






Watch Party: How to Write a CUDA Program (with CLAIRE Switzerland) [WP51210a]
本session以无限景观生成为例,介绍如何利用CUDA来优化程序,分享在优化CUDA程序时的思路流程,介绍如何处理递归问题的思路以及如何分析程序的瓶颈。
第1步 确定并行算法

这里递归细分时,选取两个点的中点并赋值固定阈值下随机的高度变化,阈值随着轮数减半,如下图所示:
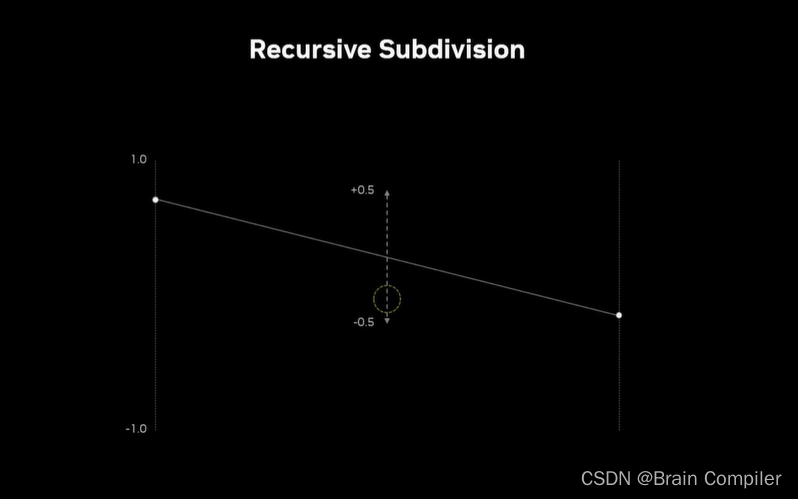
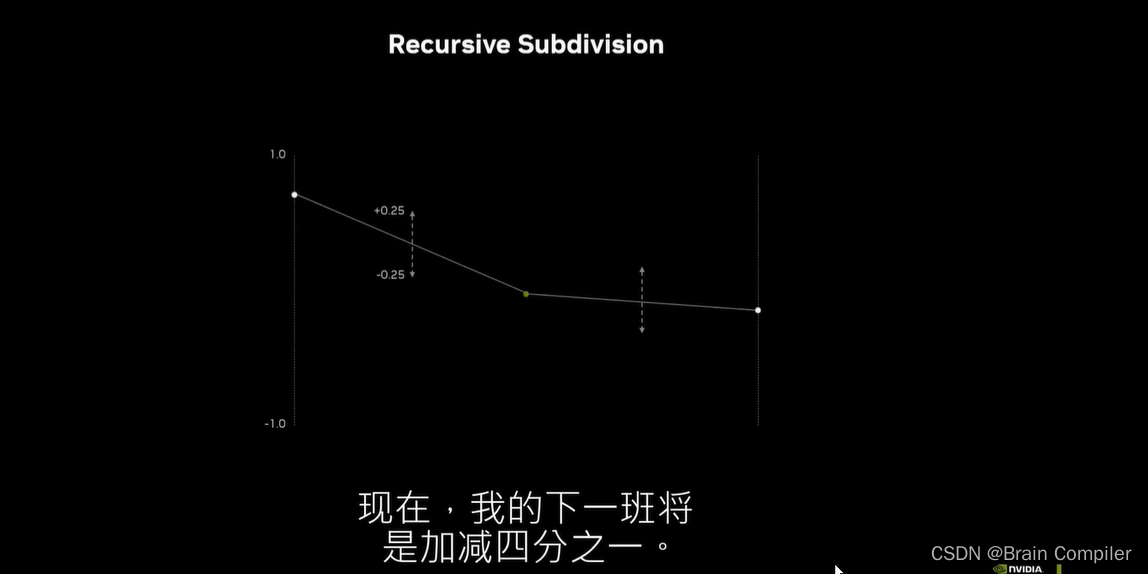
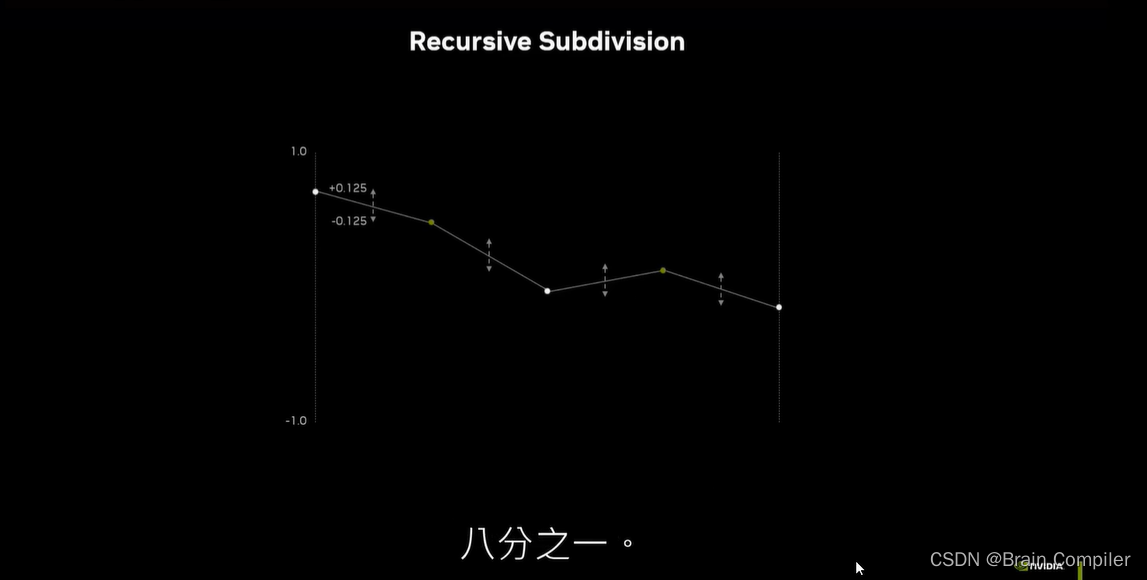
我们就得到了一条平滑的线,同理扩展到二维,用一条对角线把正方形从中间分开,因为正方形有四个非平面的点,我把它们分成了两个平面的三角形。我们将用这种三角形网格来渲染所有的三维视图,实际上是在这个象限的形式上渲染我们的景观。对X和Y进行细分,给出四个新的点,然后在中间计算出第五个新的点,作为四个新点的随机偏移。(有点像拿角来做边,然后拿边来得到中点)。现在这种细分也是递归发生的,当把这四个方块细分为越来越小的方块时,每个方块几乎都可以独立处理。因为几乎是沿着共同的边,中点是保持相同的。
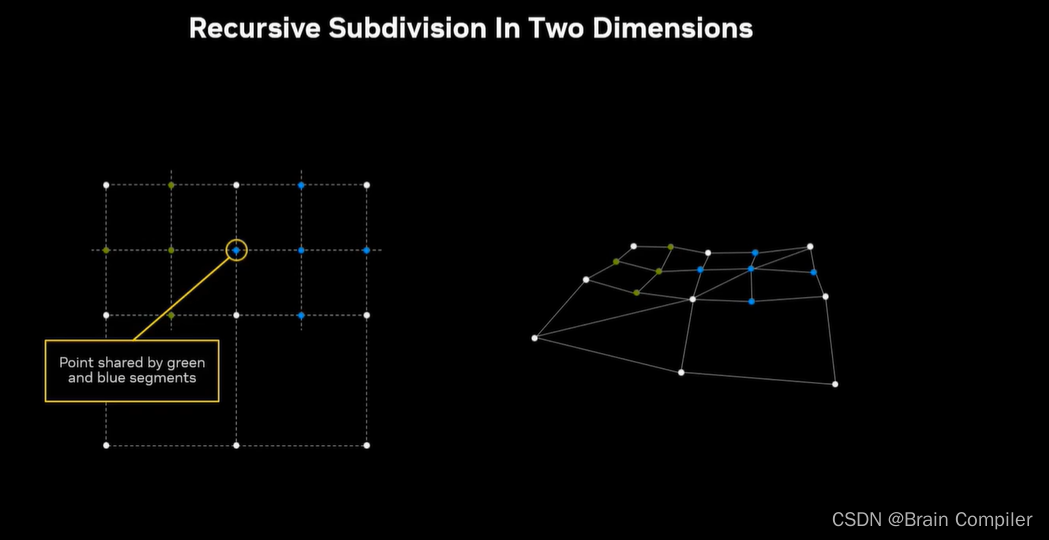
得到的效果就是:

