









论文链接
开源代码链接
论文阅读
摘要(带有提示的分割模型)
我们介绍了分割一切(SA)项目:一个新的图像分割任务,模型和数据集。在数据收集循环中使用我们的高效模型,我们建立了迄今为止(到目前为止)最大的分割数据集,在1100万张许可和尊重隐私的图像上拥有超过10亿个掩模。该模型被设计和训练为提示,因此它可以将零拍摄转移到新的图像分布和任务。我们评估了它在许多任务中的能力,发现它的零射击性能令人印象深刻-通常与之前的完全监督结果相竞争甚至优于。我们在https://segment-anything.com上发布了包含1B个掩模和11M张图像的分段任意模型(SAM)和相应的数据集(SA-1B),以促进对计算机视觉基础模型的研究。
引言
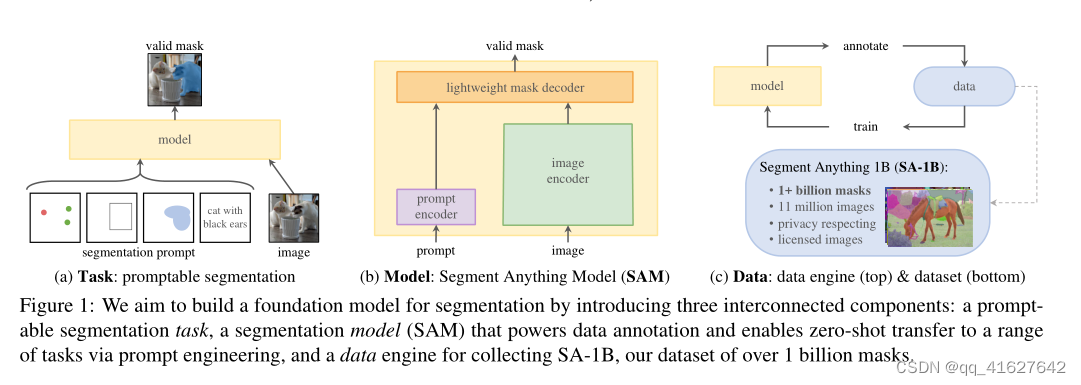
可提示的分割任务和实际使用的目标对模型体系结构施加了约束。特别是,模型必须支持灵活的提示,需要在平摊实时中计算掩码以允许交互使用,并且必须具有歧义意识。令人惊讶的是,我们发现一个简单的设计满足所有三个约束:一个强大的图像编码器计算图像嵌入,一个提示编码器嵌入提示,然后将两个信息源组合在一个轻量级的掩码解码器中,该解码器预测分割掩码。我们将此模型称为分割一切模型(Segment Anything model,简称SAM)(见图1b)。通过将SAM分为图像编码器和快速提示编码器/掩码解码器,可以使用不同的提示重复使用相同的图像嵌入(并平摊其成本)。给定图像嵌入,提示编码器和掩码解码器在web浏览器中从提示符预测掩码,时间为~ 50ms。我们将重点放在点、框和掩码提示上,并使用自由格式的文本提示来呈现初始结果。为了使SAM能够感知歧义,我们将其设计为预测单个提示的多个掩码,从而允许SAM自然地处理歧义,例如衬衫与人的例子。
Segment Anything Task
task
我们首先将提示的概念从NLP转移到分割,其中提示可以是一组前景/背景点,一个粗略的框或掩膜,自由格式的文本,或者一般情况下,任何指示图像中要分割的信息。因此,提示分段任务是在给定任何提示的情况下返回一个有效的分段掩码。“有效”掩码的要求仅仅意味着,即使提示是模糊的,并且可以引用多个对象(例如,回想一下衬衫与人的例子,参见图3),输出也应该是这些对象中至少一个的合理掩码。这个需求类似于期望语言模型对不明确的提示输出一致的响应。我们之所以选择这个任务,是因为它带来了一种自然的预训练算法和一种通过提示将零射击转移到下游分割任务的通用方法。

