f(x,y) 称为是 ( X , Y ) (X, Y) (X,Y) 的联合概率密度(函数)。
概率密度的性质:
1。 f ( x , y ) ⩾ 0 f(x,y)⩾0 f(x,y)⩾0
2。 ∫ − ∞ + ∞ ∫ − ∞ + ∞ f ( x , y ) d x d y = 1 \int_{-∞}^{+∞}\int_{-∞}^{+∞}f(x,y)\mathrm{d}x\mathrm{d}y=1 ∫−∞+∞∫−∞+∞f(x,y)dxdy=1
3。在 f ( x , y ) f ( x , y ) f(x,y) 的连续点处,有 ∂ F ( x , y ) ∂ x ∂ y = f ( x , y ) \dfrac{∂ F(x,y)}{∂ x∂ y}=f(x,y) ∂x∂y∂F(x,y)=f(x,y)
4。对于任何 R 2 \R^2 R2上的区域G, 有 P { ( X , Y ) ∈ G } = ∬ G f ( u , v ) d u d v P\{(X,Y)\in G\}=\iint\limits_G f(u,v)\mathrm{d}u\mathrm{d}v P{(X,Y)∈G}=G∬f(u,v)dudv
边缘分布(Marginal distribution)
边缘分布律:对分布律为
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P{X=xi,Y=yj}=pij 的二维离散型随机变量
P
{
X
=
x
i
}
=
P
{
X
=
x
i
,
⋃
j
=
1
∞
{
Y
=
y
j
}
}
=
∑
j
=
1
∞
p
i
j
≜
p
i
∙
\displaystyle P\{X=x_i\}=P\{X=x_i,\bigcup^{∞}_{j=1}\{Y=y_j\}\}=\sum_{j=1}^{∞}p_{ij}\triangleq p_{i\bullet}
P{X=xi}=P{X=xi,j=1⋃∞{Y=yj}}=j=1∑∞pij≜pi∙
同理,
P
{
Y
=
y
j
}
=
P
{
⋃
i
=
1
∞
{
X
=
x
i
}
,
Y
=
y
j
}
=
∑
i
=
1
∞
p
i
j
≜
p
∙
j
\displaystyle P\{Y=y_j\}=P\{\bigcup^{∞}_{i=1}\{X=x_i\},Y=y_j\}=\sum_{i=1}^{∞}p_{ij}\triangleq p_{\bullet j}
P{Y=yj}=P{i=1⋃∞{X=xi},Y=yj}=i=1∑∞pij≜p∙j
X / Y y 1 y 2 ⋯ y j ⋯ P { X = x i } x 1 p 11 p 12 ⋯ p 1 j ⋯ p 1 ∙ x 2 p 21 p 22 ⋯ p 2 j ⋯ p 2 ∙ ⋮ ⋯ ⋯ ⋯ ⋮ x i p i 1 p i 2 ⋯ p i j ⋯ p i ∙ ⋮ ⋯ ⋯ ⋯ ⋮ P { Y = y j } p ∙ 1 p ∙ 2 ⋯ p ∙ j ⋯ 1 \begin{array}{c|ccccc|c} X/Y &y_1&y_2&\cdots&y_j&\cdots &P\{X=x_i\} \\ \hline x_1 &p_{11}&p_{12}&\cdots&p_{1j}&\cdots &p_{1 \bullet} \\ x_2 &p_{21}&p_{22}&\cdots&p_{2j}&\cdots &p_{2 \bullet} \\ \vdots &\cdots&&\cdots&&\cdots &\vdots \\ x_i&p_{i1}&p_{i2}&\cdots&p_{ij}&\cdots &p_{i \bullet} \\ \vdots &\cdots&&\cdots&&\cdots &\vdots \\ \hline P\{Y=y_j\} &p_{\bullet 1}&p_{\bullet 2}&\cdots&p_{\bullet j}&\cdots &1 \end{array} X/Yx1x2⋮xi⋮P{Y=yj}y1p11p21⋯pi1⋯p∙1y2p12p22pi2p∙2⋯⋯⋯⋯⋯⋯⋯yjp1jp2jpijp∙j⋯⋯⋯⋯⋯⋯⋯P{X=xi}p1∙p2∙⋮pi∙⋮1
边缘概率密度:对概率密度为
f
(
x
,
y
)
f(x,y)
f(x,y)的二维连续型随机变量
f
X
(
x
)
=
∫
−
∞
+
∞
f
(
x
,
y
)
d
y
f
Y
(
y
)
=
∫
−
∞
+
∞
f
(
x
,
y
)
d
x
f_X(x)=\int_{-∞}^{+∞}f(x,y)\mathrm{d}y\\ f_Y(y)=\int_{-∞}^{+∞}f(x,y)\mathrm{d}x
fX(x)=∫−∞+∞f(x,y)dyfY(y)=∫−∞+∞f(x,y)dx
边缘分布函数:可以由
(
X
,
Y
)
(X,Y)
(X,Y)的分布函数所确定
F
X
(
x
)
≜
P
{
X
⩽
x
,
Y
<
+
∞
}
=
F
(
x
,
+
∞
)
=
lim
y
→
+
∞
F
(
x
,
y
)
F_X(x)\triangleq P\{X ⩽ x,Y<+∞\}=F(x,+∞)=\lim\limits_{y\to +∞}F(x,y)
FX(x)≜P{X⩽x,Y<+∞}=F(x,+∞)=y→+∞limF(x,y)
F
Y
(
y
)
≜
P
{
X
<
+
∞
,
Y
⩽
y
}
=
F
(
+
∞
,
y
)
=
lim
x
→
+
∞
F
(
x
,
y
)
F_Y(y)\triangleq P\{X<+∞,Y ⩽ y\}=F(+∞,y)=\lim\limits_{x\to +∞}F(x,y)
FY(y)≜P{X<+∞,Y⩽y}=F(+∞,y)=x→+∞limF(x,y)
相互独立(mutual independence):
∀
x
,
y
,
F
(
x
,
y
)
=
F
X
(
x
)
F
Y
(
y
)
∀ x,y,F(x,y)=F_X(x)F_Y(y)
∀x,y,F(x,y)=FX(x)FY(y)称随机变量X ,Y相互独立。
二维离散型:
⟺
p
i
j
=
p
i
∙
p
∙
j
\iff p_{ij}=p_{i \bullet}p_{\bullet j}
⟺pij=pi∙p∙j
二维连续型:
⟺
f
(
x
,
y
)
=
f
X
(
x
)
f
Y
(
y
)
\iff f(x,y)=f_X(x)f_Y(y)
⟺f(x,y)=fX(x)fY(y)
条件分布(Conditional distribution)
条件分布(conditional distribution):对二维离散型随机变量
(
X
,
Y
)
(X,Y)
(X,Y)
P
{
X
=
x
i
∣
Y
=
y
j
}
=
P
{
X
=
x
i
,
Y
=
y
j
}
P
{
Y
=
y
j
}
=
p
i
j
p
∙
j
P\{X=x_i|Y=y_j\}=\dfrac{P\{X=x_i,Y=y_j\}}{P\{Y=y_j\}}=\dfrac{p_{ij}}{p_{\bullet j}}
P{X=xi∣Y=yj}=P{Y=yj}P{X=xi,Y=yj}=p∙jpij
同理,
P
{
Y
=
y
j
∣
X
=
x
i
}
=
P
{
X
=
x
i
,
Y
=
y
j
}
P
{
X
=
x
i
}
=
p
i
j
p
i
∙
P\{Y=y_j|X=x_i\}=\dfrac{P\{X=x_i,Y=y_j\}}{P\{X=x_i\}}=\dfrac{p_{ij}}{p_{i \bullet}}
P{Y=yj∣X=xi}=P{X=xi}P{X=xi,Y=yj}=pi∙pij
条件概率密度:对二维连续型随机变量
(
X
,
Y
)
(X,Y)
(X,Y)
当
Y
=
y
Y=y
Y=y时,X的条件概率密度
f
X
∣
Y
(
x
∣
y
)
=
f
(
x
,
y
)
f
Y
(
y
)
f_{X|Y}(x|y)=\dfrac{f(x,y)}{f_Y(y)}
fX∣Y(x∣y)=fY(y)f(x,y)
同理
f
Y
∣
X
(
y
∣
x
)
=
f
(
x
,
y
)
f
X
(
x
)
f_{Y|X}(y|x)=\dfrac{f(x,y)}{f_X(x)}
fY∣X(y∣x)=fX(x)f(x,y)
条件分布函数:
F
X
∣
Y
(
x
∣
y
)
=
P
{
X
⩽
x
∣
Y
=
y
}
=
{
P
{
X
⩽
x
,
Y
=
y
}
P
{
Y
=
y
}
,
P
{
Y
=
y
}
>
0
,
即
Y
为
离
散
型
随
机
变
量
lim
ϵ
→
0
+
P
{
X
⩽
x
,
y
<
Y
⩽
y
+
ϵ
}
P
{
y
<
Y
⩽
y
+
ϵ
}
,
P
{
Y
=
y
}
=
0
,
即
Y
为
连
续
型
随
机
变
量
F_{X|Y}(x|y)=P\{X⩽ x|Y=y\}= \\ \begin{cases} \dfrac{P\{X⩽ x,Y=y\}}{P\{Y=y\}}, & P\{Y=y\}>0,即Y为离散型随机变量 \\ \\ \lim\limits_{ϵ\to 0^+}\dfrac{P\{X⩽ x,y<Y⩽ y+ϵ\}}{P\{y<Y⩽ y+ϵ\}},&P\{Y=y\}=0,即Y为连续型随机变量 \end{cases}
FX∣Y(x∣y)=P{X⩽x∣Y=y}=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧P{Y=y}P{X⩽x,Y=y},ϵ→0+limP{y<Y⩽y+ϵ}P{X⩽x,y<Y⩽y+ϵ},P{Y=y}>0,即Y为离散型随机变量P{Y=y}=0,即Y为连续型随机变量
常见的二维随机变量分布(Usual two-dimensional distribution of random variables)
二维均匀分布:概率密度函数 f ( x , y ) = { 1 / A , ( x , y ) ∈ D 0 , ( x , y ) ∉ D , 其 中 A 为 D 的 面 积 f(x,y)=\begin{cases} 1/A,&(x,y)\in D \\ 0,&(x,y) \not\in D \end{cases},其中A为D的面积 f(x,y)={1/A,0,(x,y)∈D(x,y)∈D,其中A为D的面积
二维正态分布:
(1) 设
Z
1
,