第2步 复用已有样本代码
改写CUDA Samples中的OceanFFT代码,以适应于我们自己的无限景观生成算法。(注意在CUDA toolkit 11以后的版本,CUDA Samples不再跟随工具包一起安装,但是可以在github上获取)

第3步 划分任务
发言人的笔记本电脑有20个SM(流多处理器),每个SM在内部最多运行20和48个线程。这比通常运行一个可能有一个超线程的CPU调用要多得多。这使得在GPU上的执行在一个核心内是并行的,所以在一个核心内的线程合作处理数据。没有抢占,这意味着一旦工作填满机器,你必须等待现有工作退出。

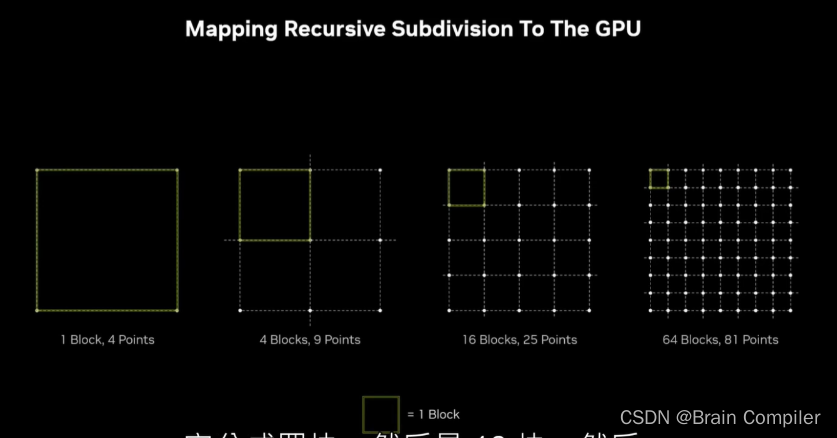
接下来要将任务映射到线程块上,每一个块最多有1024个线程,这些线程一起工作,需要注意的是这些块是基于不同的独立数据块进行工作,这一点跟CPU很不一样。

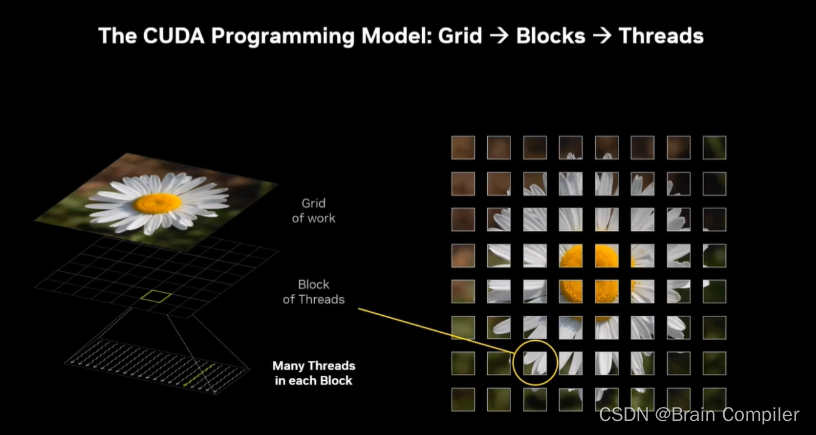
回到我们的问题,每一个块都会映射到线程网格中的一个独立工作块,如下:
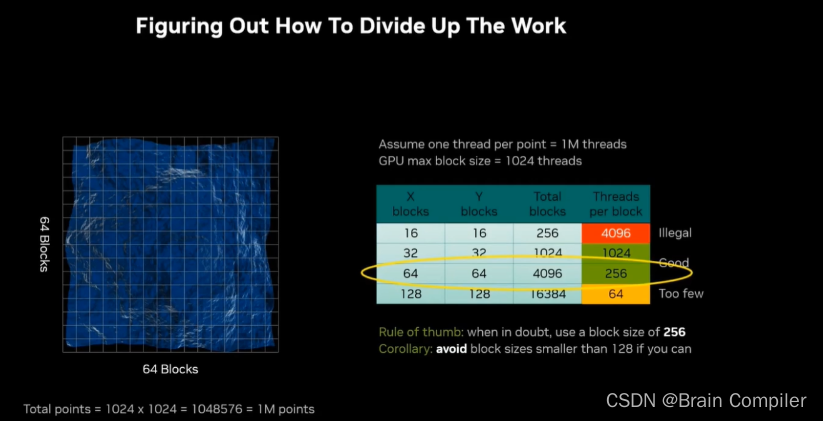
但是我们需要设计block的大小和数量,在演讲者的笔记本硬件基础上一个block最多运行1024个线程,所以下图中第一行的4096是违法的,而64又太少利用率不高,所以考虑用1024或者256(根据经验,通常我们设计block大小为256)
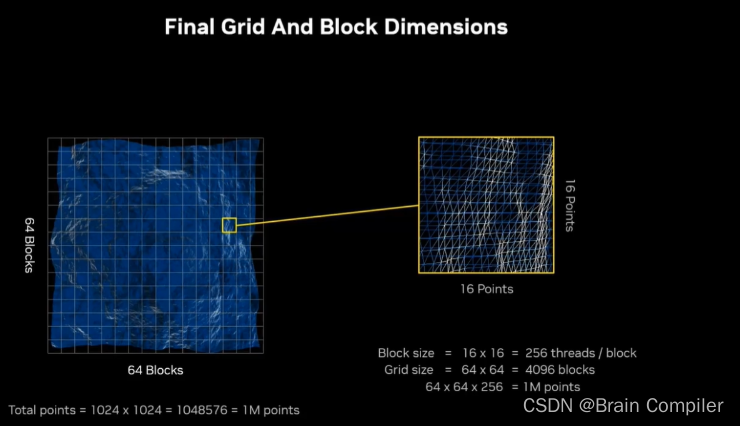
所以我们就分配好了每个线程块负责的区域,相当于有一个64*64的网格,总共有4096个线程块,每个块都要负责16*16的地形,也就是说每个块256个像素,这两者相乘就可以得到我们想要的一百万个点。
第4步 复用轮子
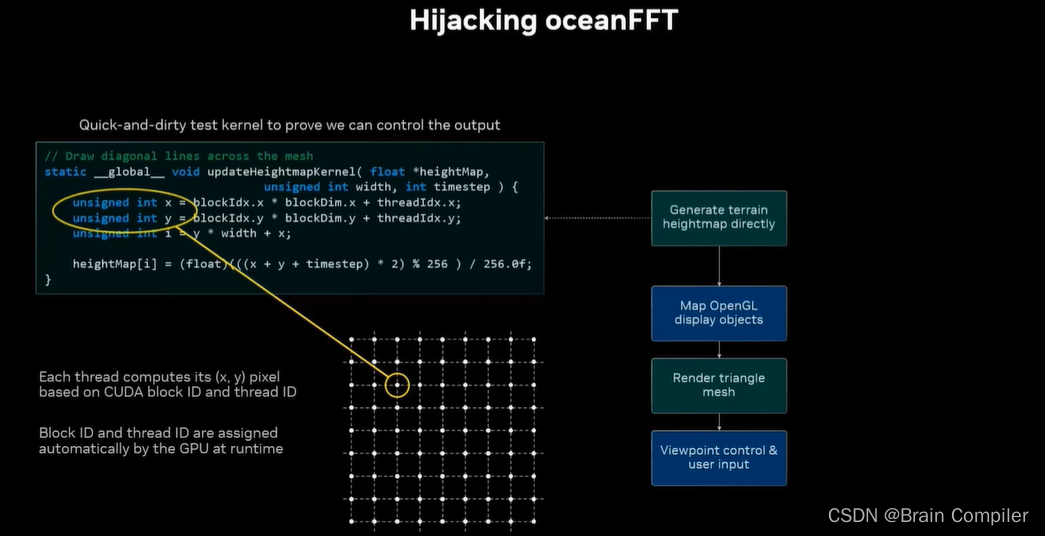
重用oceanFFT的代码,如图绿色是GPU部分,蓝色是CPU部分。它生成了一个表面,将其映射成一个高度图,再调用openGL来做网格的渲染,在重新渲染之前检查视角是否有变化。

我们想办法复用oceanFFT代码,在其基础上加以修改,以实现我们无限景观生成中生成高度的功能。(事实上我们根本不需要生成海洋的部分,只需要设置一个高度,其以下的都赋同一个值和蓝色作为海洋,以上的部分就是山。)

