







目录
一、进程标识符 pid
概念:每个进程都有标识该进程身份的唯一数字,称为 pid
1.1 类型 pid_t
pid 的类型是 pid_t,传统意义上是个有符号的十六位整型,但是由于 pid 只能为正数,故同时最多存在三万多个进程
但是现在,很多系统已经对这个类型进行过 typedef 了,因此现在不同机器上这个类型占多少位是不确定的
注意:pid 顺次向下使用
假如现在已存在 pid=16533 的进程,但是不存在进程标识符为 16532 的进程,则给新产生的下一个进程所分配的进程标识符应该是 16534,而非 16532。这和文件描述符的分配策略是不同的
1.2 命令 ps
man ps
功能:打印出当前进程的信息
这个命令选项很多,要在 man 中学习,常用的几个命令选项:
- ps axf:查看当前运行的进程的情况
- ps axm:以详细信息查看当前运行的进程的情况
- ps ax -L:以 LINUX 特有的方式查看当前运行的进程的情况
- ......
1.3 getpid && getppid
man 2 getpid;man 2 getppid
#include <sys/types.h>
#include <unistd.h>
pid_t getpid(void); // 获取当前进程的pid
pid_t getppid(void); // 获取当前进程父进程的pid二、进程的产生
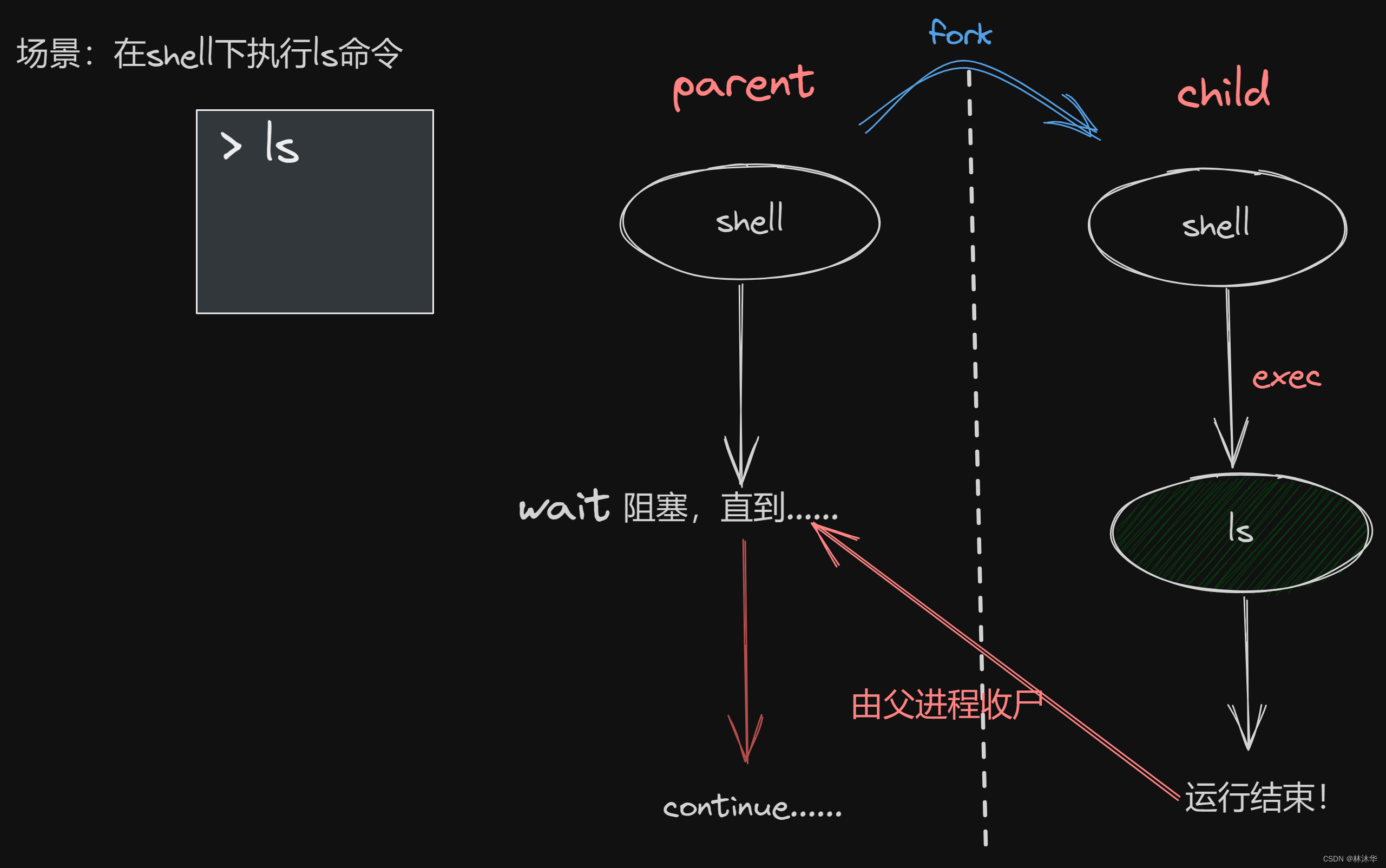
2.1 fork 简介
学了这个函数之后,别忘了 fork 这个单词原本的含义:叉子
man 2 fork
#include <sys/types.h>
#include <unistd.h>
pid_t fork(void);功能:创建一个子进程
fork 是通过复制(duplicating)当前进程创建子进程的