Z
2
Z_1, Z_2
Z1,Z2 为独立同分布
N
(
0
,
1
)
N(0,1)
N(0,1) 的随机变量,则
Z
1
,
Z
2
Z_1, Z_2
Z1,Z2 的联合密度函数为
f
(
z
1
,
z
2
)
=
1
2
π
e
−
1
2
(
z
1
2
+
z
2
2
)
f(z_1,z_2)=\frac{1}{2π}e^{-\frac{1}{2}(z_1^2+z_2^2)}
f(z1,z2)=2π1e−21(z12+z22)
(2) 作变换,令
{
X
=
σ
1
Z
1
+
μ
1
Y
=
σ
2
(
ρ
Z
1
+
1
−
ρ
2
Z
2
)
+
μ
2
(
σ
1
,
σ
2
>
0
,
∣
ρ
∣
<
1
)
\begin{cases} X=σ_1Z_1+μ _1 \\ Y=σ_2(ρZ_1+\sqrt{1-ρ^2}Z_2)+μ _2 \end{cases}\quad (σ_1,σ_2>0,|ρ|<1)
{X=σ1Z1+μ1Y=σ2(ρZ1+1−ρ2Z2)+μ2(σ1,σ2>0,∣ρ∣<1)
则称
(
X
,
Y
)
(X ,Y)
(X,Y) 服从参数为
(
μ
1
,
μ
2
,
σ
1
2
,
σ
2
2
,
ρ
)
(μ _1,μ _2,σ_1^2,σ_2^2,ρ)
(μ1,μ2,σ12,σ22,ρ) 的二维正态分布,记为
(
X
,
Y
)
∼
N
(
μ
1
,
μ
2
,
σ
1
2
,
σ
2
2
,
ρ
)
(X ,Y)∼ N(μ _1,μ _2,σ_1^2,σ_2^2,ρ)
(X,Y)∼N(μ1,μ2,σ12,σ22,ρ)
变换可写成矩阵式:
(
X
Y
)
=
A
(
Z
1
Z
2
)
+
(
μ
1
μ
2
)
\begin{pmatrix} X\\ Y\end{pmatrix} =A \begin{pmatrix} Z_1\\ Z_2\end{pmatrix}+ \begin{pmatrix} μ _1\\ μ _2\end{pmatrix}
(XY)=A(Z1Z2)+(μ1μ2)
其中
A
=
(
σ
1
0
σ
2
ρ
σ
2
1
−
ρ
2
)
A=\begin{pmatrix} σ_1&0\\ σ_2ρ&σ_2\sqrt{1-ρ^2}\end{pmatrix}
A=(σ1σ2ρ0σ21−ρ2),于是
(
Z
1
Z
2
)
=
A
−
1
(
X
−
μ
1
Y
−
μ
2
)
\begin{pmatrix} Z_1\\ Z_2\end{pmatrix} =A^{-1} \begin{pmatrix} X-μ _1\\ Y-μ _2\end{pmatrix}
(Z1Z2)=A−1(X−μ1Y−μ2)
将此式代入
Z
1
,
Z
2
Z_1, Z_2
Z1,Z2 的联合密度式,并注意到此变换中雅可比行列式为
∣
J
∣
=
det
A
−
1
=
1
σ
1
σ
2
1
−
ρ
2
|J|=\det A^{-1}=\dfrac{1}{σ_1σ_2\sqrt{1-ρ^2}}
∣J∣=detA−1=σ1σ21−ρ21
即得
(
X
,
Y
)
(X ,Y)
(X,Y) 的联合密度
f
(
x
,
y
)
f(x,y)
f(x,y) (过于复杂,就不写了!)
由定义知若
ρ
=
0
ρ=0
ρ=0 , 则
X
=
σ
1
Z
1
+
μ
1
,
Y
=
σ
2
Z
2
+
μ
2
X=σ_1Z_1+μ _1,Y=σ_2Z_2+μ _2
X=σ1Z1+μ1,Y=σ2Z2+μ2,即 X 与 Y 独立。从密度函数看,X 与Y 地位是对称的,决定了它们的分布特点是一致的.
二维正态的定义的特点使得许多分布规律的计算十分简单。
边缘概率密度:因
X
=
σ
1
Z
1
+
μ
1
X=σ_1Z_1+μ _1
X=σ1Z1+μ1,故
X
∼
N
(
μ
1
,
σ
1
2
)
X∼ N(μ _1,σ_1^2)
X∼N(μ1,σ12),由对称性可知
Y
∼
N
(
μ
2
,
σ
2
2
)
Y∼ N(μ _2,σ_2^2)
Y∼N(μ2,σ22),两个边缘分布均与ρ无关
条件概率密度:由于
Z
1
=
x
−
μ
1
σ
1
Z_1=\frac{x-μ _1}{σ_1}
Z1=σ1x−μ1,故
Y
∣
X
=
x
∼
N
(
σ
2
ρ
σ
1
(
x
−
μ
1
)
,
σ
2
2
(
1
−
ρ
2
)
)
Y|_{X=x}∼ N(\frac{σ_2ρ}{σ_1}(x-μ _1),σ_2^2(1-ρ^2))
Y∣X=x∼N(σ1σ2ρ(x−μ1),σ22(1−ρ2))
由对称性可知
X
∣
Y
=
y
∼
N
(
σ
1
ρ
σ
2
(
y
−
μ
2
)
,
σ
1
2
(
1
−
ρ
2
)
)
X|_{Y=y}∼ N(\frac{σ_1ρ}{σ_2}(y-μ _2),σ_1^2(1-ρ^2))
X∣Y=y∼N(σ2σ1ρ(y−μ2),σ12(1−ρ2))
两个随机变量的函数的分布(The distribution of two random-variables functions)
二维离散:设二维离散型随机变量
(
X
,
Y
)
(X ,Y)
(X,Y)具有分布律
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P{X=xi,Y=yj}=pij
(1) 若
U
=
u
(
X
,
Y
)
U=u(X,Y)
U=u(X,Y),求
U
U
U的分布律
先确定
U
U
U的取值
u
i
u_i
ui,再找出
P
{
U
=
u
i
}
=
P
{
(
X
,
Y
)
∈
D
}
P\{U=u_i\}=P\{(X,Y)\in D\}
P{U=ui}=P{(X,Y)∈D}计算分布律
(2) 若
U
=
u
(
X
,
Y
)
,
V
=
v
(
X
,
Y
)
U=u(X,Y),V=v(X,Y)
U=u(X,Y),V=v(X,Y),求
(
U
,
V
)
(U,V)
(U,V)的分布律
先确定
(
U
,
V
)
(U,V)
(U,V)的取值
(
u
i
,
v
i
)
(u_i,v_i)
(ui,vi),再找出
P
{
U
=
u
i
,
V
=
v
i
}
=
P
{
(
X
,
Y
)
∈
D
}
P\{U=u_i,V=v_i\}=P\{(X,Y)\in D\}
P{U=ui,V=vi}=P{(X,Y)∈D}计算分布律
二维连续:设二维连续型随机变量
(
X
,
Y
)
(X ,Y)
(X,Y)具有概率密度
f
(
x
,
y
)
f(x,y)
f(x,y)
(1) 若
Z
=
g
(
X
,
Y
)
Z=g(X,Y)
Z=g(X,Y),求
Z
Z
Z的分布函数或概率密度
先求Z的分布函数
F
Z
(
z
)
=
P
{
Z
⩽
z
}
=
P
{
g
(
X
,
Y
)
⩽
z
}
=
∬
g
(
x
,
y
)
⩽
z
f
(
x
,
y
)
d
x
d
y
\displaystyle F_Z(z)=P\{Z⩽ z\}=P\{g(X,Y)⩽ z\}=\iint\limits_{g(x,y)⩽ z}f(x,y)\mathrm{d}x\mathrm{d}y
FZ(z)=P{Z⩽z}=P{g(X,Y)⩽z}=g(x,y)⩽z∬f(x,y)dxdy
再求导得到密度函数
f
Z
(
z
)
=
F
Z
′
(
z
)
f_Z(z)=F'_Z(z)
fZ(z)=FZ′(z)
(2) 若
(
U
,
V
)
(U,V)
(U,V)为
(
X
,
Y
)
(X,Y)
(X,Y)的一个变换,并设变换的雅可比矩阵存在, 且行列式不为零,求
(
U
,
V
)
(U,V)
(U,V)的概率密度
因
(
U
,
V
)
(U,V)
(U,V)为
(
X
,
Y
)
(X,Y)
(X,Y)的一个变换,故可设
X
=
x
(
U
,
V
)
,
Y
=
y
(
U
,
V
)
X=x(U,V),Y=y(U,V)
X=x(U,V),Y=y(U,V)
又
(
U
,
V
)
(U,V)
(U,V)的分布函数可表为
G
(
u
,
v
)
=
P
{
U
⩽
u
,
V
⩽
v
}
=
∬
U
⩽
u
,
V
⩽
v
f
(
x
,
y
)
d
x
d
y
\displaystyle G(u,v)=P\{U⩽ u,V⩽ v\}=\iint\limits_{U⩽ u,V⩽ v}f(x,y)\mathrm{d}x\mathrm{d}y
G(u,v)=P{U⩽u,V⩽v}=U⩽u,V⩽v∬f(x,y)dxdy
将上述变换用于积分,即得
G
(
u
,
v
)
=
∫
−
∞
u
∫
−
∞
v
f
[
x
(
s
,
t
)
,
y
(
s
,
t
)
]
∣
J
(
s
,
t
)
∣
d
s
d
t
\displaystyle G(u,v)=\int_{-∞}^{u}\int_{-∞}^{v}f[x(s,t),y(s,t)]|J(s,t)|\mathrm{d}s\mathrm{d}t
G(u,v)=∫−∞u∫−∞vf[x(s,t),y(s,t)]∣J(s,t)∣dsdt
对上式求两阶偏导,即得
g
(
u
,
v
)
=
∂
2
G
(
u
,
v
)
∂
u
∂
v
=
f
[
x
(
s
,
t
)
,
y
(
s
,
t
)
]
∣
J
(
s
,
t
)
∣
g(u,v)=\dfrac{∂^2G(u,v)}{∂ u ∂ v}=f[x(s,t),y(s,t)]|J(s,t)|
g(u,v)=∂u∂v∂2G(u,v)=f[x(s,t),y(s,t)]∣J(s,t)∣
连续型随机变量
Z
=
X
+
Y
Z=X+Y
Z=X+Y的分布
F
Z
(
z
)
=
∫
−
∞
z
f
Z
(
u
)
d
u
F_Z(z)=\int_{-∞}^{z}f_Z(u)\mathrm{d}u
FZ(z)=∫−∞zfZ(u)du
f
Z
(
z
)
=
∫
−
∞
+
∞
f
(
z
−
y
,
y
)
d
y
=
∫
−
∞
+
∞
f
(
x
,
z
−
x
)
d
x
f_Z(z)=\int_{-∞}^{+∞}f(z-y,y)\mathrm{d}y=\int_{-∞}^{+∞}f(x,z-x)\mathrm{d}x
fZ(z)=∫−∞+∞f(z−y,y)dy=∫−∞+∞f(x,z−x)dx
特别, 若X与Y 独立, 则有
f
Z
(
z
)
=
∫
−
∞
+
∞
f
X
(
z
−
y
)
f
Y
(
