







Github
Mask_RCNN-Master
Win10下手把手教你Mask R-CNN用自己的数据集训练(从labelme标记开始)
Labelme标注数据,使用Mask RCNN训练自己的数据集
1、搭建环境
1、参考要安装的库

numpy
scipy
Pillow
cython
matplotlib
scikit-image
tensorflow>=1.3.0
keras>=2.0.8
opencv-python
h5py
imgaug
IPython[all]
2、pip安装库
pip install scikit-image -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install h5py -i https://pypi.tuna.tsinghua.edu.cn/simple
3、安装Pycocotools,见博客Tensorflow object detection api(maskrcnn的搭建流程)
4、我的环境的库的版本
(tf1) D:\Pythonbase\Mask_RCNN>pip list
Package Version
----------------------------- ---------
absl-py 0.13.0
alabaster 0.7.12
appdirs 1.4.4
argon2-cffi 20.1.0
arrow 1.1.1
astor 0.8.1
astroid 2.6.5
async-generator 1.10
atomicwrites 1.4.0
attrs 21.2.0
autopep8 1.5.5
Babel 2.9.1
backcall 0.2.0
bcrypt 3.2.0
binaryornot 0.4.4
black 21.7b0
bleach 3.3.1
cached-property 1.5.2
certifi 2021.5.30
cffi 1.14.6
chardet 4.0.0
charset-normalizer 2.0.3
click 8.0.1
cloudpickle 1.6.0
colorama 0.4.4
cookiecutter 1.7.3
cryptography 3.4.7
cycler 0.10.0
Cython 0.29.24
dataclasses 0.8
decorator 4.4.2
defusedxml 0.7.1
diff-match-patch 20200713
docutils 0.17.1
easydict 1.9
entrypoints 0.3
flake8 3.8.4
gast 0.5.1
grpcio 1.39.0
h5py 2.10.0
idna 3.2
imageio 2.9.0
imagesize 1.2.0
imgaug 0.4.0
imgviz 1.2.6
importlib-metadata 4.6.1
inflection 0.5.1
intervaltree 3.1.0
ipykernel 5.5.5
ipython 7.16.1
ipython-genutils 0.2.0
ipywidgets 7.6.3
isort 5.9.3
jedi 0.17.2
Jinja2 3.0.1
jinja2-time 0.2.0
jsonschema 3.2.0
jupyter 1.0.0
jupyter-client 6.2.0
jupyter-console 6.4.0
jupyter-core 4.7.1
jupyterlab-pygments 0.1.2
jupyterlab-widgets 1.0.0
Keras 2.2.0
Keras-Applications 1.0.2
Keras-Preprocessing 1.0.1
keyring 23.0.1
kiwisolver 1.3.1
lazy-object-proxy 1.6.0
lxml 4.6.3
Markdown 3.3.4
MarkupSafe 2.0.1
matplotlib 3.2.2
mccabe 0.6.1
mistune 0.8.4
mypy-extensions 0.4.3
nbclient 0.5.3
nbconvert 6.0.7
nbformat 5.1.3
nest-asyncio 1.5.1
networkx 2.5.1
notebook 6.4.0
numpy 1.19.5
numpydoc 1.1.0
object-detection 0.1
opencv-python 4.5.3.56
packaging 21.0
pandas 1.1.5
pandocfilters 1.4.3
paramiko 2.7.2
parso 0.7.0
pathspec 0.9.0
pexpect 4.8.0
pickleshare 0.7.5
Pillow 8.3.1
pip 21.1.3
pluggy 0.13.1
poyo 0.5.0
prometheus-client 0.11.0
prompt-toolkit 3.0.19
protobuf 3.17.3
psutil 5.8.0
ptyprocess 0.7.0
pycodestyle 2.6.0
pycparser 2.20
pydocstyle 6.1.1
pyflakes 2.2.0
Pygments 2.9.0
pylint 2.9.6
pyls-black 0.4.7
pyls-spyder 0.3.2
PyNaCl 1.4.0
pyparsing 2.4.7
PyQt5 5.12.3
PyQt5-sip 12.9.0
PyQtWebEngine 5.12.1
pyrsistent 0.18.0
python-dateutil 2.8.2
python-jsonrpc-server 0.4.0
python-language-server 0.36.2
python-slugify 5.0.2
pytz 2021.1
PyWavelets 1.1.1
pywin32 301
pywin32-ctypes 0.2.0
pywinpty 1.1.3
PyYAML 5.4.1
pyzmq 22.1.0
QDarkStyle 3.0.2
qstylizer 0.2.0
QtAwesome 1.0.3
qtconsole 5.1.1
QtPy 1.9.0
regex 2021.7.6
requests 2.26.0
rope 0.19.0
Rtree 0.9.7
scikit-image 0.17.2
scipy 1.5.4
Send2Trash 1.7.1
setuptools 39.1.0
Shapely 1.7.1
six 1.16.0
slim 0.1
snowballstemmer 2.1.0
sortedcontainers 2.4.0
Sphinx 4.1.2
sphinxcontrib-applehelp 1.0.2
sphinxcontrib-devhelp 1.0.2
sphinxcontrib-htmlhelp 2.0.0
sphinxcontrib-jsmath 1.0.1
sphinxcontrib-qthelp 1.0.3
sphinxcontrib-serializinghtml 1.1.5
spyder-kernels 2.0.5
tensorboard 1.9.0
tensorflow-gpu 1.9.0
termcolor 1.1.0
terminado 0.10.1
testpath 0.5.0
text-unidecode 1.3
textdistance 4.2.1
three-merge 0.1.1
tifffile 2020.9.3
tinycss2 1.1.0
toml 0.10.2
tomli 1.1.0
tornado 6.1
traitlets 4.3.3
typed-ast 1.4.3
typing-extensions 3.10.0.0
ujson 4.0.2
urllib3 1.26.6
watchdog 2.1.3
wcwidth 0.2.5
webencodings 0.5.1
Werkzeug 2.0.1
wheel 0.36.2
widgetsnbextension 3.5.1
wincertstore 0.2
wrapt 1.12.1
yapf 0.31.0
zipp 3.5.0
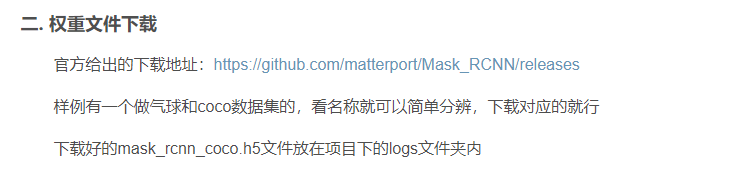
5、权重文件下载
官方给出的下载地址
我们将权重文件放到了路径下

6、测试demo



修改demo为test.py,代码如下
'''
Author: your name
Date: 2021-08-04 16:17:04
LastEditTime: 2021-08-04 16:44:31
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Mask_RCNN\samples\test.py
'''
''''''
#1、导入库包
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
# Root directory of the project
# ROOT_DIR=os.chdir(r"D:\Pythonbase\Mask_RCNN")
# os.getcwd()
ROOT_DIR = os.path.abspath("./")
print("ROOT_DIR",ROOT_DIR)
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
import coco
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
class InferenceConfig(coco.CocoConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
config = InferenceConfig()
config.display()
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(COCO_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['BG', 'person', 'bicycle', 'car', 'motorcycle', 'airplane',
'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird',
'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear',
'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie',
'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard',
'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup',
'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed',
'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote',
'keyboard', 'cell phone', 'microwave', 'oven', 'toaster',
'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors',
'teddy bear', 'hair drier', 'toothbrush']
# Load a random image from the images folder
file_names = next(os.walk(IMAGE_DIR))[2]
image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
# Run detection
results = model.detect([image], verbose=1)
# Visualize results
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])
2、创建自己的数据
1、获取样本数据
1、经过直接裁剪后的训练样本

