







目录
摘 要
本论文研究了某市接待国内游客人数的情况,利用该市近四年旅游人数的数据,运用一种特殊的RNN模型——LSTM模型,建立旅游人数预测模型,预测本月数据时考虑前24个月的数据,利用往年数据对模型进行训练,迭代训练2000次,模型的损失函数降低到0.0001水平。分别对2019年和2020年旅游人数进行预测,测试值与真实值总人数相差不到1万人,并利用2019年的测试数据和真实数据的标准差评估了模型的预测效果,标准差为53.86,所以模型预测效果非常好。通过比对2020年真实值与预测值,分析出新冠病毒的全球蔓延对该市旅游人数影响巨大,使该市旅游人数减少了约74.67%,大约7012万人。
关键词:旅游人数,SLTM,新冠疫情.
1 问题重述
1.1 新冠疫情对Q市旅游人数的影响问题描述
2019年末的COV-19疫情的出现,在2020年产生了重大影响,全国多行业的发展有所减缓,Q市的旅游业也严重受到波及。近4年来 (2016年~2019年) Q市接待国内游客如下表1所示。根据表中历史数据,试建立数学模型,回答以下问题:
(1)根据2016-1018前三年的数据,建立旅游人数预测模型,预测2019年Q市各月的旅游人数,并和2019年实际人数进行比较,说明此模型的预测效果;
(2)根据2016-2019年四年的数据,以上述模型预测并评价此次新冠病毒的全球蔓延对2020年Q市旅游人数造成的影响(表2为2020年实际旅游人数)。
表1. Q市往年接待国内游客人数(单位:万人)
| 月年 | 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | 7月 | 8月 | 9月 | 10月 | 11月 | 12月 | 合计 |
| 2016年 | 47 | 32 | 134 | 153 | 506 | 412 | 876 | 1226 | 237 | 589 | 142 | 64 | 4418 |
| 2017年 | 48 | 35 | 146 | 183 | 713 | 425 | 1087 | 1347 | 261 | 754 | 173 | 82 | 5254 |
| 2018年 | 53 | 31 | 158 | 224 | 861 | 537 | 1246 | 1562 | 326 | 924 | 215 | 87 | 6224 |
| 2019年 | 57 | 34 | 164 | 238 | 976 | 612 | 1429 | 1916 | 357 | 1163 | 206 | 75 | 7227 |
表2. Q市2020年接待国内游客人数(单位:万人)
| 月年 | 1月 | 2月 | 3月 | 4月 | 5月 | 6月 | 7月 | 8月 | 9月 | 10月 | 11月 | 12月 | 合计 |
| 2020年 | 32 | 14 | 12 | 17 | 68 | 174 | 657 | 765 | 127 | 342 | 107 | 63 | 2378 |
1.2 新冠疫情对Q市旅游人数的影响问题中数据的解释
表格中单位为万人,模型预测结果可以采用四舍五入的方法保留四位小数。
2 假设和符号
2.1 基本假设
1. 旅游需求发展没有跳跃式发展,即需求的发展是渐进的,旅游业发展平稳。
2. 景点本身不发生大的变化。
3. 检索得到的数据可靠性高。
4. 旅游需求主要受资源,环境,交通,季节,费用和服务质量等因素的影响。
2.2 论文中所用符号说明基本假设
X:代表月份(1,2,…,12),输入数据
y:代表每月对应的旅游人数
tanh:激活函数
C_t:LSTM细胞状态
3 模型求解
3.1 模型的建立
3.1.1 LSTM模型介绍
长短期记忆神经网络(long short-term memory,LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说就是比普通RNN在更长的序列中有更好的表现。主要的改变是增加了三个门,分别是输入门、输出门和忘记门。
所有 RNN 都具有一种重复神经网络模块的链式的形式。在标准的 RNN 中,这个重复的模块只有一个非常简单的结构,例如一个 tanh 层。LSTM 同样是这样的结构,但是重复的模块拥有一个不同的结构。不同于 单一神经网络层,这里是有四个,以一种非常特殊的方式进行交互。
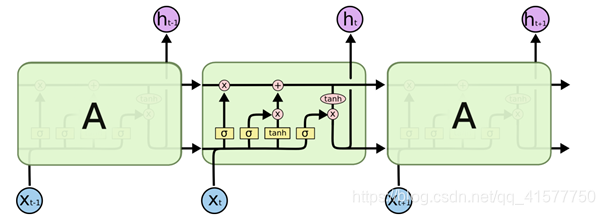
图1. LSTM 中的重复模块包含四个交互的层
图中使用的各种元素的图标解释如下:

图2. LSTM 中的图标