y
)
d
y
=
∫
−
∞
+
∞
f
Y
(
z
−
x
)
f
X
(
x
)
d
x
f_Z(z)=\int_{-∞}^{+∞}f_X(z-y)f_Y(y)\mathrm{d}y=\int_{-∞}^{+∞}f_Y(z-x)f_X(x)\mathrm{d}x
fZ(z)=∫−∞+∞fX(z−y)fY(y)dy=∫−∞+∞fY(z−x)fX(x)dx
称
f
Z
f_Z
fZ 为
f
X
f_X
fX 与
f
Y
f_Y
fY 的卷积,记为
f
Z
=
f
X
∗
f
Y
f_Z=f_X * f_Y
fZ=fX∗fY
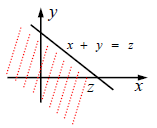
对于一般的两独立正态随机变量
X
∼
N
(
μ
1
,
σ
1
2
)
,
Y
∼
N
(
μ
2
,
σ
2
2
)
⟹
Z
=
X
+
Y
∼
N
(
μ
1
+
μ
2
,
σ
1
2
+
σ
2
2
)
X∼ N(μ _1,σ_1^2),Y∼ N(μ _2,σ_2^2)\implies Z=X+Y∼ N(μ _1+μ _2,σ_1^2+σ_2^2)
X∼N(μ1,σ12),Y∼N(μ2,σ22)⟹Z=X+Y∼N(μ1+μ2,σ12+σ22)
独立的离散型变量的和分布
(1)
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn独立且服从分布
B
(
1
,
p
)
B(1,p)
B(1,p),则
X
1
+
X
2
+
⋯
+
X
n
∼
B
(
n
,
p
)
X_1+X_2+\cdots+X_n∼ B(n,p)
X1+X2+⋯+Xn∼B(n,p)
(2)
X
1
∼
B
(
n
1
,
p
)
,
X
2
∼
B
(
n
2
,
p
)
X_1∼ B(n_1,p),X_2∼ B(n_2,p)
X1∼B(n1,p),X2∼B(n2,p),且两者独立,则
X
1
+
X
2
∼
B
(
n
1
+
n
2
,
p
)
X_1+X_2∼ B(n_1+n_2,p)
X1+X2∼B(n1+n2,p)
(3)
X
1
∼
π
(
θ
1
)
,
X
2
∼
π
(
θ
2
)
X_1∼ π(θ_1),X_2∼ π(θ_2)
X1∼π(θ1),X2∼π(θ2),且两者独立,则
X
1
+
X
2
∼
π
(
1
/
θ
1
+
1
/
θ
2
)
X_1+X_2∼ π(1/θ_1+1/θ_2)
X1+X2∼π(1/θ1+1/θ2)
连续型随机变量
Z
=
X
/
Y
Z=X/Y
Z=X/Y的分布
f
Z
(
z
)
=
{
(
1
+
z
)
−
2
,
z
>
0
0
,
z
⩽
0
f_Z(z)=\begin{cases} (1+z)^{-2},&z>0 \\ 0,&z⩽ 0 \end{cases}
fZ(z)={(1+z)−2,0,z>0z⩽0
极值分布(extreme-value distribution):设 X, Y 独立,分别有分布函数
F
X
(
x
)
,
F
Y
(
y
)
F_X(x),F_Y(y)
FX(x),FY(y)
max
{
X
,
Y
}
\max\{X, Y\}
max{X,Y}的分布函数
F
m
a
x
(
z
)
=
F
X
(
x
)
F
Y
(
y
)
F_{max}(z)=F_X(x)F_Y(y)
Fmax(z)=FX(x)FY(y)
min
{
X
,
Y
}
\min\{X, Y\}
min{X,Y}的分布函数
F
m
i
n
(
z
)
=
1
−
(
1
−
F
X
(
x
)
)
(
1
−
F
Y
(
y
)
)
F_{min}(z)=1-(1-F_X(x))(1-F_Y(y))
Fmin(z)=1−(1−FX(x))(1−FY(y))
上述结论容易推广到 n 个随机变量:即设
X
i
X_i
Xi 的分布函数分别为
F
i
(
x
i
)
,
i
=
1
,
⋯
,
n
F_i(x_i), i=1,\cdots,n
Fi(xi),i=1,⋯,n,且相互独立。则
max
{
X
1
,
⋯
,
X
n
}
,
min
{
X
1
,
⋯
,
X
n
}
\max\{X_1,\cdots,X_n\}, \min\{X_1,\cdots,X_n\}
max{X1,⋯,Xn},min{X1,⋯,Xn}的分布函数:
F
max
(
z
)
=
∏
i
=
1
n
F
i
(
z
)
;
F
min
(
z
)
=
1
−
∏
i
=
1
n
(
1
−
F
i
(
z
)
)
\displaystyle F_{\max}(z)=\prod_{i=1}^{n}F_i(z); \quad F_{\min}(z)=1-\prod_{i=1}^{n}(1-F_i(z))
Fmax(z)=i=1∏nFi(z);Fmin(z)=1−i=1∏n(1−Fi(z))
随机变量的数字特征(Numerical Characteristics)
期望(Expectation)
数学期望(mathematical expectation):设离散型随机变量 X的分布律为
P
{
X
=
x
k
}
=
p
k
P\{X=x_k\}=p_k
P{X=xk}=pk
事件的平均值
x
ˉ
=
1
n
∑
k
x
k
n
k
=
∑
k
x
k
f
k
\displaystyle\bar x=\frac{1}{n}\sum_kx_kn_k=\sum_kx_kf_k
xˉ=n1k∑xknk=k∑xkfk,其中
f
k
f_k
fk为事件
{
X
=
x
k
}
\{X=x_k\}
{X=xk}发生的频率,由第一章可知当
n
→
∞
,
f
k
→
p
k
n\to ∞,f_k\to p_k
n→∞,fk→pk,因此
x
ˉ
\bar x
xˉ的稳定值为
∑
k
x
k
p
k
\displaystyle\sum_kx_kp_k
k∑xkpk,由此
若级数
E
(
X
)
=
∑
k
=
1
∞
x
k
p
k
E(X)=\displaystyle\sum_{k=1}^{∞}x_kp_k
E(X)=k=1∑∞xkpk绝对收敛,则称
E
(
X
)
E(X)
E(X)为随机变量
X
X
X的数学期望,简称期望,又称均值(mean)
连续型随机变量
X
X
X的密度函数为
f
(
x
)
f(x)
f(x),期望定义为
E
(
X
)
=
∫
−
∞
+
∞
x
f
(
x
)
d
x
E(X)=\int_{-∞}^{+∞}xf(x)\mathrm{d}x
E(X)=∫−∞+∞xf(x)dx
期望的物理意义:x 轴上一根线密度为 f(x) 的细棒的质心坐标
Y=g(X) 的数学期望
(1) 离散情形:
E
(
Y
)
=
E
(
g
(
X
)
)
=
∑
k
=
1
∞
g
(
x
k
)
p
k
E(Y)=E(g(X))=\displaystyle\sum_{k=1}^{∞}g(x_k)p_k
E(Y)=E(g(X))=k=1∑∞g(xk)pk
(2) 连续情形:
E
(
Y
)
=
E
(
g
(
X
)
)
=
∫
−
∞
+
∞
g
(
x
)
f
(
x
)
d
x
E(Y)=E(g(X))=\displaystyle\int_{-∞}^{+∞}g(x)f(x)\mathrm{d}x
E(Y)=E(g(X))=∫−∞+∞g(x)f(x)dx
Z=h(X,Y) 的数学期望
(1) 离散情形:
E
(
Z
)
=
E
(
h
(
X
,
Y
)
)
=
∑
i
=
1
∞
∑
j
=
1
∞
h
(
x
i
,
y
j
)
p
i
j
E(Z)=E(h(X,Y))=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}h(x_i,y_j)p_{ij}
E(Z)=E(h(X,Y))=i=1∑∞j=1∑∞h(xi,yj)pij
(2) 连续情形:
E
(
Z
)
=
E
(
h
(
X
,
Y
)
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
h
(
x
,
y
)
f
(
x
,
y
)
d
x
d
y
E(Z)=E(h(X,Y))=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}h(x,y)f(x,y)\mathrm{d}x\mathrm{d}y
E(Z)=E(h(X,Y))=∫−∞+∞∫−∞+∞h(x,y)f(x,y)dxdy
特别的,
E
(
X
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
f
(
x
,
y
)
d
x
d
y
E(X)=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}xf(x,y)\mathrm{d}x\mathrm{d}y
E(X)=∫−∞+∞∫−∞+∞xf(x,y)dxdy
E
(
Y
)
=
∫
−
∞
+
∞
∫
−
∞
+
∞
y
f
(
x
,
y
)
d
x
d
y
E(Y)=\displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞}yf(x,y)\mathrm{d}x\mathrm{d}y
E(Y)=∫−∞+∞∫−∞+∞yf(x,y)dxdy
期望的性质(c为常数)
(1)
E
(
c
)
=
c
E(c)=c
E(c)=c
(2)
E
(
c
X
)
=
c
E
(
X
)
E(cX)=cE(X)
E(cX)=cE(X)
(3)
E
(
X
+
Y
)
=
E
(
X
)
+
E
(
Y
)
E(X+Y)=E(X)+E(Y)
E(X+Y)=E(X)+E(Y)
(4) 设
X
,
Y
X,Y
X,Y相互独立,
E
(
X
Y
)
=
E
(
X
)
E
(
Y
)
E(XY)=E(X)E(Y)
E(XY)=E(X)E(Y)
方差和变异系数(Variance and CV)
方差(variance):设X是一个随机变量
D
(
X
)
=
V
a
r
(
X
)
=
E
[
(
X
−
E
(
X
)
)
2
]
D(X)=Var(X)=E[(X-E(X))^2]
D(X)=Var(X)=E[(X−E(X))2]叫做X的方差。将
σ
(
X
)
=
D
(
X
)
σ(X)=\sqrt{D(X)}