2、对数据进行排序
'''
Author: your name
Date: 2021-08-17 16:52:21
LastEditTime: 2021-08-17 17:11:17
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Mask_RCNN\samples\Images\data_prepross\image_rename.py
'''
'''
此代码主要对图片进行排序
'''
import os
import shutil
from glob import glob
path=r"D:\Pythonbase\Mask_RCNN\samples\Images\Data\Images"
jpg_list = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
jpg_count=0
for file in jpg_list: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype=".tif"
Newdir=os.path.join(path,"厂房"+"_"+str(jpg_count).zfill(3)+filetype) #用字符串函数zfill 以0补全所需位数
print(Newdir)
os.rename(Olddir,Newdir)#重命名
jpg_count+=1
print("The renaming is complete!")
3、对影像数据进行样本标注
注意:1、CLASSNAMES一定要英文,否则会出现问题;
2、一开始我把图片里的每个同类物体都标注为了一个名称,比如多个厂房,都标注为了 “changfang”。在训练过程中,模型会把这多把厂房看作一个整体进行识别,而不是识别每个厂房,这就会造成显而易见的错误。最后右修改JSON的label,同类物体用“1”,“2”…区别,例如“changfang1",“changfang2"

# 批量文件转换,修改JSON文件的label名
labjsonpath=r"D:\Pythonbase\Mask_RCNN\samples\CFData\Data2\train\json"
file1names=os.listdir(labjsonpath)
for file in file1names:
filepath =labjsonpath +'/'+file
after = []
# 打开文件取出数据并修改,然后存入变量
with open(filepath, 'rb') as f:
data = json.load(f)
data_shapes=data["shapes"]
count=0
for item in data_shapes:
print(item['label'])
if item['label']=="changfang":
count=count+1
item['label']=item['label']+str(count)
after=data
with open(filepath, 'w') as f:
data = json.dump(after, f)
print("Finshed!")
2、创建train_data训练和test_data验证两个文件夹,并进行数据划分
1、创建如下几个文件夹
images为训练影像、json为Labelme标注的文件夹、label_json为转化数据集文件夹、cv2_mask为mask文件家s

2、images和json进行训练数据和测试数据的划分
'''
Author: your name
Date: 2021-08-17 17:13:38
LastEditTime: 2021-08-18 16:13:45
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Mask_RCNN\samples\Images\data_prepross\image_split.py
'''
# -*- coding: utf-8 -*-
# from __future__ import division, print_function, absolute_import
import sys
import shutil
import os
import random
import math
print(sys.path.append('../../'))
'''1、只做数据的train和eval的划分,eval数据集'''
def mkdir(path):
if not os.path.exists(path):
os.makedirs(path)
divide_rate = 0.8
root_path=r"D:\Pythonbase\Mask_RCNN\samples\Images\Data"
image_path = root_path + "/images/"
xml_path = root_path + "/json/"
def shuffle_images(image_path):
image_list = os.listdir(image_path)
print(len(image_list))
image_name = [n.split('.')[0] for n in image_list]
random.shuffle(image_name) #数据随机排序
train_images = image_name[:int(math.ceil(len(image_name)) * divide_rate)]
test_images = image_name[int(math.ceil(len(image_name)) * divide_rate):]
image_output_train = os.path.join(root_path, 'train') #训练数据集
mkdir(image_output_train)
image_output_test = os.path.join(root_path, 'val')#验证数据集
mkdir(image_output_test)
xml_train = os.path.join(root_path, 'train')
mkdir(xml_train)
xml_test = os.path.join(root_path, 'val')
mkdir(xml_test)
return train_images,test_images,image_output_train,image_output_test,xml_train, xml_test
def split_imgjson(train_images,test_images,image_output_train,image_output_test,xml_train, xml_test):
count = 0
for i in train_images:
shutil.copy(os.path.join(image_path, i + '.tif'), image_output_train)
shutil.copy(os.path.join(xml_path, i + '.json'), xml_train)
if count % 1000 == 0:
print("process step {}".format(count))
count += 1
for i in test_images:
shutil.copy(os.path.join(image_path, i + '.tif'), image_output_test)
shutil.copy(os.path.join(xml_path, i + '.json'), xml_test)
if count % 1000 == 0:
print("process step {}".format(count))
count += 1
'''2、做数据的train、eval和test的划分 '''
def shuffle_images_3(image_path):
image_list = os.listdir(image_path)
print(len(image_list))
image_name = [n.split('.')[0] for n in image_list]
random.shuffle(image_name) #数据随机排序
divide_rate1 = 0.6
divide_rate2 = 0.2
divide_rate3 = 0.2
n_train=int(math.ceil(len(image_name)) * divide_rate1)
n_val=int(math.ceil(len(image_name)) * divide_rate2)
train_images = image_name[:n_train]
val_images = image_name[n_train:n_train+n_val]
test_images = image_name[n_train+n_val:]
#print(len(train_image ))
#print(train_image)
#print(len(eval_image))
#print(len(test_image ))
image_output_train = os.path.join(root_path, 'train') #训练数据集
mkdir(image_output_train)
image_output_val = os.path.join(root_path, 'val')#验证数据集
mkdir(image_output_val)
image_output_test = os.path.join(root_path, 'test')#测试数据集
mkdir(image_output_test)
xml_train = os.path.join(root_path, 'train')
mkdir(xml_train)
xml_val = os.path.join(root_path, 'val')
mkdir(xml_val)
xml_test = os.path.join(root_path, 'test')
mkdir(xml_test)
return train_images,val_images,test_images,image_output_train,image_output_val,image_output_test,xml_train, xml_val,xml_test
def split_imgjson_3(train_images,val_images,test_images,image_output_train,image_output_val,image_output_test,xml_train, xml_val,xml_test):
count = 0
for i in train_images:
shutil.copy(os.path.join(image_path, i + '.jpg'), image_output_train)
shutil.copy(os.path.join(xml_path, i + '.json'), xml_train)
if count % 1000 == 0:
print("process step {}".format(count))
count += 1
for i in val_images:
shutil.copy(os.path.join(image_path, i + '.jpg'), image_output_val)
shutil.copy(os.path.join(xml_path, i + '.json'), xml_val)
if count % 1000 == 0:
print("process step {}".format(count))
count += 1
for i in test_images:
shutil.copy(os.path.join(image_path, i + '.jpg'), image_output_test)
shutil.copy(os.path.join(xml_path, i + '.json'), xml_test)
if count % 1000 == 0:
print("process step {}".format(count))
count += 1
if __name__ == '__main__':
#第一种
train_images,test_images,image_output_train,image_output_test,xml_train, xml_test=shuffle_images(image_path)
split_imgjson(train_images,test_images,image_output_train,image_output_test,xml_train, xml_test)
#第二种
train_images,val_images,test_images,image_output_train,image_output_val,image_output_test,xml_train, xml_val,xml_test=shuffle_images_3(image_path)
split_imgjson_3(train_images,val_images,test_images,image_output_train,image_output_val,image_output_test,xml_train, xml_val,xml_test)
3、Labelme标注数据和批量转换
conda create --name=labelme python=3.6
activate labelme
pip install pyside2
pip install pyqt5
# 不要装高版本的,原因后面讲
pip install labelme==3.16.2
首先将JSON文件统一放在一个新的文件夹里面,不能有其它格式的文件

'''
Author: your name
Date: 2021-08-03 19:04:25
LastEditTime: 2021-08-18 17:11:08
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Images\Batch_json_topng.py
'''
import os
import shutil
path = r'D:\Pythonbase\Mask_RCNN\samples\changfang\train_data\json' # path为json文件存放的路径
json_tomask_path=r"D:\Pythonbase\Mask_RCNN\samples\changfang\train_data\labelme_json"
def convert(path):
json_file=os.listdir(path)
for file in json_file:
os.system("python C:/Users/User/Anaconda3/envs/labelme/Scripts/labelme_json_to_dataset.exe %s"%(path + '/'+ file))
print("{} file was successfully converted!".format(file))
print("成功转换!")
def romve_result(path):
for root, dirs, files in os.walk(path):
for dir in dirs:
json_dirs=os.path.join(root,dir)
shutil.move(json_dirs, json_tomask_path)
if __name__ == '__main__':
convert(path)#进行转换
romve_result(path)#结果文件进行移动
进行调用

