










一.yolov3设计的基本思路
在说yolov3时,我们先从图像分类到目标检测再到YOLOV3去介绍yolov3的的基本设计思路。 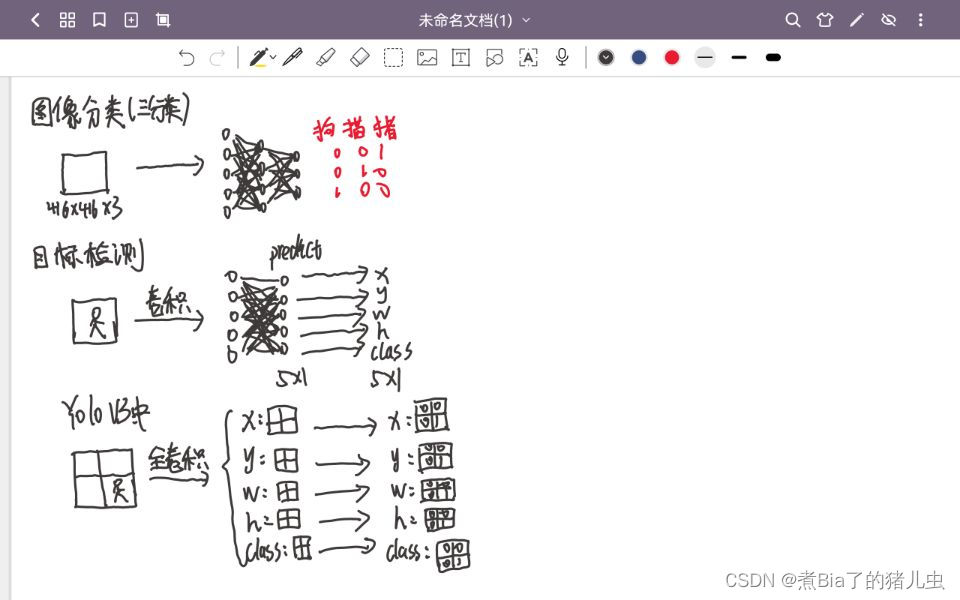
如上图所示,在图像分类中(假设是三分类),我们输入一张图片时,是判断的是整个图像他的类别是属于三分类问题中的哪一类,然后为了得到类别(比如我们分的类别是狗猫猪这三类),我们将图片送入神经网络中,经过了一个全连接层进行分类,通过softmax进行最终的输出(PS:多分类问题用softmax,二分类问题用sigmoid),然后我们把神经网络的输出值和真实值之间