σ(X)=D(X)为 X 的标准差(standard deviation)或均方差。方差和标准差刻画了 X取值的波动性,是衡量取值分散程度的数字特征。
方差的计算
特别的,当
g
(
X
)
=
(
X
−
E
(
X
)
)
2
,
D
(
X
)
=
E
(
g
(
X
)
)
g(X)=(X-E(X))^2,\ D(X)=E(g(X))
g(X)=(X−E(X))2, D(X)=E(g(X))
利用期望的性质,
D
(
X
)
=
E
(
X
2
)
−
[
E
(
X
)
]
2
D(X)=E(X^2)-[E(X)]^2
D(X)=E(X2)−[E(X)]2
方差的性质(c为常数)
(1)
D
(
c
)
=
0
D(c)=0
D(c)=0
(2)
D
(
c
X
)
=
c
2
D
(
X
)
D(cX)=c^2D(X)
D(cX)=c2D(X)
(3)
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
+
2
E
[
(
X
−
E
(
X
)
)
(
Y
−
E
(
Y
)
)
]
D(X+Y)=D(X)+D(Y)+2E[(X-E(X))(Y-E(Y))]
D(X+Y)=D(X)+D(Y)+2E[(X−E(X))(Y−E(Y))]
当
X
,
Y
X,Y
X,Y相互独立,
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
D(X+Y)=D(X)+D(Y)
D(X+Y)=D(X)+D(Y)
(4) 切比雪夫(Chebyshev)不等式,设
E
(
X
)
=
μ
,
D
(
X
)
=
σ
2
,
P
{
∣
X
−
μ
∣
⩾
ϵ
}
⩽
σ
2
ϵ
2
E(X)=μ,D(X)=σ^2,P\{|X-μ|⩾ ϵ\}⩽ \dfrac{σ^2}{ϵ^2}
E(X)=μ,D(X)=σ2,P{∣X−μ∣⩾ϵ}⩽ϵ2σ2
结果分析,将切比雪夫不等式变形为
P
{
∣
X
−
μ
∣
<
ϵ
}
>
1
−
σ
2
ϵ
2
P\{|X-μ|< ϵ\}>1-\dfrac{σ^2}{ϵ^2}
P{∣X−μ∣<ϵ}>1−ϵ2σ2,取
ϵ
=
3
σ
ϵ=3σ
ϵ=3σ则有
P
{
∣
X
−
μ
∣
<
3
σ
}
>
1
−
1
9
≈
88.0
%
P\{|X-μ|< 3σ\}>1-\frac{1}{9}\approx 88.0\%
P{∣X−μ∣<3σ}>1−91≈88.0%,即随机变量有近90%的可能性落在区间
(
μ
−
3
σ
,
μ
+
3
σ
)
(μ-3σ,μ+3σ)
(μ−3σ,μ+3σ)内。
变异系数(Coefficient of Variance,CV): 标准差与期望的比值 C V = D ( X ) E ( X ) = σ ( X ) E ( X ) CV=\dfrac{\sqrt{D(X)}}{E(X)}=\dfrac{σ(X)}{E(X)} CV=E(X)D(X)=E(X)σ(X)变异系数是个无量纲的量,从而消除了量纲对波动的影响。
分位数和中位数(Quantile and median)
分位数(Quantile),亦称分位点,是指将一个随机变量的概率分布范围分为几个等份的数值点
P
{
x
⩽
x
α
}
=
α
P\{x⩽ x_α\}=α
P{x⩽xα}=α此时
x
α
x_α
xα称为
α
α
α 分位点。常用的有中位数(即二分位数)、四分位数、百分位数等。
协方差与相关系数(Covariance and correlation coefficient)
协方差(covariance):由方差性质(3)的意义,定义
C
o
v
(
X
,
Y
)
=
E
[
(
X
−
E
(
X
)
)
(
Y
−
E
(
Y
)
)
]
\mathrm{Cov}(X,Y)=E[(X-E(X))(Y-E(Y))]
Cov(X,Y)=E[(X−E(X))(Y−E(Y))]为
X
,
Y
X,Y
X,Y 的协方差。
协方差的基本性质:(其中 a , b 为常数)
(1) 若
X
,
Y
X,Y
X,Y 相互独立,则
C
o
v
(
X
,
Y
)
=
0
\mathrm{Cov}(X,Y )=0
Cov(X,Y)=0
(2)
C
o
v
(
X
,
Y
)
=
C
o
v
(
Y
,
X
)
\mathrm{Cov}(X,Y )=\mathrm{Cov}(Y,X)
Cov(X,Y)=Cov(Y,X)
(3)
D
(
X
)
=
E
[
(
X
−
E
(
X
)
)
2
]
=
C
o
v
(
X
,
X
)
D(X)=E[(X-E(X))^2]=\mathrm{Cov}(X,X)
D(X)=E[(X−E(X))2]=Cov(X,X)
(4)
C
o
v
(
a
X
,
b
Y
)
=
a
b
C
o
v
(
X
,
Y
)
\mathrm{Cov}(aX,bY )=ab \mathrm{Cov}(X,Y)
Cov(aX,bY)=abCov(X,Y)
(5)
C
o
v
(
X
1
+
X
2
,
Y
)
=
C
o
v
(
X
1
,
Y
)
+
C
o
v
(
X
2
,
Y
)
\mathrm{Cov}(X_1+X_2,Y )=\mathrm{Cov}(X_1,Y)+\mathrm{Cov}(X_2,Y)
Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
(6)
D
(
X
+
Y
)
=
D
(
X
)
+
D
(
Y
)
+
2
C
o
v
(
X
,
Y
)
D(X+Y)=D(X)+D(Y)+2 \mathrm{Cov}(X,Y)
D(X+Y)=D(X)+D(Y)+2Cov(X,Y)
(7)
C
o
v
(
X
,
Y
)
=
E
(
X
Y
)
−
E
(
X
)
E
(
Y
)
\mathrm{Cov}(X,Y)=E(XY)-E(X)E(Y)
Cov(X,Y)=E(XY)−E(X)E(Y)
相关系数(correlation coefficient):协方差反映了随机变量X与Y的相关性(这种关系是什么关系?)。但协方差是有量纲的数字特征,为了消除其量纲的影响,考虑单位化的随机变量,令
X
∗
=
X
−
E
(
X
)
D
(
X
)
,
Y
∗
=
Y
−
E
(
Y
)
D
(
Y
)
X^*=\dfrac{X-E(X)}{\sqrt{D(X)}},Y^*=\dfrac{Y-E(Y)}{\sqrt{D(Y)}}
X∗=D(X)X−E(X),Y∗=D(Y)Y−E(Y)
引入一个新概念
ρ
X
Y
=
C
o
v
(
X
∗
,
Y
∗
)
=
C
o
v
(
X
,
Y
)
D
(
X
)
D
(
Y
)
ρ_{XY}=\mathrm{Cov}(X^*,Y^*)=\dfrac{\mathrm{Cov}(X,Y)}{\sqrt{D(X)}\sqrt{D(Y)}}
ρXY=Cov(X∗,Y∗)=D(X)D(Y)Cov(X,Y)称为
X
,
Y
X,Y
X,Y的相关系数
进一步考虑
X
,
Y
X,Y
X,Y之间的关系,考虑
X
,
Y
X,Y
X,Y之间的线性关系, 即
Y
^
=
a
+
b
X
\hat Y=a+bX
Y^=a+bX(a,b为常数) 近似的表示
Y
Y
Y,均方误差
e
=
E
[
(
Y
−
Y
^
)
2
]
=
E
[
(
Y
−
(
a
+
b
X
)
)
2
]
e=E[(Y-\hat Y)^2]=E[(Y-(a+bX))^2]
e=E[(Y−Y^)2]=E[(Y−(a+bX))2]
求
min
{
e
}
\min\{e\}
min{e},令
∂
e
∂
a
=
0
,
∂
e
∂
b
=
0
\dfrac{∂ e}{∂ a}=0,\dfrac{∂ e}{∂ b}=0
∂a∂e=0,∂b∂e=0,解得
b
0
=
C
o
v
(
X
,
Y
)
D
(
X
)
,
a
0
=
E
(
Y
)
−
b
0
E
(
X
)
b_0=\dfrac{\mathrm{Cov}(X,Y)}{D(X)},a_0=E(Y)-b_0E(X)
b0=D(X)Cov(X,Y),a0=E(Y)−b0E(X)
带入可得
min
{
e
}
=
D
(
Y
)
(
1
−
ρ
X
Y
2
)
\min\{e\}=D(Y)(1-ρ^2_{XY})
min{e}=D(Y)(1−ρXY2)
相关系数的性质:
(1)
ρ
X
Y
⩽
1
ρ_{XY}⩽ 1
ρXY⩽1
(2)
ρ
X
Y
=
1
⟺
∃
a
,
b
∈
R
,
Y
=
a
X
+
b
ρ_{XY}=1\iff ∃ a,b\in\R,Y=aX+b
ρXY=1⟺∃a,b∈R,Y=aX+b
相关系数的实际意义
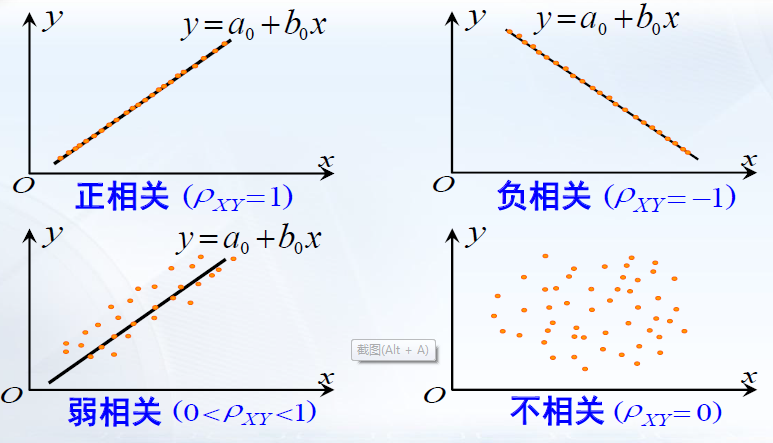
相关系数是一个用来表征两个随机变量之间线性关系密切程度的特征数,有时也称为“线性相关系数”。
当
ρ
X
Y
ρ_{XY}
ρXY较大时,表明X与Y的线性关系程度较好;
当
ρ
X
Y
ρ_{XY}
ρXY较小时,表明X与Y的线性关系程度较差。
特别地,
当
∣
ρ
X
Y
∣
=
1
|ρ_{XY}|=1
∣ρXY∣=1时,表明X与Y之间以概率1存在线性关系;
当
ρ
X
Y
=
0
ρ_{XY}=0
ρXY=0时,表明X与Y之间没有线性关系,称两个变量不相关。
X,Y相互独立
⟹
\implies
⟹ X,Y不相关;但X,Y不相关不能判断X,Y相互独立
矩 (Moment)
参考链接:https://www.zhihu.com/question/23236070/answer/143316942
物理意义:数学中矩的概念来自物理学。在物理学中,矩是表示距离和物理量乘积的物理量,表征物体的空间分布。由其定义,矩通常需要一个参考点(基点或参考系)来定义距离。如力和参考点距离乘积得到的力矩(或扭矩),原则上任何物理量和距离相乘都会产生力矩,质量,电荷分布等。
如对空间密度积分
ν
k
=
∫
r
k
ρ
(
r
)
d
r
ν_k=\displaystyle\int r^kρ(r)\mathrm{d}r
νk=∫rkρ(r)dr,如果点表示质量,则第零矩是总质量,一阶矩是重心,二阶矩是转动惯量。