如下文件夹是我们转化的数据集

转化完成后移动到labelme_json文件夹下

内容结果如下

4、将转换后的mask移动到cv2_mask文件夹下
将上面的文件夹内的文件夹命名为移动到labelme_json文件夹内
如下是第二种Labelme批量转换2方法
cv2_mask存放特定物体对应特定颜色的8位彩色label.png图片,运行 label_png_move.py代码
'''
Author: your name
Date: 2021-08-04 18:22:00
LastEditTime: 2021-08-18 17:39:19
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Images\data_prepross\move_labelpng.py
'''
import os
import shutil
import sys
import re
spath=r'D:\Pythonbase\Mask_RCNN\samples\changfang\train_data\labelme_json'
tpath=r'D:\Pythonbase\Mask_RCNN\samples\changfang\train_data\cv2_mask'
sfolder=os.listdir(spath)
i=1
for tempfolder in sfolder:
temppath=os.path.join(spath,tempfolder)
flist=os.listdir(temppath)
if not 'label.png' in flist:
print('not find label.png in {}'.format(temppath))
continue
# 开始复制文件,注意这里不改变名字
# step 1 创建新的文件夹
shutil.copy(os.path.join(temppath,'label.png'),os.path.join(tpath,'{}.png'.format(tempfolder.replace("_json",""))))
结果如下

