









参考链接:作者专栏
目录
摘要:
与之前两阶段的实例分割不同,是single shot 一阶段框架。
提出一个简单的全卷积的可用于mask预测的模块,可以和现有的检测算法结合。
我们的方法称为PolarMask,将实例分割问题描述为实例中心分类和极坐标下的密集距离回归。
PolarMask提出了一种新的instance segmentation建模方式,通过寻找物体的轮廓(contour)建模。
1.Introduction
实例分割是一个具有挑战性的任务,同时预测一张图片中每个实例的位置和语义分割mask。比较常用的解决办法就是像Mask RCNN一样的先检测再分割的两阶段方法。越来越多的工作致力于设计简单的bounding box检测器和后续的实例分割识别任务。我们的工作更着重于后者。
因此,我们的目标是设计一个概念简单的mask预测模块,它可以很容易地插入到许多现成的检测器中,从而实现实例分割。
语义表示:像素到像素的对应预测是非常奢侈的(如maskrcnn,下图(b)),特别是在single-shot方法中。我们指出,如果获得轮廓(下图(c)(d)),则可以成功而有效地恢复掩模。

在本文中,我们设计了基于极坐标表示的实例分割方法。
极坐标表示的优点:
(1)极坐标的原点可以看作是物体的中心。(2)从原点出发,轮廓中的点由距离和角度决定。(3)角度具有天然的方向性,使得将点连接成一个整体轮廓非常方便。(笛卡尔表示法缺乏第三种属性的优势)
基于极坐标系的方式已经将固定角度设为先验,网络只需回归固定角度的长度即可,简化了问题的难度。该模型获取输入图像,并预测从每个角度采样的正位置(实例中心的候选)到实例轮廓的距离,并在组装后输出最终mask。
我们用的目标检测器是FCOS。做一些修改,PolarMask也可以应用到RetinaNet , YOLO等检测网络上。
具体来说我们提出PolarMask用于实例分割,将实例分割问题描述为实例中心分类和极坐标下的密集距离回归。该模型获取输入图像,并预测从每个角度采样的正位置(实例中心的候选)到实例轮廓的距离,并在组装后输出最终mask。它引入了微不足道的开销。简单性和效率是single-shot实例分割的两个关键因素,PolarMask成功地实现了这两个关键因素。

PolarMask最重要的特点是:(1) anchor free and bbox free,不需要出检测框;(2) fully convolutional network, 相比FCOS把4根射线散发到36根射线,将实例分割和目标检测用同一种建模方式来表达。因此,PolarMask可以看作是FCOS的一个推广形式,或者FCOS是PolarMask的一个特例。
PolarMask can be viewed as a generalization of FCOS, or FCOS is a special case of PolarMask.
为了最大限度地发挥极值表示的优势,我们分别提出了极值中心和极值IoU损失(Polar Centerness and Polar IoU Loss)来处理高质量中心样本的抽样和密集距离回归的优化。它们将掩模精度提高约15%。
本文的主要贡献总结为三个方面:
- 引入了一种新的实例分割方法:PolarMask,,在极坐标层面建模Mask。把实例分割任务转换为两个平行的任务:实例中心分类和密集距离回归。这种方法最大的特点是简单高效。(我们第一次证明了实例分割的复杂度,无论是从设计复杂度还是计算复杂度来看,都可以与bbox对象检测一样。)
- 专门为本文的框架提出了Polar IoU Loss and Polar Centerness(极值中心和极值IoU损失)。相比于smooth-L1 loss,PolarIoU loss能极大的提高mask准确性。Polar Centerness改进了FCOS中最初的“中心”概念,从而进一步提高了性能。
- 第一次我们提出了更简单更灵活的实例分割框架,与更复杂的单阶段训练方法(通常包括多尺度训练和更长的训练时间)相比,获得更有竞争力的表现。We hope that PolarMask can serve as a fundamental and strong baseline for single shot instance segmentation.
2. Related Work
两阶段的实例分割方法都遵循着‘Detect then Segment‘,先检测再分割的范式,在检测框里再进行分割。它们可以达到最先进的性能,但速度往往很慢。
一阶段的方法,这里文中举了一些例子,比较复杂。并且这些方法不能直接对实例建模,,而且很难被优化。(比如存在这些优化问题:longer training time, more data augmentation and extra labels)
我们的PolarMask通过更简单的灵活的两个分支,直接对实例分割建模,对质心的每个像素进行分类,回归质心和轮廓之间的射线密集距离。
classifying each pixel of mass-center of instance and regressing the dense distance of rays between mass-center and contours.
PolarMask最重要的优点就是简单高效,相比于以上提到的方法。在实验中,由于我们的目标是设计一个概念上简单灵活的掩模预测模块,所以我们并没有采用太多的训练技巧,比如数据扩充、训练时间延长等。
3.Our methods
3.1 Architecture
整个模型结构包括:Backbone网络和FPN特征提取网络设置都与FCOS一致,为了对比简洁高效性),两个或三个任务分支,取决于这个模型是否预测bbox。(polarmask可以结合单阶段和两阶段的模型使用)

3.2 Polar Mask Segmentation
这一部分详细的介绍怎么用极坐标建模实例(instance)
我们对实例的候选中心(Xc,Yc)和位于轮廓(Xi,Yi)上的点(I=1, 2,…,n)进行采样,然后从中心开始,N射线均匀地发射,具有相同的角度间隔δ(例如,n=36,δth==10),其长度由中心到轮廓上的点来确定。(这也是前面说的我们只需要对距离进行回归)
与之前的逐像素的生成mask相比,这里将mask建模转换为一个实例中心和36个点之间的距离回归,计算量大大减少。