数学意义:矩是物体形状识别的重要参数指标。在统计学中,矩是对变量分布和形态特点的一组度量。定义在实数域的实函数相对于值c的k阶矩为: ν k = ∫ − ∞ + ∞ ( x − c ) k f ( x ) d x ν_k = \int_{-∞}^{+∞} (x - c)^k\,f(x)\,\mathrm{d}x νk=∫−∞+∞(x−c)kf(x)dx如果点表示概率密度,则第零阶矩表示总概率(=1)。
(1) k阶(原点)矩(origin moment):随机变量 X X X的k阶(原点)矩定义为 μ k = E ( X k ) μ_k=E(X^k) μk=E(Xk)
连续型:
μ
k
=
∫
−
∞
+
∞
x
k
f
(
x
)
d
x
=
∫
−
∞
+
∞
x
k
d
F
(
x
)
μ_k =\displaystyle \int_{-∞}^{+∞} x^k\,f(x)\,\mathrm{d}x= \int_{-∞}^{+∞} x^k\,\mathrm{d}F(x)
μk=∫−∞+∞xkf(x)dx=∫−∞+∞xkdF(x),其中
f
(
x
)
f(x)
f(x)为概率密度函数。
离散型:
μ
k
=
∑
i
=
1
∞
x
i
k
p
i
μ_k=\displaystyle\sum_{i=1}^{∞}x_i^kp_i
μk=i=1∑∞xikpi,其中
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P{X=xi}=pi为概率分布函数。
(2) k 阶中心矩(central moment):移除均值后计算的矩被称为中心矩。 对于二阶及更高阶的矩,通常使用中心矩(围绕平均值的矩,均值是一阶矩),而不是原点矩,因为中心矩能更清楚的体现关于分布形状的信息。
ν
k
=
E
[
(
X
−
E
(
X
)
)
k
]
ν_k=E[(X-E(X))^k]
νk=E[(X−E(X))k]
连续型:
ν
k
=
∫
−
∞
+
∞
[
x
−
E
(
X
)
]
k
f
(
x
)
d
x
ν_k = \displaystyle\int_{-∞}^{+∞} [x-E(X)]^k\,f(x)\,\mathrm{d}x
νk=∫−∞+∞[x−E(X)]kf(x)dx,其中
f
(
x
)
f(x)
f(x)为概率密度函数。
离散型:
ν
k
=
∑
i
=
1
∞
[
x
i
−
E
(
X
)
]
k
p
i
ν_k=\displaystyle\sum_{i=1}^{∞}[x_i-E(X)]^kp_i
νk=i=1∑∞[xi−E(X)]kpi,其中
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P{X=xi}=pi为概率分布函数。
期望和方差:随机变量的数学期望(expectation)即为其一阶原点矩
E
(
X
)
E(X)
E(X)
方差(variance)即为二阶中心矩
V
a
r
(
X
)
=
E
[
x
−
E
(
X
)
]
2
Var(X)=E [x-E(X)]^2
Var(X)=E[x−E(X)]2
(3) ( k + l ) (k+l) (k+l) 阶混合矩(mixed moment):二维随机变量 ( X , Y ) (X,Y) (X,Y)的 ( k + l ) (k+l) (k+l) 阶混合(原点)矩为 μ k l ′ = E ( X k Y l ) μ'_{kl}=E(X^kY^l) μkl′=E(XkYl)
连续型:
μ
k
l
′
=
∫
−
∞
+
∞
∫
−
∞
+
∞
x
k
y
l
f
(
x
,
y
)
d
x
d
y
\displaystyle μ'_{kl}= \int_{-∞}^{+∞}\int_{-∞}^{+∞} x^ky^lf(x,y)\,\mathrm{d}x\mathrm{d}y
μkl′=∫−∞+∞∫−∞+∞xkylf(x,y)dxdy,其中
f
(
x
,
y
)
f(x,y)
f(x,y)为概率密度函数。
离散型:
μ
k
l
′
=
∑
i
=
1
∞
∑
j
=
1
∞
x
i
k
y
j
l
p
i
j
μ'_{kl}=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}x_i^ky_j^lp_{ij}
μkl′=i=1∑∞j=1∑∞xikyjlpij,其中
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P{X=xi,Y=yj}=pij为概率分布函数。
(4)
(
k
+
l
)
(k+l)
(k+l) 阶混合中心距(mixed central moment):随机变量
(
X
,
Y
)
的
(
k
+
l
)
(X,Y)的(k+l)
(X,Y)的(k+l) 阶中心矩被定义为
μ
k
l
′
=
E
[
(
X
−
E
(
X
)
)
k
(
Y
−
E
(
Y
)
)
l
]
μ'_{kl}=E[(X-E(X))^k(Y-E(Y))^l]
μkl′=E[(X−E(X))k(Y−E(Y))l]
连续型:
μ
k
l
′
=
∫
−
∞
+
∞
∫
−
∞
+
∞
[
x
−
E
(
X
)
]
k
[
y
−
E
(
Y
)
]
l
f
(
x
,
y
)
d
x
d
y
μ'_{kl}= \displaystyle\int_{-∞}^{+∞}\int_{-∞}^{+∞} [x-E(X)]^k[y-E(Y)]^lf(x,y)\,\mathrm{d}x\mathrm{d}y
μkl′=∫−∞+∞∫−∞+∞[x−E(X)]k[y−E(Y)]lf(x,y)dxdy,其中
f
(
x
,
y
)
f(x,y)
f(x,y)为概率密度函数。
离散型:
μ
k
l
′
=
∑
i
=
1
∞
∑
j
=
1
∞
[
x
i
−
E
(
X
)
]
k
[
y
j
−
E
(
Y
)
]
l
p
i
j
μ'_{kl}=\displaystyle\sum_{i=1}^{∞}\sum_{j=1}^{∞}[x_i-E(X)]^k[y_j-E(Y)]^lp_{ij}
μkl′=i=1∑∞j=1∑∞[xi−E(X)]k[yj−E(Y)]lpij,其中
P
{
X
=
x
i
,
Y
=
y
j
}
=
p
i
j
P\{X=x_i,Y=y_j\}=p_{ij}
P{X=xi,Y=yj}=pij为概率分布函数。
(1+1) 阶混合中心矩即为协方差。
矩母函数(moment generating function, MFG):在统计学中,矩母函数是一个关于随机变量的实值函数,它可以替代密度函数来描述分布。也就是说,出了概率密度函数外,我们也可以通过矩母函数来描述分布。对于某些概率密度函数和累计密度函数比较复杂的情况,我们使用矩母函数分析分布会大大降低复杂性,尤其是对于随机变量的加权求和来说,矩母函数可以提供非常简单的计算。当然,矩母函数出了是基于实值函数,也可以是基于向量和矩阵的,扩展性很好。但是,并不是所有的分布都存在矩母函数。
定义随机变量 e t X e^{tX} etX的数学期望为随机变量 X X X的矩母函数: M X ( t ) = E ( e t X ) , t ∈ R M_X(t)=E(e^{tX}),t\in\R MX(t)=E(etX),t∈R
连续型:
M
X
(
t
)
=
∫
−
∞
+
∞
exp
(
t
x
)
f
(
x
)
d
x
M_X(t)=\displaystyle\int_{-∞}^{+∞}\exp(tx)f(x)\mathrm{d}x
MX(t)=∫−∞+∞exp(tx)f(x)dx,其中
f
(
x
)
f(x)
f(x)为概率密度函数。
离散型:
M
X
(
t
)
=
∑
exp
(
t
x
i
)
p
i
M_X(t)=\displaystyle\sum \exp(tx_i)p_i
MX(t)=∑exp(txi)pi,其中
P
{
X
=
x
i
}
=
p
i
P\{X=x_i\}=p_i
P{X=xi}=pi为概率分布函数。
另外,矩母函数的对数为累积量生成函数
R
X
(
t
)
=
ln
M
X
(
t
)
R_X(t)=\ln M_X(t)
RX(t)=lnMX(t)
矩母函数的性质
(1) 随机变量的矩母函数与概率分布具有一一对应关系,即
M
Y
(
t
)
=
M
X
(
t
)
⟺
F
X
(
x
)
=
F
Y
(
y
)
M_Y(t)=M_X(t) \iff F_X(x)=F_Y(y)
MY(t)=MX(t)⟺FX(x)=FY(y)
(2) 若随机变量
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn相互独立,则
Y
=
X
1
+
X
2
+
⋯
,
X
n
Y=X_1+X_2+\cdots,X_n
Y=X1+X2+⋯,Xn的矩母函数
M
Y
(
t
)
=
M
X
1
(
t
)
M
X
1
(
t
)
⋯
M
X
1
(
t
)
M_Y(t)=M_{X_1}(t)M_{X_1}(t)\cdots M_{X_1}(t)
MY(t)=MX1(t)MX1(t)⋯MX1(t)
(3) 若
Y
=
a
+
b
X
Y=a+bX
Y=a+bX,则矩母函数
M
Y
(
t
)
=
e
a
t
M
X
(
b
t
)
M_Y(t)=e^{at}M_X(bt)
MY(t)=eatMX(bt)
矩母函数的特征:以连续随机变量为例,离散型随机变量可做相同变换。
(1) 由泰勒级数
e
x
=
1
+
x
+
x
2
2
!
+
⋯
+
x
n
n
!
+
⋯
e^x=1+x+\dfrac{x^2}{2!}+\cdots+\dfrac{x^n}{n!}+\cdots
ex=1+x+2!x2+⋯+n!xn+⋯,得
M
X
(
t
)
=
E
(
e
t
X
)
=
∫
−
∞
+
∞
[
1
+
t
x
+
(
t
x
)
2
2
!
+
⋯
+
(
t
x
)
n
n
!
+
⋯
]
f
(
x
)
d
x
M_X(t)=E(e^{tX})=\displaystyle\int_{-∞}^{+∞}[1+tx+\dfrac{(tx)^2}{2!}+\cdots+\dfrac{(tx)^n}{n!}+\cdots] f(x)\mathrm{d}x
MX(t)=E(etX)=∫−∞+∞[1+tx+2!(tx)2+⋯+n!(tx)n+⋯]f(x)dx,即
M
X
(
t
)
=
1
+
t
M
1
+
t
2
2
!