3、数据增强操作
3.1、等比率缩放
项目中要使用实例分割网络将图片中的目标分割出来,但是原图普遍非常大,大部分是 (5000pixels * 6000pixels) 这样的规格,如果直接传到网络中进行训练,计算量会非常大。所以考虑先离线resize好了之后作为数据集再训练网络,而不是在输入网络之间才resize(这样会很浪费时间)
import cv2
import os
import glob
import json
import collections
import numpy as np
from labelme import utils
if __name__ == "__main__":
src_dir = './srcDir'
dst_dir = './dstDir'
if not os.path.exists(dst_dir):
os.makedirs(dst_dir)
# 先收集一下文件夹中图片的格式列表,例如 ['.jpg', '.JPG']
exts = dict()
filesnames = os.listdir(src_dir)
for filename in filesnames:
name, ext = filename.split('.')
if ext != 'json':
if exts.__contains__(ext):
exts[ext] += 1
else:
exts[ext] = 1
anno = collections.OrderedDict() # 这个可以保证保存的字典顺序和读取出来的是一样的,直接使用dict()的话顺序会很乱(小细节哦)
for key in exts.keys():
for img_file in glob.glob(os.path.join(src_dir, '*.' + key)):
file_name = os.path.basename(img_file)
print(f"Processing {file_name}")
img = cv2.imread(img_file)
(h, w, c) = img.shape # 统计了一下,所有图片的宽度里面,1344是占比较多的宽度中最小的那个,因此
# 都等比例地将宽resize为1344(这里可以自己修改)
w_new = 1344
h_new = int(h / w * w_new) # 高度等比例缩放
ratio = w_new / w # 标注文件里的坐标乘以这个比例便可以得到新的坐标值
img_resize = cv2.resize(img, (w_new, h_new)) # resize中的目标尺寸参数为(width, height)
cv2.imwrite(os.path.join(dst_dir, file_name), img_resize)
# 接下来处理标注文件json中的标注点的resize
json_file = os.path.join(src_dir, file_name.split('.')[0] + '.json')
save_to = open(os.path.join(dst_dir, file_name.split('.')[0] + '.json'), 'w')
with open(json_file, 'rb') as f:
anno = json.load(f)
for shape in anno["shapes"]:
points = shape["points"]
points = (np.array(points) * ratio).astype(int).tolist()
shape["points"] = points
# 注意下面的img_resize编码加密之前要记得将通道顺序由BGR变回RGB
anno['imageData']=str(utils.img_arr_to_b64(img_resize[..., (2, 1, 0)]), encoding='utf-8')
json.dump(anno, save_to, indent=4)
print("Done")
3.2、 标注的训练数据集太少,利用已有的数据增强代码去增强原来的训练样本
# encoding='UTF-8'
# author: pureyang
# TIME: 2019/8/26 下午5:22
# Description:data augmentation for Object Segmentation
##############################################################
# 包括:
# 1. 改变亮度
# 2. 加噪声
# 3. 加随机点
# 4. 图像模糊
# 5. 镜像(需要改变points)
# 6. 做旋转(对图像和关键节点)
# 7. 等比例缩放图像和关键点
import time
import random
import cv2
import os
import numpy as np
from skimage.util import random_noise
import base64
import json
import re
from copy import deepcopy
import argparse
import imageio
import imgaug as ia
from imgaug import augmenters as iaa
from imgaug.augmentables.bbs import BoundingBox, BoundingBoxesOnImage
from imgaug.augmentables import Keypoint, KeypointsOnImage
# 图像均为cv2读取
class DataAugmentForObjectDetection():
def __init__(self, change_light_rate=0.5,
add_noise_rate=0.5, random_point=0.5, blur_pic_rate=0.5 ,flip_rate=0.5, shift_rate=0.5, rand_point_percent=0.03,rotate_pic_keypoints_rate=0.5,
resize_pic_points_rate=1,is_addNoise=True, is_changeLight=True, is_random_point=True,is_blur_pic=True, is_shift_pic_bboxes=True,
is_filp_pic_bboxes=True,is_rotate_pic_keypoints=True,is_resize_pic_points=False):
# 配置各个操作的属性
self.change_light_rate = change_light_rate
self.add_noise_rate = add_noise_rate
self.random_point = random_point
self.blur_pic_rate = blur_pic_rate
self.flip_rate = flip_rate
self.shift_rate = shift_rate
self.rand_point_percent = rand_point_percent
self.rotate_pic_keypoints_rate = rotate_pic_keypoints_rate
self.resize_pic_points_rate = resize_pic_points_rate
# 是否使用某种增强方式
self.is_addNoise = is_addNoise
self.is_changeLight = is_changeLight
self.is_random_point = is_random_point
self.is_blur_pic = is_blur_pic
self.is_filp_pic_bboxes = is_filp_pic_bboxes
self.is_shift_pic_bboxes = is_shift_pic_bboxes
self.is_rotate_pic_keypoints = is_rotate_pic_keypoints
self.is_resize_pic_points = is_resize_pic_points
# 加噪声
def _addNoise(self, img):
return random_noise(img, seed=int(time.time())) * 255
# 调整亮度
def _changeLight(self, img):
alpha = random.uniform(0.35, 1)
blank = np.zeros(img.shape, img.dtype)
return cv2.addWeighted(img, alpha, blank, 1 - alpha, 0)
# 随机的改变点的值
def _addRandPoint(self, img):
percent = self.rand_point_percent
num = int(percent * img.shape[0] * img.shape[1])
for i in range(num):
rand_x = random.randint(0, img.shape[0] - 1)
rand_y = random.randint(0, img.shape[1] - 1)
if random.randint(0, 1) == 0:
img[rand_x, rand_y] = 0
else:
img[rand_x, rand_y] = 255
return img
# 模糊图像
def _blur_pic(self,img):
seq = iaa.Sequential([iaa.OneOf([
iaa.GaussianBlur((0, 3.0)), # 高斯模糊
iaa.AverageBlur(k=(2, 7)), # 均值模糊
iaa.MedianBlur(k=(3, 11))])]) # 中值模糊
img = seq(images=img)
return img
# 平移
def _shift_pic_bboxes(self, img, json_info):
# ---------------------- 平移图像 ----------------------
h, w, _ = img.shape
x_min = w
x_max = 0
y_min = h
y_max = 0
shapes = json_info['shapes']
for shape in shapes:
points = np.array(shape['points'])
x_min = min(x_min, points[:, 0].min())
y_min = min(y_min, points[:, 1].min())
x_max = max(x_max, points[:, 0].max())
y_max = max(y_max, points[:, 0].max())
d_to_left = x_min # 包含所有目标框的最大左移动距离
d_to_right = w - x_max # 包含所有目标框的最大右移动距离
d_to_top = y_min # 包含所有目标框的最大上移动距离
d_to_bottom = h - y_max # 包含所有目标框的最大下移动距离
x = random.uniform(-(d_to_left - 1) / 3, (d_to_right - 1) / 3)
y = random.uniform(-(d_to_top - 1) / 3, (d_to_bottom - 1) / 3)
M = np.float32([[1, 0, x], [0, 1, y]]) # x为向左或右移动的像素值,正为向右负为向左; y为向上或者向下移动的像素值,正为向下负为向上
shift_img = cv2.warpAffine(img, M, (img.shape[1], img.shape[0]))
# ---------------------- 平移boundingbox ----------------------
for shape in shapes:
for p in shape['points']:
p[0] += x
p[1] += y
return shift_img, json_info
# 镜像
def _filp_pic_bboxes(self, img, json_info):
# ---------------------- 翻转图像 ----------------------
h, w, _ = img.shape
sed = random.random()
if 0 < sed < 0.33: # 0.33的概率水平翻转,0.33的概率垂直翻转,0.33是对角反转
flip_img = cv2.flip(img, 0) # _flip_x
inver = 0
elif 0.33 < sed < 0.66:
flip_img = cv2.flip(img, 1) # _flip_y
inver = 1
else:
flip_img = cv2.flip(img, -1) # flip_x_y
inver = -1
# ---------------------- 调整boundingbox ----------------------
shapes = json_info['shapes']
for shape in shapes:
for p in shape['points']:
if inver == 0:
p[1] = h - p[1]
elif inver == 1:
p[0] = w - p[0]
elif inver == -1:
p[0] = w - p[0]
p[1] = h - p[1]
return flip_img, json_info
# 旋转图像
def _rotate_pic_keypoints(self, img, json_info):
# ---------------------- 旋转图像和标注文件 ----------------------
sed = np.random.random()
shapes = json_info['shapes']
if sed <= 0.3:
for shape in shapes:
Keypointlist = []
for p in shape['points']:
x = p[0]
y = p[1]
Keypointlist.append(Keypoint(x=x, y=y))
kps = KeypointsOnImage(Keypointlist, shape=img.shape) # json的节点
seq = iaa.Sequential([iaa.Affine(rotate=[45])])
# Augment keypoints and images.
image_aug, kps_aug = seq(image=img, keypoints=kps)
# image_before = ia.imshow(kps.draw_on_image(img, size=7))
# image_after = ia.imshow(kps_aug.draw_on_image(image_aug, size=7))
kps_aug = kps_aug.to_xy_array().tolist()
shape['points'] = kps_aug
elif 0.3 < sed <= 0.5:
for shape in shapes:
Keypointlist = []
for p in shape['points']:
x = p[0]
y = p[1]
Keypointlist.append(Keypoint(x=x, y=y))
kps = KeypointsOnImage(Keypointlist, shape=img.shape) # json的节点
seq = iaa.Sequential([iaa.Affine(rotate=[90])])
# Augment keypoints and images.
image_aug, kps_aug = seq(image=img, keypoints=kps)
# image_before = ia.imshow(kps.draw_on_image(img, size=7))
# image_after = ia.imshow(kps_aug.draw_on_image(image_aug, size=7))
kps_aug = kps_aug.to_xy_array().tolist()
shape['points'] = kps_aug
else:
for shape in shapes:
Keypointlist = []
for p in shape['points']:
x = p[0]
y = p[1]
Keypointlist.append(Keypoint(x=x, y=y))
kps = KeypointsOnImage(Keypointlist, shape=img.shape) # json的节点
seq = iaa.Sequential([iaa.Affine(rotate=[270])])
# Augment keypoints and images.
image_aug, kps_aug = seq(image=img, keypoints=kps)
# image_before = ia.imshow(kps.draw_on_image(img, size=7))
# image_after = ia.imshow(kps_aug.draw_on_image(image_aug, size=7))
kps_aug = kps_aug.to_xy_array().tolist()
shape['points'] = kps_aug
return image_aug, json_info
# 等比例缩放
def _resize_pic_points(self, img, json_info):
shapes = json_info['shapes']
for shape in shapes:
Keypointlist = []
for p in shape['points']:
print("p", p)
x = p[0]
y = p[1]
Keypointlist.append(Keypoint(x=x, y=y))
kps = KeypointsOnImage(Keypointlist, shape=img.shape) # json的节点
# Augment keypoints and images.
image_aug = ia.imresize_single_image(img, (512, 512))
kps_aug = kps.on(image_aug)
# image_before = ia.imshow(kps.draw_on_image(img, size=7))
image_after = ia.imshow(kps_aug.draw_on_image(image_aug, size=7))
kps_aug = kps_aug.to_xy_array().tolist()
shape['points'] = kps_aug
return image_aug, json_info
# 图像增强方法
def dataAugment(self, img, dic_info):
change_num = 0 # 改变的次数
while change_num < 1: # 默认至少有一种数据增强生效
if self.is_changeLight:
if random.random() > self.change_light_rate: # 改变亮度
change_num += 1
img = self._changeLight(img)
if self.is_addNoise:
if random.random() < self.add_noise_rate: # 加噪声
change_num += 1
img = self._addNoise(img)
if self.is_random_point:
if random.random() < self.random_point: # 加随机点
change_num += 1
img = self._addRandPoint(img)
# if self.is_blur_pic:
# if random.random() < self.blur_pic_rate: # 加模糊
# change_num += 1
# img = self._blur_pic(img)
if self.is_shift_pic_bboxes:
if random.random() < self.shift_rate: # 平移
change_num += 1
img, json_info = self._shift_pic_bboxes(img, dic_info)
if self.is_rotate_pic_keypoints:
if random.random() < self.rotate_pic_keypoints_rate: # 旋转
change_num += 1
img, dic_info = self._rotate_pic_keypoints(img, dic_info)
if self.is_filp_pic_bboxes or 1:
if random.random() < self.flip_rate: # 翻转
change_num += 1
img, json_info = self._filp_pic_bboxes(img, dic_info)
if self.is_resize_pic_points:
if random.random() < self.resize_pic_points_rate:
change_num += 1
img, json_info = self.is_resize_pic_points(img, dic_info)
return img, dic_info
# xml解析工具
class ToolHelper():
# 从json文件中提取原始标定的信息
def parse_json(self, path):
with open(path)as f:
json_data = json.load(f)
return json_data
# 对图片进行字符编码
def img2str(self, img_name):
with open(img_name, "rb")as f:
base64_data = str(base64.b64encode(f.read()))
match_pattern = re.compile(r'b\'(.*)\'')
base64_data = match_pattern.match(base64_data).group(1)
return base64_data
# 保存图片结果
def save_img(self, save_path, img):
# cv2.imwrite(save_path, img)
imageio.imwrite(save_path, img)
# 保持json结果
def save_json(self, file_name, save_folder, dic_info):
with open(os.path.join(save_folder, file_name), 'w') as f:
json.dump(dic_info, f, indent=2)
if __name__ == '__main__':
need_aug_num = 6 # 每张图片需要增强的次数
toolhelper = ToolHelper() # 工具
is_endwidth_dot = True # 文件是否以.jpg或者png结尾
dataAug = DataAugmentForObjectDetection() # 数据增强工具类
# 获取相关参数
parser = argparse.ArgumentParser() # 创建参数对象
parser.add_argument('--source_img_json_path', type=str, default='data') # 添加参数--source_img_json_path
parser.add_argument('--save_img_json_path', type=str, default='data2') # 添加参数--save_img_json_path
args = parser.parse_args()
source_img_json_path = args.source_img_json_path # 图片和json文件原始位置
save_img_json_path = args.save_img_json_path # 图片增强结果保存文件
# 如果保存文件夹不存在就创建
if not os.path.exists(save_img_json_path):
os.mkdir(save_img_json_path)
for parent, _, files in os.walk(source_img_json_path):
files.sort() # 排序一下
for file in files:
if file.endswith('jpg') or file.endswith('png'):
cnt = 0
pic_path = os.path.join(parent, file)
json_path = os.path.join(parent, file[:-4] + '.json')
json_dic = toolhelper.parse_json(json_path)
# 如果图片是有后缀的
if is_endwidth_dot:
# 找到文件的最后名字
dot_index = file.rfind('.')
_file_prefix = file[:dot_index] # 文件名的前缀
_file_suffix = file[dot_index:] # 文件名的后缀
# img = cv2.imread(pic_path)
img = imageio.imread(pic_path)
while cnt < need_aug_num: # 继续增强
auged_img, json_info = dataAug.dataAugment(deepcopy(img), deepcopy(json_dic))
img_name = '{}_{}{}'.format(_file_prefix, cnt + 1, _file_suffix) # 图片保存的信息
img_save_path = os.path.join(save_img_json_path, img_name)
toolhelper.save_img(img_save_path, auged_img) # 保存增强图片
json_info['imagePath'] = img_name
base64_data = toolhelper.img2str(img_save_path)
json_info['imageData'] = base64_data
toolhelper.save_json('{}_{}.json'.format(_file_prefix, cnt + 1),
save_img_json_path, json_info) # 保存xml文件
print(img_name)
cnt += 1 # 继续增强下一张
产生的文件数据,后续需要进行排序重名名操作