Center samples
在质心范围内,从上到下从右到左选取一组center samples.就可以增加9~16个samples。

这种做法有两个优点:
(1)将阳性样品的数量从1增加到9 ~ 16可以在很大程度上避免阳性和阴性样品的不平衡。然而,训练分类分支时仍需要focal loss(后面有解释)。(2)质心可能不是一个实例的最佳中心样本。更多的候选点使得自动找到一个实例的最佳中心成为可能。我们将在3.3节中详细讨论。
Distance Regression
有了中心点(Xc,Yc)和轮廓线上的点(Xi,Yi),计算距离很简单。N=36,则轮廓线上有36个点,间隔10°。大多数情况下都可以获得所需要的n条射线。接着讨论了三种特例,比如不同射线在轮廓上的点是重合的等等。作者也认为这些特例也是限制Polar表示的性能上界接近mAP100%的主要因素。
回归分支的训练是非常重要的。PolarMask的mask分支实际上是一个密集距离回归任务(a dense distance regression task)。每一个训练样本的n条相关的射线应被视为一个整体,而不是独立的回归的example。因此我们提出了Polar IoU Loss。3.4详细讨论。
轮廓线上的点的位置坐标是这样计算的:
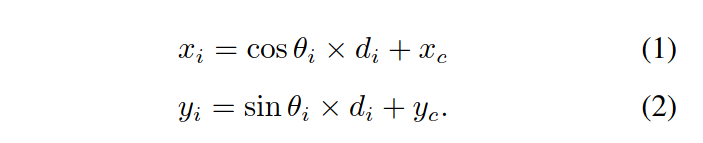
参数:角度,距离,中心坐标。
Mask Assembling
在推理过程中,网络输出分类和中心度(Polar centerness),将中心度与分类相乘,得到最终的置信度分数。在将置信度得分阈值设为0.05之后,我们最多只能根据每个FPN级别的最高得分预测1k来组装mask。 合并所有级别的最高预测,并应用阈值为0.5的非最大抑制(NMS)产生最终结果。 在这里,我们介绍了mask的组装过程和快速的NMS过程。NMS用来删除冗余的掩码。
3.3. Polar Centerness
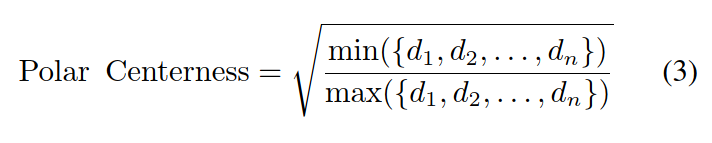
这是一个简单而有效的策略来重设点的权重,这样dmin和dmax越接近,分配给点的权重就越高。实验表明,在AP75等更严格的定位条件下,极坐标中心能提高定位精度。
3.4. Polar IoU Loss
smooth-l1 loss and IoU loss are the two effective ways to supervise the regression problems.
然而,smooth-l1损失忽略了相同对象的样本之间的相关性,从而导致定位精度较低。然而,IoU损失的训练过程将优化作为一个整体来考虑,并直接优化兴趣度量。
然而,计算所预测掩模的IoU和它的groundtruth是非常棘手的,并且很难实现并行计算。
在这项工作中,我们推导了一个简单而有效的算法来计算掩模IoU基于极坐标向量表示,并取得了具有竞争力的性能,如下所示。根据IoU的定义我们引入了Polar IoU Loss,也是交并比,计算方式如下:

离散形式

进一步化简为:
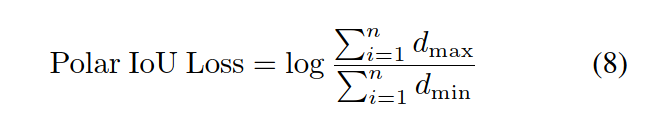
Polar IoU Loss is the binary cross entropy (BCE) loss of Polar IoU. Since the optimal IoU is always 1.
我们的Polar IoU Loss有两个优势:(1) 它是可微的,允许反向传播;并且很容易实现并行计算,从而促进快速训练过程。(2) 从整体上预测回归目标。实验表明,与平滑l1损耗相比,它能大幅度提高系统的整体性能。(3) 另外,Polar IoU损失能够自动保持分类损失和密集距离预测回归损失之间的平衡。我们将在实验中详细讨论。

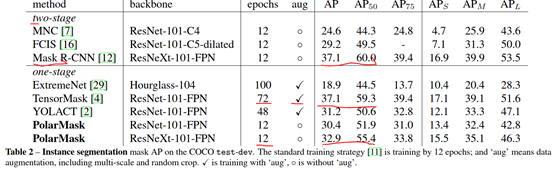
性能对比:在单阶段方法中,PolarMask性能较好,速度快且精度较高,以后可作为单阶段方法的一个baseline。
在这个模型中,分类分支采用的损失函数是focal loss,基于交叉熵的改进,用于平衡正负样本,详情可参考以下链接。
Focal loss: https://www.cnblogs.com/king-lps/p/9497836.html
二分类交叉熵损失:
![]()
在原有交叉熵的基础上,增加因子gamma和alpha.
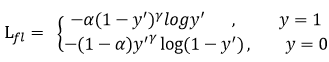
只添加alpha虽然可以平衡正负样本的重要性,但是无法解决简单与困难样本的问题。
gamma调节简单样本权重降低的速率,当gamma为0时即为交叉熵损失函数,当gamma增加时,调整因子的影响也在增加。实验发现gamma为2是最优。















 1619
1619











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