3.1.2 LSTM模型核心思想
LSTM 的关键就是细胞状态,水平线在图上方贯穿运行。细胞状态类似于传送带。直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。
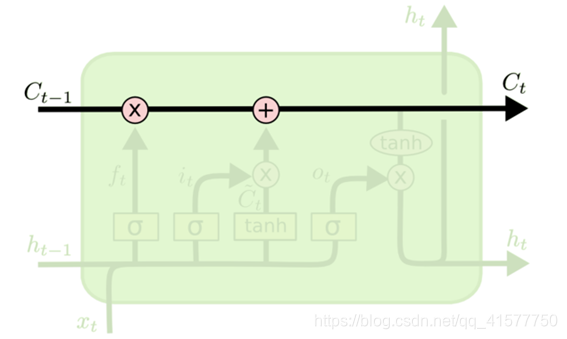
图3. SLTM核心思想
LSTM 有通过精心设计的称作为“门”的结构来去除或者增加信息到细胞状态的能力。门是一种让信息选择式通过的方法。他们包含一个 sigmoid 神经网络层和一个 pointwise 乘法操作。
图4. SLTM的门结构
Sigmoid 层输出 0 到 1 之间的数值,描述每个部分有多少量可以通过。0 代表“不许任何量通过”,1 就指“允许任意量通过”!
LSTM 拥有三个门,来保护和控制细胞状态。
3.1.3 理解 LSTM
LSTM 中的第一步是决定从细胞状态中丢弃什么信息。这个决定通过一个称为忘记门层完成。该门会读取h_{t-1}和x_t,输出一个在 0 到 1 之间的数值给每个在细胞状态C_{t-1}中的数字。1 表示“完全保留”,0 表示“完全舍弃”。
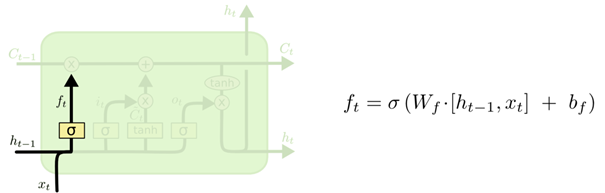
图5. 决定丢弃信息
下一步是确定什么样的新信息被存放在细胞状态中。这里包含两个部分。第一,sigmoid 层称 “输入门层” 决定什么值将要更新。然后,一个 tanh 层创建一个新的候选值向量,\tilde{C}_t,会被加入到状态中。
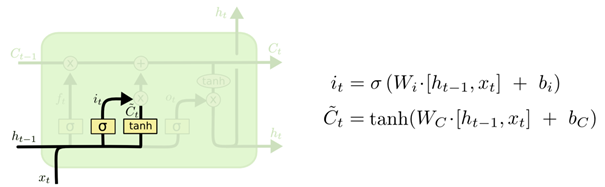
图6. 确定更新信息
更新旧细胞状态,C_{t-1}更新为C_t,把旧状态与f_t相乘,丢弃掉确定需要丢弃的信息。接着加上i_t * \tilde{C}_t。这就是新的候选值,根据决定更新每个状态的程度进行变化。
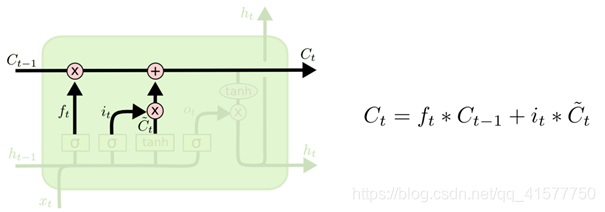
图7. 更新细胞状态
最终,需要确定输出什么值。这个输出将会基于细胞状态,但是也是一个过滤后的版本。首先,运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,把细胞状态通过 tanh 进行处理(得到一个在 -1 到 1 之间的值)并将它和 sigmoid 门的输出相乘,最终仅仅会输出确定输出的那部分。
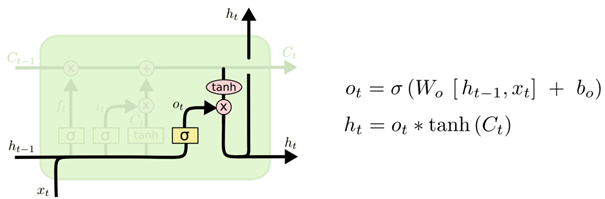
图8. 输出信息
3.2 求解或编程
3.2.1 实现原理
构建一个具有单个神经元的输入层、具有4个LSTM存储单元的隐藏层,以及具有单个值预测的输出层的神经网络。LSTM存储单元采用的是默认的sigmoid激活函数。对网络训练2000个epochs,并将batch_size设置为1。
模型预测过程中会将新预测到的数据值添加列表,用于预测接下来的数据。采用的方式是逐个月份进行预测,利用前24个月的数据,预测本次数据,所以需进行12次预测。
LSTM的输入数据具有以下形式的特定阵列结构:[样本,时间步长,特征]。在create_dataset()函数中生成的数据集采用的是如下的形式:[样本,特征]。然后需要使用numpy.reshape()函数对数据集进行结构转换,转换时将每个样本作为一个时间步长。
3.2.2 具体过程
1. 导入历年旅游人数的数据,共60条,表示2016-2020近60个月旅游人。
2. 标准化数据,使用Scikit-Learn中的MinMaxScaler预处理类对数据集进行归一化处理,将数据缩放到0——1。
3. 将数据分为训练集和测试集,解决问题一训练集为1-36条数据,测试集为37-48条数据,解决问题二训练集为1-48条数据,测试集为49-60条数据。
4. 创建训练数据集X_train, y_train分别代表模型输入数据集和结果数据集,每一维X_train[i]包含12个数据,及预测月份y_train[i]的前12个月的数据。
5. 模型设置隐含层设置4个LSTM存储单元,神经元设置单个输入输出层,采用默认的sigmoid激活函数,loss函数采用标准差。对X_train, y_train数据集进行训练,训练周期为epochs=2000,batch_size=1,得到数据模型。
6. 重复12轮预测,利用前24个月的数据,每一轮预测一个月份的旅游人数,并将新预测的数据添加到列表中,用于预测下一个月份的旅游人数。
7. 预测数据与真实数据计算标准差,评估模型预测效果。
8. 反标准化预测数据,并打印数据折线图和旅游人数预测结果。
