







7 PyTorch的正则化
7.1 正则化之weight_decay
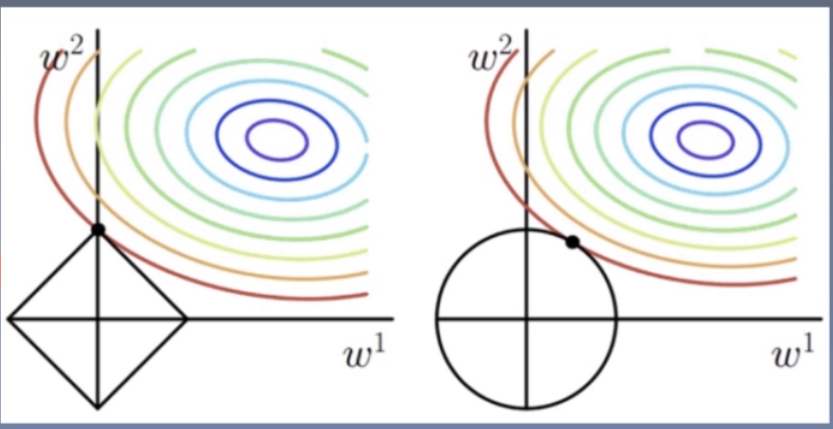
Regularization:减小方差的策略,从而解决过拟合问题,常见的方法有:L1正则化和L2正则化weight decay(权值衰减)= L2 Regularization
在PyTorch的优化器中提供了 weight decay(权值衰减)的实现
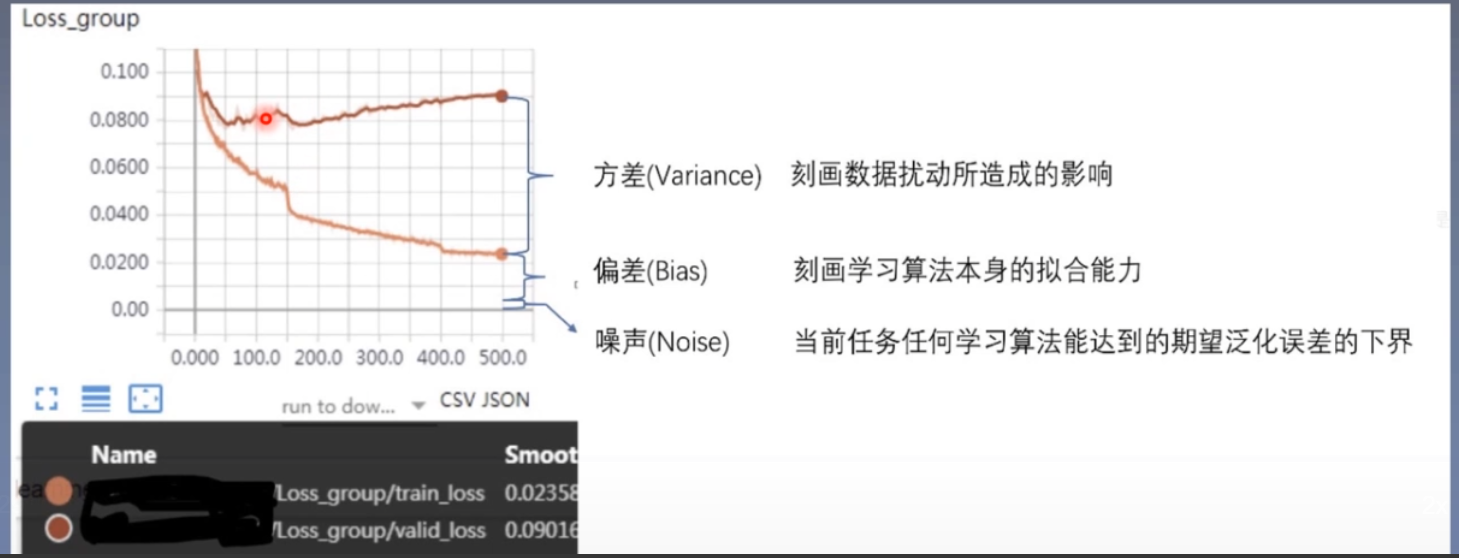
误差可分解为:偏差、方差与噪声之和,即误差=偏差+方差+噪声
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法自身的拟合能力
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
- 噪声:表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界
L1正则项:
∑
i
=
1
N
∣
w
i
∣
\sum\limits_{i = 1}^N {\left| {{w_i}} \right|}
i=1∑N∣wi∣
L2正则项:
∑
i
=
1
N
w
i
2
\sum\limits_{i = 1}^N {w_i^2}
i=1∑Nwi2