细说复制:父子进程除了下述区别,剩下的一模一样!甚至子进程执行到的位置都和当前进程一样
fork 后父子进程的区别:
- fork 的返回值不同,父进程返回子进程 pid,子进程返回 0
- 父子进程的 pid 不同
- 父子进程各自的父进程不同,故父子进程通过 getppid 获取到各自父进程的 pid 不同
- 未决信号和文件锁不继承
- 资源利用率清零。比如说父进程用了大量资源,显然不能让子进程也用这么多资源
补充:init 进程是所有进程的祖先进程,其进程 pid 为 1
2.2 fork 实例 1
示例 1 介绍 fork 的基本使用。主要关注一下 fork 的返回值:父进程返回子进程 pid,子进程返回 0,创建失败返回 -1。故一般来说,fork 后需要接上分支语句,通过 fork 的返回值判断是哪种情况
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
printf("[%d]: Begin!\n", getpid());
pid = fork();
// fork后接上分支语句,通过fork返回值判断情况
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // Child
printf("[%d]: Child is working!\n", getpid());
}
else { // Parent
printf("[%d]: Parent is working!\n", getpid());
}
printf("[%d]: End!\n", getpid());
exit(0);
}
在上述运行过程中,fork 之后,父进程执行语句先打印,子进程执行语句后打印。但是不要凭空假设哪个进程先运行!哪个进程先运行是由调度器的调度策略所决定的
如果想人为控制一下进程运行的先后顺序,可做如下操作:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
printf("[%d]: Begin!\n", getpid());
pid = fork();
// fork后接上分支语句,通过fork返回值判断情况
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // Child
printf("[%d]: Child is working!\n", getpid());
}
else { // Parent
sleep(1); // 让父进程歇会儿,调度器一般就会让子进程先运行了
printf("[%d]: Parent is working!\n", getpid());
}
printf("[%d]: End!\n", getpid());
exit(0);
}
但是通过 sleep 来控制进程运行的先后顺序是有缺陷的方法,后续会介绍别的更好的方法
接下来,我们看看如何证明确实 fork 创建了子进程
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
printf("[%d]: Begin!\n", getpid());
pid = fork();
// fork后接上分支语句,通过fork返回值判断情况
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // Child
printf("[%d]: Child is working!\n", getpid());
}
else { // Parent
printf("[%d]: Parent is working!\n", getpid());
}
sleep(100); // 让父子进程延迟100秒再结束
printf("[%d]: End!\n", getpid());
exit(0);
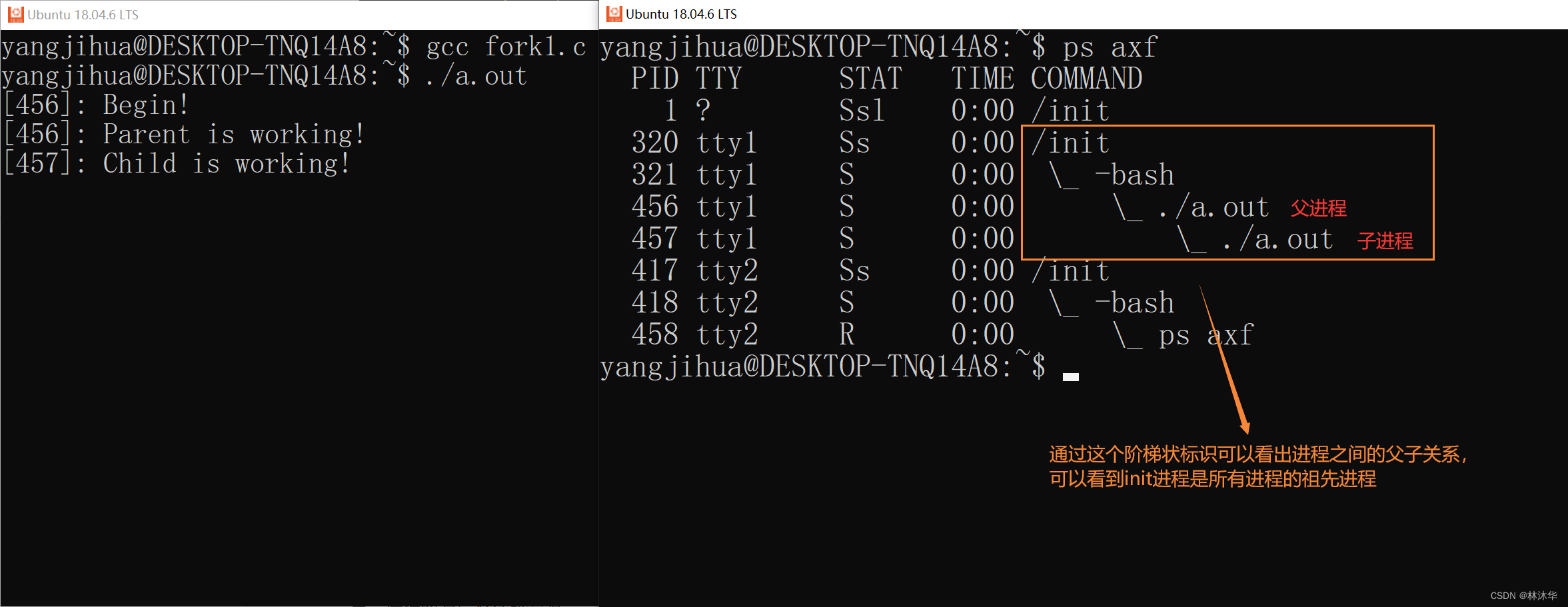
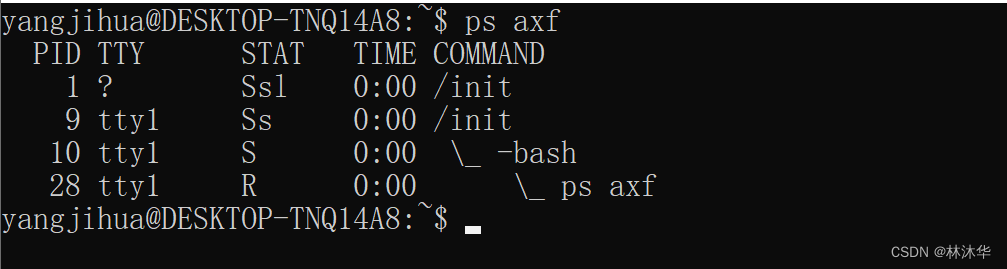
}在父子进程运行过程中,通过 ps 命令查看当前运行的进程的情况
接下来,看一个奇怪的现象,当我们将输出重定向到 out 文件中......
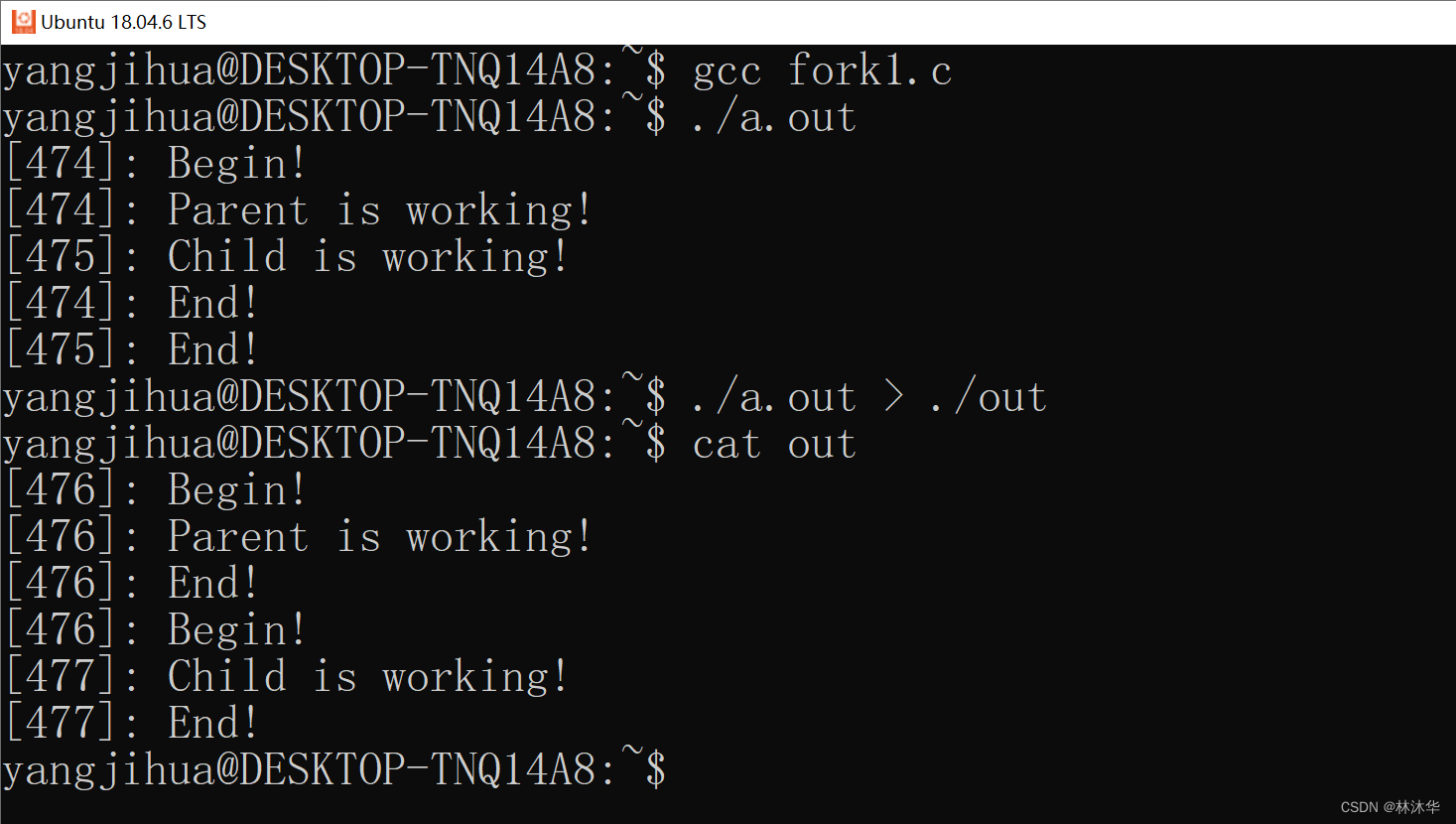
嚯?重定向到文件后,Begin 居然打印了两次,而且显示的都是父进程打印的......
可是按照我们之前的分析,不是只应该在 fork 之前,由父进程打印一次 Begin 嘛......
而且输出到终端,和重定向到文件,居然不一样......
问题多多,为什么捏?给几个提示 :
- 终端和文件具有不同的标准I/O缓冲类别
- duplicating
下面开始解答:
终端的缓冲类别默认是行缓冲,也就是说遇到换行符就会刷新缓冲区,因此,在 printf 中遇到换行符了,就能立马将缓冲区中的内容打印到终端显示上。
而文件的缓冲类别默认是全缓冲,也就是说在填满标准 I/O 缓冲区后,才对缓冲区进行冲洗。这样一来,printf 中即使遇到了换行符,因为缓冲区还没满,因此不会刷新。那么在即将执行 fork 的时候,希望打印出来的那几个字符仍然驻留在缓冲区,接下来,fork 会 duplicating 当前进程,创建子进程。别忘了,此时当前进程的缓冲区也一并被复制到子进程中了!相当于调用了 fork 之后,有两个缓冲区,这两个缓冲区都有字符驻留于其中。那么,会打印出两个 Begin 也就不足为奇了。并且,缓冲区中的字符内容已经固定,打印出来的将会是 fork 之前的进程的进程号(也就是父进程的进程号)
怎么解决这种问题?在 fork 之前,使用 fflush(NULL) 刷新所有已打开的流
#include <stdlib.h>
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid;
printf("[%d]: Begin!\n", getpid());
fflush(NULL); /*!!!*/
pid = fork();
// fork后接上分支语句,通过fork返回值判断情况
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // Child
printf("[%d]: Child is working!\n", getpid());
}
else { // Parent
printf("[%d]: Parent is working!\n", getpid());
}
printf("[%d]: End!\n", getpid());
exit(0);
}2.3 fork 实例 2
实例 2 介绍一下 fork 的应用。我们的需求:找出 30000000~30000200 之间的所有质数
- 单进程版本的暴力破解思想如下:
#include <stdio.h>
#include <stdlib.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
for(i = LEFT; i <= RIGHT; i++) { // 遍历每一个数,判定其是否为质数
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
}
exit(0);
}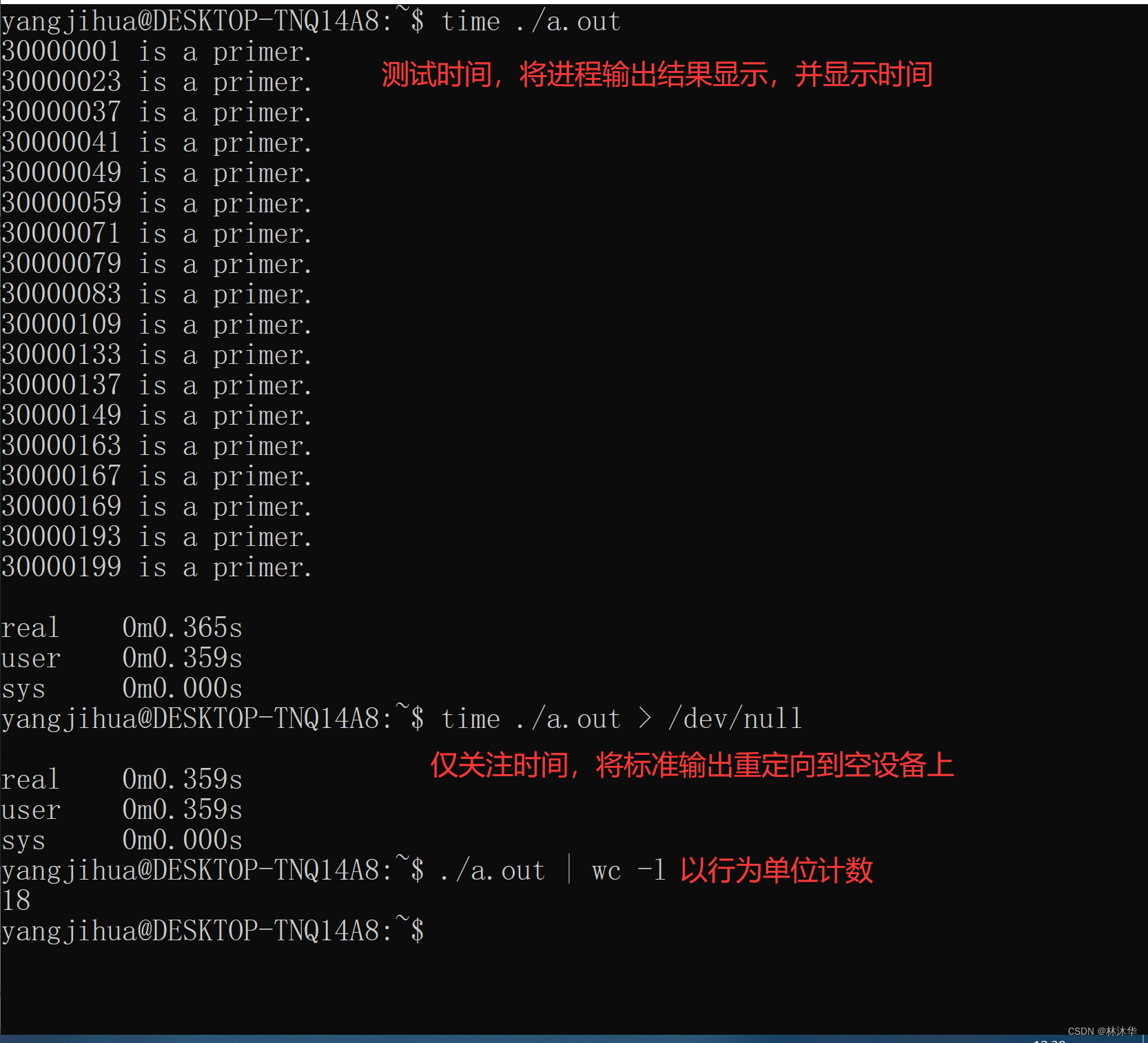
在测试上述代码的时候,用到的一些细碎的知识点:
wc - print newline, word, and byte counts for each file“|” 是 Linux 管道命令操作符,简称管道符。使用此管道符 “|” 可以将两个命令分隔开,“|” 左边命令的输出就会作为 “|” 右边命令的输入。此命令可连续使用,第一个命令的输出会作为第二个命令的输入,第二个命令的输出又会作为第三个命令的输入,依此类推
重定向到空设备:将标准输出重定向到空设备,就能将不需要的标准输出中的内容输出到空设备。注意 time 显示的那部分内容重定向不过去,因为那部分内容不属于标准输出
- 多进程协作版本的暴力破解思想如下:(注意子进程一定要在恰当的时候退出)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
pid_t pid;
for(i = LEFT; i <= RIGHT; i++) {
pid = fork(); // 对每个数,都创建一个子进程来判断其是不是质数
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) { // child,判断该数是否为质数
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
// 子进程一定要在这退出!!!否则子进程会也会继续fork出孙进程......
exit(0);
}
}
exit(0);
}
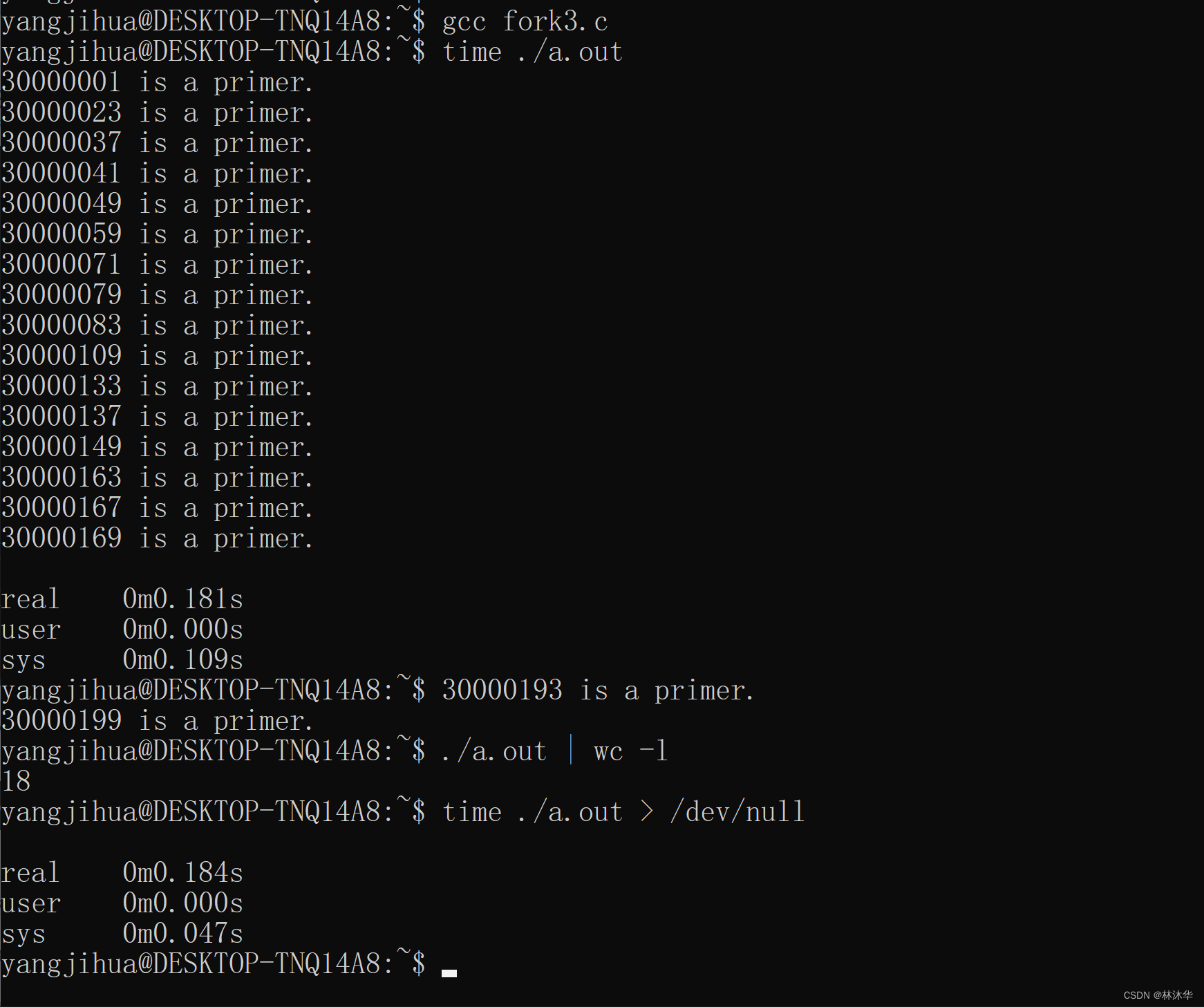
现在我们让子进程在退出前,先睡眠 1000s,这样父进程会先执行完毕而退出
再使用命令 ps axf 查看进程树
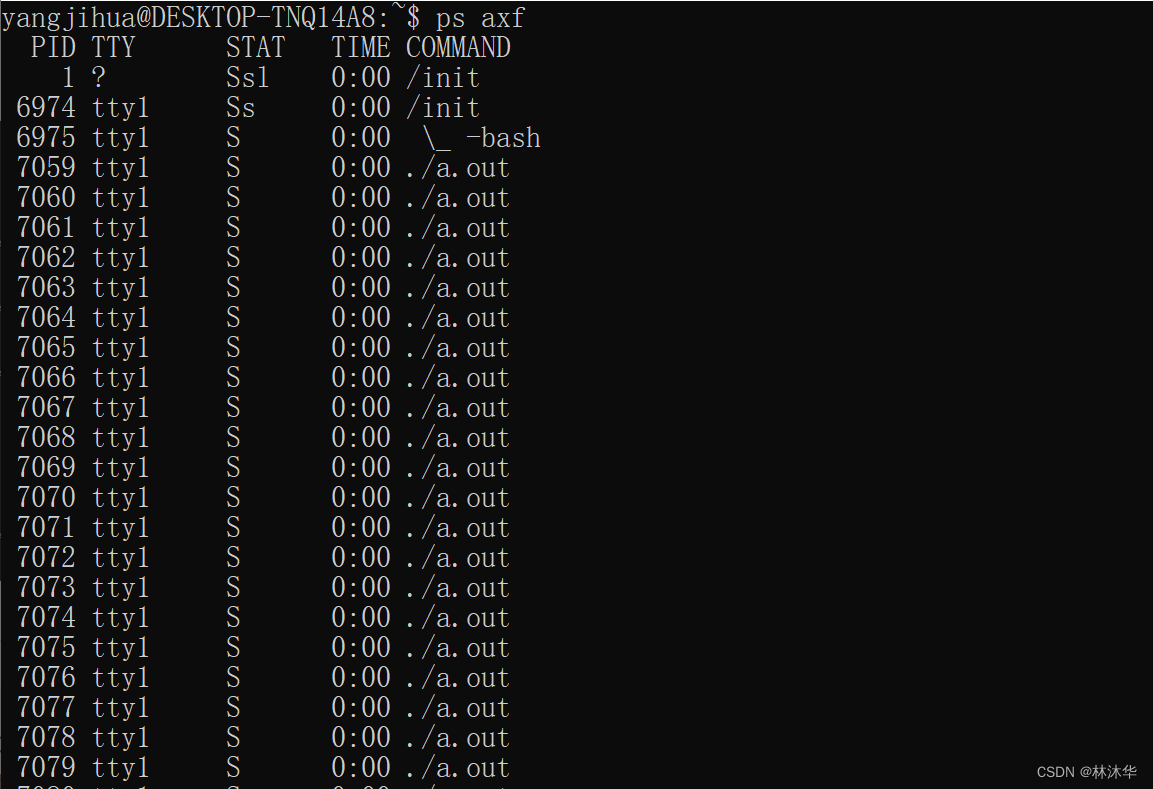
此时 201 个子进程的状态为 S(可中断的睡眠状态),且父进程为 init 进程(每个进程以顶格形式出现),这说明这些进程已经被 init 进程接管了。这里的子进程在 init 进程接管之前就是孤儿进程
孤儿进程:一个父进程退出,它的一个或多个子进程将成为孤儿进程。孤儿进程将被 init 进程所收养,并由 init 进程对它们完成状态收集工作,孤儿进程并不会有什么危害
现在我们让父进程在退出前,先睡眠 1000s,这样子进程会先执行完毕而退出
再使用命令 ps axf 查看进程树
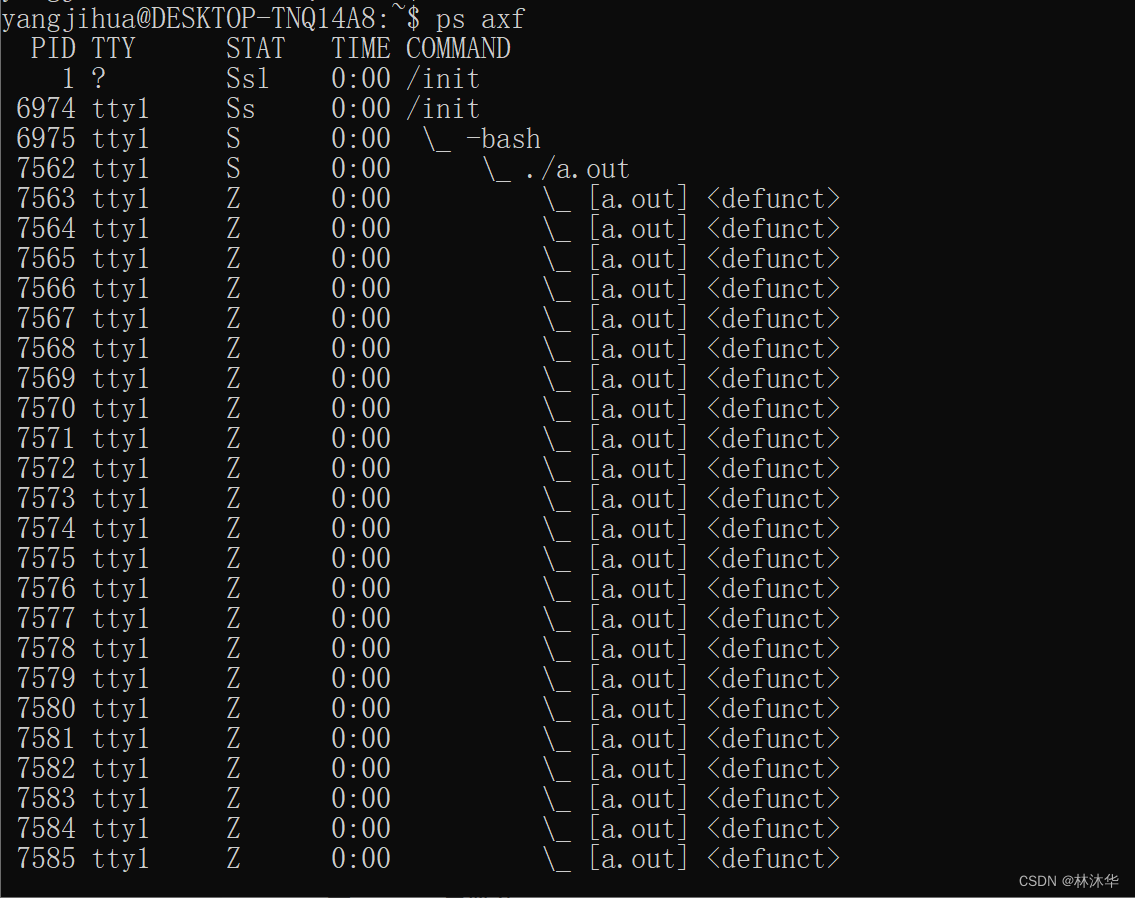
可以看到子进程状态为 Z,即为僵尸状态
僵尸进程:一个进程使用 fork 创建子进程,如果子进程退出,而父进程还没有调用 wait 或 waitpid 获取子进程的状态信息(收尸),那么子进程的进程描述符仍然保存在系统中,这种进程称之为僵尸进程
僵尸进程的危害:僵尸进程虽然不占太多内存,但如果父进程不调用 wait() / waitpid() 的话,那么保留的信息就不会释放,其进程号就会一直被占用,而系统所能使用的进程号是有限的,如果大量的产生僵死进程,将因为没有可用的进程号而导致系统不能产生新的进程
总而言之,上述介绍了两种进程,总结如下:
- 孤儿进程:没有父进程的进程
- 僵尸进程:已退出但是未被“收尸”的进程
一个进程可能同时是孤儿和僵尸:该进程还没被任何父进程接管且该进程还未被“收尸”
补充一下进程状态:man ps
Here are the different values that the s, stat and state output specifiers (header "STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO)
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
For BSD formats and when the stat keyword is used, additional characters may be displayed:
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group2.4 vfork
考虑这样一个场景,父进程使用了一个占用内存很大的数据,此时它 fork 了一个子进程,而子进程仅仅打印一个字符串就退出了,此时这块很大的数据复制到子进程的内存空间中,造成了很大的内存浪费
为了解决这个问题,在 fork 实现中,增加了读时共享,写时复制(Copy-On-Write,COW)的机制,避免了子进程用了很大力气复制了父进程的所有的地址空间,却什么也不做的现象。具体而言:
- 读时共享:如果父子进程都不对页面进行操作或只读,那么便一直共享同一物理页面
- 写时复制:只要父子进程有一个尝试进行修改某一个页面,那么内核便会为该页面创建一个新的物理页面,并将内容复制到新的物理页面中,让父子进程真正地各自拥有自己的物理内存页面