3.2.3 实现代码:
1. 建立模型
def build_model():
model = Sequential()
model.add(LSTM(units=4, input_shape=(1, look_back)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
return model
2. 创建数据集
def create_dataset(dataset):
dataX, dataY = [], []
# for i in range(len(dataset) - look_back - 1):
for i in range(len(dataset) - look_back):
x = dataset[i:i + look_back, 0]
dataX.append(x)
y = dataset[i + look_back, 0]
dataY.append(y)
# print('X: %s, Y: %s' % (x, y))
return np.array(dataX), np.array(dataY)
3. 训练模型
model = build_model()
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=2)
4. 模型预测
predict_xlist = dataset[train_size - look_back:train_size + validation_size, :] # 添加预测x列表
predict_y = [] # 添加预测y列表
predict_validation = [] #添加预测y列表
while len(predict_y) < 12:
i = 0
validation = predict_xlist[-timesteps:, :]
X_validation, y_validation = create_dataset(validation)
X_validation = np.reshape(X_validation, (X_validation.shape[0], 1, X_validation.shape[1])) # 变换格式,适应LSTM模型
# 模型预测数据
predict_validation = model.predict(X_validation)
pre = predict_validation.astype('float32')# 12维
predict_xlist = np.concatenate((predict_xlist, pre), axis=0)
# 反标准化数据,目的是为了保证MSE的准确性
predict_validation = scaler.inverse_transform(predict_validation) # 预测的 19年游客的数据值
y_validation = scaler.inverse_transform([y_validation])
predict_y.extend(predict_validation[0]) # 预测的结果y,每次预测的1个数据,添加进去3.2.4 预测结果及分析:
实验数据如下:
表3.1. Q市2019、2020年接待国内游客人数真实值及预测值(单位:万人)
| 2019真实值 | 2019预测值 | 2020真实值 | 2020预测值 | |
| 1月 | 57 | 67.4242 | 32 | 77.3402 |
| 2月 | 34 | 12.0256 | 14 | 26.9391 |
| 3月 | 164 | 193.7576 | 12 | 177.5304 |
| 4月 | 238 | 227.8908 | 17 | 162.9022 |
| 5月 | 976 | 977.4772 | 68 | 1143.6656 |
| 6月 | 612 | 702.357 | 174 | 692.6789 |
| 7月 | 1429 | 1361.6063 | 657 | 1855.8857 |
| 8月 | 1916 | 1841.384 | 765 | 2766.4673 |
| 9月 | 357 | 383.0164 | 127 | 477.9497 |
| 10月 | 1163 | 1088.7664 | 342 | 1764.9553 |
| 11月 | 206 | 299.5706 | 107 | 197.2131 |
| 12月 | 75 | 71.0087 | 63 | 46.2876 |