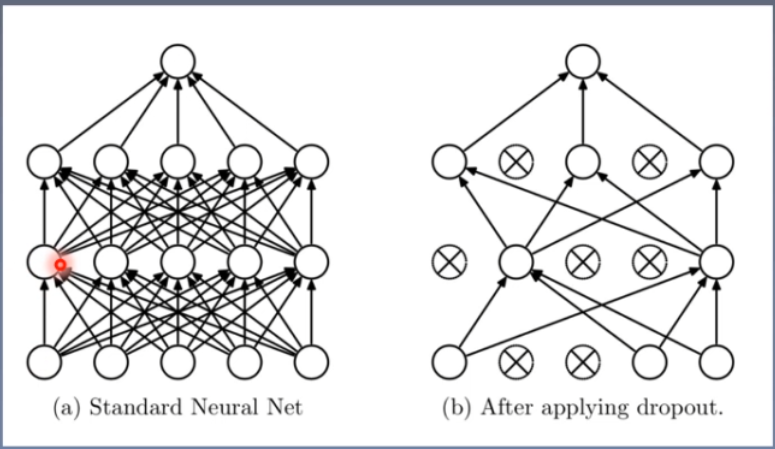
7.2 正则化之Dropout
Dropout:随机失活神经元
- 随机:dropout probability
- 失活:weight=0
注意事项:下面二选一即可解决【权值数据尺度变化/分布异常,导致训练困难】
- 测试模式时,所有权重需乘以 1 − p 1-p 1−p
- 【
PyTorch实现细节:】训练模式时,所有权重均乘以 1 1 − p \frac{1}{1-p} 1−p1,即除以 1 − p 1-p 1−p
-
nn.Dropout()
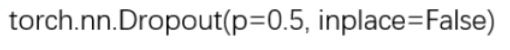
功能:Dropout层参数说明:
- p:被舍弃概率,失活概率
7.3 Batch Normalization
Batch Normalization(BN):批标准化,目的是使一批(Batch)所对应的feature map的数据满足均值为0、方差为1的分布规律
【重点】Batch Normalization详解以及PyTorch实验
- 批:一批数据,通常为mini-batch
- 标准化:0均值,1方差
使用之处:卷积层之后,激活函数层之前优点:
- 可以
用更大学习率,加速模型收敛- 可以
不用精心设计权值初始化- 可以
不用dropout或较小的dropout- 可以
不用L2或者较小的weight decay- 可以