在 fork 还没实现 copy on write 之前。Unix 设计者很关心 fork 之后立刻执行 exec 所造成的地址空间浪费,所以引入了 vfork 系统调用。vfork 后必须调用 exec 函数,如果 vfork 后的子进程试图修改数据、进行其他函数调用或者没有调用 exec 就返回,都会带来不可预知的结果!现在 vfork 已经不常用了
三、进程的消亡及释放资源
3.1 wait
man 2 wait
#include <sys/types.h>
#include <sys/wait.h>
pid_t wait(int *wstatus);功能:等待进程状态发生变化
通俗一点儿的功能描述为:让进程等待,直到收尸它的某一个僵尸子进程
进程一旦调用了 wait,就立即阻塞自己,由 wait 自动分析是否当前进程的某个子进程已经退出,如果让它找到了这样一个已经变成僵尸的子进程,wait 就会收集这个子进程的信息,并把它彻底销毁(收尸);如果没有找到这样一个子进程,wait 就会一直阻塞在这里,直到有一个出现为止
- 如果执行成功,wait 会返回“被收尸”进程的 PID;失败,则 wait 返回 -1
- wstatus — 指针作为返回值,用来保存“被收尸”进程的一些退出状态(僵尸进程肯定是某个已经退出的进程)。指针所指整型数表征了退出状态的信息,能够通过下面一些宏函数,从这个整型数中获取我们想要的退出状态信息
| 宏 | 说明 |
|---|---|
| WIFEXITED(wstatus) | 如果子进程正常结束,它就返回真;否则返回假 |
| WEXITSTATUS(wstatus) | 如果 WIFEXITED(status) 为真,则可以用该宏取得子进程 exit()/return 返回的结束代码 |
| WIFSIGNALED(wstatus) | 如果子进程因为一个未捕获的信号而终止,它就返回真;否则返回假 |
| WTERMSIG(wstatus) | 如果 WIFSIGNALED(status) 为真,则可以用该宏获得导致子进程终止的信号代码 |
| WIFSTOPPED(wstatus) | 如果当前子进程被暂停了,则返回真;否则返回假 |
| WSTOPSIG(wstatus) | 如果 WIFSTOPPED(status) 为真,则可以使用该宏获得导致子进程暂停的信号代码 |
3.2 waitpid
#include <sys/types.h>
#include <sys/wait.h>
pid_t waitpid(pid_t pid, int *wstatus, int options);功能:等待进程状态发生变化
从本质上讲,waitpid 和 wait 的作用是完全相同的,但 waitpid 多出了两个可以由用户控制的参数 pid 和 options
- pid — 用于指定对哪些子进程收尸。当 pid 取不同的值时,在这里有不同的意义
| 取值 | 含义 |
|---|---|
| pid > 0 | 只对进程 ID 等于 pid 的僵尸子进程收尸 |
| pid = -1 | 可对任何一个僵尸子进程收尸 |
| pid = 0 | 只对与父进程同一个进程组中的僵尸子进程收尸 |
| pid < -1 | 对某个指定进程组中的任何僵尸子进程收尸,这个进程组的 ID 等于 pid 的绝对值 |
- wstatus — 指针作为返回值,用来保存“被收尸”进程的一些退出状态。指针所指整型数表示了退出状态的信息,能够通过一些宏函数,从这个整型数中获取我们想要的退出状态信息
- options — 是一个位图,可以通过按位或来设置,如果不设置则置为 0 即可。最常用的选项是 WNOHANG,作用是即使没有可收尸的僵尸进程,它也会立即返回,此时 waitpid 不同于 wait,它变成了非阻塞的函数
- 当正常返回时,waitpid 返回被收尸子进程的 PID;如果设置了 WNOHANG,而 waitpid 没有发现已经退出的子进程,则返回 0;如果 waitpid 出错,则返回 -1
代码示例:在找质数的多进程版本上进行修改,需求是父进程需要负责收尸其子进程
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#define LEFT 30000000
#define RIGHT 30000200
int main(void) {
int i, j, mark;
pid_t pid;
for(i = LEFT; i <= RIGHT; i++) {
pid = fork(); // 对每个数,都创建一个子进程来判断其是不是质数
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) { // child,判断该数是否为质数
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("%d is a primer.\n", i);
// 子进程一定要在这退出!!!否则子进程会也会继续fork出孙进程......
exit(0);
}
}
int st;
for (i = LEFT; i <= RIGHT; i++) { // 父进程负责等待收尸201个子进程
wait(&st);
}
exit(0);
}3.3 应用:进程分配初探
试想一个问题,刚刚那个找质数的程序,需要我们创建 201 个进程去判断每个数是不是质数。那么如果有上百万的数需要我们判断呢?总不能创建上百万个进程吧?直接崩啦!
因此,我们需要严格限定创建的进程个数。假如我们限定我们只能创建 3 个进程去完成我们的任务,那么问题来了: 怎么合理分配这三个进程的任务?让这三个进程所承担的任务量相对来说均匀点儿
- 方案一:分块分配

这种分配方式不妥。因为这三个进程所需要判断的数字区间内,质数个数明显不一样!质数个数不同导致执行 IO 打印的次数不同,显然任务分配不够均匀
- 方案二:交叉分配