M
2
+
⋯
+
t
n
n
!
M
n
+
⋯
M_X(t)=1+tM_1+\dfrac{t^2}{2!}M_2+\cdots+\dfrac{t^n}{n!}M_n+\cdots
MX(t)=1+tM1+2!t2M2+⋯+n!tnMn+⋯其中
M
i
M_i
Mi为随机变量
X
X
X的
i
i
i 阶中心矩
(2)
M
X
(
−
t
)
M_X(-t)
MX(−t) 是双侧拉普拉斯变换(Laplace Transform)
(3) 不管概率分布是不是连续,矩母函数都可以用黎曼-斯蒂尔切斯积分给出:
M
X
(
t
)
=
∫
−
∞
+
∞
e
t
x
d
F
(
x
)
M_X(t)=\displaystyle\int_{-∞}^{+∞}e^{tx}\mathrm{d}F(x)
MX(t)=∫−∞+∞etxdF(x)其中,
F
(
x
)
F(x)
F(x)是累积分布函数(Cumulative Distribution Function, CDF)。
特征函数(characteristic function):定义复随机变量 e i t X e^{itX} eitX的数学期望为随机变量 X X X的特征函数: φ X ( t ) = E ( e i t X ) , t ∈ R φ_X(t)=E(e^{itX}),t\in\R φX(t)=E(eitX),t∈R特征函数与矩母函数的关系 φ X ( t ) = M X ( i t ) φ_X(t)=M_X(it) φX(t)=MX(it),由此可知特征函数与矩母函数有相同的性质
求随机变量的矩:如果随机变量 X X X矩母函数存在,则各阶矩存在且可由矩量母函数表示 E ( X k ) = M X ( k ) ( 0 ) = d k M X d t k ∣ t = 0 E(X^k)=M_X^{(k)}(0)=\dfrac{\mathrm{d}^kM_X}{\mathrm{d}t^k}|_{t=0} E(Xk)=MX(k)(0)=dtkdkMX∣t=0特别的有 E ( X ) = M X ′ ( 0 ) , V a r ( X ) = M X ′ ′ ( 0 ) − [ M X ′ ( 0 ) ] 2 E(X)=M'_X(0),Var(X)=M''_X(0)-[M'_X(0)]^2 E(X)=MX′(0),Var(X)=MX′′(0)−[MX′(0)]2
偏度和峰度(Skewness and kurtosis)
偏度(skewness):随机变量的偏度(衡量分布不对称性)定义为
S
(
X
)
=
ν
3
ν
2
3
/
2
=
E
[
X
−
E
(
X
)
]
3
[
V
a
r
(
x
)
]
3
/
2
S(X)=\dfrac{ν_3}{ν_{2}^{3/2}}=\dfrac{E[X-E(X)]^3}{[Var(x)]^{3/2}}
S(X)=ν23/2ν3=[Var(x)]3/2E[X−E(X)]3
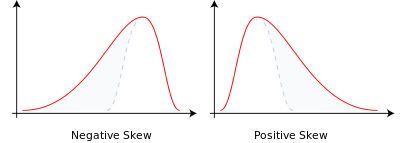
任何对称分布偏态为0
S
<
0
S<0
S<0,向左偏斜(分布尾部在左侧较长,失效率数据常向左偏斜,如极少量的灯泡会立即烧坏)
S
>
0
S>0
S>0,向右偏斜分布(分布尾部在右侧较长,工资数据往往以这种方式偏斜,大多数人所得工资较少)
偏度无量纲,是描述分布偏离对称程度的一个特征数。
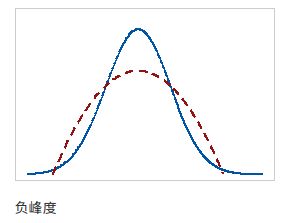
峰度(kurtosis):一般随机变量的峰度定义为其四阶中心矩与方差平方的比值再减3,减3是为了让正态分布峰度为0,这也被称为超值峰度。
K
(
X
)
=
ν
4
ν
2
2
−
3
=
E
[
x
−
E
(
X
)
]
4
V
a
r
2
(
X
)
−
3
K(X)=\dfrac{ν_4}{ν_{2}^{2}}-3=\dfrac{E[x-E(X)]^4}{Var^2(X)}-3
K(X)=ν22ν4−3=Var2(X)E[x−E(X)]4−3
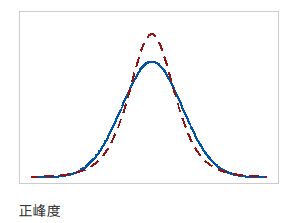
完全符合正态分布的数据峰度值为0,且正态分布曲线被称为基线。峰度无量纲,是相对于正态分布而言的超出量。
K
>
0
K>0
K>0,标准化后的分布比标准正态分布剑鞘
K
<
0
K<0
K<0,标准化后的分布比标准正态分布平坦
协方差矩阵与多维正态分布(Covariance matrix and multivariate normal distribution)
协方差矩阵(Covariance matrix):设n维随机变量
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)
X=(X1,X2,⋯,Xn),记
c
i
j
=
C
o
v
(
X
i
,
X
j
)
(
i
,
j
=
1
,
2
,
⋯
,
n
)
c_{ij}=\mathrm{Cov}(X_i,X_j)\ (i,j=1,2,\cdots,n)
cij=Cov(Xi,Xj) (i,j=1,2,⋯,n),则称
C
=
(
c
i
j
)
n
×
n
C=(c_ij)_{n× n}
C=(cij)n×n为随机向量
X
\mathbf{X}
X 的协方差矩阵。
协方差矩阵的性质:
(1)
C
=
C
T
C=C^T
C=CT, 即协方差阵为对称阵
(2)
C
⩾
0
C⩾ 0
C⩾0 , 即协方差阵为非负定矩阵
定理 :设
(
X
,
Y
)
∼
N
(
μ
1
,
μ
2
,
σ
1
,
σ
2
,
ρ
)
(X,Y)∼ N(μ_1,μ_2,σ_1,σ_2,ρ)
(X,Y)∼N(μ1,μ2,σ1,σ2,ρ),则
(1)
X
,
Y
X,Y
X,Y的相关系数
ρ
X
Y
=
ρ
ρ_{XY}=ρ
ρXY=ρ
(2)
X
,
Y
X,Y
X,Y的协方差矩阵为
C
=
(
σ
1
2
ρ
σ
1
σ
2
ρ
σ
1
σ
2
σ
2
)
C=\begin{pmatrix} σ_1^2&ρσ_1σ_2 \\ ρσ_1σ_2&σ_2 \end{pmatrix}
C=(σ12ρσ1σ2ρσ1σ2σ2)
(3)
X
,
Y
X,Y
X,Y相互独立
⟺
ρ
X
Y
=
ρ
=
0
\iff ρ_{XY}=ρ=0
⟺ρXY=ρ=0
⟺
X
,
Y
\iff X,Y
⟺X,Y互不相关
二维正态随机变量密度函数的矩阵表示法
f
(
x
)
=
1
2
π
∣
C
∣
1
/
2
exp
{
−
1
2
(
x
−
μ
)
C
−
1
(
x
−
μ
)
T
}
f(\mathbf{x})=\dfrac{1}{2π|C|^{1/2}}\exp\{-\dfrac{1}{2}(\mathbf{x-μ})C^{-1}(\mathbf{x-μ})^T\}
f(x)=2π∣C∣1/21exp{−21(x−μ)C−1(x−μ)T}
其中
x
=
(
x
,
y
)
,
μ
=
(
μ
1
,
μ
2
)
,
C
\mathbf{x}=(x,y),\mathbf{μ}=(μ_1,μ_2),C
x=(x,y),μ=(μ1,μ2),C为协方差阵
n维正态随机变量:设
C
C
C 为 n 阶正定对称阵,
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
n
)
μ=(μ_1,μ_2,\cdots,μ_n)
μ=(μ1,μ2,⋯,μn)为n维已知向量,记
x
=
(
x
1
,
x
2
,
⋯
,
x
n
)
∈
R
n
\mathbf{x}=(x_1,x_2,\cdots,x_n)\in\R^n
x=(x1,x2,⋯,xn)∈Rn,若n维正态随机向量
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)
X=(X1,X2,⋯,Xn)的密度函数为
f
(
x
)
=
1
(
2
π
)
n
/
2
∣
C
∣
1
/
2
exp
{
−
1
2
(
x
−
μ
)
C
−
1
(
x
−
μ
)
T
}
f(\mathbf{x})=\dfrac{1}{(2π)^{n/2}|C|^{1/2}}\exp\{-\dfrac{1}{2}(\mathbf{x-μ})C^{-1}(\mathbf{x-μ})^T\}
f(x)=(2π)n/2∣C∣1/21exp{−21(x−μ)C−1(x−μ)T}
则称
X
\mathbf{X}
X 服从 n 维正态分布, 记为
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X=(X1,X2,⋯,Xn)∼N(μ,C)
n 维正态分布的性质:
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X=(X1,X2,⋯,Xn)∼N(μ,C)
(1)
f
(
x
)
>
0
f(\mathbf{x})>0
f(x)>0
(2)
∫
−
∞
+
∞
⋯
∫
−
∞
+
∞
f
(
x
1
,
x
2
,
⋯
,
x
n
)
d
x
1
d
x
2
⋯
d
x
n
=
1
\displaystyle\int_{-∞}^{+∞}\cdots\int_{-∞}^{+∞}f(x_1,x_2,\cdots,x_n)\mathrm{d}x_1\mathrm{d}x_2\cdots\mathrm{d}x_n=1
∫−∞+∞⋯∫−∞+∞f(x1,x2,⋯,xn)dx1dx2⋯dxn=1
(3)
μ
i
=
E
(
x
i
)
(
1
=
1
,
2
,
⋯
,
n
)
μ_i=E(x_i)\quad (1=1,2,\cdots,n)
μi=E(xi)(1=1,2,⋯,n)
