







Transformer学习整理1
Encoder-decoder结构;自注意力机制;
最早出自:《Attention Is All You Need》(2017,google)
无CNN,RNN结构;
包括6个结构完全相同的编码器,和6个结构完全相同的解码器,其中每个编码器和解码器设计思想完全相同,只不过由于任务不同而有些许区别。

以机器翻译为例:
(1)输入数据处理:
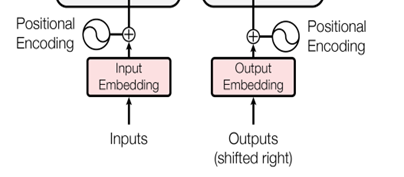
- 源单词嵌入
向量化;
- 位置编码 positional encoding
transformer内部没有类似RNN的循环结构,没有捕捉顺序序列的能力。在句子翻译中,词的顺序不同会导致句子意思不同。为了解决这个问题,在编码词向量时会额外引入了位置编码position encoding向量表示两个单词i和j之间的距离,简单来说就是在词向量中加入了单词的位置信息。(位置编码方法:(1)网络自动学习(2)定义规则。详见附录)
- 单词嵌入向量和位置编码向量相加
(2)编码器结构
6个完全一样结构的编码器层
一个编码器层包含Self-Attention和Feed-forward neural network (FFNN)两个子层,FFNN是全连接层。

Self-attention就是q,k,v标准的attetion,q,k,v来自同一个源。计算每个词和周围所有词的attention。相当于任两个词之间都有直连的关系线路,可捕获长距离依赖,不同程度上利用信息(权重分配),知道编码器更注意什么,attention的解释性更好。(相比于CNN)
编码器层里的self-attention是Multi-head attention。输入向量分别经过一个线性层变换得到Q,K,V向量。多头注意力相当于输入向量经过多套线性变换得到多套Q,K,V,计算多套注意力最后再拼接起来(并行地计算多层自注意力)。论文里使用h=8。多头注意力可以提取不同特征。
6个编码器层,每一层计算注意力都只与前一层的输入有关。由于每一层的Attention计算只和其前一层的Attention输出有关,所以当前层的所有词的Attention可以并行计算,互不干扰,这就使得Transformer可以利用GPU进行并行训练。(RNN是串行的,沿句子方向。Trnsformer是垂直方向叠加attention,并行训练。)

(3)解码器结构
6个完全一样结构的解码器层。
每一层包括三个子层:self-attention, Encoder-Decoder Attention和FFNN(全连接层)。

与Encoder中的self-attention不同的是多了 mask的操作。
因为Decoder在计算注意力只能用上当前解码的词和之前的词,在用矩阵计算注意力时,要把还未出现的词遮上。比如Decoder第二个词时,用黑框蒙住了第三、四个词的运算(设置值为-1e9)
Transformer在Encoder阶段可以并行化,Decoder阶段依然要一个个词顺序翻译,依然是串行的。
Encoder-decoder attention
在解码器中用self-attention只用到了翻译句子的信息,没有用到源句子的信息(翻译前)。因此对于encoder中源句子的信息,decoder用Encoder-decoder attention注意到并利用,encoder向decoder指出的两个箭头就是key,value,query来自decoder的self-att层。Encoder-Decoder Attention的作用就是看看当前要翻译的词在源句子中各个词上的注意力情况。
附录:
一、位置编码方法(Position encoding)
位置编码的两种方式:
- 网络自动学习
e.g.
self.pos_embedding = nn.Parameter(torch.randn(1, N, 512))
2. 自己定义规则
e.g.
sin-cos规则

二、多头注意力
“多头”注意机制,有多个查询/键/值权重矩阵集(Transformer使用8个注意力头,因此我们对于每个编码器/解码器有8个矩阵集合。
三、Decoder中的Masked Multi-head attention(self-attention)
Masked multi-head attention: 和编码部分的multi-head attention类似,但是多了一 次masked,因为在解码部分,解码的时候时从左到右依次解码的,当解出第一个字的时候,第一个字只能与第一个字计算相关性,当解出第二个字的时候,只能计算出第二个字与第一个字和第二个字的相关性,…;所以需要linalg.LinearOperatorLowerTriangular进行一次mask;

https://zhuanlan.zhihu.com/p/44731789
参考链接:
1.https://zhuanlan.zhihu.com/p/308301901
3.https://zhuanlan.zhihu.com/p/44731789
4.《Attention is all you need》https://arxiv.org/abs/1706.03762















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









