






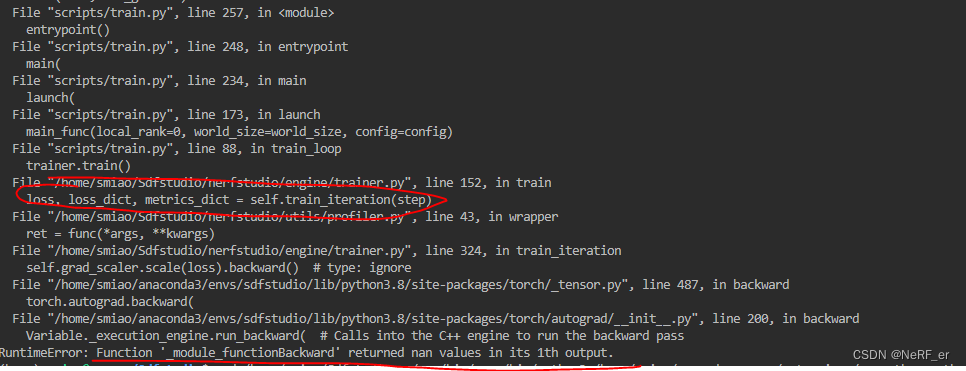
前向的时候不报错,但是在 反向BP 的时候报错,这类问题是很难解决的,目前解决了一些方案汇总如下:
1. 检测网络的结构参数是否合理,不能出现网络的层数 num_layers 过深的层。
之前 的错误是 背景 Nerfacto MLP的层数 设定为8, 导致会在BP 的时候报错。
2. Debug 的方法 可以使用 try 和 except 这样的函数
try:
self.grad_scaler.scale(loss).backward() # type: ignore
except:
## Save the checkpoint
保存在哪一个 step 会报错的checkpoint, 然后 尝试去 复现 这个错误,如果能复现这个 Bug, 然后去debug 会方便很多。
设置随机数的种子,保证结果是 可复现的。
seed = 0
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
2. Loss 过大,需要对 Loss multi 的系数进行 Review, 比如 语义前面的系数 一般是 0.01 如果给成 1 很容易出现BP 这样的错误。
loss_dict['semantics_loss'] = semantic_loss_mult * self.cross_entropy_loss(outputs["semantics"],batch['semantics'].squeeze(dim=-1))
注意前面需要乘以系数
3. 可能是学习率learning rate 的原因,在训练初期Spade CNN 的实验中,将learning rate 调小可以解决这个问题。
optimizers={
"voxel_encoder": {
"optimizer": AdamOptimizerConfig(lr=0.5*1e-2, eps=1e-15),
"scheduler": SchedulerConfig(lr_final=0.002, max_steps=30000),
},
"fields": {
"optimizer": AdamOptimizerConfig(lr=1e-3, eps=1e-15),
"scheduler": SchedulerConfig(lr_final=0.002, max_steps=30000),
},
"field_background": {
"optimizer": AdamOptimizerConfig(lr=0.5*1e-2, eps=1e-15),
# "scheduler": MultiStepSchedulerConfig(max_steps=30000),
"scheduler": SchedulerConfig(lr_final=0.002, max_steps=30000),
},
},
4. 可能是网络的结构设计不合理的原因,一般过深,超过4层的 MLP 最好跟上 Skip Connection 的设计,防止梯度消失或者爆炸的存在
在MVSNerf 中的 modulation MLP 中,一般超过了 6层的 MLP 最好都需要接上 Skip Connection 模块
4. 可能是Loss Function 设计不太合理导致的
在Urban Radiance Field 的Paper 里面,假设 Weight 的 曲线是 一个 Gaussion 分布函数, 但这其实并不是特别的 合理, Weight 的 分布不应该约束是哪一种分布,只保证其加和之后为1 就可以了。 尤其是 泛化训练的时候,需要训练很多的 Step 这种 报错更为常见。
















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