然后对增强的结果重新排序:
'''
Author: your name
Date: 2021-09-01 11:32:20
LastEditTime: 2021-09-01 19:17:19
LastEditors: Please set LastEditors
Description: In User Settings Edit
FilePath: \Mask_RCNN\samples\data_prepross\jmage_json_rename.py
'''
import json
import os
import imageio
import base64
import re
# xml解析工具
class ToolHelper():
# 从json文件中提取原始标定的信息
def parse_json(self, path):
with open(path)as f:
json_data = json.load(f)
return json_data
# 对图片进行字符编码
def img2str(self, img_name):
with open(img_name, "rb")as f:
base64_data = str(base64.b64encode(f.read()))
match_pattern = re.compile(r'b\'(.*)\'')
base64_data = match_pattern.match(base64_data).group(1)
return base64_data
# 保存图片结果
def save_img(self, save_path, img):
# cv2.imwrite(save_path, img)
imageio.imwrite(save_path, img)
# 保持json结果
def save_json(self, file_name, save_folder, dic_info):
with open(os.path.join(save_folder, file_name), 'w') as f:
json.dump(dic_info, f, indent=2)
if __name__ == '__main__':
# input_img_json_path=r"D:\Pythonbase\Mask_RCNN\samples\data_prepross\Images"
# output_img_json_path="D:\Pythonbase\Mask_RCNN\samples\data_prepross\Imagesout"
# input_img_json_path=r"D:\Pythonbase\Mask_RCNN\samples\data_prepross\images512"
# output_img_json_path="D:\Pythonbase\Mask_RCNN\samples\data_prepross\images512out"
input_img_json_path=r"D:\Pythonbase\Mask_RCNN\samples\data_prepross\imagesall"
output_img_json_path="D:\Pythonbase\Mask_RCNN\samples\data_prepross\Imagesallout"
# 如果保存文件夹不存在就创建
if not os.path.exists(output_img_json_path):
os.mkdir(output_img_json_path)
toolhelper = ToolHelper() # 工具
for parent, _, files in os.walk(input_img_json_path):
files.sort() # 排序一下
cnt = 0
for file in files:
if file.endswith('jpg') or file.endswith('png'):
pic_path = os.path.join(parent, file)
json_path = os.path.join(parent, file[:-4] + '.json')
json_dic = toolhelper.parse_json(json_path)
img = imageio.imread(pic_path)
filetype=".png"
img_name = '{}_{}{}'.format("changfang", str(cnt).zfill(4),filetype) # 图片保存的信息
print(img_name)
img_save_path = os.path.join(output_img_json_path, img_name)
toolhelper.save_img(img_save_path, img) # 保存增强图片
json_dic ['imagePath'] = img_name
base64_data = toolhelper.img2str(img_save_path)
json_dic['imageData'] = base64_data
json_dic['imageHeight'] = 512
json_dic['imageWidth'] = 512
toolhelper.save_json('{}_{}.json'.format("changfang", str(cnt).zfill(4)),
output_img_json_path, json_dic) # 保存xml文件
cnt += 1 # 继续下一张
print("The image and json renaming is complete!")
3.3 、MASKRCNN的nucleus的数据增强示例,问题是不是到增强的结果怎么和原来的训练数据合并到dataset一起进入训练网络

4、数据训练
4.1、注意的问题
如果你不想测试coco里默认的81类,只想测试2类,那一定记住要把model.load_weights(COCO_MODEL_PATH, by_name=True)改为model.load_weights(COCO_MODEL_PATH, by_name=True, exclude=["mrcnn_class_logits", "mrcnn_bbox_fc","mrcnn_bbox", "mrcnn_mask"])
4.2、训练CPU或者GPU的设置




