







1. 准备
1.1 框架搭建说明
1.为什么要搭建Mask R-CNN的识别框架?
Mask R-CNN是一种主流的深度学习识别框架,常用于主流的实例分割场景,如拆码垛、货物拣选。
2.为什么要采用Tensorflow搭建?
TensorFlow 是目前应用最广泛的深度学习框架,除了提供 faster rcnn,同样提供 mask rcnn,利用 TensorFlow Models 可以快速搭建自己的 mask rcnn 模型。
3.为什么不采用Keras封装或者K&TF来完成识别框架的训练、识别?
Keras仅支持Python语言,模型数据为.h5,仅供Python调用,不便于项目的集成开发;Tensorflow可支持C++和Python,模型形式多样,方便项目应用,便于集成开发。
目前,确定的方案是采用Python进行训练,得到模型.pb,应用于OpenCV4.3.0的DNN识别框架,实现节点编辑器中的调用。
1.2 开发环境要求
操作系统: Window 10
IDE:Anaconda(最新)
语言:Python 3.6
Tensorflow版本:1.15.0
**由于版本的适配问题,以上推荐版本是可以正常配置的,下文配图请以此处提到的为准。请参考本文,根据实际使用的硬件和应用需求进行合理配置。
1.3 数据文件准备
本文以为识别对象进行说明。
171张图像,尺寸为128010243,灰度图,三通道。
2. Anaconda安装与Tensorflow环境搭建
2.1 Anaconda安装与配置
Win10环境搭建Tensorflow环境,需要安装Anaconda。
下载地址:
https://www.anaconda.com/products/individual
1.点击exe进行安装

2.设置安装路径

3.“Register Anaconda3 as my default Python 3.8”可保留选择

如遇长时间“卡顿”,查看是否有杀毒软件拦截进程,若没有,请耐心等待安装完成。

2.2 CUDA与CUDNN安装与配置
根据想要安装的Tensotflow版本选择下载和安装匹配的CUDA与CUDNN。在Tensorflow官网上有windows下的GPU版本对应的CUDA与CUDNN版本号。
Tensorflow官网地址:https://tensorflow.google.cn/install/source_windows