首先接入oceanFFT代码进行高度的生成,方法和效果如图:
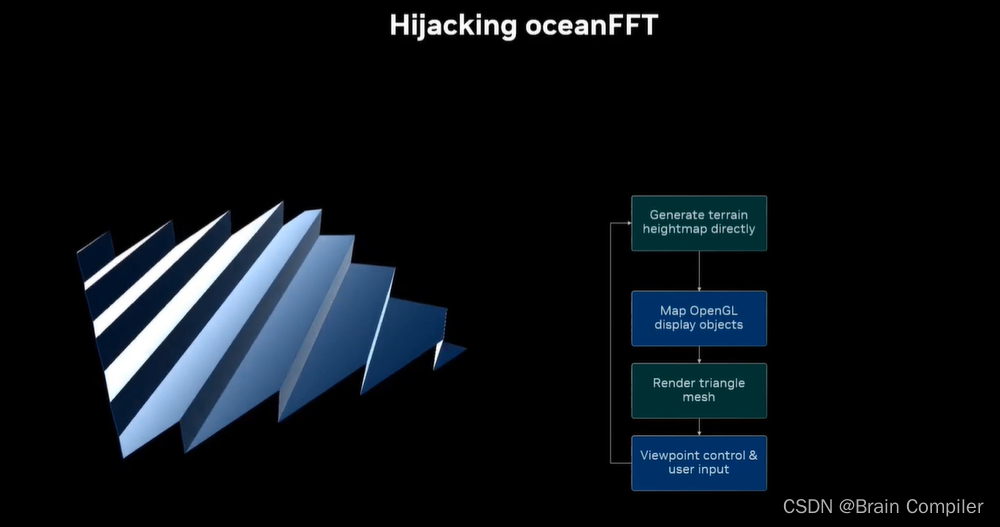
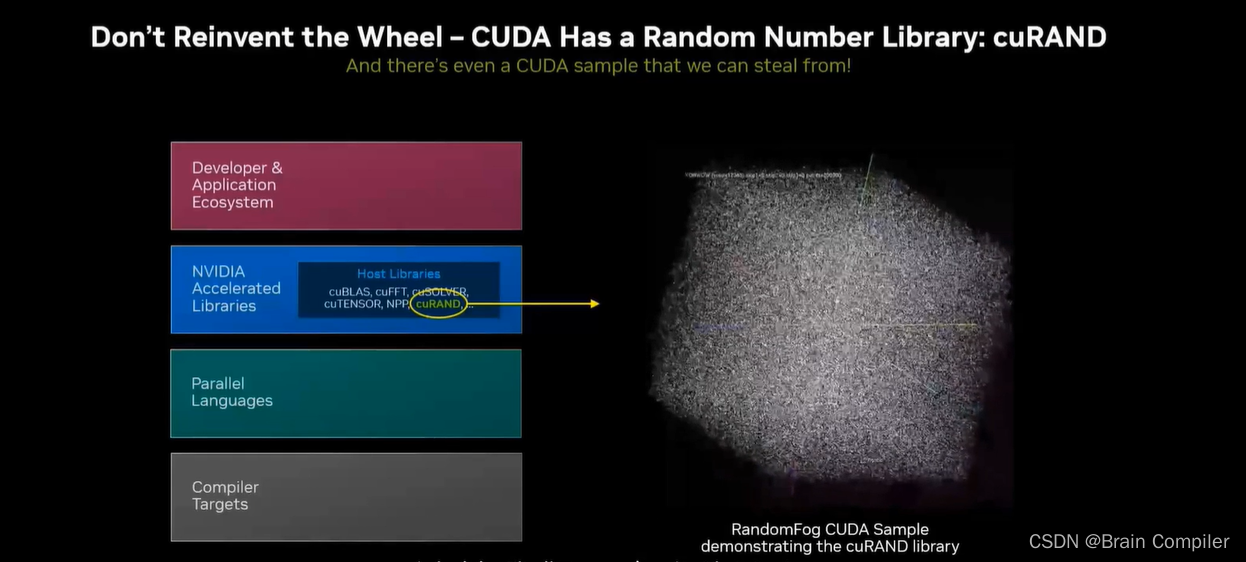
接下来结合我们的递归细分,需要产生决定高度变化的随机数,但是数以百万规模的随机数很难生成,所以考虑调用CUDA提供的cuRand随机数生成库,至此我们就基于OceanFFT实现了静态的景观生成,效果如下:


第5步 实现不能复用的代码
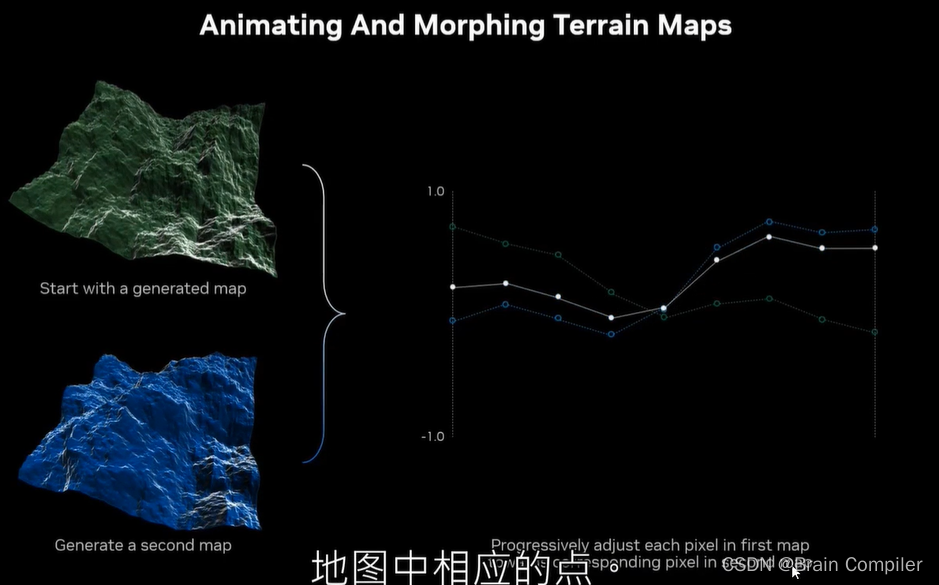
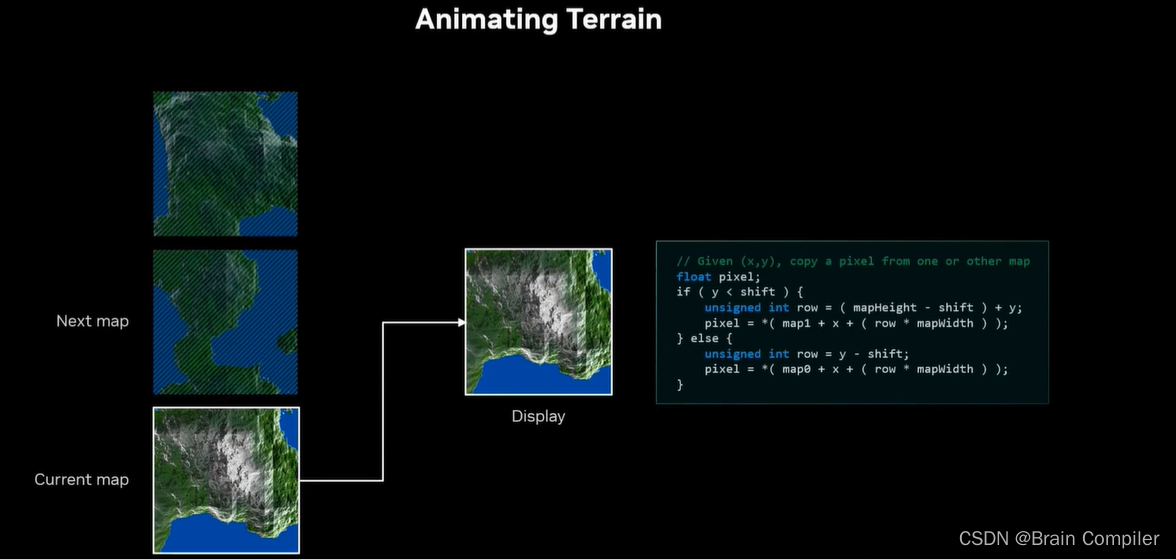
接下来想要做一个无尽的景观的动画,所以需要确定在生成的静态景观之间进行渐变过渡等等。渐变过程很简单,也就是说从一个景观变形到下一个,只需要获得第一张地图的点,然后分别逐渐移动到第二张的点,如图所示:
第6步 考虑性能
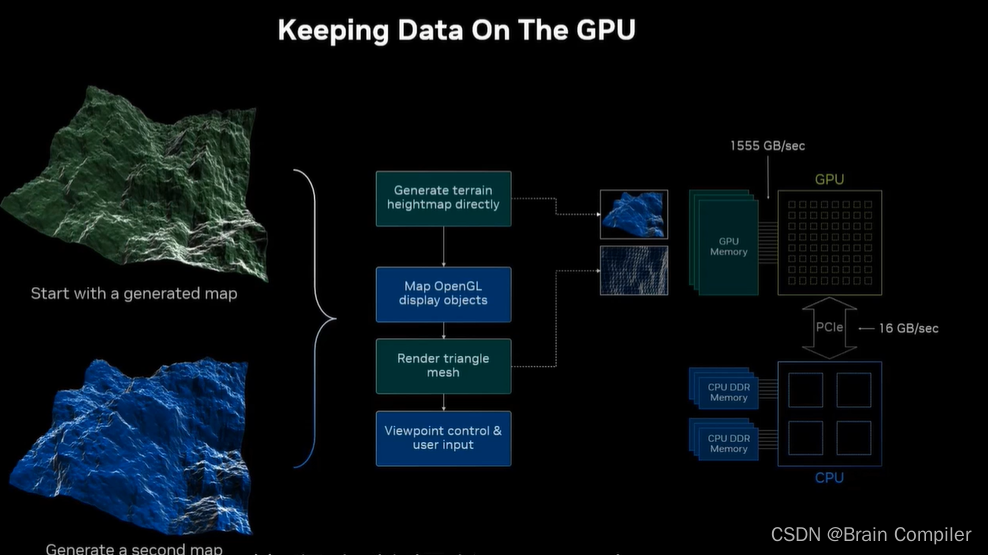
让我们回头看看我们的工作流程,想想工作流程是如何映射到GPU上的。我们要把所有的数据都留在GPU上,这意味着我的变形操作也要和数据一起留在GPU上。所以不仅是地形图的数据,还有用于显示的所有网格和三角形的数据,以及在两者之间移动所计算的数据。
GPU可以直接访问CPU的部分内存,速度是16GB每秒,它访问自己内存的速度是每秒1555GB,也就是说GPU访问GPU内存是访问CPU内存速度的一百倍,这是因为CPU在PCI总线的另一边,也就是说PCI总线是数据传输的瓶颈,所以我们尽可能地将数据放在近处,以避免PICe传输的巨大开销。
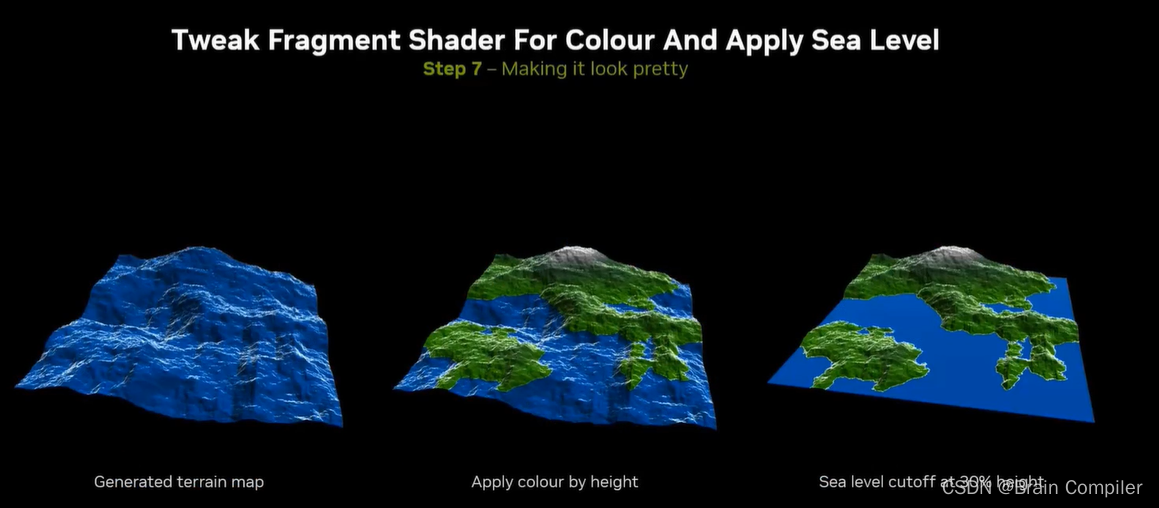
第7步 美化
用OpenGL进行着色,我们根本不需要生成海洋的部分,只需要设置一个高度进行深度截断,其以下的都赋同一个值和蓝色作为海洋,以上的部分就是山,可以着色成绿色或者灰色。
接下来需要飞跃整个场景,所以需要一长串连续的地形片,使一个地图的顶行与下一个的底行相匹配,以便于拼接在一起。而我们设计的递归细分算法很容易实现这一点:底部的边缘不用再随机生成数,而是复制上一个贴图的顶部边缘的随机数,这样就连在一起了,看上去就像一幅连续的风景。

