






一、深度学习中,使用GPU进行训练,首先要确定电脑上是否有相应的驱动。
如果没有的话,可以在英伟达的官网上进行相应的下载。
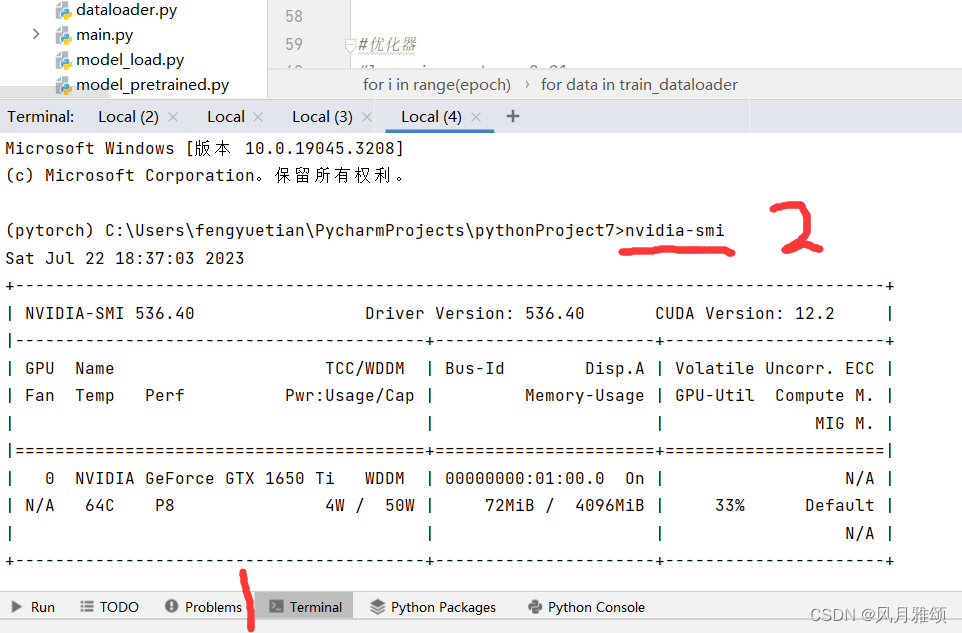
在pycharm中选择Terminal,然后输入
nvidia-smi会显示相应的版本,在下载时要注意版本型号。
二、调用GPU方式一
添加“.cuda()”,使用如下。
采用GPU进行训练,在三个地方进行相应的修改。
1、网络模型部分 model = model.cuda()
#创建网络模型
class Feng(nn.Module):
def __init__(self):
super(Feng, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(64*4*4, 64),
nn.Linear(64, 10),
)
def forward(self, x):
x = self.model(x)
return x
feng = Feng()
#先判断一下是否有GPU进行训练,但是每一个使用GPU前,都需要进行判断。
if torch.cuda.is_available():
#调用GPU进行训练
feng = feng.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()建立的网络模型,在下面进行相应的调用。可以先判断一下电脑上是否有相应的GPU驱动。
2、数据部分(输入,标注)
A、训练部分数据调用GPU imgs = imgs.cuda() targets = targets.cuda()
#训练步骤开始
for data in train_dataloader:
imgs, targets = data
imgs = imgs.cuda()#################
targets = targets.cuda()###############
outputs = feng(imgs)
loss = loss_fn(outputs, targets)
#优化器梯度清零
optimizer.zero_grad()
#反向传播,得到每个参数节点的梯度
loss.backward()
#调用优化器,对梯度参数进行优化
optimizer.step()
total_train_step = total_train_step + 1
#整体的步骤满100的时候,才打印
if total_train_step %100 == 0:
end_time = time.time()
print(end_time - start_time)
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
writer.add_scalar("train_loss", loss.item(), total_train_step)B、测试部分调用GPU
#测试步骤开始
total_test_loss = 0
#整体正确的个数为0
total_accuracy = 0
with torch.no_grad():#网络模型的梯度都去除
for data in test_dataloader:
imgs, targets = data
imgs = imgs.cuda()#######################
targets = targets.cuda()############################
outputs = feng(imgs)
loss = loss_fn(outputs, targets)#计算loss误差
total_test_loss = total_test_loss + loss.item()
#每小部分正确的个数
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy3、损失函数 loss =loss.cuda()
#损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.cuda()三、调用GPU方式二 device = torch.device("cuda") 如果是多显卡,可以制定相应的显卡,调用为 device = torch.device("cuda:1")
#定义训练的设备
#device = torch.device("cpu")#定义使用cpu进行训练
device = torch.device("cuda:0")#使用GPU训练同时,相应的数据以及损失函数等,也需要修改。
module = module.to(device)损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn = loss_fn.to(device)训练和测试数据
#训练步骤开始
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device) #测试步骤开始
total_test_loss = 0
#整体正确的个数为0
total_accuracy = 0
with torch.no_grad():#网络模型的梯度都去除
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)四、采用谷歌
搜索goole.colab
使用多种环境,常见代码
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")














 2063
2063











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