由于我安装的Tensorflow-gpu 1.14.0经过测试适配CUDA10.0,CUDNN v7版本,具体可以在NVIDIA官网查询,下载需要注册账号,直接微信就能注册,十分方便,不建议去其他地方下载,建议下载官网版本。
CUDA Toolkit网址:https://developer.nvidia.com/cuda-toolkit-archive
CUDNN网址:https://developer.nvidia.com/rdp/cudnn-archive
下载完成后安装CUDA Toolkit,安装时间可能比较长,”Extraction path“是暂时解压路径,安装完成后就会消失,直接点击OK,直到安装完成,如果出现安装失败,建议检查Microsoft Visual C++组件,或者安装Microsoft Visual Studio 2019解决。
安装CUDNN,将下载的CUDNN解压。
复制解压出来的三个文件,替换安装的CUDA路径。
因为我CUDA安装用的默认路径所以我的CUDA路径为:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0
安装完成后,编辑电脑环境变量,添加CUDA安装路径下的:
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.0\libnvvp
到环境变量
2.3 启动Anaconda
在Cortana输入Anaconda打开Anaconda Prompt。
如果不想用默认的Python3.8,可通过cmd使用anaconda命令创建python的虚拟环。使用Python3.6:
1.conda create -n mtfpy36 python=3.6 # mtfpy36为环境名,可定义。
2.激活py36环境:activate mtfpy36
退出当前环境:deactivate mtfpy36
2.4 创建Tensorflow运行环境
上一步已经创建了一个mtfpy36的虚拟环境,一下有关Anaconda操作均是在此环境下进行的操作。
1.进入虚拟环境
在Cortana输入Anaconda打开Anaconda Prompt,输入命令:
conda activate mtfpy36
2.安装并测试tensorflow-gpu/tensorflow
如果有nvidia显卡,可安装TensorFlowGPU版本;否则,电脑将不支持GPU加速。如果不知道GPU对应的cuda&cudnn版本号,可先不装cuda&cudnn,待进行tensorflow-gpu安装完成测试时获取对应的cuda&cudnn版本。
安装:
->conda intstall tensorflow=1.15
若无法正常安,可采用pip方式:
->pip intstall tensorflow=1.15
测试:
->python
->>> import tensorflow as tf
如果不报错,说明安装成功。
2.5 TensorFlow Object Detection API配置
tensorflow附带了一些样例和示范代码,我们在示范代码的基础上做修改,训练自己的目标检测模型。
1.下载models
下载链接:
<因有些下载链接已失效,需要补充models获取的方式>
2.安装api
将models解压,进入models/research/目录:
->cd <盘符>:
-><盘符>:
->cd <盘符>:…\ models\research
windows用户需按下列步骤手动安装(若已安装,请忽略):
pip install pillow
pip install jupyter
pip install matplotlib
进入models/research/目录 ,手动编译.proto文件,共29个,一个一个输入(因protoc版本不同,可尝试是否支持批量处理,如protoc object_detection/protos/*.proto --python_out=.):
protoc object_detection/protos/anchor_generator.proto --python_out=.
protoc object_detection/protos/argmax_matcher.proto --python_out=.
protoc object_detection/protos/bipartite_matcher.proto --python_out=.
protoc object_detection/protos/box_coder.proto --python_out=.
protoc object_detection/protos/box_predictor.proto --python_out=.
protoc object_detection/protos/eval.proto --python_out=.
protoc object_detection/protos/faster_rcnn.proto --python_out=.
protoc object_detection/protos/faster_rcnn_box_coder.proto --python_out=.
protoc object_detection/protos/graph_rewriter.proto --python_out=.
protoc object_detection/protos/grid_anchor_generator.proto --python_out=.
protoc object_detection/protos/hyperparams.proto --python_out=.
protoc object_detection/protos/image_resizer.proto --python_out=.
protoc object_detection/protos/input_reader.proto --python_out=.
protoc object_detection/protos/keypoint_box_coder.proto --python_out=.
protoc object_detection/protos/losses.proto --python_out=.
protoc object_detection/protos/matcher.proto --python_out=.
protoc object_detection/protos/mean_stddev_box_coder.proto --python_out=.
protoc object_detection/protos/model.proto --python_out=.
protoc object_detection/protos/multiscale_anchor_generator.proto --python_out=.
protoc object_detection/protos/optimizer.proto --python_out=.
protoc object_detection/protos/pipeline.proto --python_out=.
protoc object_detection/protos/post_processing.proto --python_out=.
protoc object_detection/protos/preprocessor.proto --python_out=.
protoc object_detection/protos/region_similarity_calculator.proto --python_out=.
protoc object_detection/protos/square_box_coder.proto --python_out=.
protoc object_detection/protos/ssd.proto --python_out=.
protoc object_detection/protos/ssd_anchor_generator.proto --python_out=.
protoc object_detection/protos/string_int_label_map.proto --python_out=.
protoc object_detection/protos/train.proto --python_out=.
3.将object_detection加入系统环境变量
进入models/research文件夹,输入:
python setup.py install
进入models/research/slim文件夹,输入:
python setup.py install
然后,按下列步骤将research文件夹和slim文件夹加入系统变量。
进入资源管理器,右键点击属性-高级系统属性-环境变量设置-path,编辑如图所示,路径换成你自己的:

4.安装完成测试
打开cmd,进入刚创建的虚拟环境。
进入models/research文件夹,输入:
python object_detection/builders/model_builder_test.py
出现类似提示,即安装完成。