(4)
C
=
(
c
i
j
)
n
×
n
C=(c_{ij})_{n× n}
C=(cij)n×n是
(
X
1
,
X
2
,
⋯
,
X
n
)
(X_1,X_2,\cdots,X_n)
(X1,X2,⋯,Xn)的协方差矩阵,且
D
(
X
i
)
=
c
i
i
(
1
=
1
,
2
,
⋯
,
n
)
C
o
v
(
X
i
,
X
j
)
=
c
i
j
(
1
=
1
,
2
,
⋯
,
n
)
D(X_i)=c_{ii} \quad (1=1,2,\cdots,n) \\ \mathrm{Cov}(X_i,X_j)=c_{ij}\quad (1=1,2,\cdots,n)
D(Xi)=cii(1=1,2,⋯,n)Cov(Xi,Xj)=cij(1=1,2,⋯,n)
(5)
X
i
∼
N
(
μ
i
,
c
i
i
)
(
1
=
1
,
2
,
⋯
,
n
)
X_i∼ N(μ_i,c_{ii})\quad (1=1,2,\cdots,n)
Xi∼N(μi,cii)(1=1,2,⋯,n)
(6) 若
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn相互独立,且各
X
i
∼
N
(
μ
i
,
σ
i
2
)
X_i∼ N(μ_i,σ_i^2)
Xi∼N(μi,σi2),则
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
(X_1,X_2,\cdots,X_n)∼ N(μ,C)
(X1,X2,⋯,Xn)∼N(μ,C),其中
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
n
)
,
C
=
d
i
a
g
(
σ
1
2
,
σ
1
2
⋯
,
σ
n
2
)
μ=(μ_1,μ_2,\cdots,μ_n),C=\mathrm{diag}(σ_1^2,σ_1^2\cdots,σ_n^2)
μ=(μ1,μ2,⋯,μn),C=diag(σ12,σ12⋯,σn2)
重要定理
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C)
X=(X1,X2,⋯,Xn)∼N(μ,C)
(1) 其任意
k
(
1
⩽
k
⩽
n
)
k(1⩽ k⩽ n)
k(1⩽k⩽n)维子向量均服从k维正态分布
(2)
X
=
(
X
1
,
X
2
,
⋯
,
X
n
)
∼
N
(
μ
,
C
)
⟺
X
1
,
X
2
,
⋯
,
X
n
\mathbf{X}=(X_1,X_2,\cdots,X_n)∼ N(μ,C) \iff X_1,X_2,\cdots,X_n
X=(X1,X2,⋯,Xn)∼N(μ,C)⟺X1,X2,⋯,Xn的任一非零线性组合
l
1
X
1
+
l
2
X
2
+
⋯
l
n
X
n
l_1X_1+l_2X_2+\cdots l_nX_n
l1X1+l2X2+⋯lnXn服从一维正态分布
(3) 正态随机向量的线性变换不变性: 令
Y
=
X
A
Y=XA
Y=XA,其中
A
=
(
a
i
j
)
n
×
m
A=(a_{ij})_{n× m}
A=(aij)n×m,则
Y
=
(
Y
1
,
Y
2
,
⋯
,
Y
m
)
Y=(Y_1,Y_2,\cdots,Y_m)
Y=(Y1,Y2,⋯,Ym) 仍服从多维正态分布
(4)
X
1
,
X
2
,
⋯
,
X
n
X_1,X_2,\cdots,X_n
X1,X2,⋯,Xn相互独立
⟺
X
1
,
X
2
,
⋯
,
X
n
\iff X_1,X_2,\cdots,X_n
⟺X1,X2,⋯,Xn两两不相关
⟺
C
=
d
i
a
g
(
c
11
,
c
22
,
⋯
,
c
n
n
)
\iff C=\mathrm{diag}(c_{11},c_{22},\cdots,c_{nn})
⟺C=diag(c11,c22,⋯,cnn)(即C为对角阵)
大数定律和中心极限定理(Law of Large Numbers & Central Limit Theorem)
依概率收敛 (convergence in probability):回顾概率的概念是如何产生的?

设
n
n
n次独立重复试验中事件
A
A
A发生的次数为
n
A
n_A
nA则当
n
n
n越来越大时,有
∀
ϵ
>
0
,
lim
n
→
∞
P
{
∣
n
A
n
−
p
∣
⩾
ϵ
}
=
0
∀ ϵ>0,\lim\limits_{n\to∞}P\{|\dfrac{n_A}{n}-p|⩾ ϵ\}=0
∀ϵ>0,n→∞limP{∣nnA−p∣⩾ϵ}=0这种收敛性称为依概率收敛。
定义:设 Y 1 , Y 2 , ⋯ , Y n , ⋯ Y_1,Y_2,\cdots,Y_n,\cdots Y1,Y2,⋯,Yn,⋯为一随机变量序列,c为一常数,若对于 ∀ ϵ > 0 ∀ ϵ>0 ∀ϵ>0均有 lim n → ∞ P { ∣ Y n − c ∣ ⩾ ϵ } = 0 \lim\limits_{n\to∞}P\{|Y_n-c|⩾ ϵ\}=0 n→∞limP{∣Yn−c∣⩾ϵ}=0成立,则称随机变量序列依概率收敛于c,记为 Y n → P c ( n → ∞ ) Y_n\xrightarrow{P}c\quad (n\to∞) YnPc(n→∞)
性质:若
X
n
→
P
a
,
Y
n
→
P
b
(
n
→
∞
)
X_n\xrightarrow{P}a,Y_n\xrightarrow{P}b\quad (n\to∞)
XnPa,YnPb(n→∞),函
g
(
x
,
y
)
g(x,y)
g(x,y)在点
(
a
,
b
)
(a,b)
(a,b)处连续,那么
g
(
X
n
,
Y
n
)
→
P
g
(
a
,
b
)
(
n
→
∞
)
g(X_n,Y_n)\xrightarrow{P}g(a,b)\quad (n\to∞)
g(Xn,Yn)Pg(a,b)(n→∞)
特别的,若
X
n
→
P
a
(
n
→
∞
)
X_n\xrightarrow{P}a\quad (n\to∞)
XnPa(n→∞),函数
f
(
x
)
f(x)
f(x)在点
a
a
a处连续,那么
f
(
X
n
)
→
P
f
(
a
)
(
n
→
∞
)
f(X_n)\xrightarrow{P}f(a)\quad (n\to∞)
f(Xn)Pf(a)(n→∞)
大数定律(Law of Large Numbers)
Bernoulli 大数定律 设
n
A
n_A
nA 是
n
n
n 次独立重复试验中事件
A
A
A 发生的次数,且
P
(
A
)
=
p
P(A)=p
P(A)=p,则对于
∀
ϵ
>
0
∀ ϵ>0
∀ϵ>0有
lim
n
→
∞
P
{
∣
n
A
n
−
p
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{n_A}{n}-p|⩾ ϵ\}=0
n→∞limP{∣nnA−p∣⩾ϵ}=0,即
n
A
n
→
P
p
(
n
→
∞
)
\dfrac{n_A}{n}\xrightarrow{P}p\quad (n\to∞)
nnAPp(n→∞) 频率稳定于概率
Chebyshev 大数定律 设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X1,X2,⋯,Xn,⋯为相互独立的随机变量序列,且具有相同的数学期望
μ
μ
μ 和方差
σ
2
σ^2
σ2,则对于
∀
ϵ
>
0
∀ ϵ>0
∀ϵ>0有
lim
n
→
∞
P
{
∣
1
n
∑
i
=
1
n
X
i
−
μ
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i-μ|⩾ ϵ\}=0
n→∞limP{∣n1i=1∑nXi−μ∣⩾ϵ}=0,即
1
n
∑
i
=
1
n
X
i
→
P
μ
(
n
→
∞
)
\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i\xrightarrow{P}μ\quad (n\to∞)
n1i=1∑nXiPμ(n→∞) 平均值稳定于期望
Sinchin 大数定律 设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X1,X2,⋯,Xn,⋯为独立同分布(independent identically distri- buted;IID)的随机变量序列,且其期望为
μ
μ
μ 和方差
σ
2
σ^2
σ2,则对于
∀
ϵ
>
0
∀ ϵ>0
∀ϵ>0有
lim
n
→
∞
P
{
∣
1
n
∑
i
=
1
n
X
i
−
μ
∣
⩾
ϵ
}
=
0
\lim\limits_{n\to∞}P\{|\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i-μ|⩾ ϵ\}=0
n→∞limP{∣n1i=1∑nXi−μ∣⩾ϵ}=0,即
1
n
∑
i
=
1
n
X
i
→
P
μ
(
n
→
∞
)
\dfrac{1}{n}\displaystyle\sum_{i=1}^{n}X_i\xrightarrow{P}μ\quad (n\to∞)
n1i=1∑nXiPμ(n→∞)
大数定律的意义
(1) 给出了“频率稳定性”的严格数学解释.
(2) 提供了通过试验来确定事件概率的方法.
(3) 是数理统计中参数估计的重要理论依据之一.
(4) 是Monte Carlo方法1的主要数学理论基础.
