






大家好,这是我的第一篇博客,写的不好请见谅。
小编是个多年的NBA观众,最近正值季后赛的比赛,闲来无事,突发奇想,想利用刚刚所学的python著名爬虫框架scrapy采集一下全NBA的球员基本信息。好了闲话不多说,让我们开始吧!

一.环境配置
1.安装python3.6,并且配置环境变量,打开cmd,输入python 显示以下内容说明安装成功。

2.python安装好了,然后安装scrapy框架
可以直接去点击打开链接这里按Shift+f组合键打开搜索框,输入scrapy,下载最新版本的scrapy。
(1)
(2) scrapy依赖twiste包,我们还是去点击这里去下载这个包。
(3) 安装 lxml解析库,这个直接在cmd中输入pip install lxml即可。
3.然后不要着急启动,安装whl文件需要安装wheel库,这里直接打开cmd 输入pip install wheel安装即可。
4. 以上手动下载的包需要复制到你的python路径下面,我的是这个路径
5.然后打开cmd依次启动它们 例如 
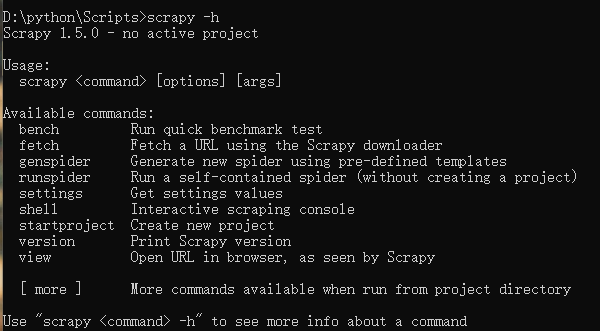
6.如果按照以上步骤完毕之后,在cmd中输入scrapy -h显示如下内容,则证明你终于安装成功了scrapy框架,可以正式开始了!
二 开始你的第一个scrapy项目
经过以上安装的痛苦,终于可以开始了。let's go! 打开你的cmd ,输入以下命令

这里我建立了一个叫hupu的项目
下面来简单介绍一下各个文件作用:
1、Items是将要装载抓取的数据的容器,它工作方式像python里面的字典。定义它的属性为scrpiy.item.Field对象,就像是一个对象关系映射(ORM).
3, pipelines.py: 项目管道文件,用于提取Items内容
4、settings.py: 项目配置文件
5、middlewares.py下载中间件。
说到scrapy不得不说下面这张图:
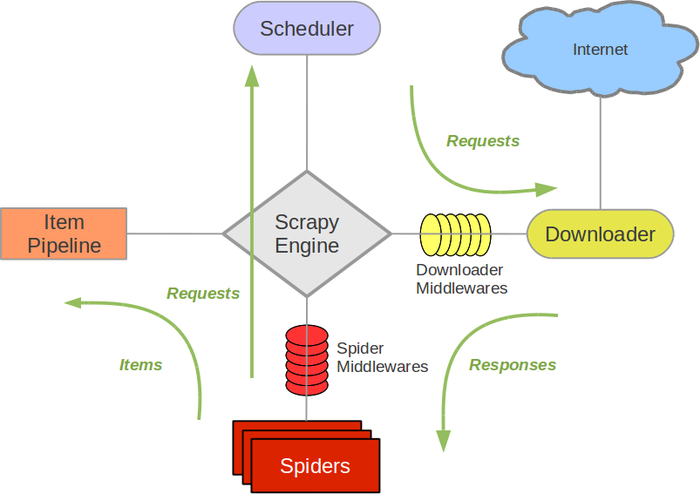
Scrapy Engine: 这是引擎,负责Spiders、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等等!(像不像人的身体?)
Scheduler(调度器): 它负责接受引擎发送过来的requests请求,并按照一定的方式进行整理排列,入队、并等待Scrapy Engine(引擎)来请求时,交给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spiders来处理,
Spiders:它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器),
Item Pipeline:它负责处理Spiders中获取到的Item,并进行处理,比如去重,持久化存储(存数据库,写入文件,总之就是保存数据用的)
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spiders中间‘通信‘的功能组件(比如进入Spiders的Responses;和从Spiders出去的Requests)
参考于 详情看 这里 https://cuiqingcai.com/3472.html/comment-page-2#comments
三 编写你的爬虫代码
(1)首先,我们要明确我们的爬取站点和目标。之前说了,今天我们来爬去虎扑NBA的所有球员资料,来,直接上代码https://nba.hupu.com/players/rockets 从这里开始,这个页面有各个球队,各个球员的所有基本资料。目标站点明确了,接下来我们来明确一下我们需要爬的字段。在items.py里面定义要爬取的字段。(这是items.py)
import scrapy
class HupuItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
#球队
playerteam = scrapy .Field ()
#球员照片
playerimg = scrapy .Field ()
#球员姓名
playername = scrapy .Field ()
#球员号码
playernumber = scrapy .Field ()
#球员位置
playerjob = scrapy .Field ()
#球员身高
playertall = scrapy .Field ()
#球员体重
playerweight = scrapy .Field ()
#球员生日
playerbirthday = scrapy .Field ()
#球员合同
playercont = scrapy .Field ()
#球员年薪
playersal = scrapy .Field ()(2)然后,开始编写你的爬虫代码:(这是我的player.py)
import scrapy
import re
from hupu .items import HupuItem
class Hupu(scrapy .Spider ):
name = 'hupu'
allowed_domains=['hupu.com']
start_urls = ['https://nba.hupu.com/players/rockets']导入scrapy模块,re模块是正则模块,后面要用到的,导入刚才配好的items文件。
name 就是你自定义的爬虫名字,allowed_domains是该爬虫的允许作用域,start_urls 是起始的开爬的url地址。
然后重写parse这个方法,这里我用了xpath方法提取了球队的名字和球队的连接
def parse(self, response):
url_list = response.xpath('//span[@class="team_name"]/a/@href').extract()
playerteam_list = response.xpath('//span[@class="team_name"]/a/text()').extract()