如图,如果把任务看成一张张扑克牌,交叉分配任务就像是轮流给人发牌那样分配任务。好像有了一点儿随机性,但是在该问题模型上也不太 OK。因为,始终有个进程拿到所需判断的数是三的倍数!这就意味那个进程拿到的数永远不可能是质数!这还随机个鬼诶?
- 方案三:池内算法
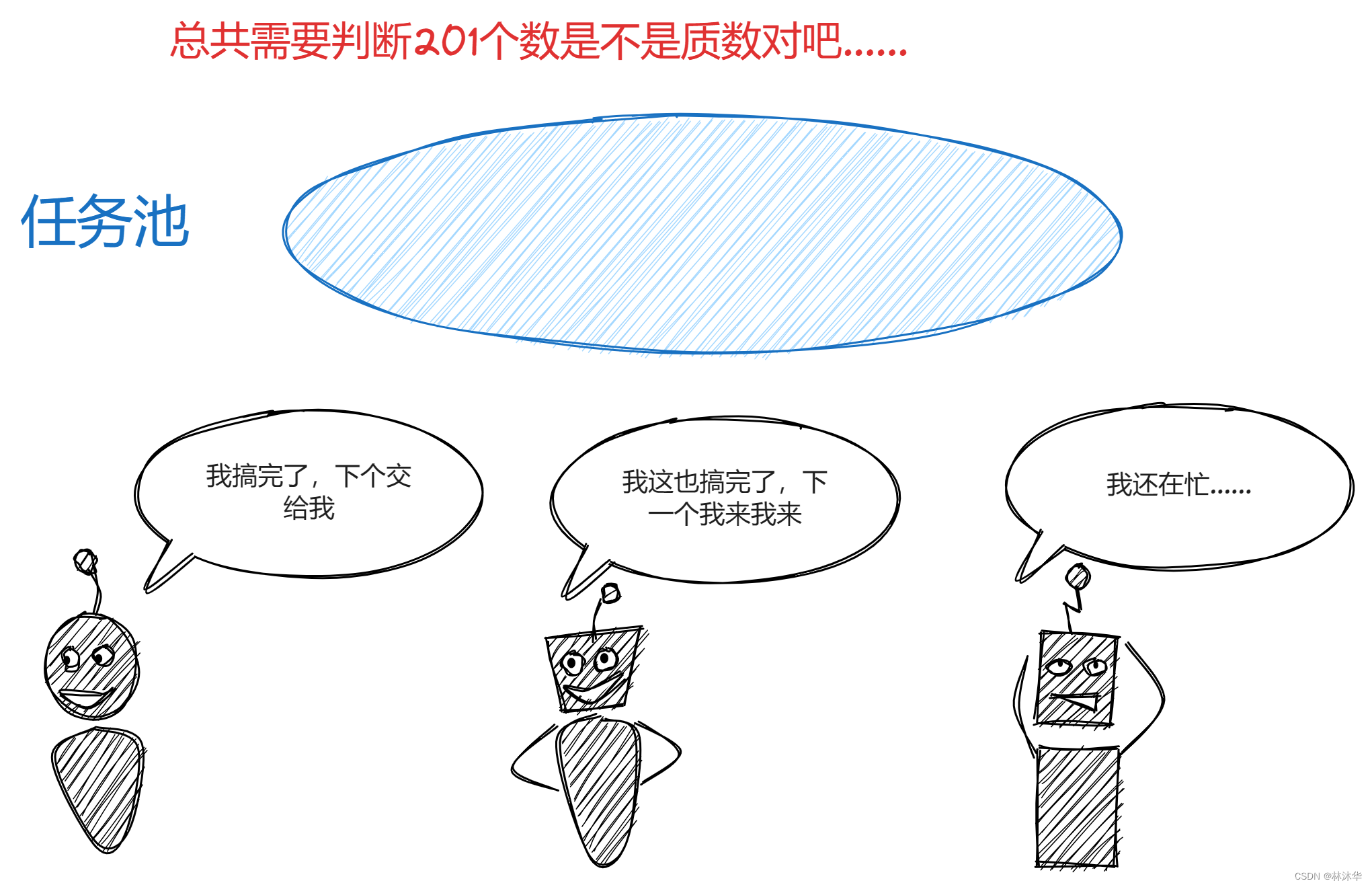
将一个个任务依次放进一个“池”内,然后这几个进程去“抢任务”,做的快的就能分配到更多的任务。这个算法还不错,有一定随机性
鉴于通常情况交叉分配比分块分配更好,而池内算法涉及竞争,我们在这里实现交叉分配
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
#define LEFT 30000000
#define RIGHT 30000200
#define N 3 // 所要求的进程个数
int main(void) {
int i, j, mark;
pid_t pid;
for (int n = 0; n < N; ++n) { // 创建N个进程
pid = fork();
if (pid < 0) { // 创建失败
perror("fork()");
// 其实还应该在这里“收尸”已经创建的子线程
exit(1);
}
if (pid == 0) {
for(i = LEFT + n; i <= RIGHT; i += N) {
mark = 1;
for(j = 2; j < i/2; j++) {
if(i % j == 0) {
mark = 0;
break;
}
}
if(mark)
printf("[%d]: %d is a primer.\n", n, i); // 这里用n给进程取名,便于显示是由哪个进程找到的质数
}
exit(0); // 子线程退出
}
}
for (int n = 0; n < N; ++n) { // 父线程负责等待收尸N个子线程
wait(NULL);
}
exit(0);
}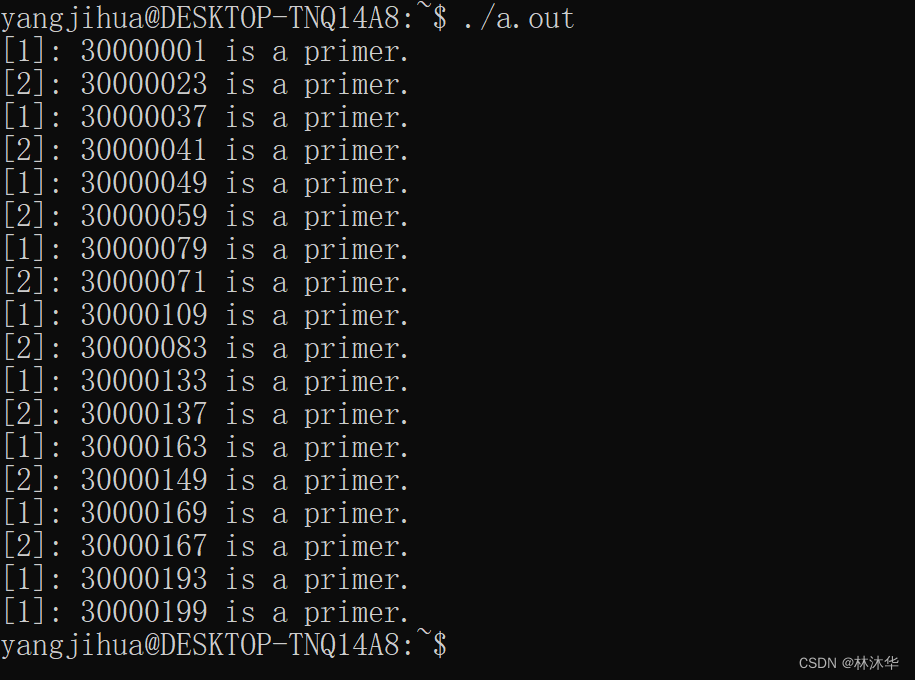
可以看出,找到的质数全是由进程 1 和进程 2 打印的,进程 0 拿到的数永远不可能是质数,因为进程 0 拿到的数永远都是三的倍数
四、exec 函数族
先关注一下 ps 命令下的进程树
都知道进程树表示了父子关系。不由自主想到一个问题:在这里,为什么 bash 进程的子进程是 ps,而不是 bash 呢?fork 出子进程和父进程不应该是一样的吗?
此外,如果 UNIX 系统内部只通过 fork 创建子进程,那么产生的所有子进程都做相同的工作,还有什么意义?
来,介绍一下 exec 函数族,或许我们就能够推测出 UNIX 的部分工作机制了
4.1 exec 简介
man 3 exec
#include <unistd.h>
extern char **environ;
int execl(const char *path, const char *arg, ...
/*, (char *) NULL */);
int execlp(const char *file, const char *arg, ...
/*, (char *) NULL */);
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);
int execv(const char *path, char *const argv[]);
int execvp(const char *file, char *const argv[]);
int execvpe(const char *file, char *const argv[], char *const envp[]);功能:执行一个文件
exec 函数族会用新的进程替换(replace)当前进程
细说替换:根据指定的文件名或目录名找到可执行文件,并用它来取代原调用进程的数据段、代码段和堆栈段,在执行完之后,原调用进程的内容除了进程号外,其他全部被新程序的内容替换了,新程序从其 main 函数开始执行。因为调用 exec 并不创建新进程,所以前后的进程 ID 并未改变
宏观上了解了这个函数族的功能,接下来介绍一下这些函数具体功能:
妈耶,这么多函数名字??怎么记呢?我们注意到这些函数名都是以 "exec" 开头的,后面跟着不同后缀而已。我们搞清楚这些后缀的含义就好
- l:以可变参数形式传入参数列表
- v:以 vector 形式传入参数列表
- p:可在 $PATH 中查找可执行程序名
- e:可指定 envp 环境列表作为新的环境变量
4.1.1 execl
int execl(const char *path, const char *arg, ...
/*, (char *) NULL */);- path - 指定可执行文件完整路径
- arg - arg0
- ... - 可视为 arg1、arg2、...、argn、NULL,其中,arg0、arg1、...、argn 共同描述了一个由字符串组成的列表,这个列表中的内容用于填充可执行文件内 main 的 argv 所指向的数组。argn 后要跟上一个 char* 类型的 NULL 结尾表示列表结束
4.1.2 execlp
int execlp(const char *file, const char *arg, ...
/*, (char *) NULL */);- file - 指定可执行文件完整路径或文件名,如果参数 file 中包含 /,则将其视为完整路径;否则将其视为文件名,并在环境列表中找到 KEY 为 PATH 的环境变量,在其值所指定的各目录中搜寻可执行文件
- arg - arg0
- ... - 可视为 arg1、arg2、...、argn、NULL,其中,arg0、arg1、...、argn 共同描述了一个由字符串组成的列表,这个列表中的内容用于填充可执行文件内 main 的 argv 所指向的数组。argn 后要跟上一个 char* 类型的 NULL 结尾表示列表结束
4.1.3 execle
int execle(const char *path, const char *arg, ...
/*, (char *) NULL, char * const envp[] */);- path - 指定可执行文件完整路径
- arg - arg0
- ... - 可视为 arg1、arg2、...、argn、NULL、envp,其中,arg0、arg1、...、argn 共同描述了一个由字符串组成的列表,这个列表中的内容用于填充可执行文件内 main 的 argv 所指向的数组。argn 后要跟上一个 char* 类型的 NULL 结尾表示列表结束。在列表结束后,应该传递一个 envp,指向字符串数组,用来表示新的环境列表
4.1.4 execv
- 同 execl,只不过将 execl 中的 arg0、arg1、...、argn、NULL 装进一个数组传递给 execv
4.1.5 execvp
- 同 execlp,只不过将 execlp 中的 arg0、arg1、...、argn、NULL 装进一个数组传递给 execvp
4.1.6 execve
- 同 execle,只不过将 execle 中的 arg0、arg1、...、argn、NULL 装进一个数组传递给 execve
4.2 代码示例1
用 date 进程替换当前进程
首先需要查看 date 命令可执行文件所在的路径

然后开炫
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
extern char ** environ;
/*
* 用date进程替换当前进程
*/
int main() {
puts("Begin!\n");
// execl("/bin/date", "date", "+%s", NULL); // date +%s
// execlp("date", "date", NULL); // date
execle("/bin/date", "date", "+%F", NULL, environ); // date +%F
// 其中"date""+%F"分别代表着可执行文件date中的main函数中的argv[0]、argv[1]
// 想保持原进程环境变量,最后一个参数传入指向字符串数组的指针environ即可
// 如果成功,该进程就被替换成其他进程了,永远不会执行到这里
// 执行到这里说明已经失败了
perror("exec()");
exit(1);
puts("End!\n");
exit(0);
}
结果显示:在执行 execle 后,进程被替换为了 date +%F,从而原进程后面需要打印的字符串不再显示
假如我们重定向到某个文件......