不用LRN(局部响应标准化)

_BatchNorm类

-
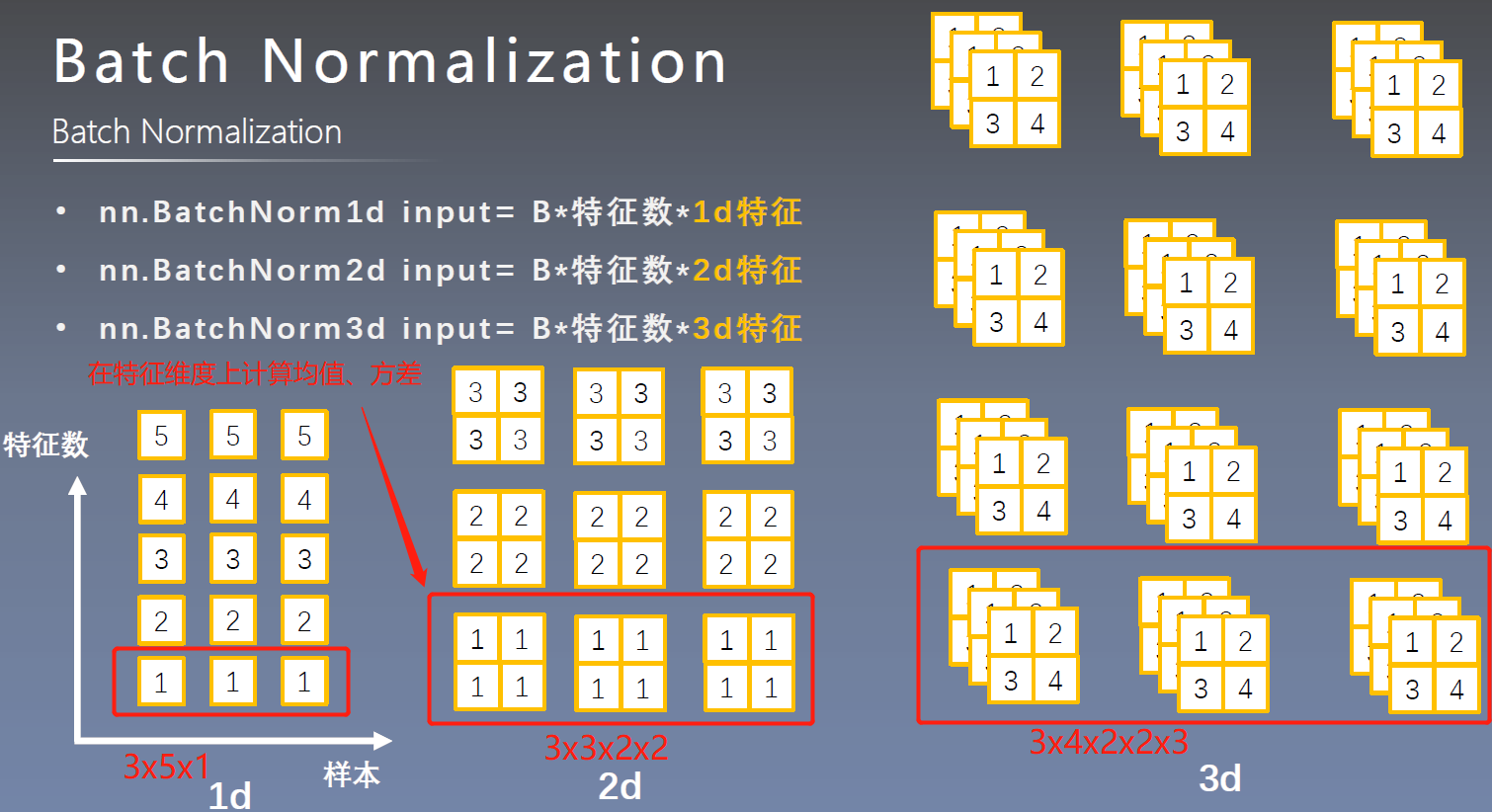
nn.BatchNorm1d() -
nn.BatchNorm2d() -
nn.BatchNorm3d()- 参数说明:
- num_features:一个样本特征数量(最重要)
- eps:分母修正项,防止分母为零
- momentum:指数加权平均估计当前mean/var
- affine:是否需要affine transform
- track_running_stats:是训练状态还是测试状态
- 主要属性:
- running_mean:均值
- running_var:方差
- weight:affine transform中的gamma
- bias:affine transform中的beta
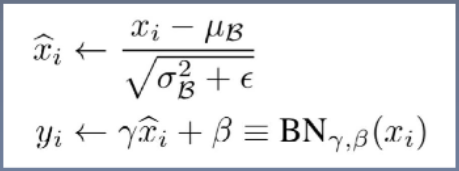
注意事项:-
训练时:均值和方差采用指数加权平均计算
-
计算公式:
running_mean=(1-momentum)*pre_running_mean+momentum*mean_t
running_var=(1-momentum)*pre_running_var+momentum*var_t
-
-
测试时:均值和方差采用当前统计值
- 参数说明:
-
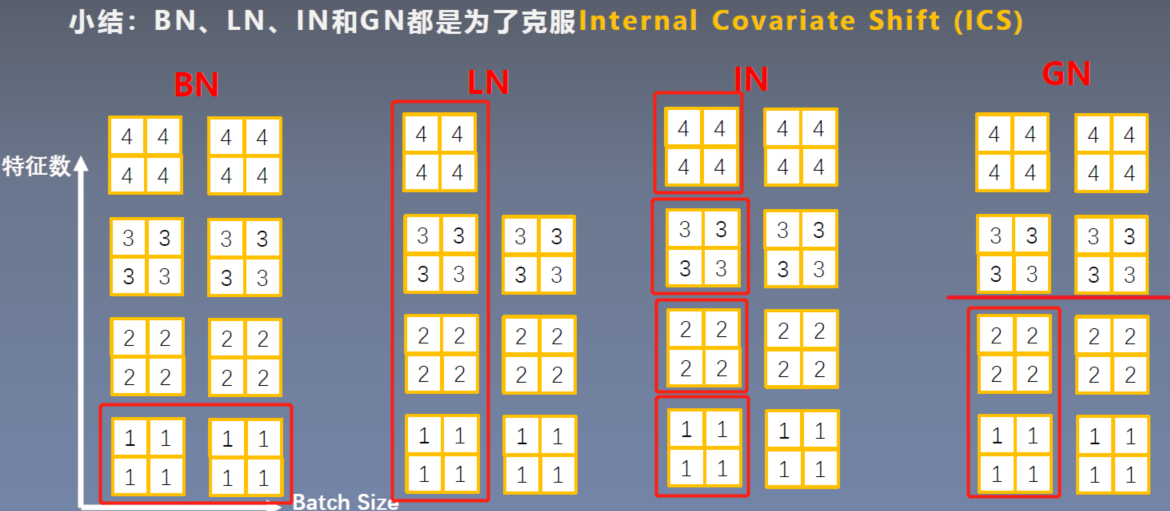
7.4 Normalization in DL
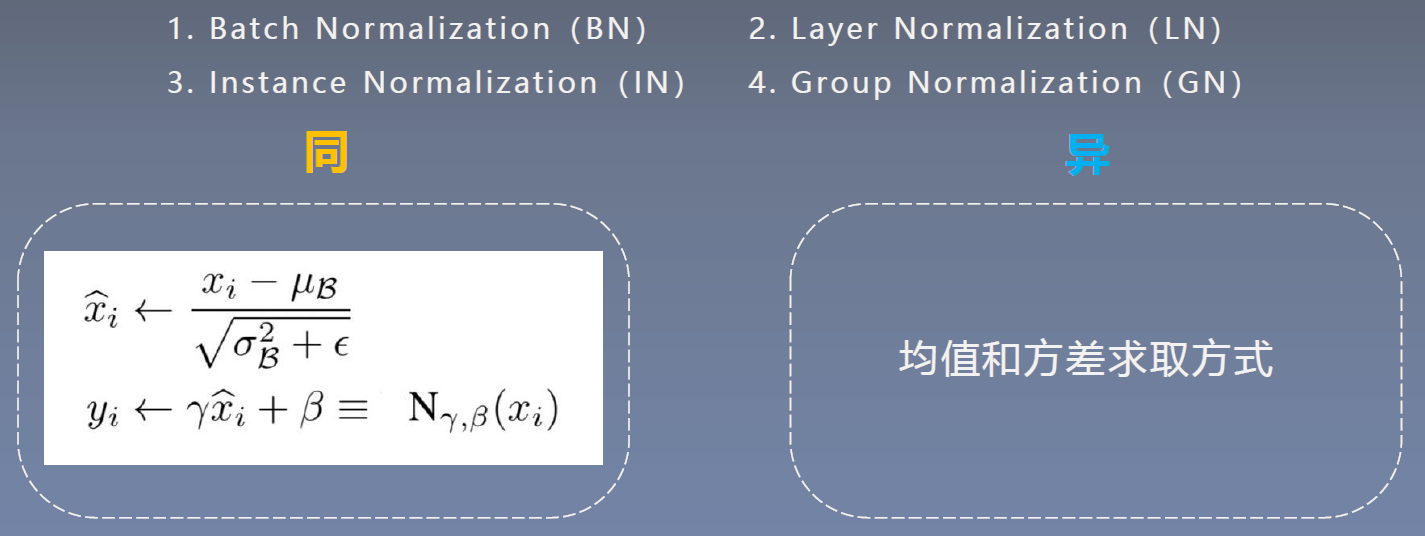
Normalization:可以约束数据尺度,避免出现数据梯度爆炸或者梯度消失的情况,利于模型训练常见的Normalization:
- Batch Normalization(BN)
- Layer Normalization(LN)
- Instance Normalization(IN)
- Group Normalization(GN)
-
Layer Normalization(LN)
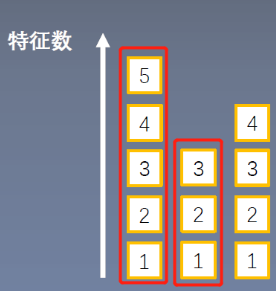
起因:BN不适用于变长的网络,如RNN思路:逐层计算均值和方差
注意事项:
- 不再有running_mean和running_var
- gamma和beta为逐元素的
-
nn.LayerNorm()

参数说明:- normalized_shape:该层特征形状,即C*H*W
- eps:分母修正项,防止分母为零
- elementwise_affine:是否需要affine transform
-
Instance Normalization(IN)起因:BN在图像生成(Image Generation)中不适用