4.3、测试结果的评估

4.2、训练代码
# -*- coding: utf-8 -*-
import os
import sys
import random
import math
import re
import time
import numpy as np
import cv2
import matplotlib
import matplotlib.pyplot as plt
import tensorflow as tf
from mrcnn.config import Config
from mrcnn import model as modellib,utils
from mrcnn import visualize
import yaml
from mrcnn.model import log
from PIL import Image
import warnings
warnings.filterwarnings('ignore')
#os.environ["CUDA_VISIBLE_DEVICES"] = "0"
# Root directory of the project,程序的主路径,#ROOT_DIR = os.path.abspath("../")
ROOT_DIR = os.getcwd()
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
iter_num=0
# Local path to trained weights file
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name,指定配置的名字,可以根据识别的目标进行命名
NAME = "changfang"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1 #GPU的个数
IMAGES_PER_GPU = 1 #每块GPU的影像数据,batch size
# Number of classes (including background),识别目标数量,包括背景为其中一类
NUM_CLASSES = 1 + 1 # background + 3 shapes
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.定义图象尺寸,以IMAGE_MAX_DIM为主
IMAGE_MIN_DIM = 512
IMAGE_MAX_DIM = 512
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (8 * 6, 16 * 6, 32 * 6, 64 * 6, 128 * 6) # anchor side in pixels
# RPN_ANCHOR_SCALES = (32, 64, 128, 256, 512)
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.# 每个图像的ROI数量
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple,# epoch:每个时期的训练步数,不需要与训练集一致,每个人时期(epoch)未保存的Tensorboard以及计算验证统计信息
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small, # 每个训练时期结束时运行的验证数,较大的数字可以提高验证统计数据的准确性,但会降低训练速度
# VALIDATION_STEPS = 50
VALIDATION_STEPS = 5
class DrugDataset(utils.Dataset):
# 得到该图中有多少个实例(物体)
def get_obj_index(self, image):
n = np.max(image)
return n
# 解析labelme中得到的yaml文件,从而得到mask每一层对应的实例标签
def from_yaml_get_class(self, image_id):
info = self.image_info[image_id]
with open(info['yaml_path']) as f:
temp = yaml.load(f.read(),Loader=yaml.FullLoader)
labels = temp['label_names']
del labels[0] #去除背景后的类别
return labels
# 重新写draw_mask
def draw_mask(self, num_obj, mask, image,image_id):
#print("draw_mask-->",image_id)
#print("self.image_info",self.image_info)
info = self.image_info[image_id]
#print("info-->",info)
#print("info[width]----->",info['width'],"-info[height]--->",info['height'])
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
#print("image_id-->",image_id,"-i--->",i,"-j--->",j)
#print("info[width]----->",info['width'],"-info[height]--->",info['height'])
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
return mask
# 重新写load_shapes,里面包含自己的自己的类别
# 并在self.image_info信息中添加了path、mask_path 、yaml_path
# yaml_pathdataset_root_path = "/tongue_dateset/"
# img_floder = dataset_root_path + "rgb"
# mask_floder = dataset_root_path + "mask"
# dataset_root_path = "/tongue_dateset/"
def load_shapes(self, count, img_floder, mask_floder, imglist, dataset_root_path):
"""Generate the requested number of synthetic images.
count: number of images to generate.
height, width: the size of the generated images.
"""
# Add classes
self.add_class("shapes", 1, "changfang")
for i in range(count):
# 获取图片宽和高
filestr = imglist[i].split(".")[0]
#print(imglist[i],"-->",cv_img.shape[1],"--->",cv_img.shape[0])
#print("id-->", i, " imglist[", i, "]-->", imglist[i],"filestr-->",filestr)
# filestr = filestr.split("_")[1]
mask_path = mask_floder + "/" + filestr + ".png"
yaml_path = dataset_root_path + "labelme_json/" + filestr + "_json/info.yaml"
cv_img = cv2.imread(dataset_root_path + "labelme_json/" + filestr + "_json/img.png")
self.add_image("shapes", image_id=i, path=img_floder + "/" + imglist[i],
width=cv_img.shape[1], height=cv_img.shape[0], mask_path=mask_path, yaml_path=yaml_path)
# 重写load_mask
def load_mask(self, image_id):
"""Generate instance masks for shapes of the given image ID.
"""
global iter_num
print("image_id",image_id)
info = self.image_info[image_id]
count = 1 # number of object
img = Image.open(info['mask_path'])
num_obj = self.get_obj_index(img)
mask = np.zeros([info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img,image_id)
occlusion = np.logical_not(mask[:, :, -1]).astype(np.uint8)
for i in range(count - 2, -1, -1):
mask[:, :, i] = mask[:, :, i] * occlusion
occlusion = np.logical_and(occlusion, np.logical_not(mask[:, :, i]))
labels = []
labels = self.from_yaml_get_class(image_id)
labels_form = []
for i in range(len(labels)):
if labels[i].find("changfang") != -1:
# print "car"
labels_form.append("changfang")
# elif labels[i].find("leg") != -1:
# # print "leg"
# labels_form.append("leg")
# elif labels[i].find("well") != -1:
# # print "well"
# labels_form.append("well")
class_ids = np.array([self.class_names.index(s) for s in labels_form])
return mask, class_ids.astype(np.int32)
def get_ax(rows=1, cols=1, size=8):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Change the default size attribute to control the size
of rendered images
"""
_, ax = plt.subplots(rows, cols, figsize=(size * cols, size * rows))
return ax
if __name__ == "__main__":
#1、训练和验证数据集的基础设置
dataset_root_path="D:/Pythonbase/Mask_RCNN/samples/changfang/"
img_floder = dataset_root_path + "images"
mask_floder = dataset_root_path + "cv2_mask"
imglist = os.listdir(img_floder)
count = len(imglist)
#train与val数据集准备
dataset_train = DrugDataset()
dataset_train.load_shapes(count, img_floder, mask_floder, imglist,dataset_root_path)#加载训练数据
dataset_train.prepare()
#print("dataset_train-->",dataset_train._image_ids)
dataset_val = DrugDataset()
dataset_val.load_shapes(40, img_floder, mask_floder, imglist,dataset_root_path)
dataset_val.prepare()
#print("dataset_val-->",dataset_val._image_ids)
# 2、随机的显示训练数据集中的样本标注信息Load and display random samples
image_ids = np.random.choice(dataset_train.image_ids, 4)
for image_id in image_ids:
image = dataset_train.load_image(image_id)
mask, class_ids = dataset_train.load_mask(image_id)
visualize.display_top_masks(image, mask, class_ids, dataset_train.class_names)
# ## 加入训练集
# dataset_root_path="C:/Tensorflow/Mask_RCNN/dataset/train"
# img_floder = dataset_root_path+"pic"
# mask_floder = dataset_root_path+"mask"
# imglist = os.listdir(img_floder) #获取图片文件名list
# count = len(imglist)
# dataset_train = BoxDataset()
# dataset_train.load_shapes(count, 1000, 1000, img_floder, mask_floder, imglist,dataset_root_path)
# dataset_train.prepare()
# # 加入验证集
# dataset_root_path_val="C:/Tensorflow/Mask_RCNN/dataset/Val/"
# img_floder_val = dataset_root_path_val+"pic"
# mask_floder_val = dataset_root_path_val+"mask"
# imglist_val = os.listdir(img_floder_val)
# count_val = len(imglist_val)
# dataset_val = BoxDataset()
# dataset_val.load_shapes(count_val, 1000, 1000, img_floder_val, mask_floder_val, imglist_val,dataset_root_path_val)
# dataset_val.prepare()
#3、设置配置参数
config = ShapesConfig()
config.display()#加载训练的配置信息
#4、创建Mask RCNN模型,模型保存到logs中。 Create model in training mode
model = modellib.MaskRCNN(mode="training", config=config,
model_dir=MODEL_DIR)
# Which weights to start with?
init_with = "coco" # imagenet, coco, or last
if init_with == "imagenet":
model.load_weights(model.get_imagenet_weights(), by_name=True)
elif init_with == "coco":
# Load weights trained on MS COCO, but skip layers that
# are different due to the different number of classes
# See README for instructions to download the COCO weights
# print(COCO_MODEL_PATH)
model.load_weights(COCO_MODEL_PATH, by_name=True,
exclude=["mrcnn_class_logits", "mrcnn_bbox_fc",
"mrcnn_bbox", "mrcnn_mask"])#加载预训练模型的权重
elif init_with == "last":
# Load the last model you trained and continue training
model.load_weights(model.find_last()[1], by_name=True)
#5、开始训练模型
# Train the head branches
# Passing layers="heads" freezes all layers except the head
# layers. You can also pass a regular expression to select
# which layers to train by name pattern.
'''
只有正面。在这里,我们冻结所有的骨干层,只训练随机初始化的层(即那些我们没有使用MS COCO预先训练的重量)。
为了只训练头部层,将layers='heads'传递给train()函数。
'''
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE,
epochs=10,
layers='heads')
# Fine tune all layers
# Passing layers="all" trains all layers. You can also
# pass a regular expression to select which layers to
# train by name pattern.
model.train(dataset_train, dataset_val,
learning_rate=config.LEARNING_RATE / 10,
epochs=200,
layers="all")#设置学习率,训练的周期,训练的模型网络层
#6、加载训练好的测试模型
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
inference_config = InferenceConfig()
model = modellib.MaskRCNN(mode="inference",
config=inference_config,
model_dir=MODEL_DIR)
model_path = model.find_last()
# Load trained weights
print("Loading weights from ", model_path)
model.load_weights(model_path, by_name=True)
#7、# 随机的测试一张影像,Test on a random image
image_id = random.choice(dataset_val.image_ids)
original_image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset_val, inference_config,
image_id, use_mini_mask=False)
log("original_image", original_image)
log("image_meta", image_meta)
log("gt_class_id", gt_class_id)
log("gt_bbox", gt_bbox)
log("gt_mask", gt_mask)
visualize.display_instances(original_image, gt_bbox, gt_mask, gt_class_id,
dataset_train.class_names, figsize=(8, 8))
results = model.detect([original_image], verbose=1)
r = results[0]
visualize.display_instances(original_image, r['rois'], r['masks'], r['class_ids'],
dataset_val.class_names, r['scores'], ax=get_ax())
# 8、对模型进行评估,Compute VOC-Style mAP @ IoU=0.5
# Running on 10 images. Increase for better accuracy.
image_ids = np.random.choice(dataset_val.image_ids, 20)#随机的从验证数据集里面选20张图片
APs = []
for image_id in image_ids:
# Load image and ground truth data,
image, image_meta, gt_class_id, gt_bbox, gt_mask = modellib.load_image_gt(dataset_val, config,
image_id, use_mini_mask=False)#验证数据集的标注掩膜信息
masked_imageL=visualize.display_instances(image, gt_bbox, gt_mask, gt_class_id, dataset_val.class_names, figsize=(8, 8))
molded_images = np.expand_dims(modellib.mold_image(image, config), 0)
# Run object detection
results = model.detect([image], verbose=0)
r = results[0]
#Load detection image
masked_imageD=visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
dataset_val.class_names, r['scores'])
plt.savefig(r"./out/%s" % ( masked_imageL), dpi=96.0, pad_inches=0.0)
cv2.imwrite("./test_results/%s"%(masked_imageD), masked_imageL)
# Compute AP
AP, precisions, recalls, overlaps = utils.compute_ap(gt_bbox, gt_class_id, gt_mask,
r["rois"], r["class_ids"], r["scores"], r['masks'])
APs.append(AP)
print("厂房模型的评估mAP为: ", np.mean(APs))
5、测试数据
#1、导入库包
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
import cv2
# Root directory of the project
ROOT_DIR = os.path.abspath("../")
# print("ROOT_DIR",ROOT_DIR)
# Import Mask RCNN
sys.path.append(ROOT_DIR) # To find local version of the library
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
from mrcnn.config import Config
# sys.path.append(os.path.join(ROOT_DIR, "samples/coco/")) # To find local version
# import coco
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
# Local path to trained weights file
changfang_MODEL_PATH = os.path.join(MODEL_DIR, "")
# # Download COCO trained weights from Releases if needed
# if not os.path.exists(COCO_MODEL_PATH):
# utils.download_trained_weights(COCO_MODEL_PATH)
#1、设置配置文件,测试代码的配置文件尽量与训练的配置参数一致
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable 为配置指定一个可识别的名称
NAME = "changfang"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 3 shapes 检测的目标类别数,包括背景和检测目标
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.(512,832),(1088,1152)
IMAGE_MIN_DIM = 512
IMAGE_MAX_DIM = 512
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (32, 64, 128, 256, 512) # anchor side in pixels
# RPN_ANCHOR_SCALES = (8, 16, 32, 64, 128) # anchor side in pixels
RPN_ANCHOR_SCALES = (8 * 6, 16 * 6, 32 * 6, 64 * 6, 128 * 6) # anchor side in pixels
RPN_ANCHOR_RATIOS = [0.5, 1, 2]
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 32
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 100
# use small validation steps since the epoch is small
VALIDATION_STEPS = 5
class InferenceConfig(ShapesConfig):
GPU_COUNT = 1
IMAGES_PER_GPU = 1
if __name__ == "__main__":
#1、设置配置文件
config = InferenceConfig()
config.display()
# 2、测试图片的路径, Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
#3、加载测试模型 Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=changfang_MODEL_PATH , config=config)
model_path = model.find_last() # 使用最近新的.h权重文件
print("训练模型的路径:", model_path)
# 4、加载测试模型的权重,Load trained weights
model.load_weights(model_path, by_name=True,exclude=["mrcnn_class_logits", "mrcnn_bbox_fc","mrcnn_bbox", "mrcnn_mask"])
#5、加载类型
class_names = ['background','changfang']
# Load a random image from the images folder
#6、测试单张图片
file_names = next(os.walk(IMAGE_DIR))[2]
# image = skimage.io.imread(os.path.join(IMAGE_DIR, random.choice(file_names)))
image = skimage.io.imread(os.path.join(IMAGE_DIR +'/' + 'changfang_115.png'))
# 7、对测试图片进行测试,Run detection
results = model.detect([image], verbose=1)
# 8、显示测试结果, Visualize results
r = results[0]
masked_imageL=visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
class_names, r['scores'])
#2、测试多张检测图片路径
testpath =os.path.join(ROOT_DIR, "testcf")
testlist = os.listdir(testpath)
testlist.sort()
for image_id in testlist:
demoimg = testpath+"/"+image_id
image =skimage.io.imread(demoimg) # 读取图像skimage.io.imread
result = model.detect([image], verbose=1)
rL = result[0]
masked_imageL=visualize.display_instances(image_id,image, rL['rois'], rL['masks'], rL['class_ids'],
class_names, rL['scores'])
# 保存检测结果
height, width = image.shape[:2]
masked_imageL.set_size_inches(width/96.0,height/96.0)#输出width*height像素
plt.subplots_adjust(top=1,bottom=0,left=0,right=1,hspace =0, wspace =0)#输出图像#边框设置
plt.margins(0,0)
plt.savefig(r"./out/%s" % (image_id), dpi=96.0, pad_inches=0.0)
cv2.imwrite("./test_results/%s"%(image_id), masked_imageL)
6、模型评估
6.1、评估指标的确定