我们逐帧看一下效果:
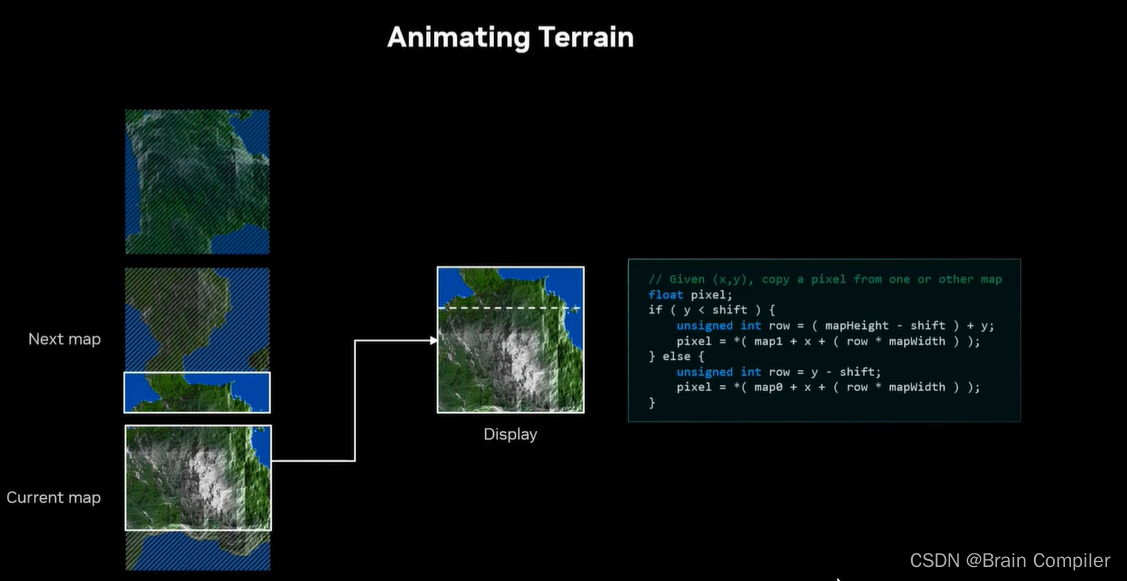
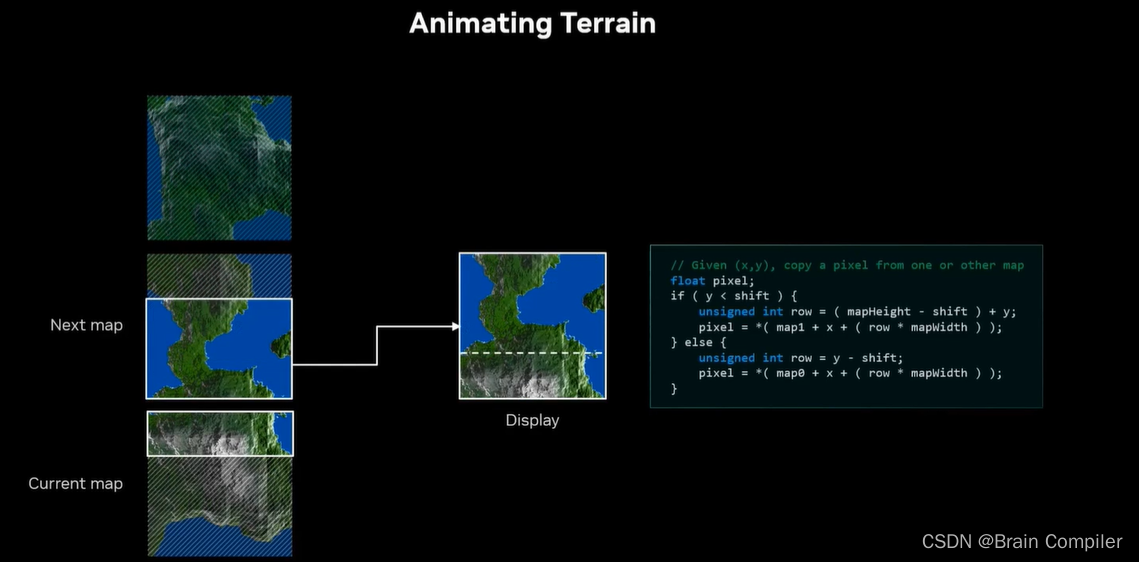
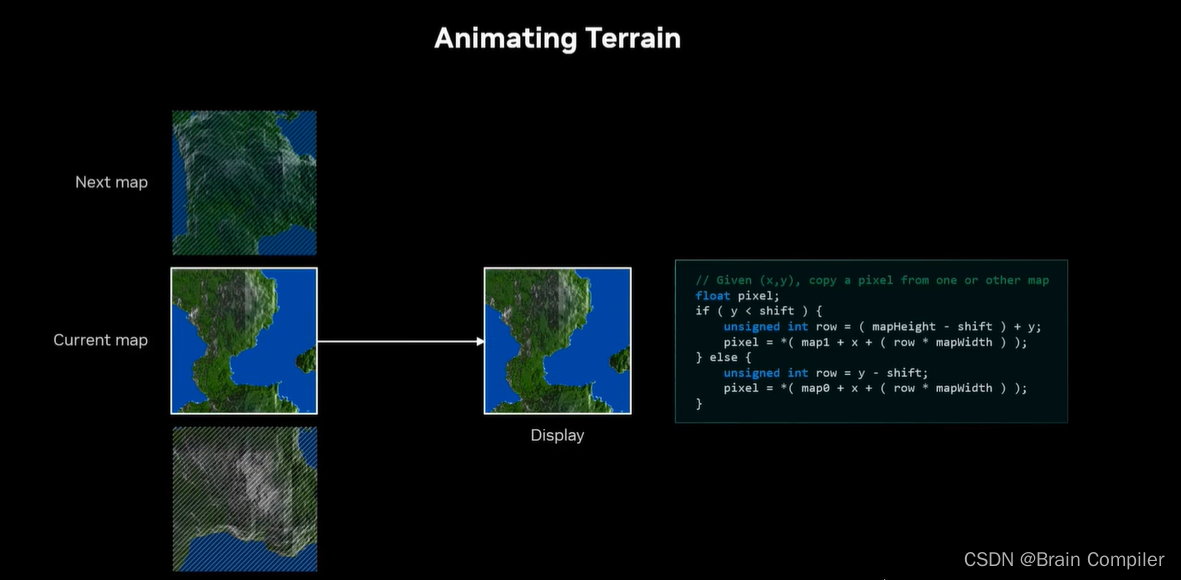
第8步:
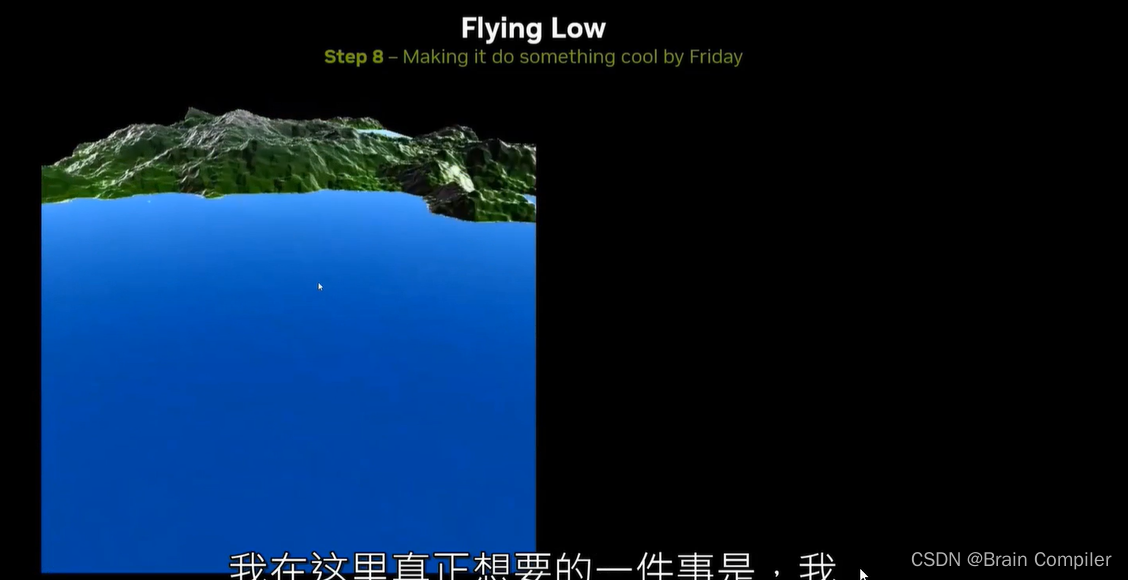
接下俩实现飞跃景观的功能,为了得到一个滚动的景观,我们可以在一个低海拔进行飞跃,也就是说我们需要得到相机飞行时所处的高度,而且要时刻记得我们尽可能地将这些数据保存在GPU内。如下是我们想要的效果:

比如说我们按照这条线进行飞跃,我们保证这些高度的数据(包括我们相机所处的高度)都存在GPU上。
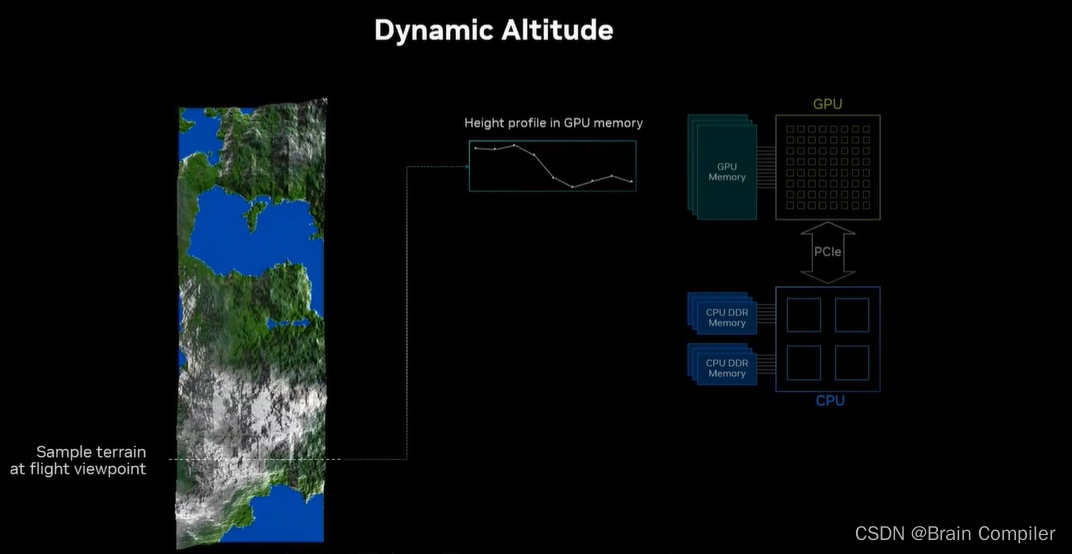
但是回顾工作流我们发现所有的控制视点逻辑都是在CPU上完成的,所以CPU需要访问GPU的内存,以此实现调整视点,但是事实是CPU不能直接从GPU内存中读取,但是GPU可以读CPU的部分内存。
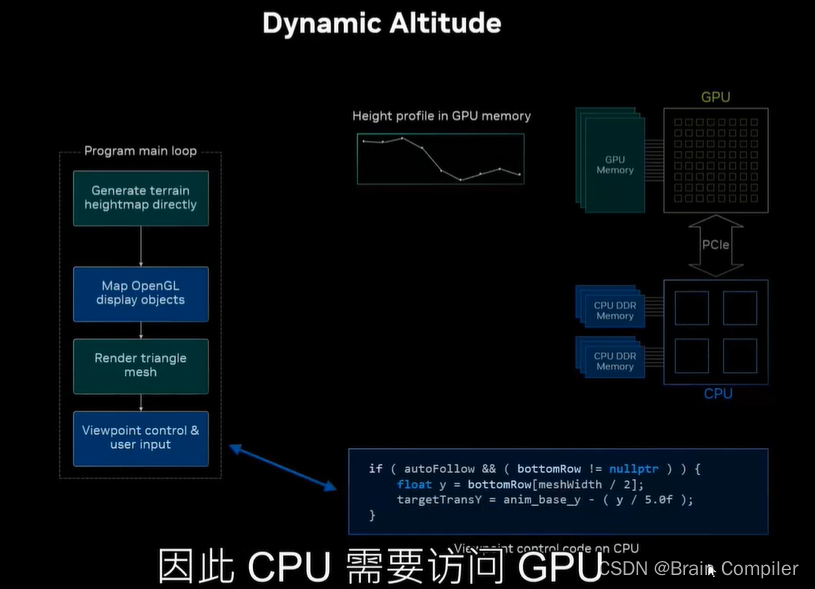
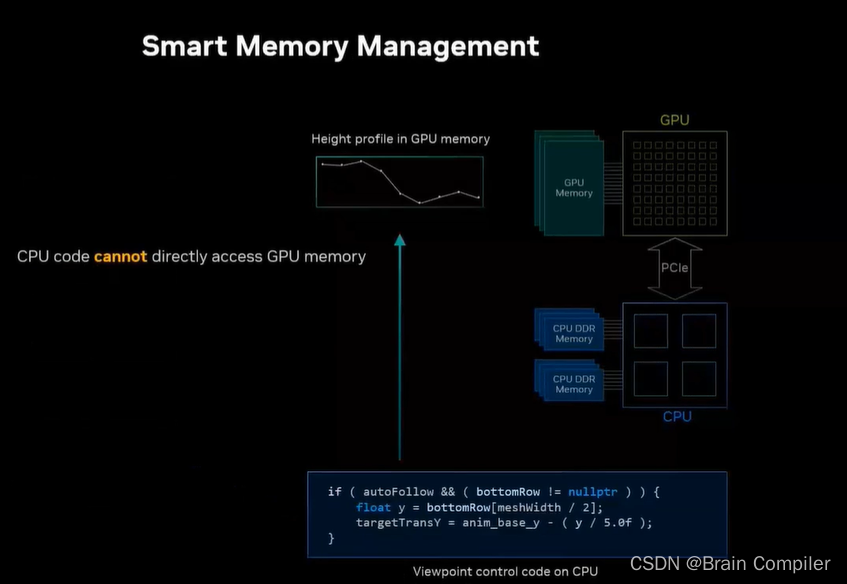
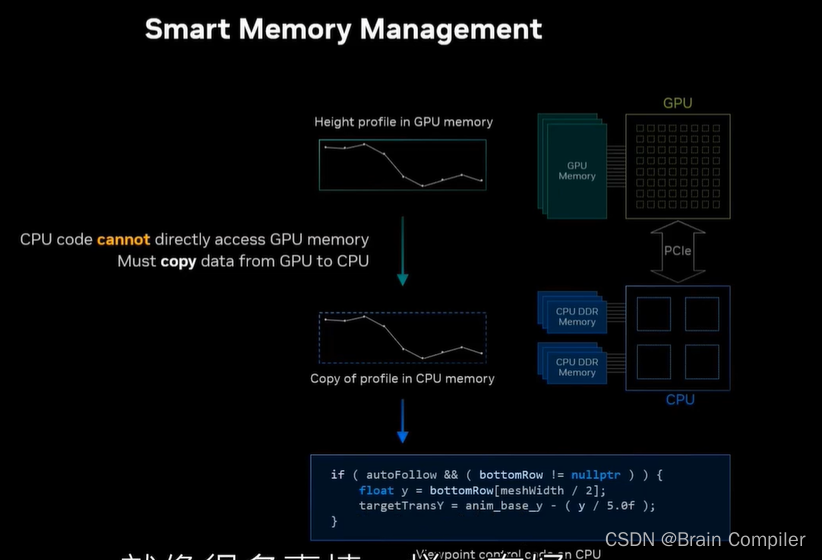
所以需要显式地将数据从GPU复制回CPU内存中,因为CPU要访问这部分不能直接读取的数据,以便于调整我们的视角。
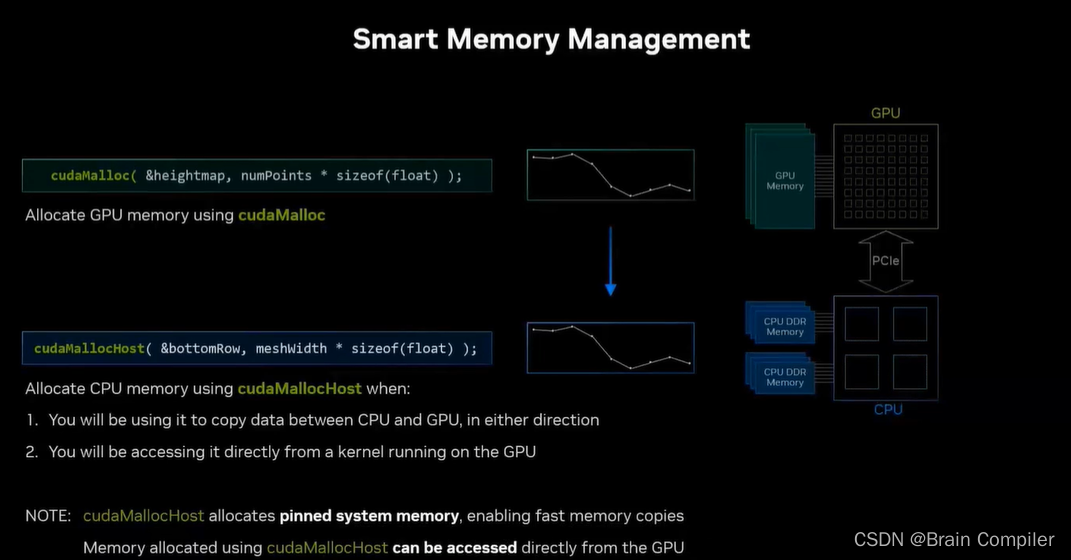
我们要解决这个问题,联想到cuda提供的GPU内存划分API:cudaMalloc,它用于划分一定大小的内存并返回一个指针。而对于主机端也有一个函数叫cudaMallocHost,它则是划分CPU内存,创建了固定(pin)的系统内存,这是系统内核中标记的用于快速DMA(Direct Memory Access 直接存储器访问)数据传输的内存,也就是我们想要的。这样比我们将数据完全从GPU复制到CPU上没用cuda分配的内存中要快5~6倍,这是因为系统内存的效率更高。需要注意的是,GPU可以访问一部分CPU内存但不是所有的CPU内存,而cudaMallocHost分配了GPU可以直接访问的内存,这是我们此优化步骤的核心。
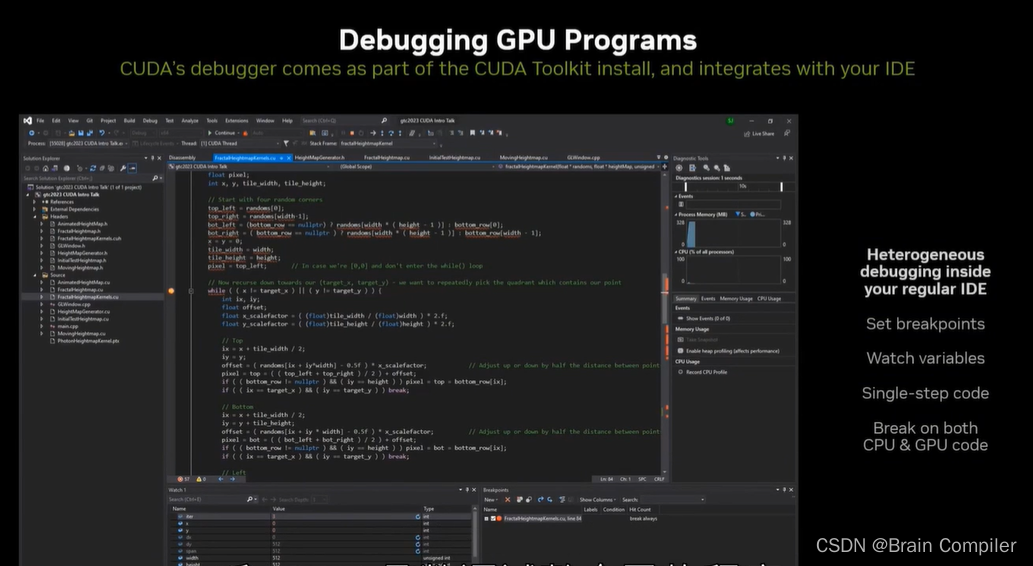
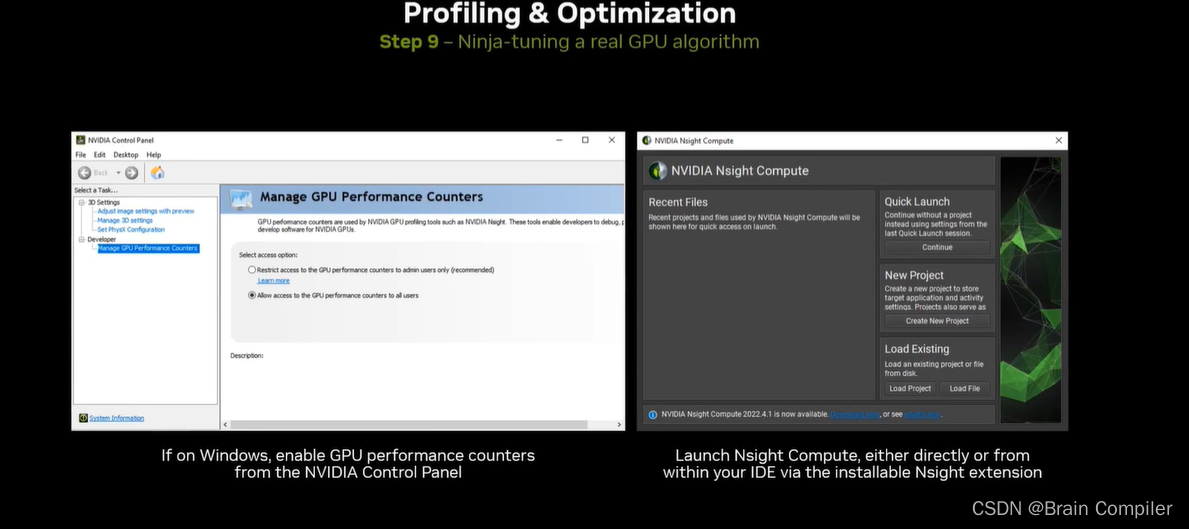
第9步 调整,Debug和IDE
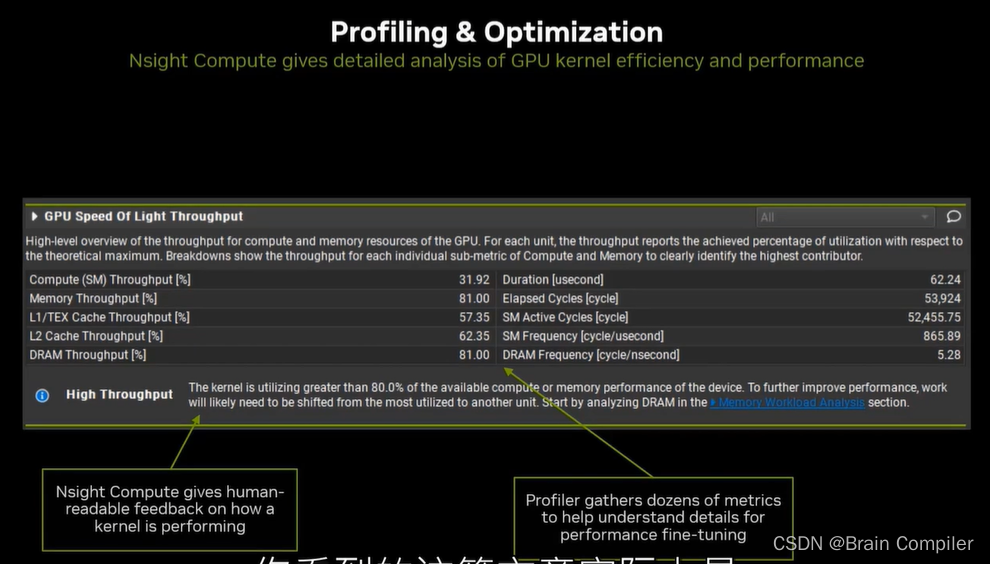
主讲人推荐了Nsight CUDA Debugger、Nsight Compute、Nsight System等工具,我们可以依据这些IDE提供的性能分析中的利用率和吞吐量等参数,对我们的CUDA程序进行调整和优化
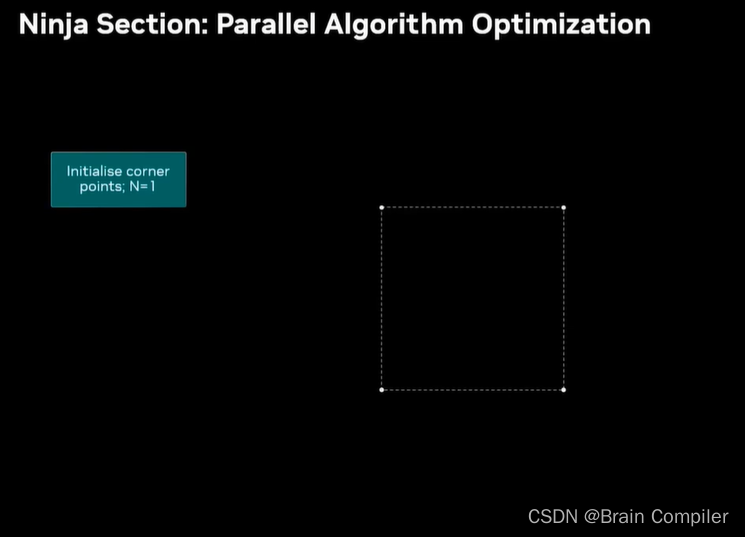
我们看一下整个生成的细节:

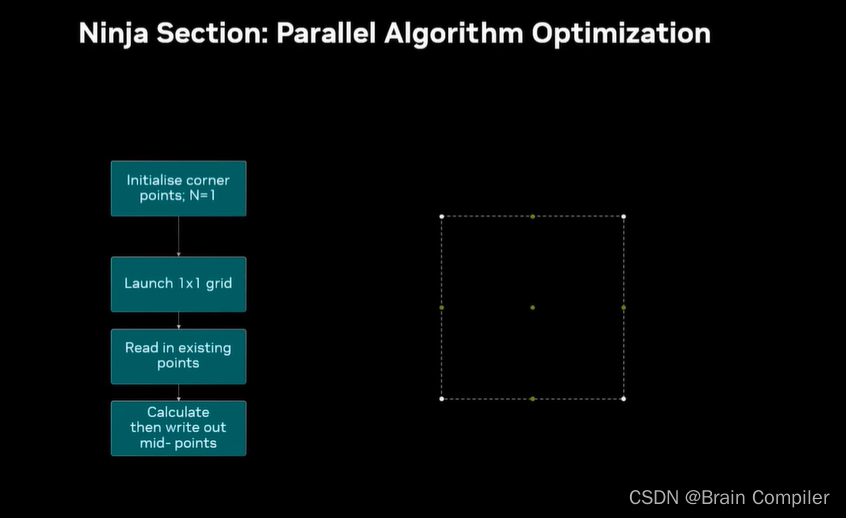
最初一个block grid,初始化四个角
然后launch一个新的1*1单块grid,读取刚才设置的四个角,计算中心和中点并写回GPU内存。
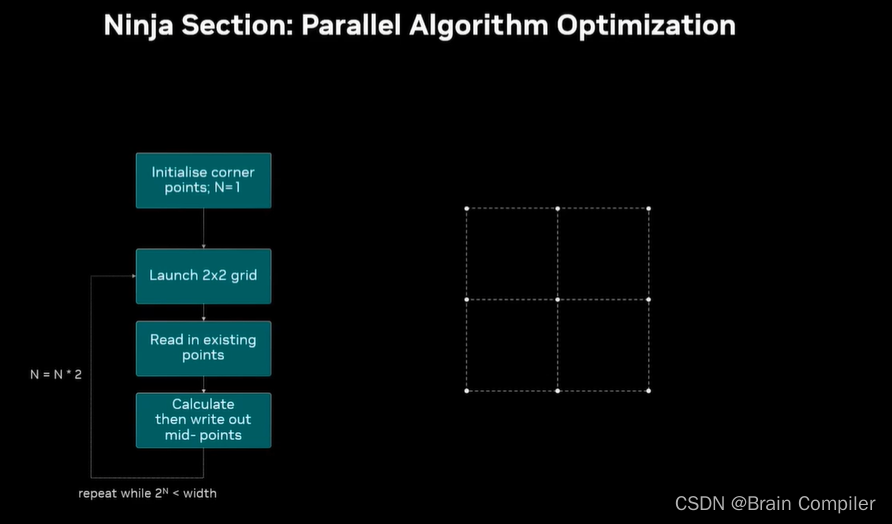
然后重复这个过程,这就是我们的递归细分算法,每一轮都启动双倍数量的线程,比如第二轮是2*2,第三轮就是4*4,直到64*64的grid,每个块有256个线程。
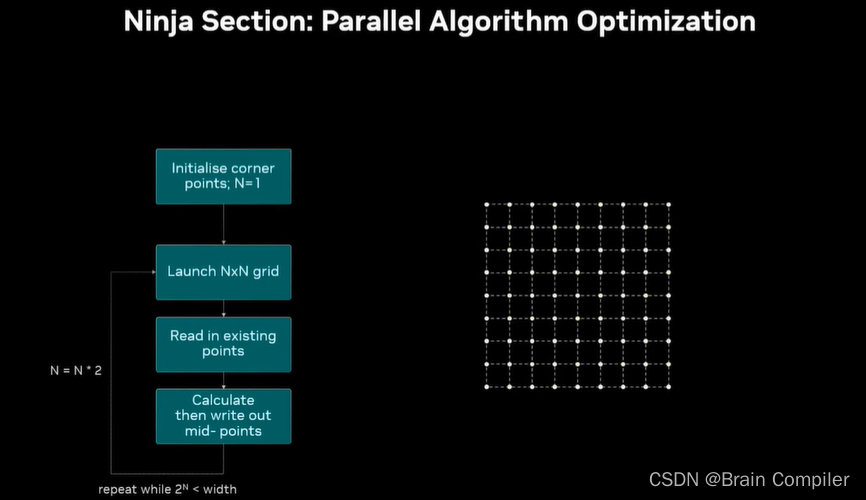
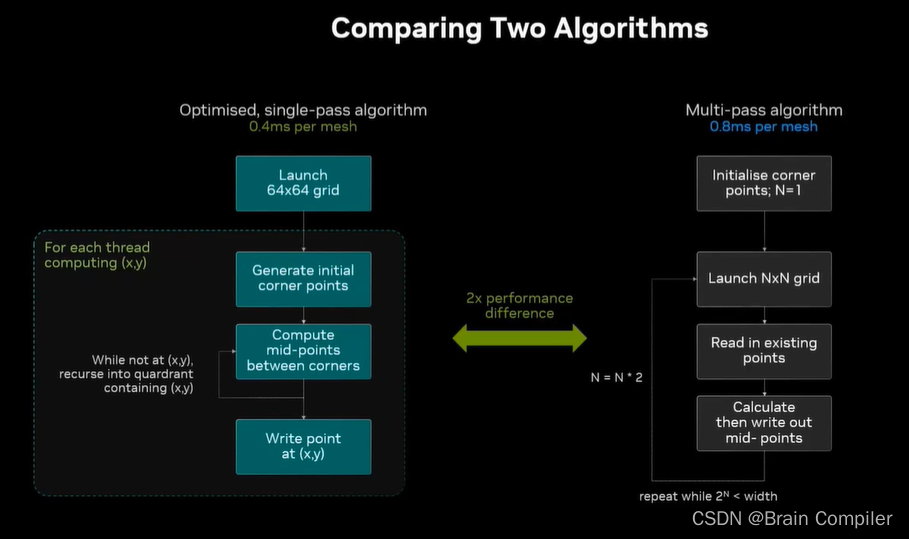
这是原始的算法,对于1024*1024的mesh,启动了10次grid(2^10=1024),每一个网格都读上一次写下的数据,然后计算数据并写下来,主讲人的笔记本用时0.8毫秒/mesh。