嗯?"Begin!" 为什么不见了?为什么和在终端打印不一样?
问题多多,为什么捏?给几个提示 :
- 终端和文件具有不同的标准I/O缓冲类别
- replace
下面开始解答:
终端的缓冲类别默认是行缓冲,也就是说遇到换行符就会刷新缓冲区,因此,在 printf 中遇到换行符了,就能立马将缓冲区中的内容打印到终端显示上。
而文件的缓冲类别默认是全缓冲,也就是说在填满标准 I/O 缓冲区后,才对缓冲区进行冲洗。这样一来,printf 中即使遇到了换行符,因为缓冲区还没满,因此不会刷新。那么在即将执行 execle 的时候,希望打印出来的那几个字符仍然驻留在原进程缓冲区,尚未被打印出来。接下来,execle 会用一个新进程 replace 当前进程。别忘了,此时当前进程的缓冲区也一并被替换了!新进程的缓冲区是空的,没有任何待打印字符,这样一来希望打印的字符就永远驻留在原进程的缓冲区,打印不出来了。
怎么解决这种问题?在 execle 之前,使用 fflush(NULL) 刷新所有已打开的流
4.3 代码示例2
刚才那个代码,测试了一下 exec 函数族的用法。但是没啥实际意义。毕竟我开个新进程,结果啥也不干直接摇身一变成了其他进程,那我何不直接调用那个进程?中间绕这么大个弯,血呆啊血呆!
但是其实如果综合 exec 函数族和之前讲的 fork、wait,就能写出有实际意义的代码了!
通过 fork 创建一个子进程,然后将子进程替换为别的进程......
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <wait.h>
int main() {
puts("Begin!\n");
fflush(NULL);
pid_t pid = fork();
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // 子进程
execl("/bin/date", "date", "+%s", NULL);
}
else { // 父进程等待子进程结束,并为其收尸
wait(NULL);
}
puts("End!\n");
exit(0);
}上述虽然只是个小小的 demo,但其实整个 UNIX 的世界都是这么实现的! 即先 fork,后 exec
补充:关于 argv[0], 其实很多时候我们并不关心,因为决定一个命令的行为的各种选项往往是看 argv[0] 之后的内容,argv[0] 仅仅代表名称。而刚刚介绍说过,exec 函数族需要传递参数,用于填充可执行文件内 main 的 argv 所指向的数组,其实 argv[0] 的部分随便填充都可以,代码示意如下
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <wait.h>
int main() {
puts("Begin!\n");
fflush(NULL);
pid_t pid = fork();
if (pid < 0) {
perror("fork()");
exit(1);
}
else if (pid == 0) { // 子进程
execl("/bin/sleep", "fakeName", "100", NULL); // 通过which sleep查看sleep命令可执行文件所在路径
}
else { // 父进程等待子进程结束,并为其收尸
wait(NULL);
}
puts("End!\n");
exit(0);
}上述代码中,我们通过 execl 让 sleep 进程替换子进程,然后用 "fakeName" 传入 sleep 进程中 main 的 argv[0],可以看到如下结果
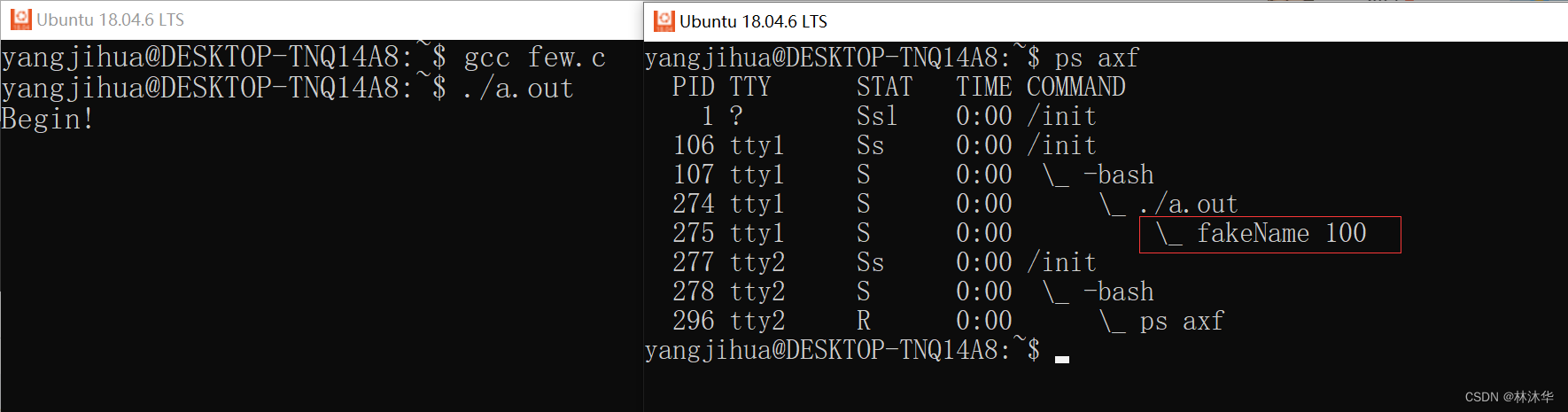
不影响 sleep 进程运行,但是在进程树里面进程的名字改变了。他明明是个 sleep,却伪装成了 fakeName
4.4 代码示例3:shell 的实现
接下来给个综合应用,我们来实现我们自己的 shell
实现之前,我们要先区分一下内部命令和外部命令,毕竟 shell 和命令息息相关
- 内部命令指的是集成在 shell 里面的命令,属于 shell 的一部分。这些命令由 shell 程序识别并在shell程序内部完成运行,通常在 linux 系统加载运行时 shell 就被加载并驻留在系统内存中,比如cd命令等,这些命令在磁盘上看不见
- 外部命令是 linux 系统中的实用程序部分,因为实用程序的功能通常都比较强大,所以其包含的程序量也会很大,在系统加载时并不随系统一起被加载到内存中,而是在需要时才将其调用内存。通常外部命令的实体并不包含在 shell 中,但是其命令执行过程是由 shell 程序控制的。shell 程序管理外部命令执行的路径查找(PATH环境变量中)、加载存放,并控制命令的执行。这些命令的二进制可执行文件在磁盘上可见
通过 which 查看命令所在路径;通过 type 查看命令是内部还是外部命令
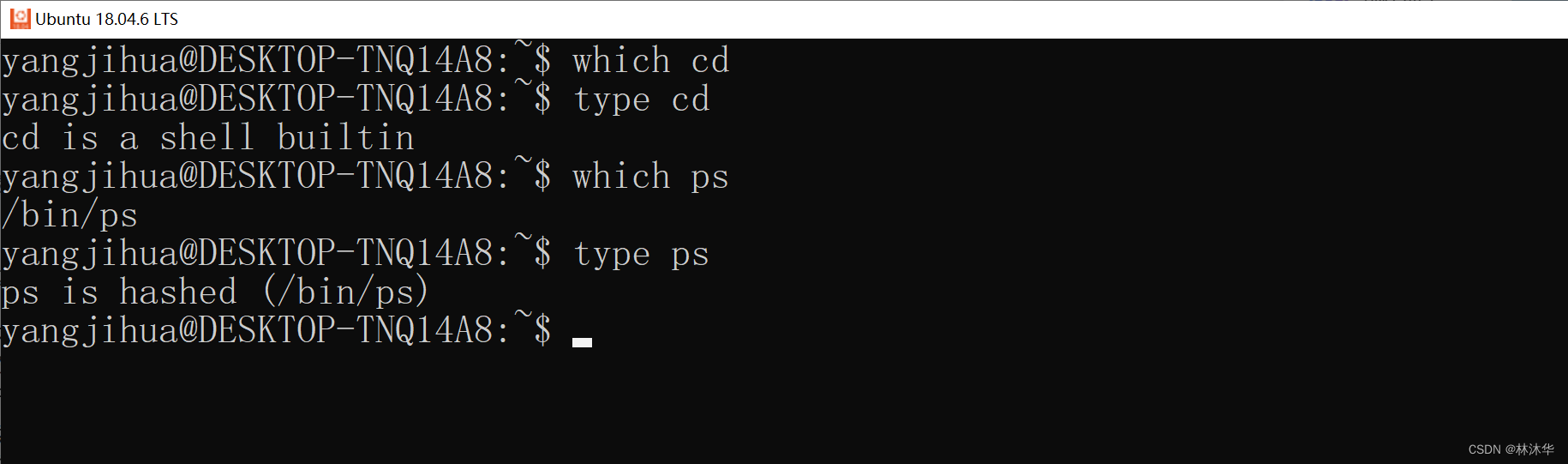
可以看出,cd 是内部命令,在磁盘上不存在路径;ps 是外部命令,磁盘上可执行文件存放位置为 /bin/ps
shell 伪代码示例
int main(void) {
// 死循环,shell不断接收用户命令
while(1) {
// 终端提示符
prompt();
// 获取命令
getline();
// 解析命令
parse();
if(内部命令) {
// ...
} else { // 外部命令
fork();
if(pid < 0) {
// 异常处理...
}
if(pid == 0) { // 子进程
exec(); // 将子进程替换为待执行程序
// 异常处理...
}
if(pid > 0) { // shell父进程
wait(NULL); // 等待子进程结束
}
}
}
exit(0);
}
代码实现,暂不处理内部命令
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#include <glob.h>
#include <wait.h>
// 分隔符:空 制表符 换行符
#define DELIMS " \t\n"
// 用于存放命令的结构体
struct cmd_st { // 为什么要封装成结构体?为了便于后续开发,可能未来还会增加针对命令的描述信息,这些信息可以扔进结构体
glob_t globres;
};
static void prompt(void) {
printf("mysh$ ");
}
static void parse(char *line, struct cmd_st *res) {
char *tok; // 用于存放分隔出来的子串
int i = 0;
while(1) {
tok = strsep(&line, DELIMS); // strsep用于将字符串line,根据分隔符DELIMS,分隔成一个个子串
// 分割完毕
if(tok == NULL)
break;
if(tok[0] == '\0') // 若两个分隔符连续,可能根据分隔符分隔出来的就是空串""
continue;
// 选项解释
// NOCHECK:不对pattern进行解析,直接返回pattern(这里是tok),相当于存储了命令行参数tok在glob_t中
// APPEND:以追加形式将tok存放在glob_t中,第一次时不追加,因为globres尚未初始化,需要系统来自己分配内存,因此乘上i(乘法优先于按位或)
glob(tok, GLOB_NOCHECK|GLOB_APPEND*i, NULL, &res->globres);
// 置为1,使得追加永远成立
i = 1;
}
}
int main(void) {
// getline的参数要初始化
char *linebuf = NULL; // 存放获取到的整行命令
size_t linebuf_size = 0;
struct cmd_st cmd; // 用于存放解析到的命令的子串
pid_t pid;
while(1) { // shell不断获取命令,是个死循环
// 终端提示符
prompt();
// getline的参数:前两个参数是用于返回的
if(getline(&linebuf, &linebuf_size, stdin) < 0) {
break;
}
// 解析一行命令
parse(linebuf, &cmd);
if(0) { // 内部命令,暂不做实现,永false
} else { // 外部命令
pid = fork();
if(pid < 0) {
perror("fork()");
exit(1);
}
if(pid == 0) {
execvp(cmd.globres.gl_pathv[0], cmd.globres.gl_pathv); // 第一个参数希望能传入命令名字,故用execvp
perror("execvp()");
exit(1);
} else {
wait(NULL); // 父进程等待收尸
}
}
}
exit(0);
}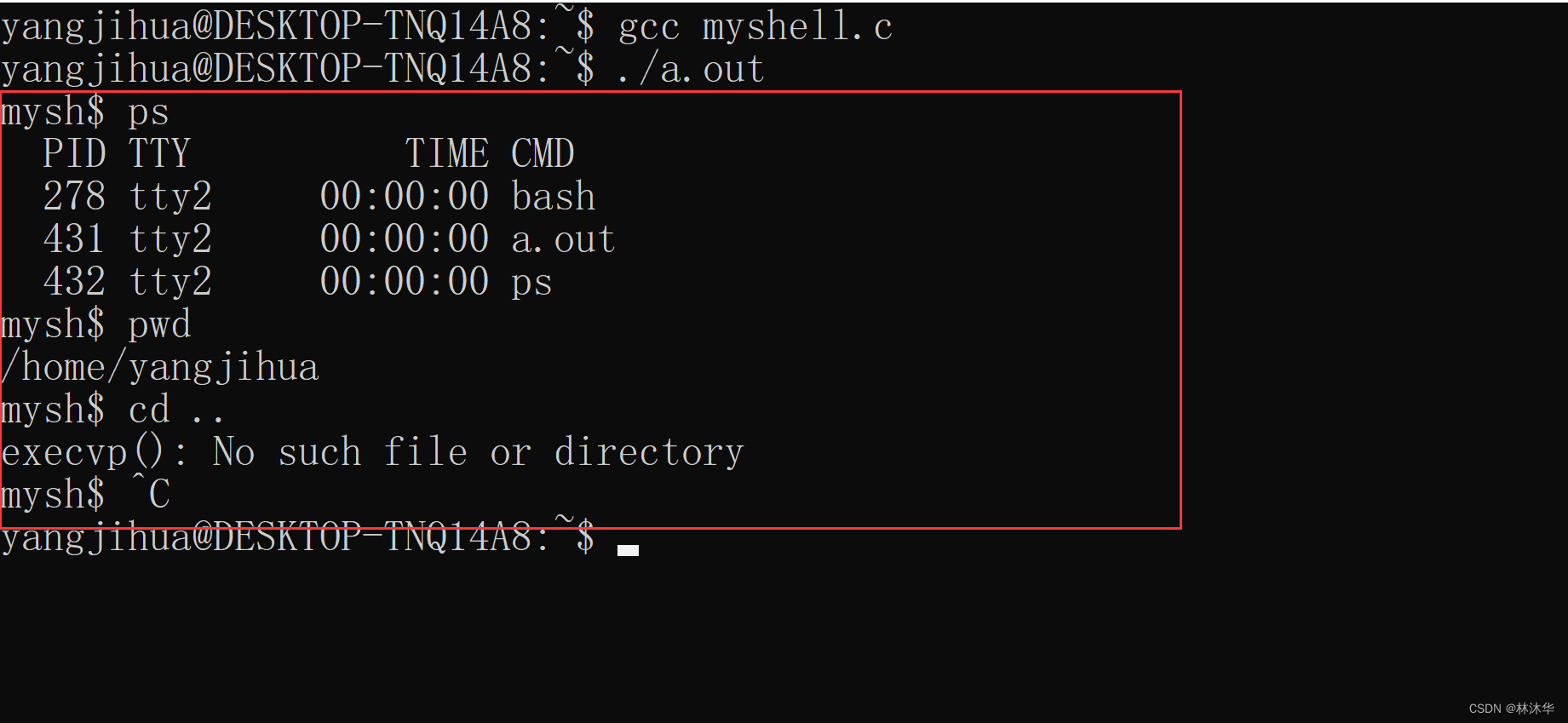
可以看到,我们的 shell 能够实现外部命令的解析
接下来,我们尝试看看这个 shell 是不是真的能派上用场
- 首先切换成 root 用户,修改 /etc/passwd 文件所记录的信息

- 然后,切换回 yangjihua 用户,见证奇迹!

