






 本文探讨了图像地理标记的过程,主要利用SIFT特征描述算子进行图像分类。介绍了如何安装和使用GraphViz,以及在实验中遇到的问题,如图片尺寸对结果的影响,拍摄距离和光线条件对分类效果的干扰。实验分析了不同数据集的效果,并得出结论,适当保持图片原始特征对图像地理位置标记的重要性。
本文探讨了图像地理标记的过程,主要利用SIFT特征描述算子进行图像分类。介绍了如何安装和使用GraphViz,以及在实验中遇到的问题,如图片尺寸对结果的影响,拍摄距离和光线条件对分类效果的干扰。实验分析了不同数据集的效果,并得出结论,适当保持图片原始特征对图像地理位置标记的重要性。
目录
1.前言
图片地理标记即图像分类,可以实现多张图片进行特定的标志性物体分类。主要步骤需要对图像提取局部描述算子,一般情况都是使用SIFT特征描述算子。然后通过判断图像是否具有匹配的局部描述算子来定义图像之间的连接,实现图像可视化连接,图的边代表连接。在实现图像连接将会使用pydot工具包,该工具包是功能强大的GraphViz图形库的Python接口。
2、安装graphviz
(1)下载链接:https://graphviz.gitlab.io/_pages/Download/Download_windows.html,下载graphviz-2.38.msi并进行安装。
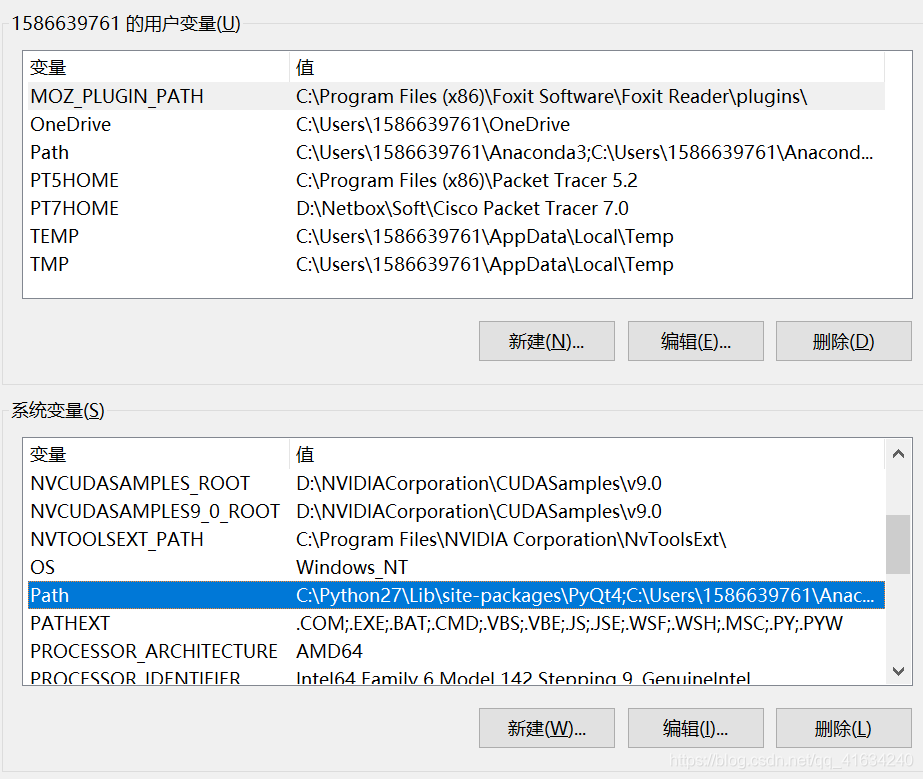
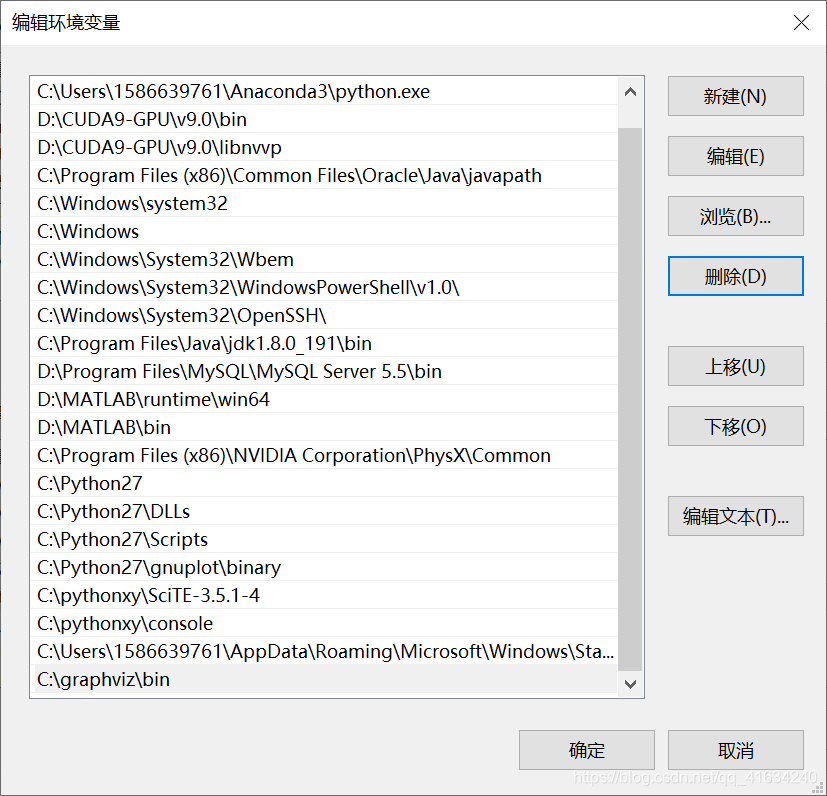
(2)安装成功过后,就要把路径添加到环境变量path里。具体步骤:此电脑-->属性-->高级系统设置-->环境变量-->path,然后新建添加其路径
(3)Windows+R 输入cmd,在出现的命令窗口中输入:pip install pydot