| 合计 | 7227 | 7226.2848 | 2378 | 9389.8151 |
问题一:
通过对2016、2017、2018年36个月份的数据进行训练得到的模型,模型损失函数loss: 5.3235e-7。
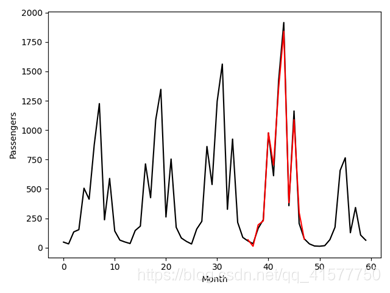
图3.1 2019年数据比对结果(红色为预测值,黑色为真实值)
预测结果如表3.1,2019年预测总人数为7226.2848万人,与真实值相差0.7152万人,真实值与测试值之间的标准差:Validation Score : 53.86 RMSE
测试值与真实值总人数相差不到1万人,各月人数差距不大,标准差较小,数据变化趋势与真实值变化趋势相符,预测效果非常好。
问题二:
通过对2016、2017、2018、2019年48个月份的数据进行训练得到的模型,模型损失函数loss: 1.3921e-4。
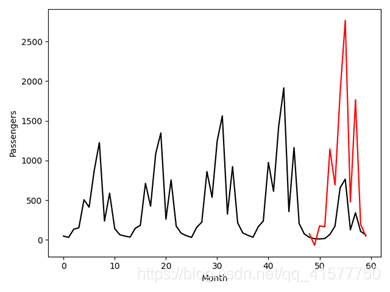
图3.2 2020年数据比对结果(红色为预测值,黑色为真实值)
预测结果如表3.1,2020年预测总人数为9389.8151万人,与真实值相差7011.8151万人,2020年实际旅游人数占预测人数的25.33%,即新冠疫情造成该市旅游人数减少了约74.67%。
3.3 解的现实意义
1. 帮助城市制定旅游发展计划,由历年统计数据可以看出旅游业发展迅速,在没有特殊情况的干扰下,每年游客数目逐年上升,政府应制定中长期旅游发展规划,合理引导促进旅游业的发展,为了适应旅游需求的不断增长,提高服务质量,旅游部门应相应加大在交通,环境改善等方面的投资力度及相互协作能力,同时,要加大对旅游资源的保护力度,防止旅游饱和和超载对环境设施的消极影响。
2. 由疫情的影响可以看出,突发事件对该城市旅游业影响巨大,政府在制定旅游发展规划过程中也应做好防护突发事件的措施和准备,将损失降到最小。有必要进一步完善各种重大突发事件的应急机制,使得旅游业在出现重大突发事件的年份中不至于出现滑坡
4 敏感性和稳健性分析
4.1 敏感性分析
由于数据预测过程中迭代次数足够高,损失函数值通常不大于0.0001,所以模型预测效果通常十分接近真实值,可以很好捕捉到历史数据中的数据变化趋势。因此模型对数据十分敏感。
4.2 稳健性分析
由于训练数据不够丰富,模型只适合近期数据预测,对于后一年的数据可以良好预测,如果对后几年的数据进行预测的话,仅靠近三四年的数据不能保证预测效果,单数如果能够提供更多的历年数据,可以预测更远。因此稳健性良好。
4.3 优缺性分析
优势:训练时间短,精度高,准确度高,易操作。
不足:由于预测过程中用到了之前预测的值而不是真实值,在预测月份过多的情况下容易出现偏差。但是在数据足够多的情况下可以避免这种状况。
5 结 论
通过对2016、2017、2018年36个月份的数据进行训练得到的模型,模型损失函数loss: 5.3235e-7。预测结果如表3.1,2019年预测总人数为7226.2848万人,与真实值相差0.7152万人,真实值与测试值之间的标准差:Validation Score : 53.86 RMSE。测试值与真实值总人数相差不到1万人,各月人数差距不大,标准差较小,数据变化趋势与真实值变化趋势相符,预测效果非常好。
通过对2016、2017、2018、2019年48个月份的数据进行训练得到的模型,模型损失函数loss: 1.3921e-4。预测结果如表3.1,2020年预测总人数为9389.8151万人,与真实值相差7011.8151万人,2020年实际旅游人数占预测人数的25.33%,即新冠疫情造成该市旅游人数减少了约74.67%。
参考文献
[1] 关于香港旅游需求的数学建模预测模型数学建模https://wenku.baidu.com/view/efbfb1acbdd126fff705cc1755270722192e59ef.html
[2] 杭州市未来旅游需求的预测(数学建模) https://wenku.baidu.com/view/9f57310d76c66137ee0619a3.html
[3] 国际旅行人数预测——使用LSTM https://blog.csdn.net/sun___m/article/details/83898522
[4] 【Keras】学习笔记18:LSTM时间序列问题预测:国际旅行人数预测
https://blog.csdn.net/qq_49189614/article/details/107767563