TP (True Positive) 代表本文算法和人工标注法均提取到建筑物.
FN (False Negative) 代表本文算法未提取到建筑物而人工标注法能提取到建筑物.
FP (FalsePositive) 代表本文算法能提取到建筑物而人工标记法未提取到建筑物.

1、mAP(准确率)
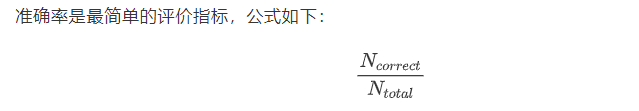
mAP=(TP)/(TP+TN)

2、Recall(查全率)
召回率(Recall)也叫查全率,衡量的是实际的正例有多少被模型预测为正例
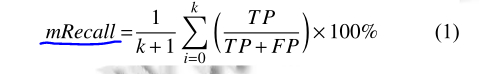
3、Precision(查准率)



4、P-R曲线和F1分数

from typing import List, Tuple
import matplotlib.pyplot as plt
def get_confusion_matrix(
y_pred: List[int],
y_true: List[int]
) -> Tuple[int, int, int, int]:
length = len(y_pred)
assert length == len(y_true)
tp, fp, fn, tn = 0, 0, 0, 0
for i in range(length):
if y_pred[i] == y_true[i] and y_pred[i] == 1:
tp += 1
elif y_pred[i] == y_true[i] and y_pred[i] == 0:
tn += 1
elif y_pred[i] == 1and y_true[i] == 0:
fp += 1
elif y_pred[i] == 0and y_true[i] == 1:
fn += 1
return (tp, fp, tn, fn)
def calc_p(tp: int, fp: int) -> float:#计算查准率
return tp / (tp + fp)
def calc_r(tp: int, fn: int) -> float:#计算查全率
return tp / (tp + fn)
def get_pr_pairs(
y_pred_prob: List[float],
y_true: List[int]
) -> Tuple[List[int], List[int]]:
ps = [1]
rs = [0]
for prob1 in y_pred_prob:
y_pred_i = []
for prob2 in y_pred_prob:
if prob2 < prob1:
y_pred_i.append(0)
else:
y_pred_i.append(1)
tp, fp, tn, fn = get_confusion_matrix(y_pred_i, y_true)
p = calc_p(tp, fp)
r = calc_r(tp, fn)
ps.append(p)
rs.append(r)
ps.append(0)
rs.append(1)
return ps, rs
y_pred_prob = [0.9, 0.8, 0.7, 0.6, 0.55, 0.54, 0.53, 0.52, 0.51, 0.505,
0.4, 0.39, 0.38, 0.37, 0.36, 0.35, 0.34, 0.33, 0.3, 0.1]
y_true = [1, 1, 0, 1, 1, 1, 0, 0, 1, 0, 1, 0, 1, 0, 0, 0, 1, 0, 1, 0]
y_pred = [1] * 10 + [0] * 10
ps, rs = get_pr_pairs(y_pred_prob, y_true)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(12, 5))
ax.plot(rs, ps);



5、均方根误差(RMSE)、平均绝对误差(MAE)、均方误差(MSE)