3. 数据集制作
3.1 数据文件分类
将数据分为两类:train、test。
3.2 标记图片
- 安装labelme
在命令行输入:pip install labelme - 标记图片
采用labelme进行图片标记。
<请参考labelme标记样本的相关内容>
3.3 将数据转化为TFRecord格式数据
根据create_tf_record.py提示,完成TFRecord格式转化。
3.4 创建pbtxt文件
根据标记对象创建pbtxt文件
4. 配置与训练
4.1 下载预训练模型
下载models-master,因版本原因,需要下载与当前框架对应的模型文件。请使用提供的资源。
4.2 修改mask rcnn config文件
1.目标种类个数
num_classes: 4,改为自己的目标种类个数
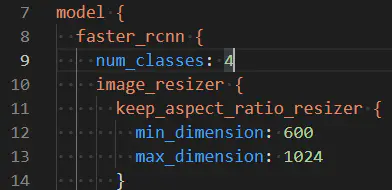
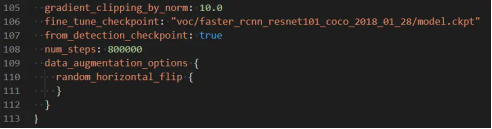
2.自定义路径指定模型位置
fine_tune_checkpoint: “PATH_TO_BE_CONFIGURED/model.ckpt”
通常在进行训练时不会从头开始训练,大部份会利用别人已经训练好的参数来微调以减少训练的时间
fine_tune_checkpoint的数值为:你定义的faster_rcnn_resnet101_coco_2018_01_28位置(例如:“object_detection/voc/faster_rcnn_resnet101_coco_2018_01_28/model.ckpt”)
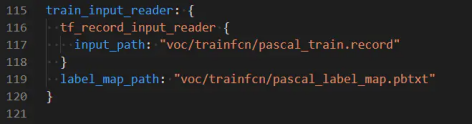
3.指定训练数据的label和record数据文件
label文件即我们刚刚修改过的标签映射文件,pascal_label_map.pbtxt
record文件:即pascal_train.record转换成tfrecord的训练集
train_input_reader: {
tf_record_input_reader { input_path: “PATH_TO_BE_CONFIGURED/pascal_train.record” }
label_map_path: “PATH_TO_BE_CONFIGURED/pascal_label_map.pbtxt”}
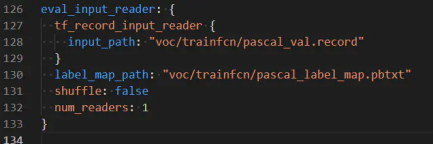
4.指定测试数据的label和record数据文件
label文件即我们刚刚修改过的标签映射文件pascal_label_map.pbtxt
record文件:即pascal_val.record转换成tfrecord的训练集
eval_input_reader: {
tf_record_input_reader { input_path: “PATH_TO_BE_CONFIGURED/pascal_val.record” }
label_map_path: “PATH_TO_BE_CONFIGURED/pascal_label_map.pbtxt”
}
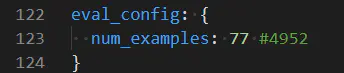
5.修改验证集图片张数
可查看数据集中val数量修改:
4.3 开始训练
进入object_detection文件夹,输入(请按实际修改成自己的路径):
python train.py --train_dir=voc\trainfcn\ --pipeline_config_path=voc\trainfcn\mask_rcnn_xxxxxx. config

4.4 查看训练过程
打开tensorboard可查看训练结果、损失函数情况等等。
进入object_detection文件夹,输入:
tensorboard --logdir=voc/trainfcn# 之前存放log的地方。
浏览器(推荐谷歌浏览器)登录XXXXXX:6006(根据提示确定),可打开Tensorboard查看信息。
4.5 转成pb格式模型
训练保存的模型如下:

经过多次训练,预览了一个你觉得最好的迭代次数保存下来的模型后,可以将该训练好的模型导出为pb文件,即Tensorflow的训练好的模型文件,可拷贝至其他机器供编程使用
该脚本名为export_inference_graph.py,脚本放在了object_detection目录下
使用方法:
python export_inference_graph.py --pipeline_config_path=voc\trainfcn\faster_rcnn_resnet101_voc07.config
–trained_checkpoint_prefix=voc\trainfcn\model.ckpt-10324 --output_directory voc\results
5.模型调用与实现
<请参考《OpenCV4.3.0版本DNN模块使用CUDA加速教程(Window10&VS2019)》>
若出现dnn无法正常读取网络,可能原因是在进行pb转化时pbtxt与pb不匹配,建议采用《pb模型文件与.pbtxt配置不匹配导致OpenCV调用dnn模块出错(Mask R-CNN为例)》(链接:https://blog.csdn.net/qq_23149979/article/details/107983330)方法生成pbtxt,重新转化pb模型。















 3839
3839











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