每个球队的链接都在这个标签下面,用xpath把它们提取成一个列表。球队名字也是如此。xpath的用法在这里就不细说了。
这里用了迭代的方法,zip打包了两个球队名字和球队链接列表,让它们平行的循环,把球队的链接传入到parse_detail函数去处理,meta传的是个字典类型。
for url, playerteam in zip(url_list, playerteam_list):
team_url = url
yield scrapy.Request(url=team_url, meta={'playerteam': playerteam}, callback=self.parse_detail)下面则是parse_detail函数的内容
def parse_detail(self, response):
print("开始下载...")
item =HupuItem ()
# 球队
item['playerteam'] = response .meta['playerteam']
#球员照片
player_img_list = response.xpath('//td[@class="td_padding"]//img/@src').extract()
# 球员姓名
player_name_list = response.xpath('//td[@class="left"][1]//a/text()').extract()
# 球员号码
player_number_list = response.xpath('//tr[not(@class)]/td[3]/text()').extract()
#球员位置
player_job_list = response.xpath('//tr[not(@class)]/td[4]/text()').extract()
# 球员身高
player_tall_list = response.xpath('//tr[not(@class)]/td[5]/text()').extract()
# 球员体重
player_weight_list = response.xpath('//tr[not(@class)]/td[6]/text()').extract()
# 球员生日
player_birthday_list = response.xpath('//tr[not(@class)]/td[7]/text()').extract()
# 球员合同
player_cont_list = response.xpath('//td[@class="left"][2]/text()').extract()
#球员年薪
player_sal_list = response.xpath('//td[@class="left"][2]/b/text()').extract()这个函数主要是对刚才传进来的请求url进行分析处理,我们仍然使用xpath来提取网页上的这些内容(如下)(包括之前传入的球队名字)

由于一支队伍有很多个球员,所以xpath提取的仍然是列表类型。然后再利用for迭代配合zip把每一位球员的信息遍历出来,并存入之前设置好的items字段中,最后yield item。
zz = zip(player_img_list ,player_name_list,player_number_list,player_job_list,player_tall_list,player_weight_list,player_birthday_list,player_cont_list,player_sal_list)
for player_img,player_name ,player_number,player_job ,player_tall,player_weight,player_birthday,player_cont,player_sal in zz:
item ["playerimg"]=player_img
item['playername'] = player_name
item['playernumber'] =player_number
item['playerjob'] = player_job
item['playertall'] = player_tall
item['playerweight'] = player_weight
item['playerbirthday'] = player_birthday
if player_cont:
item['playercont'] = player_cont
else:
item['playercont'] = 'NULL'
item['playersal'] = player_sal
yield item这样我们就写完了自定义的爬虫代码了!
(3)运行你的爬虫程序
打开cmd ,把路径导入到你spiders下面
输入 scrapy crawl hupu 即可以运行你的爬虫了!
输入这条命令 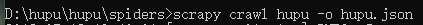
可以看见类似以下内容

再看看文件夹下面有没有生成json文件

在json.cn 里解析json数据

如果以上都没有问题那么,接下来我们进行数据入mysql数据库的操作。
四 数据存入Mysql数据库
(1)首先要确保计算机上成功安装了mysql数据库,安装就略过了...
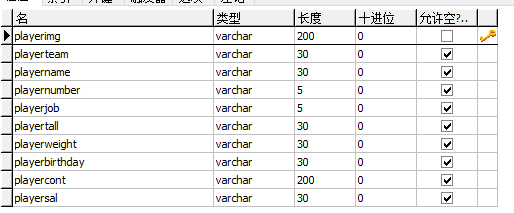
(2) 在你的数据库中创建相应的表,这是我创建的表
(3)在你的settings文件中设置一下内容
注册管道文件。
ITEM_PIPELINES = {
'hupu.pipelines.HupuPipeline': 300,
'hupu.pipelines.DBPipeline': 10,
}MYSQL_HOST = 'localhost'
MYSQL_DBNMAE = 'hupu'
MYSQL_USER = 'root'
MYSQL_PASSWORD = '123456'(4)编写你的管道文件
import pymysql
from hupu import settings
from scrapy .conf import settings
class DBPipeline(object ):
#连接数据库
def __init__(self):
self.conn = pymysql.connect(host='127.0.0.1', port=3306,
user = 'root', password = '123456',db='hupu',charset='utf8')
self.cursor = self.conn.cursor()
self .conn .commit()
def process_item(self, item, spider):
try:
self.cursor.execute(
"insert into player_info( playerimg,playerteam,playername,playernumber,playerjob,playertall,playerweight,playerbirthday,playercont,playersal) "
"values(%s ,%s, %s, %s ,%s ,%s, %s, %s, %s,%s)",
(
item["playerimg"],
item['playerteam'],
item['playername'],
item['playernumber'],
item['playerjob'],
item['playertall'],
item['playerweight'],
item['playerbirthday'],
item['playercont'],
item['playersal'])
)
self.conn.commit()
except pymysql .Error :
print("插入错误")
return item这里利用了游标,向表中插入数据。
(5)观察你的数据库内容

到这里就大功告成了,我们可以看见全NBA的球员数据都已经在你的数据库中了!!!















 8183
8183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