五、用户权限及组权限
5.1 简介
在文件系统下,曾经介绍过权限相关的知识
搬出经典老图:
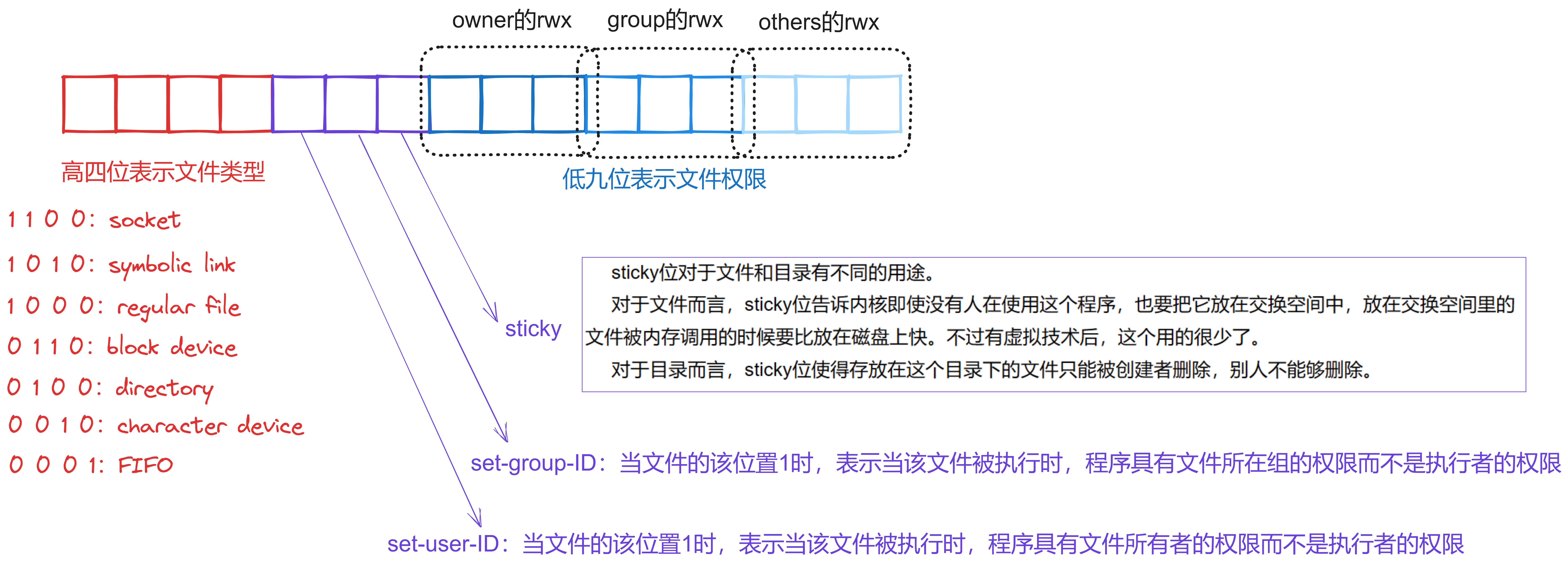
上面这张图介绍了文件属性当中的文件权限相关位。现在我们需要将用户、组的相关知识融入进去
查看文件的权限、拥有者、所属组:ls -l

下面以一个小例子引出我们的知识点
我们的目标是:修改当前用户 yangjihua 的密码
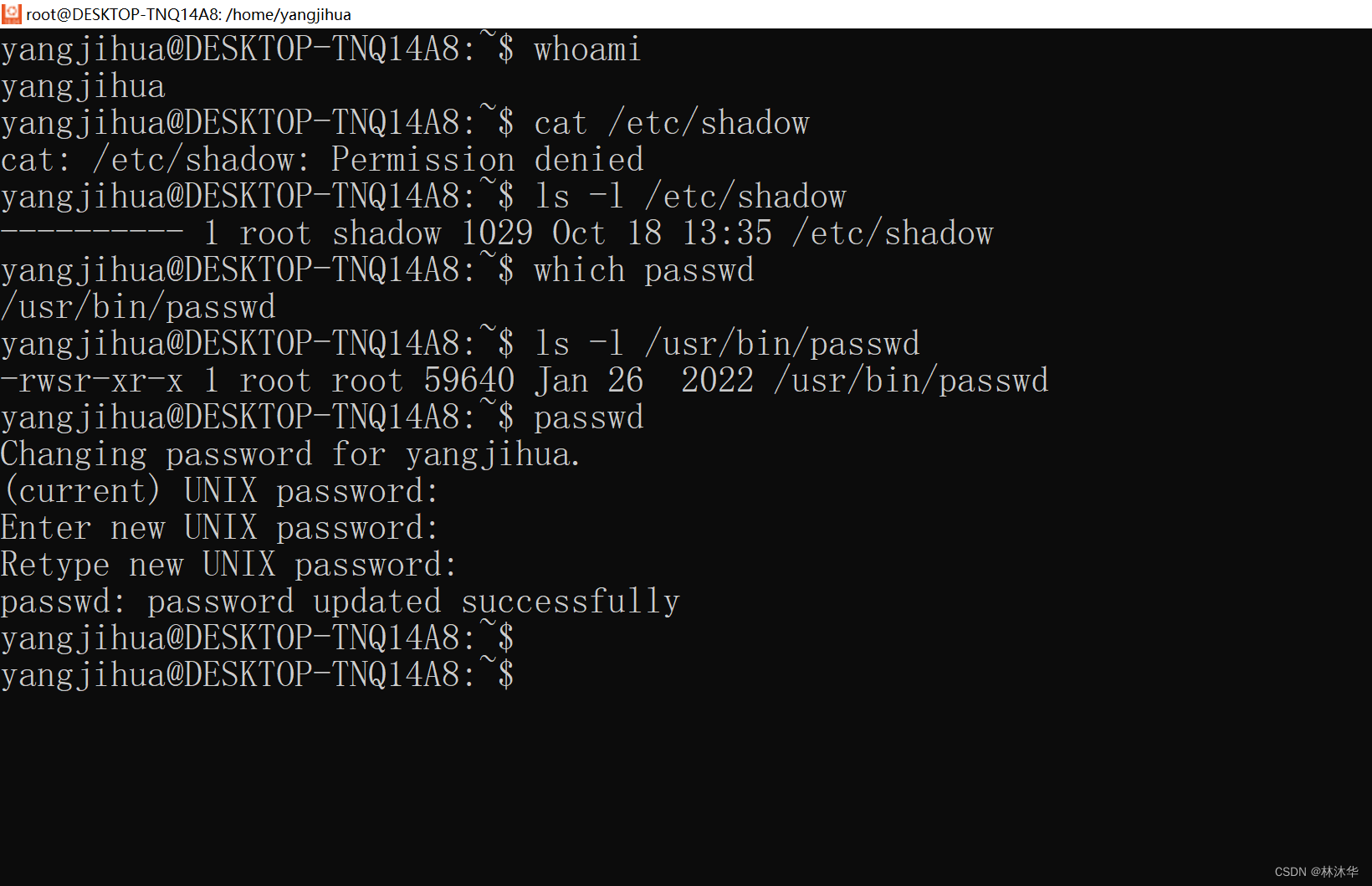
- 一个比较直观的想法是,要修改密码,密码不是储存在 /etc/shadow 嘛,我直接去那里修改!
yangjihua@DESKTOP-TNQ14A8:~$ whoami
yangjihua
yangjihua@DESKTOP-TNQ14A8:~$ cat /etc/shadow
cat: /etc/shadow: Permission denied- 呀??甚至没办法 cat,更别提修改了......,看了看 shadow 文件的权限:---------,表示 shadow 文件的非 root 拥有者、文件所属组、其他用户都没办法对该文件有任何操作。看来我不能修改这个文件内容情有可原。等等?我自己不能修改我自己的密码????
yangjihua@DESKTOP-TNQ14A8:~$ ls -l /etc/shadow
---------- 1 root shadow 1029 Oct 18 13:35 /etc/shadow- 显然 UNIX 不可能设计出如此违背逻辑的机制,有个命令可以实现密码的修改:passwd,看了看 passwd 命令的权限信息:rwsr-xr-x,拥有者是 root,所属组是 root;我作为一个其他用户,给我分配的权限是 r-x,嗯,我也能执行这个命令。那么执行,改密成功!
yangjihua@DESKTOP-TNQ14A8:~$ which passwd
/usr/bin/passwd
yangjihua@DESKTOP-TNQ14A8:~$ ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root 59640 Jan 26 2022 /usr/bin/passwd
yangjihua@DESKTOP-TNQ14A8:~$ passwd
Changing password for yangjihua.
(current) UNIX password:
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully在上面例子中,改密成功,说明成功修改了 /etc/shadow 中的内容,而 /etc/shadow 中的内容只有 root 用户有权修改。这说明在我通过命令 passwd 改密的过程中,一定发生了提权,从而让我有了 root 用户的权限!
接下来开始说明执行 passwd 命令过程中,权限提升的详细逻辑
在执行某个命令时,是带着用户的身份:uid 和 gid 去执行的
我们现在关注进程运行过程中的用户身份信息
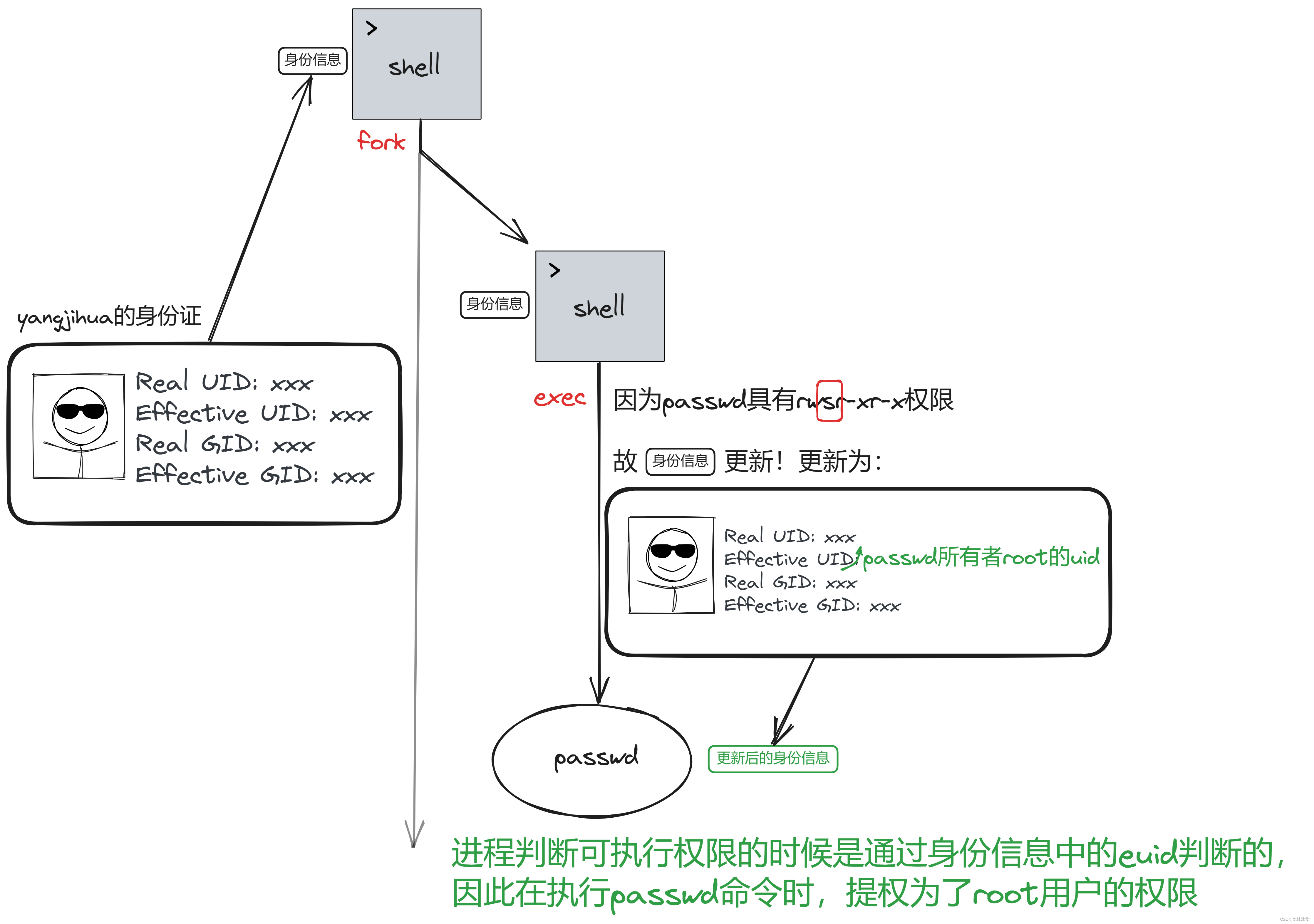
内核为每个进程维护的信息包括两个 UID 值(和两个 GID 值,是对应关系,暂略。有的内核则提供了三个),这两个 UID 分别是:
- RUID:(Real UID,实际用户 ID),我们当前以哪个用户登录,我们运行程序产生进程的 RUID就是这个用户的 UID
- EUID:(Effective UID,有效用户 ID),指当前进程实际以哪个 UID 来运行。一般情况下 EUID等于 RUID;但如果进程对应的可执行文件具有 SUID 权限(也就是 rwsr-xr-x 中的 s),那么进程的 EUID 是该文件所属的 UID。判断权限看的就是这个 EUID
补充:特殊权限(对照经典老图)
SUID:在拥有者的 x 位以 s 标识,全称 Set-user-ID
SGID:在所属组的 x 位以 s 标识,全称 Set-Group-ID
5.2 相关函数
5.2.1 getuid、geteuid
#include <unistd.h>
#include <sys/types.h>
uid_t getuid(void);
uid_t geteuid(void);功能:获取进程运行过程中用户身份信息中的 RUID 和 EUID
5.2.2 getgid、getegid
#include <unistd.h>
#include <sys/types.h>
gid_t getgid(void);
gid_t getegid(void);功能:获取进程运行过程中用户身份信息中的 RGID 和 EGID
5.2.3 setuid
#include <sys/types.h>
#include <unistd.h>
int setuid(uid_t uid);功能:设置进程运行过程中用户身份信息中的 RUID 和 EUID
- 若进程具有超级用户权限,则将实际用户 ID、有效用户 ID 均设置为 uid
- 否则,当 uid 为实际用户 ID,则将有效用户 ID 设置为 uid;当 uid 不为实际用户 ID,调用失败并置 errno
5.2.4 setgid
#include <sys/types.h>
#include <unistd.h>
int setgid(gid_t gid);功能:设置进程运行过程中用户身份信息中的 RGID 和 EGID;权限不够则仅设置 EGID
- 若进程具有超级用户权限,则将实际组 ID、有效组 ID 均设置为 gid
- 否则,当 gid 为实际组 ID,则将有效组 ID 设置为 gid;当 gid 不为实际组 ID,调用失败并置 errno
5.2.5 seteuid、setegid
#include <sys/types.h>
#include <unistd.h>
int seteuid(uid_t euid);
int setegid(gid_t egid);功能:设置进程运行过程中用户身份信息中的 EUID 和 EGID
- 若进程具有超级用户权限,则可设置 EUID 或 EGID 为任意值
- 否则,只能设置 EUID 为当前 RUID 或 EUID;设置 EGID 为当前 RGID 或 EGID
5.2.6 setreuid、setregid
#include <sys/types.h>
#include <unistd.h>
int setreuid(uid_t ruid, uid_t euid);
int setregid(gid_t rgid, gid_t egid);功能:原子交换 RUID 和 EUID;原子交换 RGID 和 EGID
5.3 代码示例
sudo 提权命令的简单实现
功能类似如下:

实现如下:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <wait.h>
int main(int argc, char ** argv) {
if (argc < 2)
{
fprintf(stderr, "Usage...\n");
exit(1);
}
pid_t pid = fork();
if (pid < 0) {
perror("fork()");
exit(1);
} else if (pid == 0)
{
execvp(argv[1], argv + 1);
perror("execvp()");
exit(1);
} else {
wait(NULL);
}
exit(0);
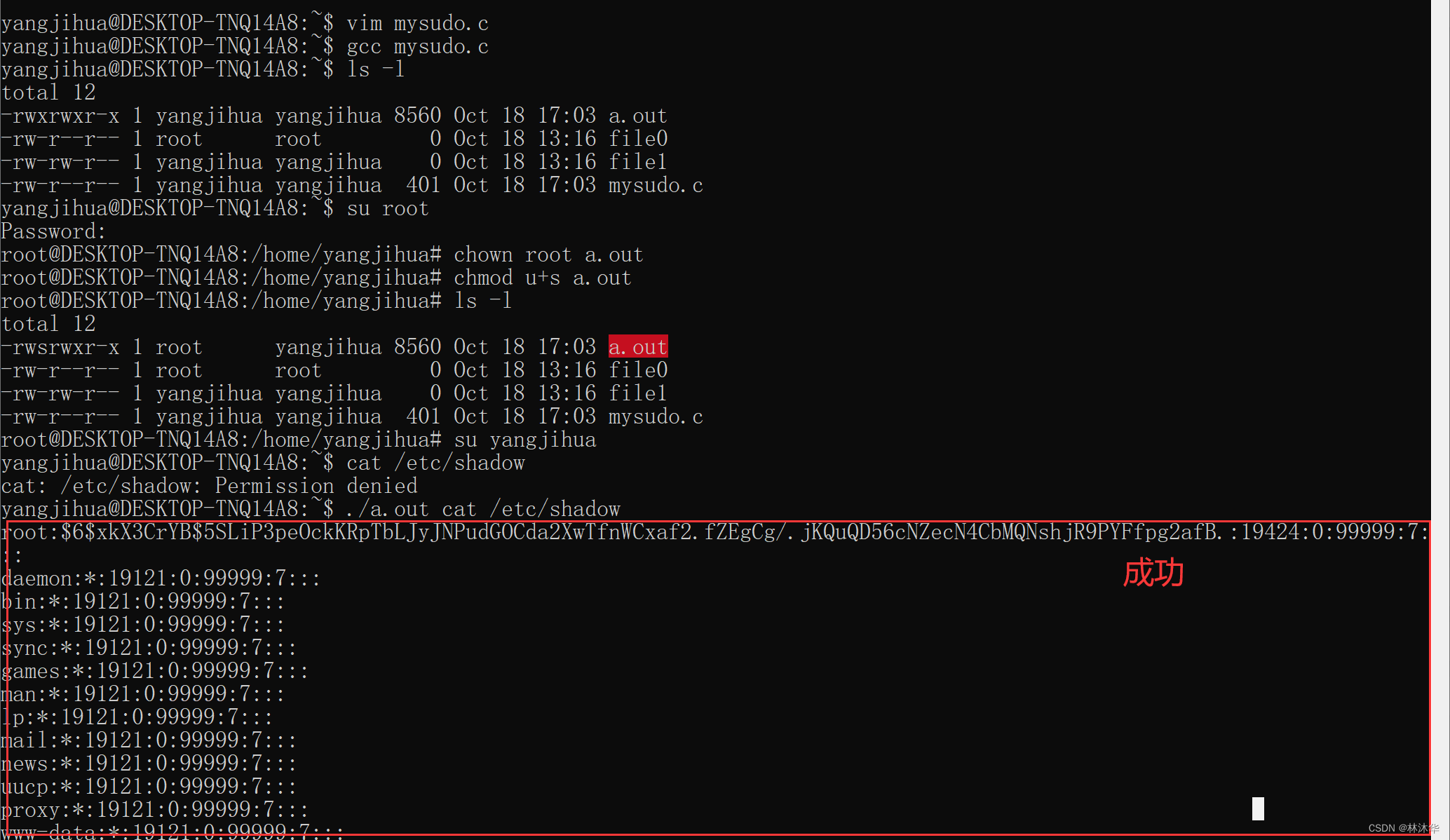
}- 下面首先进入 root 用户,将 a.out 的所有者改为 root
- 然后利用 chmod u+s 设置 a.out 的 SUID 特殊权限位,使 a.out 执行过程中具有所有者 root 的权限
- 最后切换回普通用户测试
六、什么叫解释器文件
解释器文件也叫脚本文件。脚本文件包括:shell 脚本,python 脚本等
脚本文件的后缀可任意设置,但一般来说 shell 脚本的后缀名为 .sh,python 脚本的后缀名为 .py
脚本文件的执行过程:当在 linux 系统的 shell 命令行上执行一个可执行文件时,系统会 fork 一个子进程,在子进程中内核会首先将该文件当做是二进制机器文件来执行,但是内核发现该文件不是机器文件(看到第一行为#!)后就会返回一个错误信息,收到错误信息后进程会将该文件看做是一个脚本,然后扫描该文件的第一行,获取解释器程序(本质上就是可执行文件)的名字,然后执行 exec 该解释器,并将该脚本文件当做解释器的一个参数,然后开始由解释器程序从头扫描整个脚本文件,执行每条语句(如果指定解释器为 shell,会跳过第一条语句,因为 # 对于 shell 来说是注释),就算其中某条命令执行失败了也不会影响后续命令的执行
解释器文件的格式:
#!pathname [optional-argument]
内容...- pathname:一般是绝对路径(它不会使用 $PATH 做路径搜索),对这个文件识别是由内核做为 exec 系统调用处理的
- optional-argument:相当于提供给 exec 的参数
内核 exec 执行的并不是脚本文件,而是第一行 pathname 指定的文件。一定要将脚本文件(本质是一个文本文件,以 #! 开头)和解释器(由 pathname 指定)区分开
6.1 示例1
以普通用户创建脚本 t.sh:
#!/bin/bash
ls
whoami
cat /etc/shadow
ps这个文件没有执行权限,需要添加:
yangjihua@DESKTOP-TNQ14A8:~$ vim t.sh
yangjihua@DESKTOP-TNQ14A8:~$ ls -l t.sh
-rw-rw-r-- 1 yangjihua yangjihua 42 Oct 18 21:34 t.sh
yangjihua@DESKTOP-TNQ14A8:~$ chmod u+x t.sh
yangjihua@DESKTOP-TNQ14A8:~$ ls -l t.sh
-rwxrw-r-- 1 yangjihua yangjihua 42 Oct 18 21:34 t.sh
yangjihua@DESKTOP-TNQ14A8:~$然后执行!
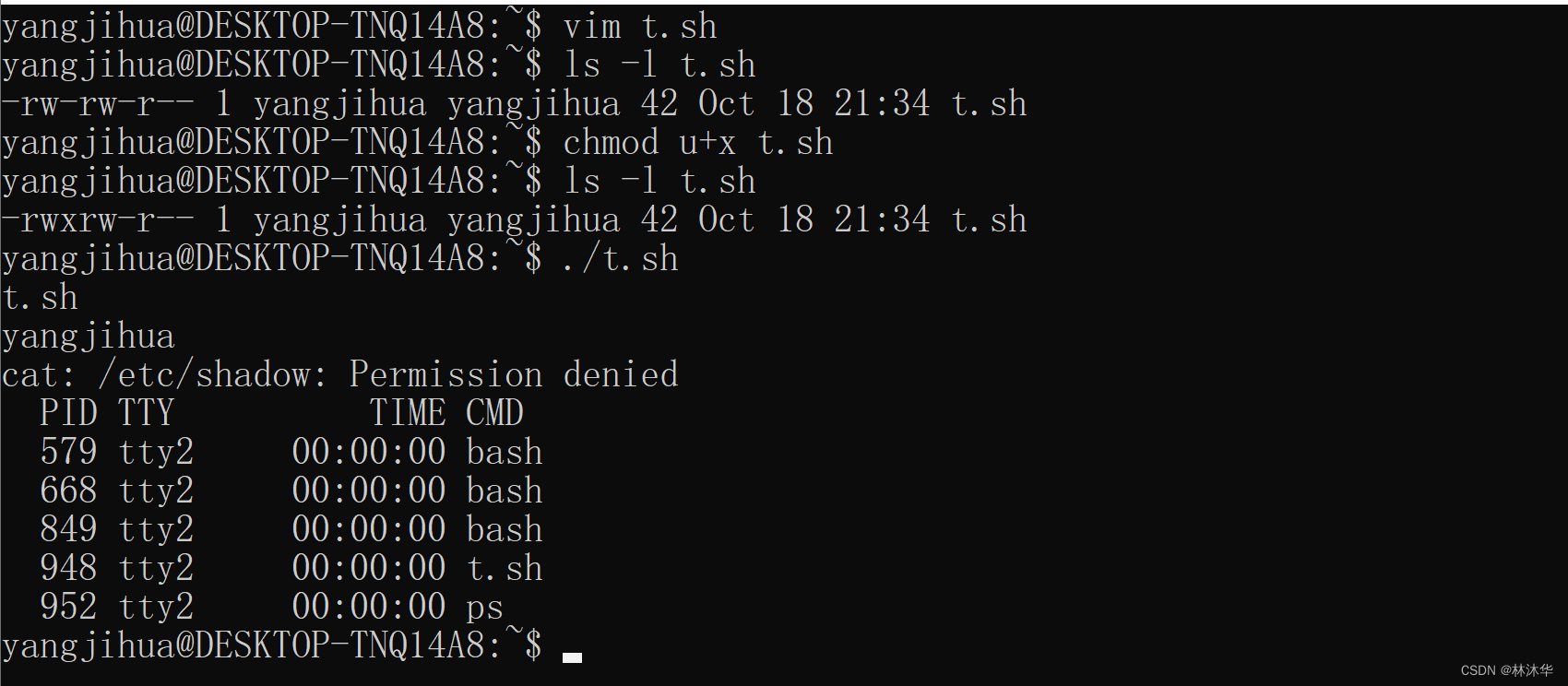
- shell执行 ./t.sh 时,fork 了一个子进程,该进程看到该文件为脚本文件,于是读取第一行,得到解释器程序的 pathname,并 exec 该解释器程序(/bin/bash),然后通过该解释器程序重新执行这个脚本文件
- 可以看出 bash 跳过了第一句,因为 # 在 bash 程序中被看成了注释,cat 命令没有权限,但后面的 ps 命令仍然继续执行
6.2 示例2
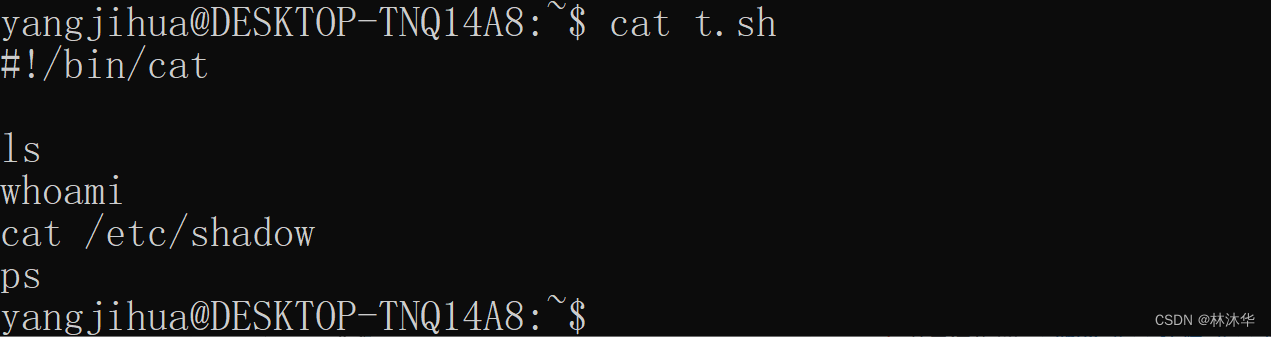
仅更改上述 t.sh 中第一行的内容:
#!/bin/cat
ls
whoami
cat /etc/shadow
ps然后执行!