思路:逐Instance(channel)计算均值和方差
-
nn.InstanceNorm()

参数说明:- num_features:一个样本特征数量(最重要)
- eps:分母修正项,防止分母为零
- momentum:指数加权平均估计当前mean/var
- affine:是否需要affine transform
- track_running_stats:是训练状态还是测试状态
-
Group Normalization(GN)
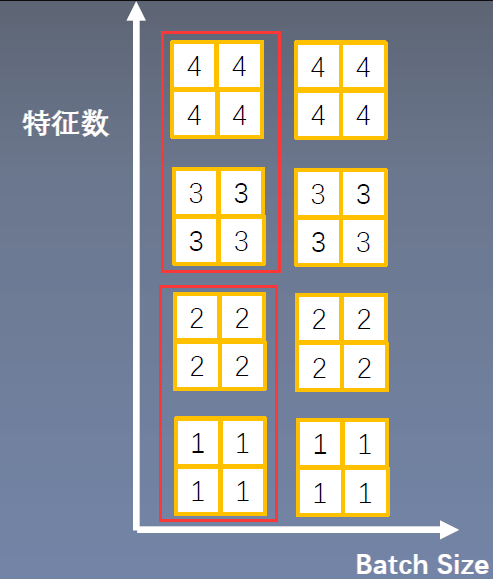
起因:小batch样本中,BN估计的均值和方差不准确思路:数据不够,通道来凑
注意事项:
- 不再有running_mean和running_var
- gamma和beta为逐通道(channel)的
应用场景:大规模(小batch size)任务
-
nn.GroupNorm()

参数说明:-
num_groups:分组数,通常设置为 2 n 2^n 2n
-
num_channels:通道数(特征数)
-
eps:分母修正项,防止分母为零
-
affine:是否需要affine transform
-














 4576
4576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