[5] 基于LSTM的时间序列数据(多步)预测https://www.jianshu.com/p/3b60cefa3109
[6] keras中使用LSTM实现一对多和多对多https://blog.csdn.net/chaofeili/article/details/89319410
[7] numpy的ndarray取数操作
https://blog.csdn.net/weixin_43251493/article/details/106157460
详细代码及数据:
github
https://github.com/YTIANYE/SMTL_ForecastNumberOfTourists
注意:两个分支代码不同,分别解决一个问题
数据
Month,Passengers
2016-01,47
2016-02,32
2016-03,134
2016-04,153
2016-05,506
2016-06,412
2016-07,876
2016-08,1226
2016-09,237
2016-10,589
2016-11,142
2016-12,64
2017-01,48
2017-02,35
2017-03,146
2017-04,183
2017-05,713
2017-06,425
2017-07,1087
2017-08,1347
2017-09,261
2017-10,754
2017-11,173
2017-12,82
2018-01,53
2018-02,31
2018-03,158
2018-04,224
2018-05,861
2018-06,537
2018-07,1246
2018-08,1562
2018-09,326
2018-10,924
2018-11,215
2018-12,87
2019-01,57
2019-02,34
2019-03,164
2019-04,238
2019-05,976
2019-06,612
2019-07,1429
2019-08,1916
2019-09,357
2019-10,1163
2019-11,206
2019-12,75
2020-01,32
2020-02,14
2020-03,12
2020-04,17
2020-05,68
2020-06,174
2020-07,657
2020-08,765
2020-09,127
2020-10,342
2020-11,107
2020-12,63实现代码
"""
LSTM时间序列问题预测:旅行人数预测
"""
import numpy as np
# import mxnet as mx
from matplotlib import pyplot as plt
from pandas import read_csv
import math
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error
seed = 7
batch_size = 1
epochs = 500
# filename = 'international-airline-passengers.csv'
filename = 'data_visitors.csv'
footer = 0
look_back = 12
predict_steps = 12
timesteps = 24 # 构造x,为72个数据,表示每次用前72个数据作为一段
def create_dataset(dataset):
# 创建数据集
dataX, dataY = [], []
# for i in range(len(dataset) - look_back - 1):
for i in range(len(dataset) - look_back):
x = dataset[i:i + look_back, 0]
dataX.append(x)
y = dataset[i + look_back, 0]
dataY.append(y)
# print('X: %s, Y: %s' % (x, y))
return np.array(dataX), np.array(dataY)
def build_model():
model = Sequential()
model.add(LSTM(units=4, input_shape=(1, look_back)))
# model.add(LSTM(units=4, input_shape=(look_back, 1)))
# model.add(Dense(units=12))
model.add(Dense(1))