进行一个损失的计算,再进行一个反向传播调整神经网络神经元的参数,直到loss收敛,表明网络已经训练好了,但是由于经过了一个人全连接层,输入和输出是固定的,并且输出位置的神经元个数和类别数是一样的。
那么,图像分类的原理,可以运用到目标检测当中吗?首先我们要知道什么是目标检测,目标检测与图像分类的不同在于目标检测是一个图片中可能包含多个我们要获取的目标信息并用画框的方式进行目标定位,而图像分类是对整个图片进行分类(也就是一个图片只有一个目标信息),如上图所示(目标检测标题下的图),假设图片中有一个人的目标,为了定位到他的位置,我们需要用框画出他的位置,也就是要让神经网络输出框的中心点,框的宽高,以及框的类(x,y,w,h,class),若按照图像分类的原理,是要经过一层全连接层,因此输出位置的神经元个数是5,可以实现一个目标的检测。但是若图片中有两个物体时怎么办,我们都知道由于经过全连接层输入和输出已经固定了,并且一个神经元负责检测一类问题,如果一个图片里包含了两个目标的话,那么我们就要获得两个目标的坐标信息(x1,y1,w1,h1,class1),(x2,y2,w2,h2,class2),显然此时的输出位置的神经元个数为5的神经网络是办不到的,那我们此时可以将输出位置的神经元个数增加到10个,显然是可以做到,在实际的训练中,数据集中每张图片包含的目标信息的个数是不一样的,