发现这次是打印了该脚本文件的所有内容。过程同上,只是这次子进程 exec 的程序为 /bin/cat 程序。执行该脚本等同于:
七、system 函数
man system
#include <stdlib.h>
int system(const char *command);功能: 执行一句 shell 命令
The system() library function uses fork(2) to create a child process that executes the shell command specified in command using execl(3) as follows:
execl("/bin/sh", "sh", "-c", command, (char *) 0);
system() returns after the command has been completed.
可以看作是 fork、execl、wait 的简单封装
八、进程会计
man acct
#include <unistd.h>
int acct(const char *filename);功能:记录终止进程的相关属性信息
- filename — 如果 filename 为现有文件,则开启会计功能,每个进程的相关属性信息都会在其终止时追加到 filename 中。如果参数为 NULL,则会关闭会计功能
- 成功返回 0;失败返回 -1 并设置 errno
- 该函数不可移植,是个方言
有哪些终止进程的相关属性信息可能会被追加呢?
man 5 acct
struct acct {
char ac_flag; /* Accounting flags */
u_int16_t ac_uid; /* Accounting user ID */
u_int16_t ac_gid; /* Accounting group ID */
u_int16_t ac_tty; /* Controlling terminal */
u_int32_t ac_btime; /* Process creation time (seconds since the Epoch) */
comp_t ac_utime; /* User CPU time */
comp_t ac_stime; /* System CPU time */
comp_t ac_etime; /* Elapsed time */
comp_t ac_mem; /* Average memory usage (kB) */
comp_t ac_io; /* Characters transferred (unused) */
comp_t ac_rw; /* Blocks read or written (unused) */
comp_t ac_minflt; /* Minor page faults */
comp_t ac_majflt; /* Major page faults */
comp_t ac_swaps; /* Number of swaps (unused) */
u_int32_t ac_exitcode; /* Process termination status (see wait(2)) */
char ac_comm[ACCT_COMM+1];
/* Command name (basename of last executed command; null-terminated) */
char ac_pad[X]; /* padding bytes */
};九、进程时间
man times
#include <sys/times.h>
clock_t times(struct tms *buf);功能:获取进程时间
- buf — 指向结构体 struct tms,调用该函数后,会将当前进程的时间有关信息填充到 buf 所指向的结构体中
- 成功则返回自过去任意时刻起已过去的时钟滴答数;失败则返回 -1 并设置 errno
buf 所指向的结构体中,有哪些信息会被填充呢?
struct tms {
clock_t tms_utime; /* user time */
clock_t tms_stime; /* system time */
clock_t tms_cutime; /* user time of children */
clock_t tms_cstime; /* system time of children */
};注意,这部分的 clock_t 是新的用于记时的类型,其值的单位为时钟滴答(clock tick),时钟滴答是一种更加细粒度的记时单位,每秒钟包含多少的时钟滴答数可以通过如下方式获取:
sysconf(_SC_CLK_TCK);十、守护进程
10.1 简介
守护进程是运行在后台的一种特殊进程,它独立于控制终端并且可以周期性的执行某种任务或者等待处理某些发生的事件
守护进程常常在系统引导装入时启动,在系统关闭时终止
守护进程是非常有用的进程,在 Linux 当中大多数服务器用的就是守护进程。守护进程完成很多系统的任务。当 Linux 系统启动的时候,会启动很多系统服务。这些进程服务是没有终端的,也就是说就算把终端关闭了,这些系统服务也是不会停止的
10.2 终端、会话与进程组
一图介绍这三者之间的关系

终端:
- 终端就是笨设备,啥也不会,仅用于传递交互指令至会话、显示会话返回的结果
会话:
- 每打开一个控制终端,或者在用户登录时,系统就会创建新会话
- 会话是有一个或者多个进程组组成的集合
- 每个会话有一个标识 SID,这个 SID 和该会话的 leader 进程的 PID 相同
- 在该会话中允许的第一个进程称作会话首进程,通常这个首进程就是 shell
- 通常,一个会话开始于用户登录,终止于用户退出,在此期间该用户运行的所有进程都属于这个会话
进程组:
- 进程组是由一个进程或者多个进程组成的集合
- 每个进程组有一个标识 PGID,这个 PGID 和该进程组的组长进程的 PID 相同
- 通常进程组与同一作业相关联,可以收到同一终端的信号:这个信号可以使同一个进程组中的所有进程终止,停止或者继续运行
- 一个进程产生子进程,则子进程和父进程是同组进程。此时,父进程是进程组的组长
- 只要在某个进程组中还有一个进程存在,则该进程组就存在
- 进程组分为前台进程组和后台进程组。最多存在一个前台进程组,前台进程组能够使用标准输入输出;后台进程组不能够使用标准输入输出
10.3 创建守护进程
10.3.1 setsid
man 2 setsid
#include <sys/types.h>
#include <unistd.h>
pid_t setsid(void);功能:创建新会话并设置进程组 ID (通俗点儿就是让子进程变成守护进程)
- 当非组长进程(子进程)调用该函数,会创建一个新会话,并向该会话添加一个新进程组,然后将该进程设置为新会话的 leader 及新进程组的组长,并使其脱离控制终端
- 此时该子进程摇身一变成了守护进程,其原来的父进程无需 wait 对该守护进程收尸,可以直接退出
- 成功返回新会话的 SID(也就是新进程组的 PGID,也就是该守护进程的 PID);失败返回 -1 并设置 errno
上述创建出来的守护进程有什么特征?
- 守护进程脱离控制终端,故 tty 字段为 ?
- 守护进程是新会话的 leader 及新进程组的组长,故守护进程的 PID = PGID = SID
- 守护进程的原父进程退出了,故它由 init 接管,因此守护进程的父进程标识 PPID = 1
因此,我们可以通过 ps axj 命令看到 UNIX 正在运行的守护进程

可以看出红框圈出来的都是守护进程,这几个进程同时满足上述几个特征
这里补充介绍一下字段含义:
- PPID:父进程的 PID
- PID:当前进程的 PID
- PGID:进程组标识
- SID:当前进程的会话标识符
- TTY:终端
- TPGID:进程组和终端的关系,-1 表示没有关系
- STAT:进程状态
- UID:启动(exec)该进程的用户的 UID
- TIME:进程执行到目前为止经历的时间
- COMMAND:启动该进程时的命令
10.3.2 getpgid、setpgid
#include <sys/types.h>
#include <unistd.h>
int setpgid(pid_t pid, pid_t pgid);
pid_t getpgid(pid_t pid);功能:setpgid 设置由 pid 所指定进程的进程组标识为 pgid;getpgid 获取由 pid 所指定进程的进程组标识
10.4 代码示例
我们希望创建一个守护进程,该进程不断往某个文件写入数字
详见注释
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define FILENAME "/tmp/out"
int daemonize() {
// 首先创建子进程
pid_t pid = fork();
if (pid < 0) {
perror("fork()");
return -1;
}
if (pid > 0) { // parent
exit(0); // 父进程不用等待子进程,直接退出
}
// child
int fd = open("/dev/null", O_RDWR);
if (fd < 0) {
perror("open()");
return -1;
}
// 脱离终端前,重定向与终端关联的描述符0 1 2
dup2(fd, 0);
dup2(fd, 1);
dup2(fd, 2);
if (fd > 2)
close(fd);
// 创建一个新会话,并向该会话添加一个新进程组,然后将该进程设置为新会话的 leader 及新进程组的组长,并使其脱离控制终端
setsid();
// 守护进程一直在当前路径运行,万一当前路径不在了......
// 因此最好将工作路径改成根目录,根目录一般会一直存在
chdir("/");
// 确定程序不会创建文件了,可以关掉umask
umask(0);
return 0;
}
int main() {
int state = daemonize(); // 通过该函数让该进程变为守护进程
if (state) // state非0,则报错退出
exit(1);
// 守护进程的任务:不断往一个文件中写入数字
FILE *fp = fopen(FILENAME, "w");
if (fp == NULL) {
perror("fopen()");
exit(1);
}
for (int i = 0;;++i) {
fprintf(fp, "%d\n", i);
fflush(fp);
sleep(10);
}
fclose(fp);
exit(0);
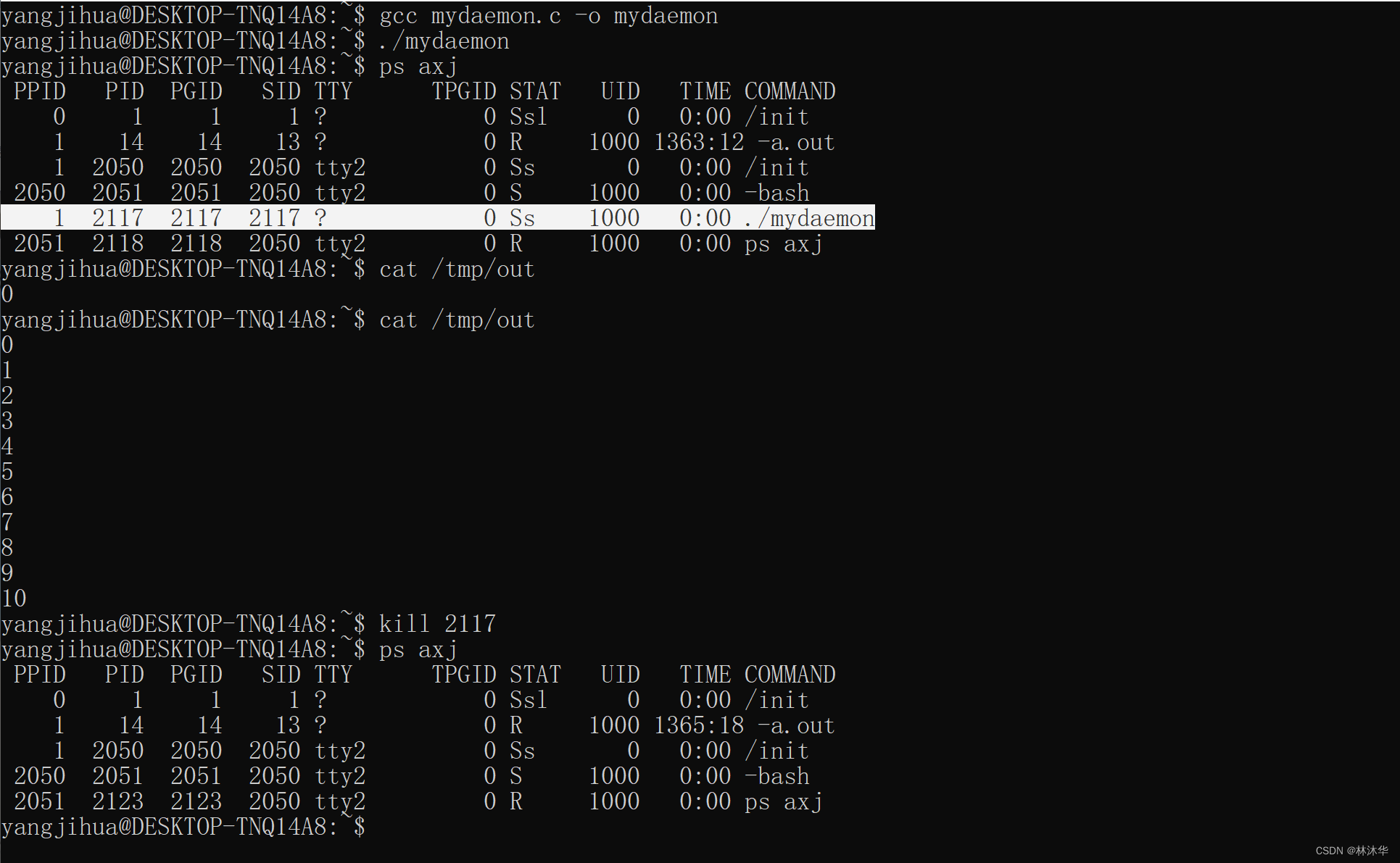
}可以看出,运行之后,出现了守护进程。其 PPID 为 1,PID = PGID = SID = 2117,能看到该进程不断往 /tmp/out 文件中写入数字。别忘了通过 kill 杀死守护进程!
补充一下,如果想动态看到文件内容的变化过程,可以使用命令 tail -f /tmp/out
十一、系统日志
11.1 syslogd 服务
系统日志存放在 /var/log 目录下面
每个应用程序都有必要写系统日志,但是不是人人都能写,毕竟万一有人乱写......
因此,UNIX 做了一个权限分隔,只有 syslogd 服务才有权限写系统日志。应用程序都是依靠 syslogd 服务来写系统日志的,这个服务像一个记录员
只需要将要写的内容提交给 syslogd,然后由 syslogd 去写系统日志
11.2 相关函数
#include <syslog.h>
void openlog(const char *ident, int option, int facility);
void syslog(int priority, const char *format, ...);
void closelog(void);功能:将想要记录的系统日志内容提交给记录员(syslogd 服务)
11.2.1 openlog
功能:为应用程序创建一个与记录员之间的连接
- ident — 相当于为这个连接取名字,这个名字也会被记录在系统日志中
- option — 特殊选项
- facility — 用于说明待提交给记录员的内容的来源
11.2.2 syslog
功能:向连接提交内容
- priority — 设定提交内容的优先级
- format — 想要提交的详细内容,后面变参的使用方式类似 printf
11.2.3 closelog
功能:关闭连接
十二、补充
本部分详细内容自行网上查阅
单实例守护进程是如何实现的?即 UNIX 是如何保证相同的后台服务进程只存在一个而不能存在多个?
UNIX 启动脚本文件相关知识?即 UNIX 是如何在开机自动开启服务的?

距离上一篇博客刚好过了一周......
平均每天更新接近3500字......
鬼知道这一章辣么多......早知道分两篇发了/(ㄒoㄒ)/~~















 1423
1423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