中心极限定理(Central Limit Theorem)
有许多随机变量,它们是由大量的相互独立的随机变量的综合影响所形成的,而其中每个个别的因素作用都很小,这种随机变量往往服从或近似服从正态分布,或者说它的极限分布是正态分布,中心极限定理正是从数学上论证了这一现象,它在长达两个世纪的时期内曾是概率论研究的中心课题。
独立同分布的中心极限定理设
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X1,X2,⋯,Xn,⋯为独立同分布的随机变量序列,且其期望为
μ
μ
μ 和方差
σ
2
σ^2
σ2,则随机变量之和
Y
n
=
∑
i
=
1
n
X
i
Y_n=\displaystyle\sum_{i=1}^{n}X_i
Yn=i=1∑nXi 的标准化变量
Z
n
=
Y
n
−
E
(
Y
n
)
D
(
Y
n
)
=
∑
i
=
1
n
X
i
−
n
μ
n
σ
Z_n=\dfrac{Y_n-E(Y_n)}{\sqrt{D(Y_n)}}=\dfrac{\displaystyle\sum_{i=1}^{n}X_i-nμ}{\sqrt{n}σ}
Zn=D(Yn)Yn−E(Yn)=nσi=1∑nXi−nμ的分布函数
F
n
(
x
)
F_n(x)
Fn(x)对于
∀
x
∈
R
∀ x\in\R
∀x∈R,有
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
i
=
1
n
X
i
−
n
μ
n
σ
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\begin{aligned} \lim\limits_{n\to∞}F_n(x)&=\lim\limits_{n\to∞}P\left\{\dfrac{\displaystyle\sum_{i=1}^{n}X_i-nμ}{\sqrt{n}σ}⩽ x\right\} \\ &=\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x) \end{aligned}
n→∞limFn(x)=n→∞limP⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧nσi=1∑nXi−nμ⩽x⎭⎪⎪⎪⎪⎬⎪⎪⎪⎪⎫=∫−∞x2π1e−t2/2dt=Φ(x)
故可认为
lim
n
→
∞
∑
i
=
1
n
X
i
∼
N
(
n
μ
,
n
σ
2
)
\lim\limits_{n\to∞}\displaystyle\sum_{i=1}^{n}X_i∼ N(nμ,nσ^2)
n→∞limi=1∑nXi∼N(nμ,nσ2),上式可改成当
lim
n
→
∞
X
ˉ
−
μ
σ
/
n
∼
N
(
0
,
1
)
\lim\limits_{n\to∞}\dfrac{\bar X-μ}{σ/\sqrt{n}}∼ N(0,1)
n→∞limσ/nXˉ−μ∼N(0,1)或
lim
n
→
∞
X
ˉ
∼
N
(
μ
,
σ
2
/
n
)
\lim\limits_{n\to∞}\bar X∼ N(μ,σ^2/n)
n→∞limXˉ∼N(μ,σ2/n)
李雅普诺夫(Lyapunov)中心极限定理设 随机变量
X
1
,
X
2
,
⋯
,
X
n
,
⋯
X_1,X_2,\cdots,X_n,\cdots
X1,X2,⋯,Xn,⋯相互独立,他们具有数学期望
E
(
X
k
)
=
μ
k
E(X_k)=μ_k
E(Xk)=μk 和方差
D
(
X
k
)
=
σ
k
2
D(X_k)=σ_k^2
D(Xk)=σk2
记
B
n
2
=
∑
k
=
1
n
σ
k
2
B_n^2=\displaystyle\sum_{k=1}^{n}σ_k^2
Bn2=k=1∑nσk2,若
∃
δ
>
0
,
1
B
n
2
+
δ
∑
k
=
1
n
E
(
∣
X
k
−
μ
k
∣
2
+
δ
)
→
0
(
n
→
∞
)
∃ δ>0,\dfrac{1}{B_n^{2+δ}}\displaystyle\sum_{k=1}^{n}E(|X_k-μ_k|^{2+δ})\to0\quad (n\to∞)
∃δ>0,Bn2+δ1k=1∑nE(∣Xk−μk∣2+δ)→0(n→∞)
则随机变量之和
Y
n
=
∑
k
=
1
n
X
k
Y_n=\displaystyle\sum_{k=1}^{n}X_k
Yn=k=1∑nXk 的标准化变量
Z
n
=
Y
n
−
E
(
Y
n
)
D
(
Y
n
)
=
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
Z_n=\dfrac{Y_n-E(Y_n)}{\sqrt{D(Y_n)}}=\dfrac{\displaystyle\sum_{k=1}^{n}X_k-\sum_{k=1}^{n}μ_k}{B_n}
Zn=D(Yn)Yn−E(Yn)=Bnk=1∑nXk−k=1∑nμk的分布函数
F
n
(
x
)
F_n(x)
Fn(x)对于
∀
x
∈
R
∀ x\in\R
∀x∈R,有
lim
n
→
∞
F
n
(
x
)
=
lim
n
→
∞
P
{
∑
k
=
1
n
X
k
−
∑
k
=
1
n
μ
k
B
n
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\begin{aligned} \lim\limits_{n\to∞}F_n(x)&=\lim\limits_{n\to∞}P\left\{\dfrac{\displaystyle\sum_{k=1}^{n}X_k-\sum_{k=1}^{n}μ_k}{B_n}⩽ x\right\} \\ &=\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x) \end{aligned}
n→∞limFn(x)=n→∞limP⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧Bnk=1∑nXk−k=1∑nμk⩽x⎭⎪⎪⎪⎪⎬⎪⎪⎪⎪⎫=∫−∞x2π1e−t2/2dt=Φ(x)
故可认为
lim
n
→
∞
∑
k
=
1
n
X
k
∼
N
(
∑
k
=
1
n
μ
k
,
B
n
2
)
\lim\limits_{n\to∞}\displaystyle\sum_{k=1}^{n}X_k∼ N(\sum_{k=1}^{n}μ_k,B_n^2)
n→∞limk=1∑nXk∼N(k=1∑nμk,Bn2)
棣莫弗-拉普拉斯(De Moivre-Laplace)中心极限定理:若随机变量序列
η
n
∼
B
(
n
,
p
)
(
n
=
1
,
2
,
⋯
)
η_n∼ B(n,p)\quad(n=1,2,\cdots)
ηn∼B(n,p)(n=1,2,⋯),则对于
∀
x
∈
R
∀ x\in\R
∀x∈R,有
lim
n
→
∞
P
{
η
n
−
n
p
n
p
(
1
−
p
)
⩽
x
}
=
∫
−
∞
x
1
2
π
e
−
t
2
/
2
d
t
=
Φ
(
x
)
\lim\limits_{n\to∞}P\left\{\dfrac{η_n-np}{\sqrt{np(1-p)}}⩽ x\right\} \\ =\displaystyle\int_{-∞}^{x}\dfrac{1}{\sqrt{2π}}e^{-t^2/2}\mathrm{d}t=Φ(x)
n→∞limP{np(1−p)ηn−np⩽x}=∫−∞x2π1e−t2/2dt=Φ(x)
故可认为
lim
n
→
∞
η
n
∼
N
(
n
p
,
n
p
(
1
−
p
)
)
\lim\limits_{n\to∞}η_n∼ N(np,np(1-p))
n→∞limηn∼N(np,np(1−p)),这个定理是CLT定理的一种特殊情况,说明了正态分布是二项分布的极限分布。
中心极限定理的意义:在实际问题中,如果某随机指标满足
(1) 该指标是由大量相互独立的随机因素迭加而成
(2) 每个因素作用都是微小的,且没有一个因素起到突出的作用
则这个随机指标近似地服从正态分布。
在实际问题中,所考虑的随机变量可以表示成多个独立的随机变量之和,如在任意指定时刻,一城市的耗电量是大量用户耗电量的总和;一个物理实验的测量误差是由许多观察不到的、可叠加的微小误差所合成的;它们往往近似服从正态分布。
附录
常见的离散型随机变量
| 分布 | 概率分布 | 累积分布函数 | 期望 | 方差 | 矩母函数 |
|---|---|---|---|---|---|
| 伯努利分布 B ( 1 , p ) B(1,p) B(1,p) | p ( 1 − p ) p(1-p) p(1−p) | p p p | p ( 1 − p ) p(1-p) p(1−p) | 1 − p + p e t 1-p+pe^t 1−p+pet | |
| 二项分布 B ( n , p ) B(n,p) B(n,p) |
∁
n
k
p
k
(
1
−
p
)
n
−
k
∁^k_np^k(1-p)^{n-k}
∁nkpk(1−p)n−k ( k = 1 , 2 , ⋯ , n ) (k=1,2,\cdots,n) (k=1,2,⋯,n) | ∑ i = 1 k ∁ n i p i ( 1 − p ) n − i \displaystyle\sum_{i=1}^{k} ∁^i_np^i(1-p)^{n-i} i=1∑k∁nipi(1−p)n−i | n p np np | n p ( 1 − p ) np(1-p) np(1−p) | ( 1 − p + p e t ) n (1-p+pe^t)^n (1−p+pet)n |
| 几何分布 G e o m ( p ) Geom(p) Geom(p) |
p
(
1
−
p
)
k
−
1
p(1-p)^{k-1}
p(1−p)k−1 ( k ∈ N ) (k\in\N) (k∈N) | 1 − ( 1 − p ) k 1-(1-p)^k 1−(1−p)k | 1 p \dfrac{1}{p} p1 | 1 − p p 2 \dfrac{1-p}{p^2} p21−p | p e t 1 − ( 1 − p ) e t \dfrac{pe^t}{1-(1-p)e^t} 1−(1−p)etpet |
| 泊松分布 P ( λ ) P(λ) P(λ) |
λ
k
e
−
λ
k
!
\dfrac{λ^ke^{-λ}}{k!}
k!λke−λ ( k ∈ N ) (k\in\N) (k∈N) | e − λ ∑ i = 1 k λ i i ! \displaystyle e^{-λ}\sum_{i=1}^{k}\dfrac{λ^i}{i!} e−λi=1∑ki!λi | λ λ λ | λ λ λ | exp ( λ ( e t − 1 ) ) \exp(λ(e^t-1)) exp(λ(et−1)) |
常见的连续型随机变量
| 分布 | 概率密度 | 累积分布函数 | 期望 | 方差 | 矩母函数 |
|---|---|---|---|---|---|
| 均匀分布 U ( a , b ) U(a,b) U(a,b) |
1
b
−
a
\dfrac{1}{b-a}
b−a1 ( x ∈ [ a , b ] ) (x\in[a,b]) (x∈[a,b]) | x − a b − a \dfrac{x-a}{b-a} b−ax−a | a + b 2 \dfrac{a+b}{2} 2a+b | ( b − a ) 2 12 \dfrac{(b-a)^2}{12} 12(b−a)2 | e b t − e a t t ( b − a ) \dfrac{e^{bt}-e^{at}}{t(b-a)} t(b−a)ebt−eat |
| 指数分布 E x p ( θ ) Exp(θ) Exp(θ) |
1
θ
e
−
x
/
θ
\frac{1}{θ}e^{-x/θ}
θ1e−x/θ ( x > 0 ) (x>0) (x>0) | 1 − e − x / θ 1-e^{-x/θ} 1−e−x/θ | θ θ θ | θ 2 θ^2 θ2 | 1 1 − θ t \dfrac{1}{1-θt} 1−θt1 |
| 正态分布 N ( μ , σ 2 ) N(μ,σ^2) N(μ,σ2) |
1
2
π
σ
e
−
(
x
−
μ
)
2
2
σ
2
\dfrac{1}{\sqrt{2π}σ}e^{-\frac{(x-μ)^2}{2σ^2}}
2πσ1e−2σ2(x−μ)2 ( μ ∈ R , σ > 0 ) (μ\in\R,σ>0) (μ∈R,σ>0) | μ μ μ | σ 2 σ^2 σ2 | exp ( μ t + 1 2 σ 2 t 2 ) \exp(μt+\frac{1}{2}σ^2t^2) exp(μt+21σ2t2) | |
| 伽马分布 G a m m a ( k , θ ) Gamma(k,θ) Gamma(k,θ) |
θ
k
Γ
(
k
)
x
k
−
1
e
−
θ
x
\dfrac{θ^k}{Γ(k)}x^{k-1}e^{-θx}
Γ(k)θkxk−1e−θx ( x > 0 ) (x>0) (x>0) Γ ( k ) = ∫ 0 ∞ x k − 1 e − x d x \displaystyleΓ(k)=\int_0^{∞}x^{k-1}e^{-x}\mathrm{d}x Γ(k)=∫0∞xk−1e−xdx | k θ kθ kθ | k θ 2 kθ^2 kθ2 |
(
1
−
θ
t
)
−
k
(1-θt)^{-k}
(1−θt)−k ( t < 1 / θ ) (t<1/θ) (t<1/θ) |
Monte Carlo方法或称为计算机随机模拟方法、计算机仿真方法,是科学与工程中的一种重要工具。Monte Carlo 方法的原理主要基于大数定律. ↩︎

















 1555
1555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