我们不可能每次在网络训练的时候,都去增加神经元的个数,因此在目标检测任务中,我们会规定网络去分最大多少类。那怎么实现呢?YOLOv3给出了答案(上图yolov3的标题)
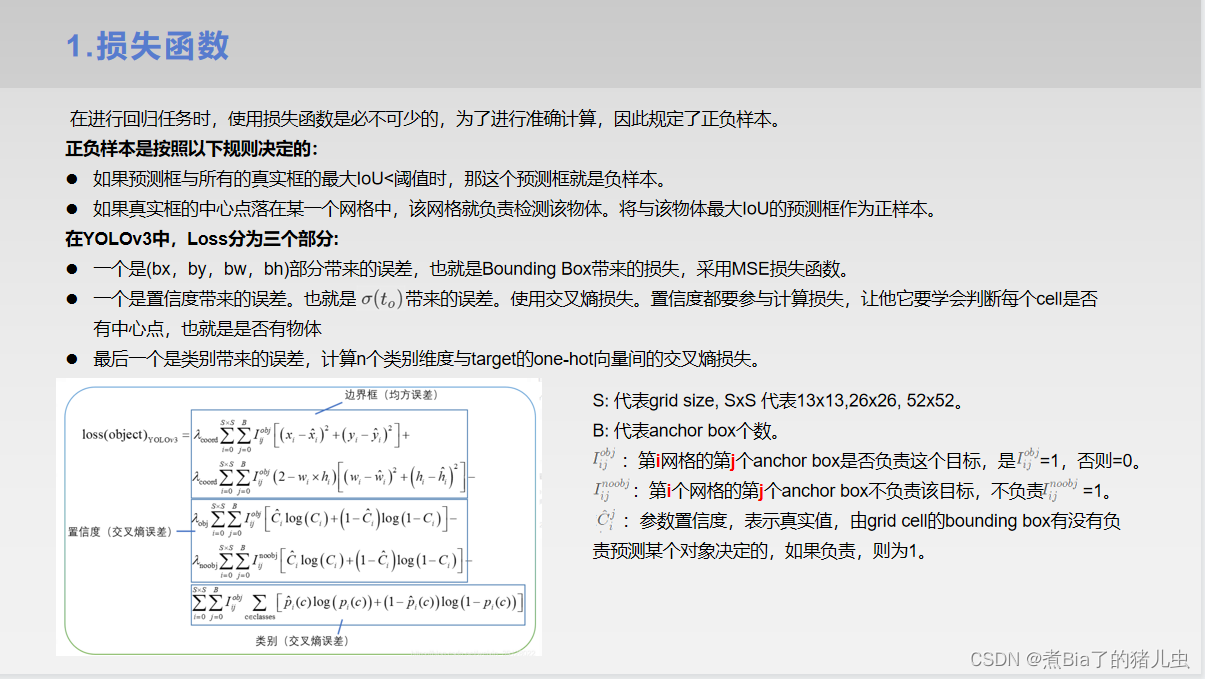
在yolo v3中,我们会把图片分成很多个网格(假设我们最大的分类数是4类),每个网格去检查这个网格中是否包含物体,每个网格都有自己对应的一个目标信息的输出值(也就是框的坐标信息值),网格中有目标的就置1,输出对应的目标信息。没有目标就置0,所有的目标信息的值都是0。具体怎么实现,请客官往下看。