# 均方误差,也称标准差,缩写为MSE,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率.
model.compile(loss='mean_squared_error', optimizer='adam')
return model
def train(trainsize,year):
# 设置随机种子
np.random.seed(seed)
# 导入数据
data = read_csv(filename, usecols=[1], engine='python', skipfooter=footer) # skipfooter=10 则最后10行不读取
dataset = data.values.astype('float32')
# 标准化数据
scaler = MinMaxScaler()
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * trainsize) # 训练集和验证集长度
validation_size = int(len(dataset) * 0.2)
train = dataset[0:train_size, :]
# validation = dataset[train_size - look_back:train_size + validation_size, :]
#### 循环测试
# 创建dataset,使数据产生相关性
X_train, y_train = create_dataset(train)
# 添加到循环
# X_validation, y_validation = create_dataset(validation)
# 将数据转换成[样本,时间步长,特征]的形式
X_train = np.reshape(X_train, (X_train.shape[0], 1, X_train.shape[1]))
# 添加到循环
# X_validation = np.reshape(X_validation, (X_validation.shape[0], 1, X_validation.shape[1]))
# 训练模型
model = build_model()
model.fit(X_train, y_train, epochs=epochs, batch_size=batch_size, verbose=2) # 通过设置详细0,1或2,您只需说明您希望如何“看到”每个时期的训练进度. verbose = 0会显示任何内容(无声) verbose = 1会显示一个动画进度条,如下所示: progres_bar verbose = 2只会提到这样的纪元数:
predict_xlist = dataset[train_size - look_back:train_size + validation_size, :] # 添加预测x列表
# predict_xlist = []
predict_y = [] # 添加预测y列表
predict_validation = [] #添加预测y列表
# predict_xlist.extend(train.tolist()) # 已经存在的最后timesteps个数据添加进列表,预测新值
while len(predict_y) < 12:
i = 0
# validation = np.array(predict_xlist[-timesteps:])
validation = predict_xlist[-timesteps:, :]
# 从最新的predict_xlist取出timesteps个数据,预测新的predict_steps个数据(因为每次预测的y会添加到predict_xlist列表中,为了预测将来的值,所以每次构造的x要取这个列表中最后的timesteps个数据词啊性)
# validation = dataset[train_size - look_back:train_size + validation_size, :]
X_validation, y_validation = create_dataset(validation)
X_validation = np.reshape(X_validation, (X_validation.shape[0], 1, X_validation.shape[1])) # 变换格式,适应LSTM模型
# 模型预测数据
predict_validation = model.predict(X_validation)
# predict_xlist.extend(predict_validation[0]) # 将新预测出来的predict_steps个数据,加入predict_xlist列表,用于下次预测
pre = predict_validation.astype('float32')# 12维
predict_xlist = np.concatenate((predict_xlist, pre), axis=0)
# np.concatenate((predict_xlist, pre))
# 反标准化数据,目的是为了保证MSE的准确性
predict_validation = scaler.inverse_transform(predict_validation) # 预测的 19年游客的数据值
y_validation = scaler.inverse_transform([y_validation])
predict_y.extend(predict_validation[0]) # 预测的结果y,每次预测的1个数据,添加进去,
#打印预测游客数量
# print(year + '年预测游客数量:')
# # print(predict_validation)
# print(predict_y)
####循环测试
# 评估模型
validation_score = math.sqrt(mean_squared_error(y_validation[0], predict_validation[:, 0]))
print('Validation Score : %.2f RMSE' % validation_score)
# 构建通过评估数据集进行预测的图表数据
predict_validation_plot = np.empty_like(dataset)
predict_validation_plot[:, :] = np.nan
predict_validation_plot[train_size + validation_size - len(predict_validation): train_size + validation_size, :] = predict_validation
# 图表显示
dataset = scaler.inverse_transform(dataset)
plt.xlabel('Month')
plt.ylabel('Passengers')
plt.plot(dataset, color='black')
plt.plot(predict_validation_plot, color='red')
plt.show()
return predict_validation
if __name__ == '__main__':
# train(0.6,'2019')
i = 0
while i < 6:
predict_validation = train(0.8,'2020')
print('########## 2020年预测游客数量:', i)
print(predict_validation)
i += 1

















 4813
4813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