6、ROC 和 AUC

在这里插入def calc_fpr(fp: int, tn: int) -> float:
return fp / (fp + tn)
def calc_tpr(tp: int, fn: int) -> float:
return tp / (tp + fn)
def get_ftpr_pairs(
y_pred_prob: List[float],
y_true: List[int]
) -> Tuple[List[int], List[int]]:
fprs = [0]
tprs = [0]
for prob1 in y_pred_prob:
y_pred_i = []
for prob2 in y_pred_prob:
if prob2 < prob1:
y_pred_i.append(0)
else:
y_pred_i.append(1)
tp, fp, tn, fn = get_confusion_matrix(y_pred_i, y_true)
fpr = calc_fpr(fp, tn)
tpr = calc_tpr(tp, fn)
fprs.append(fpr)
tprs.append(tpr)
fprs.append(1)
tprs.append(1)
return fprs, tprs
fprs, tprs = get_ftpr_pairs(y_pred_prob, y_true)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(12, 5))
ax.plot(fprs, tprs);代码片


def get_ftpr_pairs2(
y_pred_prob: List[float],
y_true: List[int]
) -> Tuple[List[int], List[int]]:
mplus = sum(y_true)
msub = len(y_true) - mplus
pairs = [(0, 0)]
prev = (0, 0)
length = len(y_pred_prob)
assert length == len(y_true)
for i in range(length):
if y_true[i] == 1:
pair = (prev[0], prev[1] + 1/mplus)
else:
pair = (prev[0] + 1/msub, prev[1])
pairs.append(pair)
prev = pair
pairs.append((1, 1))
fprs, tprs = [], []
for pair in pairs:
fprs.append(pair[0])
tprs.append(pair[1])
return fprs, tprs
fprs, tprs = get_ftpr_pairs2(y_pred_prob, y_true)
fig, ax = plt.subplots(nrows=1, ncols=1, figsize=(12, 5))
ax.plot(fprs, tprs);

7、IOU 、GIOU





`def Giou(rec1,rec2):
#分别是第一个矩形左右上下的坐标
x1,x2,y1,y2 = rec1
x3,x4,y3,y4 = rec2
iou = Iou(rec1,rec2)
area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))
area_1 = (x2-x1)*(y1-y2)
area_2 = (x4-x3)*(y3-y4)
sum_area = area_1 + area_2
w1 = x2 - x1 #第一个矩形的宽
w2 = x4 - x3 #第二个矩形的宽
h1 = y1 - y2
h2 = y3 - y4
W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的宽
H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高
Area = W*H #交叉的面积
add_area = sum_area - Area #两矩形并集的面积
end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重
giou = iou - end_area
return giou`



def Diou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
dious = torch.zeros((rows, cols))
if rows * cols == 0:#
return dious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
dious = torch.zeros((cols, rows))
exchange = True
# #xmin,ymin,xmax,ymax->[:,0],[:,1],[:,2],[:,3]
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
dious = inter_area / union - (inter_diag) / outer_diag
dious = torch.clamp(dious,min=-1.0,max = 1.0)
if exchange:
dious = dious.T
return dious

def bbox_overlaps_ciou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
cious = torch.zeros((rows, cols))
if rows * cols == 0:
return cious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
cious = torch.zeros((cols, rows))
exchange = True
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
u = (inter_diag) / outer_diag
iou = inter_area / union
with torch.no_grad():
arctan = torch.atan(w2 / h2) - torch.atan(w1 / h1)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w2 / h2) - torch.atan(w1 / h1)), 2)
S = 1 - iou
alpha = v / (S + v)
w_temp = 2 * w1
ar = (8 / (math.pi ** 2)) * arctan * ((w1 - w_temp) * h1)
cious = iou - (u + alpha * ar)
cious = torch.clamp(cious,min=-1.0,max = 1.0)
if exchange:
cious = cious.T
return cious
7、深度学习目标框回归损失函数
7.1 Smooth L1 Loss


7.2 IOULoss



7.3 GIOU


def Giou(rec1,rec2):
#分别是第一个矩形左右上下的坐标
x1,x2,y1,y2 = rec1
x3,x4,y3,y4 = rec2
iou = Iou(rec1,rec2)
area_C = (max(x1,x2,x3,x4)-min(x1,x2,x3,x4))*(max(y1,y2,y3,y4)-min(y1,y2,y3,y4))
area_1 = (x2-x1)*(y1-y2)
area_2 = (x4-x3)*(y3-y4)
sum_area = area_1 + area_2
w1 = x2 - x1 #第一个矩形的宽
w2 = x4 - x3 #第二个矩形的宽
h1 = y1 - y2
h2 = y3 - y4
W = min(x1,x2,x3,x4)+w1+w2-max(x1,x2,x3,x4) #交叉部分的宽
H = min(y1,y2,y3,y4)+h1+h2-max(y1,y2,y3,y4) #交叉部分的高
Area = W*H #交叉的面积
add_area = sum_area - Area #两矩形并集的面积
end_area = (area_C - add_area)/area_C #闭包区域中不属于两个框的区域占闭包区域的比重
giou = iou - end_area
return giou
7.4、DIOU



def Diou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
dious = torch.zeros((rows, cols))
if rows * cols == 0:#
return dious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
dious = torch.zeros((cols, rows))
exchange = True
# #xmin,ymin,xmax,ymax->[:,0],[:,1],[:,2],[:,3]
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
dious = inter_area / union - (inter_diag) / outer_diag
dious = torch.clamp(dious,min=-1.0,max = 1.0)
if exchange:
dious = dious.T
return dious


def bbox_overlaps_ciou(bboxes1, bboxes2):
rows = bboxes1.shape[0]
cols = bboxes2.shape[0]
cious = torch.zeros((rows, cols))
if rows * cols == 0:
return cious
exchange = False
if bboxes1.shape[0] > bboxes2.shape[0]:
bboxes1, bboxes2 = bboxes2, bboxes1
cious = torch.zeros((cols, rows))
exchange = True
w1 = bboxes1[:, 2] - bboxes1[:, 0]
h1 = bboxes1[:, 3] - bboxes1[:, 1]
w2 = bboxes2[:, 2] - bboxes2[:, 0]
h2 = bboxes2[:, 3] - bboxes2[:, 1]
area1 = w1 * h1
area2 = w2 * h2
center_x1 = (bboxes1[:, 2] + bboxes1[:, 0]) / 2
center_y1 = (bboxes1[:, 3] + bboxes1[:, 1]) / 2
center_x2 = (bboxes2[:, 2] + bboxes2[:, 0]) / 2
center_y2 = (bboxes2[:, 3] + bboxes2[:, 1]) / 2
inter_max_xy = torch.min(bboxes1[:, 2:],bboxes2[:, 2:])
inter_min_xy = torch.max(bboxes1[:, :2],bboxes2[:, :2])
out_max_xy = torch.max(bboxes1[:, 2:],bboxes2[:, 2:])
out_min_xy = torch.min(bboxes1[:, :2],bboxes2[:, :2])
inter = torch.clamp((inter_max_xy - inter_min_xy), min=0)
inter_area = inter[:, 0] * inter[:, 1]
inter_diag = (center_x2 - center_x1)**2 + (center_y2 - center_y1)**2
outer = torch.clamp((out_max_xy - out_min_xy), min=0)
outer_diag = (outer[:, 0] ** 2) + (outer[:, 1] ** 2)
union = area1+area2-inter_area
u = (inter_diag) / outer_diag
iou = inter_area / union
with torch.no_grad():
arctan = torch.atan(w2 / h2) - torch.atan(w1 / h1)
v = (4 / (math.pi ** 2)) * torch.pow((torch.atan(w2 / h2) - torch.atan(w1 / h1)), 2)
S = 1 - iou
alpha = v / (S + v)
w_temp = 2 * w1
ar = (8 / (math.pi ** 2)) * arctan * ((w1 - w_temp) * h1)
cious = iou - (u + alpha * ar)
cious = torch.clamp(cious,min=-1.0,max = 1.0)
if exchange:
cious = cious.T
return cious
8、深度学习调参tricks总结
8.1learning-rate与batch-size的关系
一般来说,越大的batch-size使用越大的学习率
原理很简单,越大的batch-size意味着我们学习的时候,收敛方向的confidence越大,我们前进的方向更加坚定,而小的batch-size则显得比较杂乱,毫无规律性,因为相比批次大的时候,批次小的情况下无法照顾到更多的情况,所以需要小的学习率来保证不至于出错
一般来说,卷积层设置的学习率应该更低一些,而全连接层的学习率可以适当提高。

8.2、权重初始化

8.3 dropout























 1043
1043











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