以下就是我在开组会时,使用的自己做的PPT内容(PS:PPT里有一部分内容是借鉴了其他大佬的博客的知识,但是我没有博客保存链接,因此看到了请艾特我)。

第二部分:特征提取网络
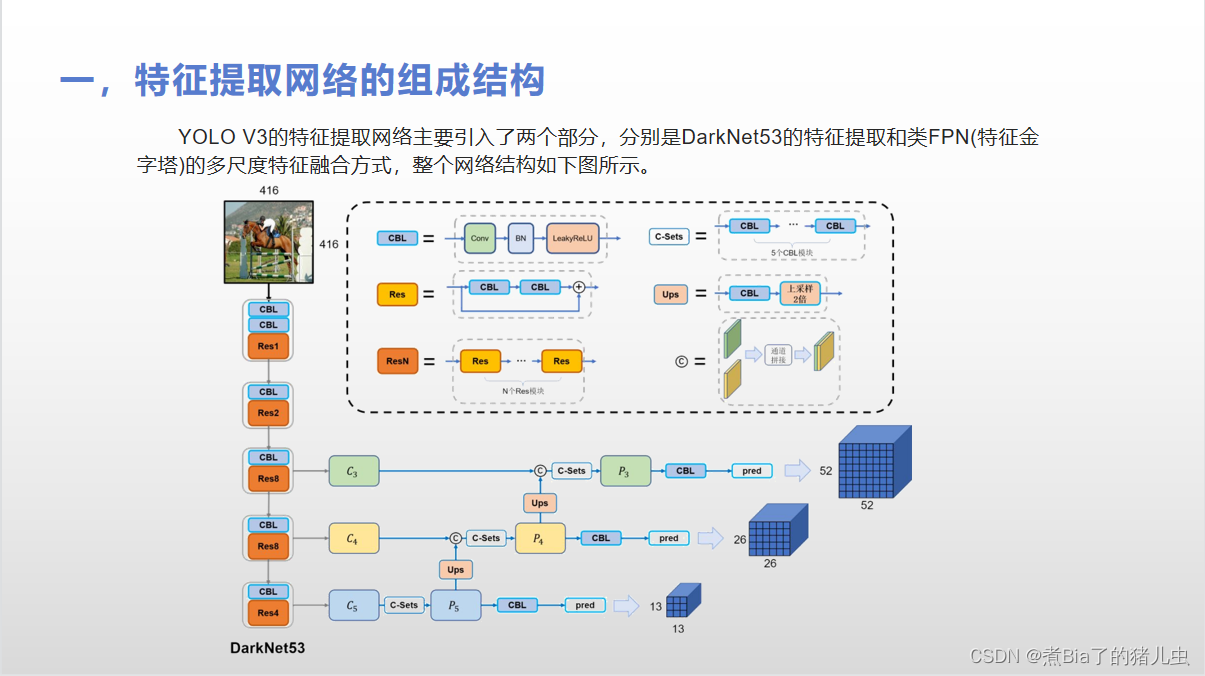
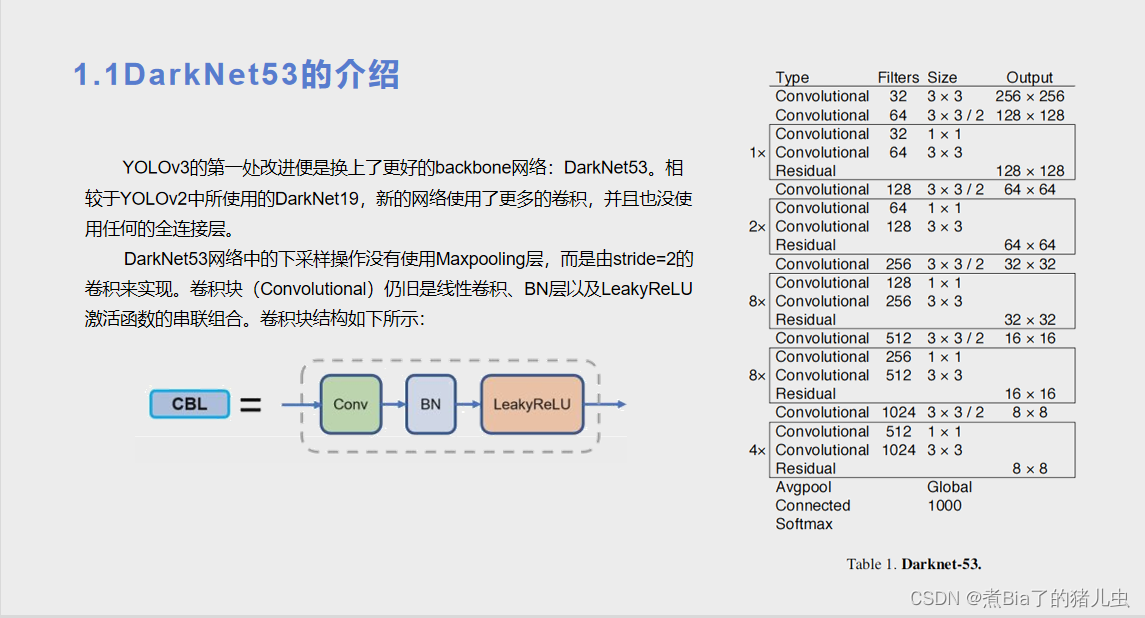
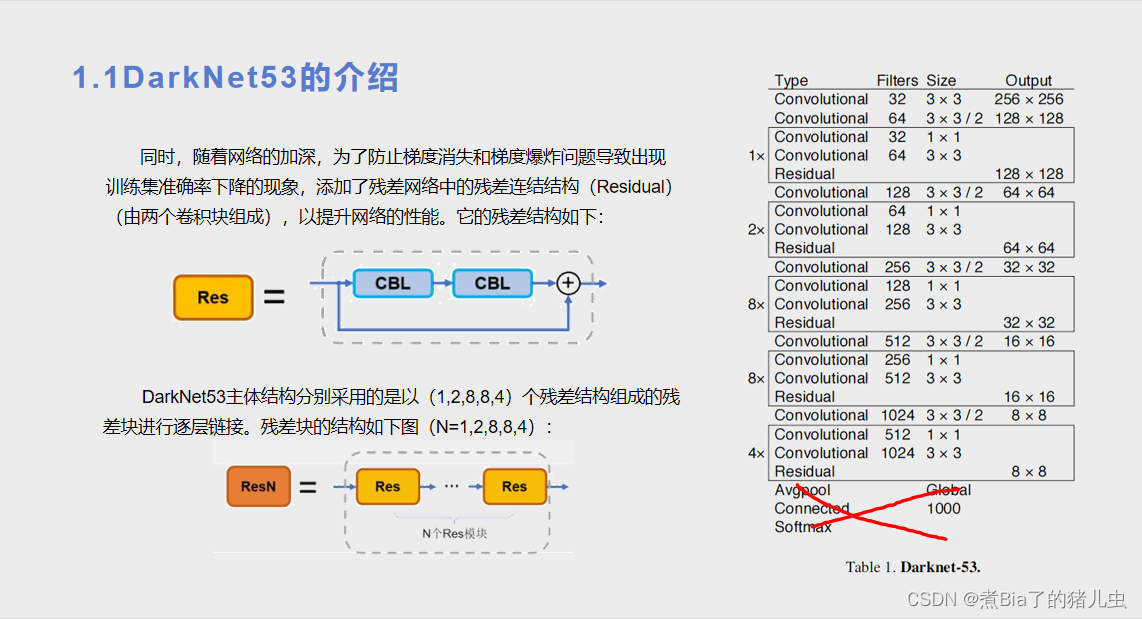
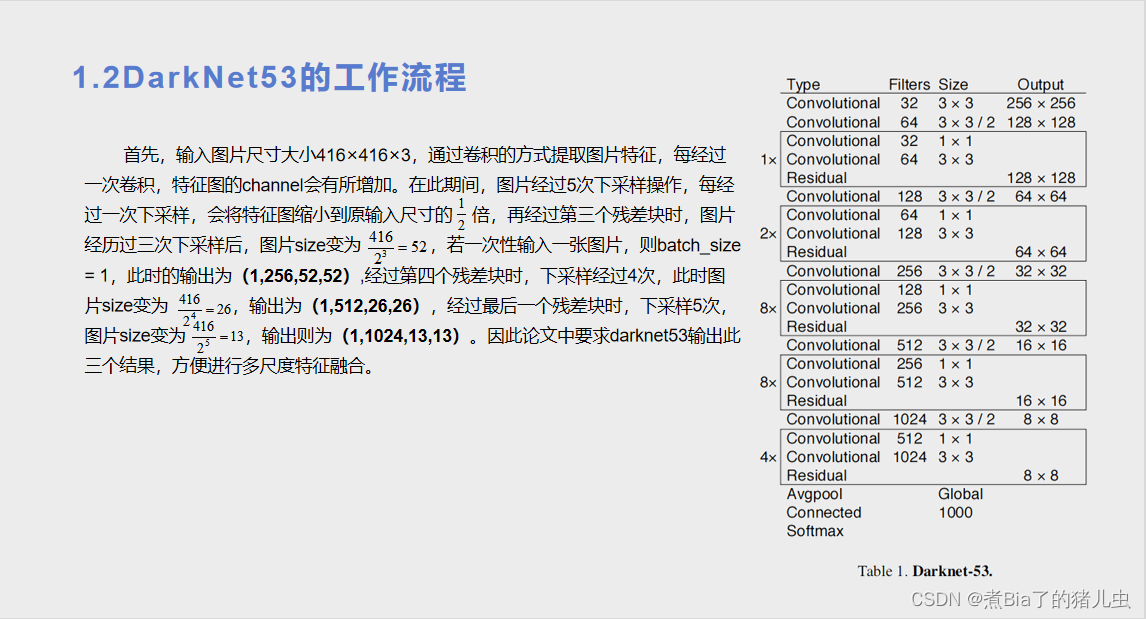
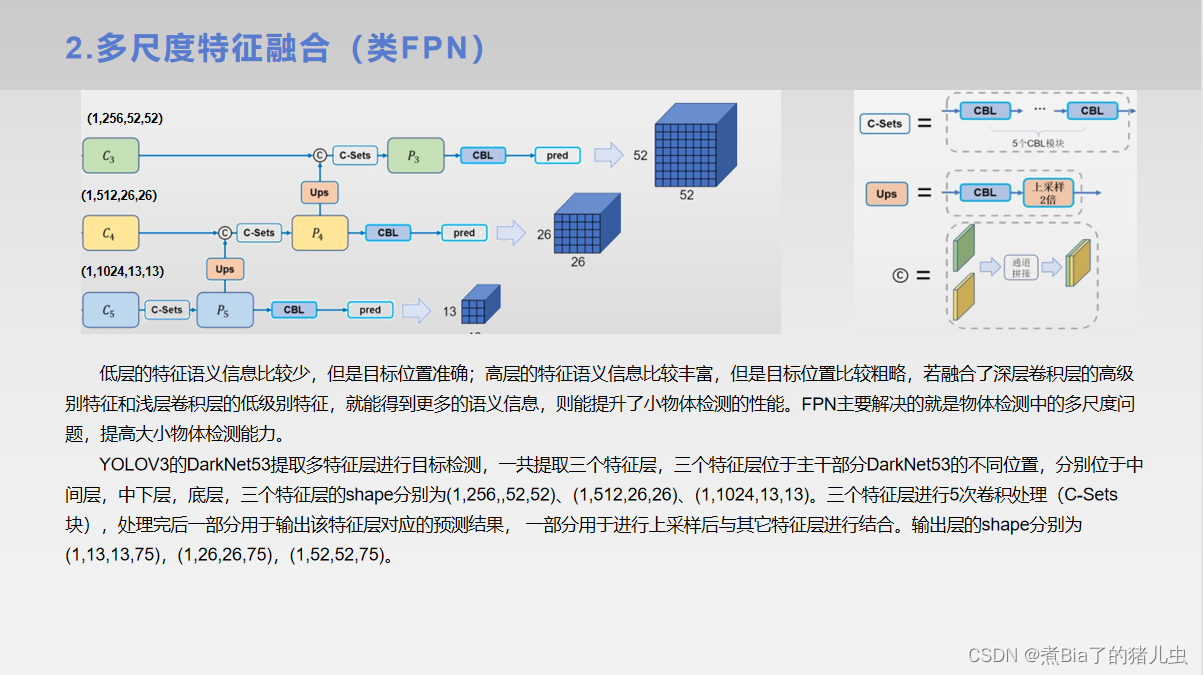
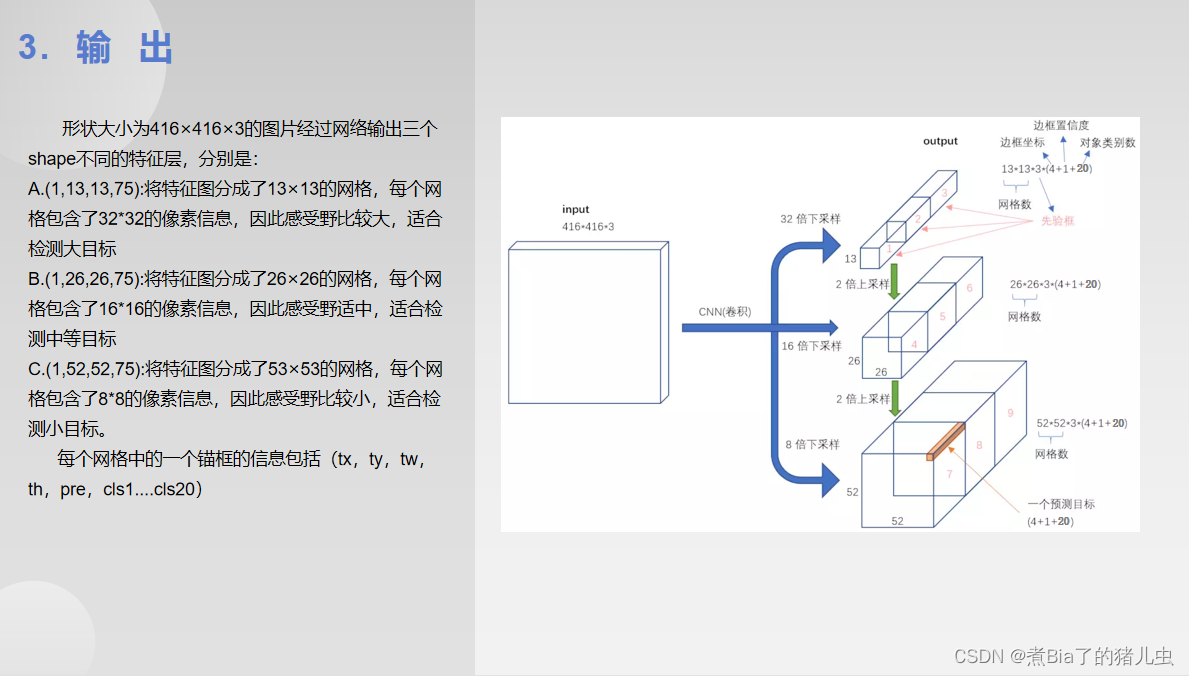 第三部分:边界框的生成