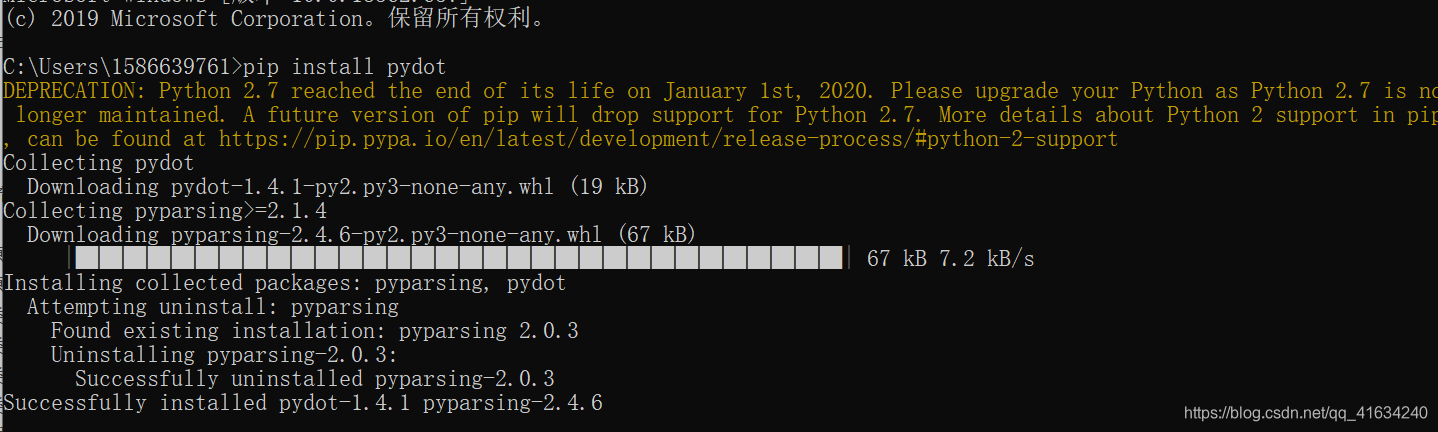
这样即安装成功
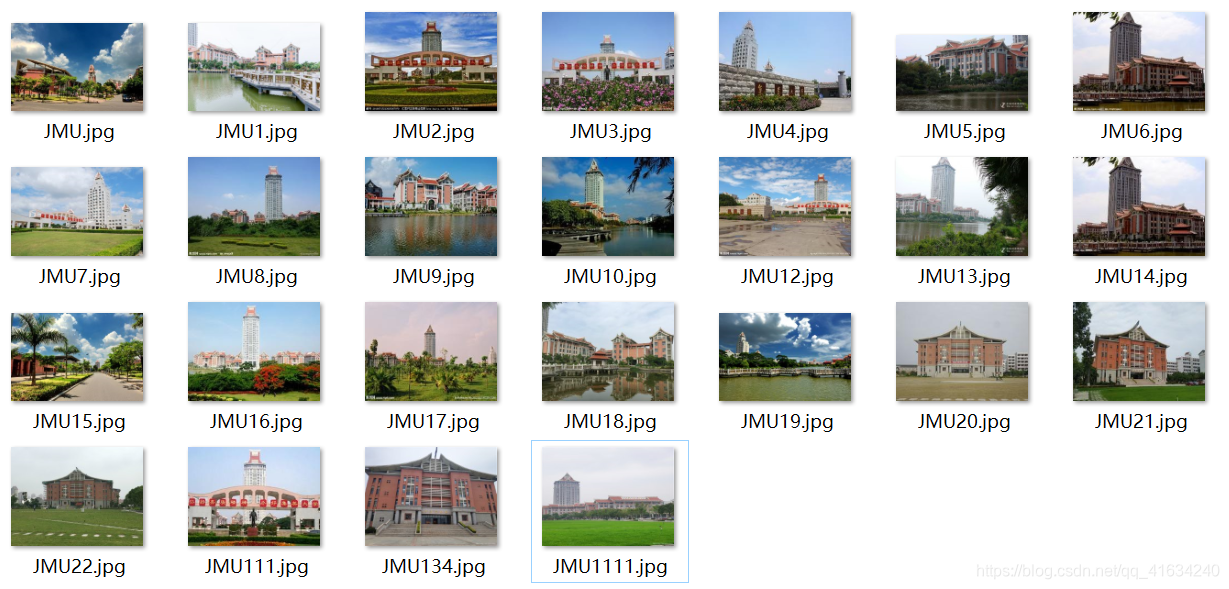
3.实验数据集
该数据集由集美大学延奎图书馆、嘉庚图书馆、尚大楼不同角度的图片组成
4.实验代码
# -*- coding: utf-8 -*-
from pylab import *
from PIL import Image
from PCV.localdescriptors import sift
from PCV.tools import imtools
import pydot
""" This is the example graph illustration of matching images from Figure 2-10.
To download the images, see ch2_download_panoramio.py."""
#download_path = "panoimages" # set this to the path where you downloaded the panoramio images
#path = "/FULLPATH/panoimages/" # path to save thumbnails (pydot needs the full system path)
#download_path = "F:\\dropbox\\Dropbox\\translation\\pcv-notebook\\data\\panoimages" # set this to the path where you downloaded the panoramio images