Figure 3: Each column shows 3 valid masks generated by SAM from a single ambiguous point prompt (green circle).
图3:每列显示SAM从一个不明确的点提示(绿色圆圈)生成的3个有效掩码。
Pre-training.
预训练。提示分割任务提出了一种自然的预训练算法,该算法为每个训练样本模拟一系列提示(例如,点、框、掩码),并将模型的掩码预测与基本事实进行比较。我们从交互式分割中采用了这种方法[109,70],尽管与交互式分割不同,交互式分割的目的是在足够的用户输入后最终预测一个有效的掩码,但我们的目标是始终预测任何提示的有效掩码,即使提示是模糊的。这确保了预训练模型在涉及歧义的用例中是有效的,包括我们的数据引擎§4所要求的自动注释。我们注意到,在这个任务中表现良好是具有挑战性的,需要专门的建模和训练损失选择,我们在§3中讨论过
零射击转移
零射击转移。直观地说,我们的预训练任务赋予了模型在推理时对任何提示作出适当响应的能力,因此下游任务可以通过设计适当的提示来解决。例如,如果有一个猫的边界框检测器,猫实例分割可以通过提供检测器的框输出作为提示给我们的模型来解决。一般来说,许多实际的分割任务都可以作为提示。除了自动数据集标记,我们在§7的实验中探索了五个不同的示例任务。
Related tasks
相关的任务。分割是一个很广阔的领域,有交互式分割[57,109]、边缘检测[3]、超像素化[85]、目标建议生成[2]、前景分割[94]、语义分割[90]、实例分割[66]、全视分割[59]等。我们的提示分割任务的目标是产生一个功能广泛的模型,可以通过快速工程适应许多(尽管不是全部)现有的和新的分割任务。这种能力是任务泛化的一种形式[26]。请注意,这与之前在多任务分割系统上的工作不同。在多任务系统中,单个模型执行一组固定的任务,例如联合语义分割、实例分割和全视分割[114,19,54],但训练和测试任务是相同的。我们工作中的一个重要区别是,训练用于提示分割的模型可以作为更大系统中的组件在推理时间执行新的不同任务,例如,执行实例分割,提示分割模型与现有的对象检测器相结合。
Discussion
讨论。提示和组合是功能强大的工具,可以以可扩展的方式使用单个模型,从而潜在地完成模型设计时未知的任务。这种方法类似于其他基础模型的使用方式,例如CLIP[82]是DALL·E[83]图像生成系统的文本-图像对齐组件。我们预计,可组合的系统设计,由提示工程等技术提供动力,将比专门为固定任务集训练的系统实现更广泛的应用。通过组合的镜头来比较提示式和交互式分割也是很有趣的:虽然交互式分割模型是为人类用户设计的,但正如我们将演示的那样,为提示式分割训练的模型也可以组成一个更大的算法系统。
Segment Anything Model
接下来,我们描述了分段任意模型(SAM),用于提示分段。SAM有三个组件,如图4所示:一个图像编码器,一个灵活的提示编码器和一个快速掩码解码器。我们建立在Transformer视觉模型[14,33,20,62]的基础上,对(平摊)实时性能进行了特定的权衡。我们在这里高层次地描述这些组件,细节见§a。

Image encoder .
图像编码器。在可扩展性和强大的预训练方法的激励下,我们使用了MAE[47]预训练的视觉变压器(ViT)[33],以最小程度适应处理高分辨率输入[62]。图像编码器每个图像运行一次,可以在提示模型之前应用。
Prompt encoder .
提示编码器。我们考虑两组提示:稀疏(点、框、文本)和密集(掩码)。我们通过位置编码[95]来表示点和框,并对每个提示类型和使用CLIP[82]的现成文本编码器的自由格式文本进行学习嵌入求和。密集提示(即掩码)使用卷积嵌入,并在图像嵌入中按元素求和
Mask decoder .
掩码解码器。掩码解码器有效地将图像嵌入、提示嵌入和输出令牌映射到掩码。该设计受到[14,20]的启发,采用了对Transformer解码器块[103]的修改,然后是动态掩码预测头。我们改进的解码器块在两个方向上使用提示自注意和交叉注意(提示到图像嵌入,反之亦然)来更新所有嵌入。在运行两个块之后,我们对图像嵌入进行上采样,MLP将输出标记映射到动态线性分类器,然后该分类器计算每个图像位置的掩码前景概率。
Resolving ambiguity.
解决歧义。对于一个输出,如果给出一个模糊的提示,该模型将平均多个有效掩码。为了解决这个问题,我们修改了模型,以预测单个提示符的多个输出掩码(见图3)。我们发现3个掩码输出足以解决大多数常见情况(嵌套掩码通常最多有三个深度:整体、部分和子部分)。在训练期间,我们只在面罩上进行最小损失[15,45,64]。为了对掩码进行排序,该模型预测每个掩码的置信度分数(即估计的借据)。
Efficiency.
效率。整体模型设计很大程度上是由效率驱动的。给定预先计算的图像嵌入,提示编码器和掩码解码器在web浏览器中运行,在CPU上,大约50ms。这种运行时性能支持模型的无缝、实时交互式提示。
Losses and training.
损失和训练。我们使用[14]中使用的焦损失[65]和骰子损失[73]的线性组合来监督掩模预测。我们使用几何提示的混合来训练可提示的分割任务(文本提示见§7.5)。接下来[92,37],我们通过在每个掩码中随机抽取11轮提示来模拟交互式设置,从而使SAM无缝地集成到我们的数据引擎中。















 1472
1472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