第三部分:边界框的生成
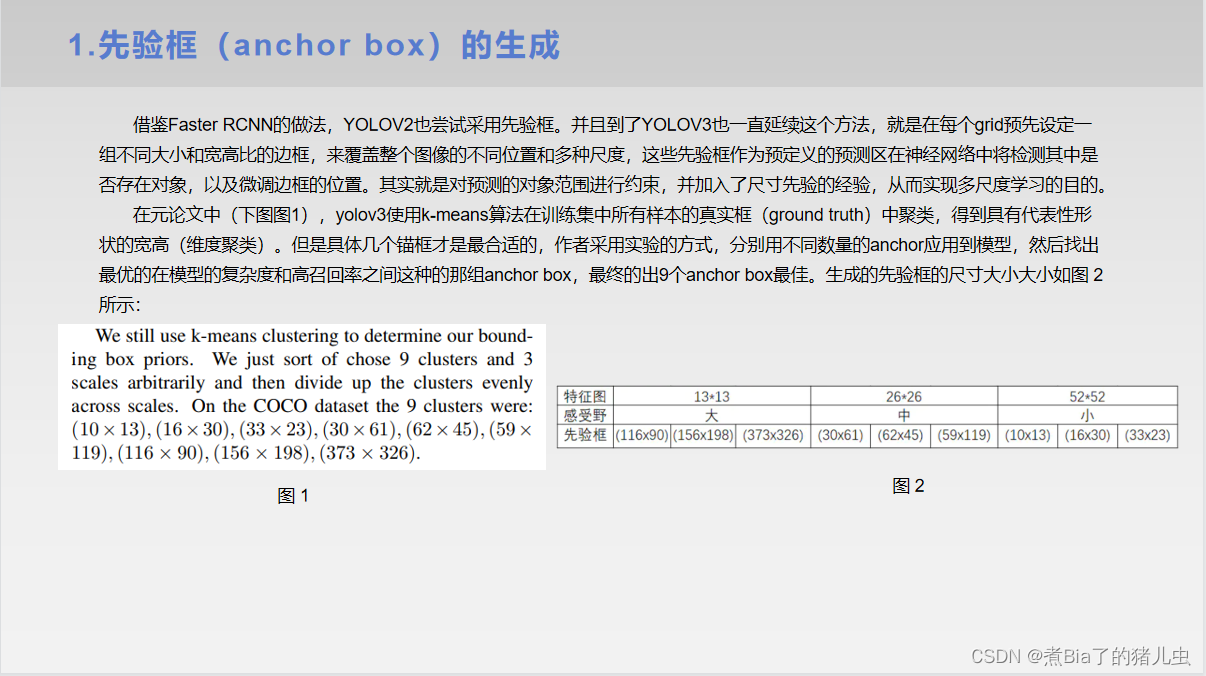


第四部分:误差计算



第5部分:测试阶段

PS:以上是我在开组会时,自己做的一个PPT内容(有些内容存在问题,但是我还没有解决),因为在汇报的过程中,我还加自己口述的内容,并没有写在PPT上,因此对于这里面的过程不懂的或者有什么错误的地方欢迎评论区留言,大家一起探讨。















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