#path = "F:\\dropbox\\Dropbox\\translation\\pcv-notebook\\data\\panoimages\\" # path to save thumbnails (pydot needs the full system path)
download_path = "D:\JMU\computer_vision\experience2"
path = "D:\JMU\computer_vision\experience2"
# list of downloaded filenames
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
# extract features
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print 'comparing ', imlist[i], imlist[j]
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print 'number of matches = ', nbr_matches
matchscores[i, j] = nbr_matches
print "The match scores is: %d", matchscores
#np.savetxt(("../data/panoimages/panoramio_matches.txt",matchscores)
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
threshold = 2 # min number of matches needed to create link
g = pydot.Dot(graph_type='graph') # don't want the default directed graph
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = path + str(i) + '.png'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = path + str(j) + '.png'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
g.write_png('change3.png')
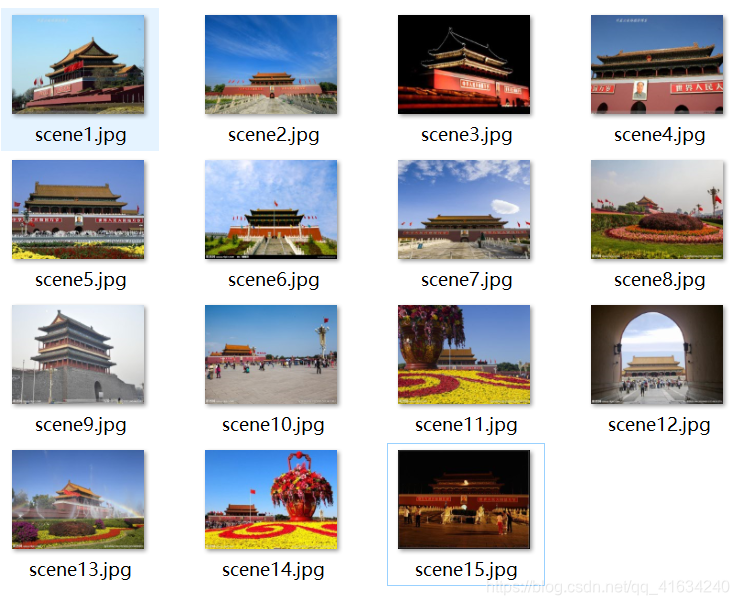
5.结果截图
6.实验分析
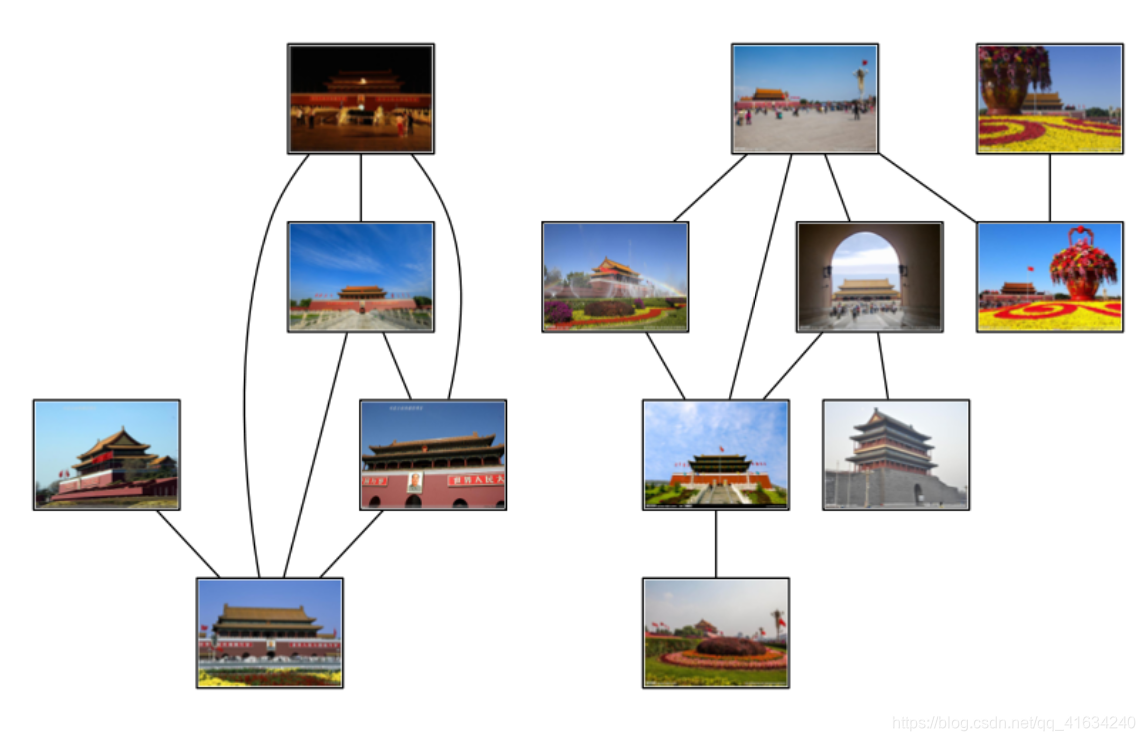
(1)在实验时由于图片过大,然后运行过程过长,所以在运行之前我将图片的像素进行更改,将其更改成了240*180的,然后进行了上面代码的运行,运行只用了十几秒就结束了,最终看到结果发现只有几张图片成功的标记了。以为是数据集的问题,所以又找了一个数据集,还是进行了像素的更改,最终结果还是这样(两组数据集和结果如下图)。



最终,发现将图片的数据集像素被压缩的太小,虽然有利于提高运行速度,但是失去了图片原本的特征,不利于图像地理位置的标记。
(2)通过实验发现,匹配过程中个别图片拍摄的远近会影响图片的分类效果
(3)当拍摄的光线太亮时,会影响图片地理位置的标记。(如下图的右图)


















 323
323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