这是原始的算法,我们继续进行优化,CPU缓存特别快,而GPU重新计算值比将其保存到内存并读出来要快很多(100倍),因为一次算数运算是5个周期,而访存是500个周期,基于这一点我们进行优化。

我们直接到最后一次启动,启动了1024*1024个线程,是64*64的block grid,每个block有256个线程,每个线程独立计算一个像素的值,包括它之前所有的层次结构,一共一百万个像素,一百万个线程。

首先每个线程生成角上的点并保存到本地(线程具有本地寄存器和数据),我们考虑生成一百万次但是不保存在内存中,只是作为本地数据保持在线程里(所以支付的是计算成本而不是内存成本)。
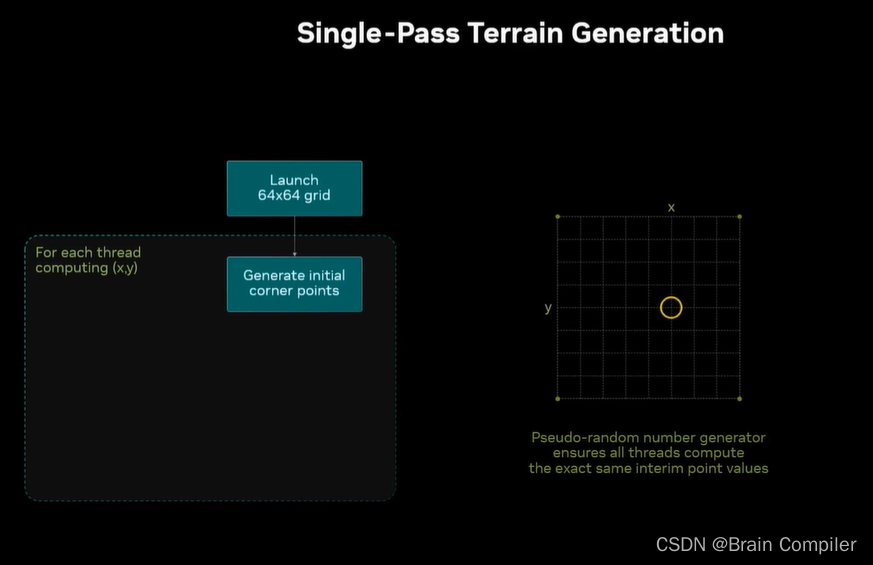
用这些点生成5个中点,也都是存在线程的本地寄存器中,我们针对的是网格中的黄圈位置,但是网格中的所有线程都将进行完全相同的计算,每个点都生成相同的点集(因为用的是相同的伪随机数生成器)。
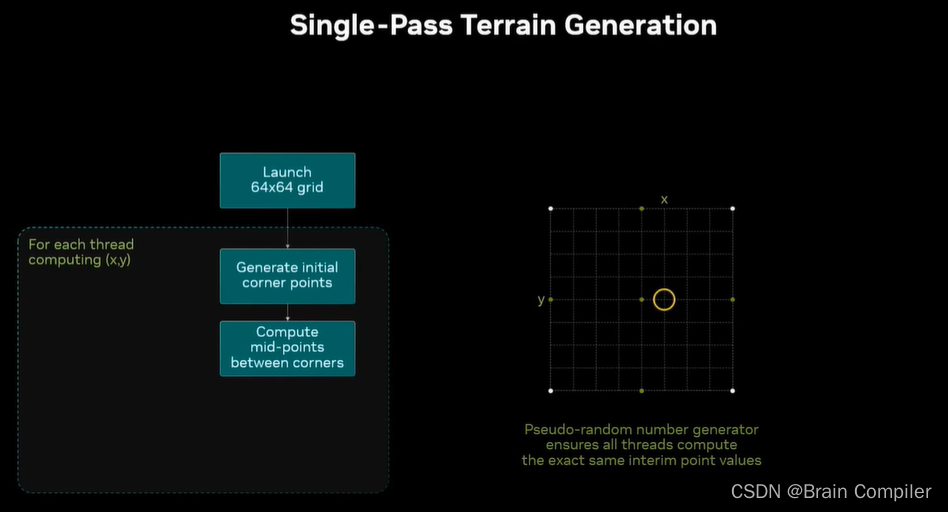
现在放大这个线程的目标,一些中点变成了新的角点,再计算新的中点。
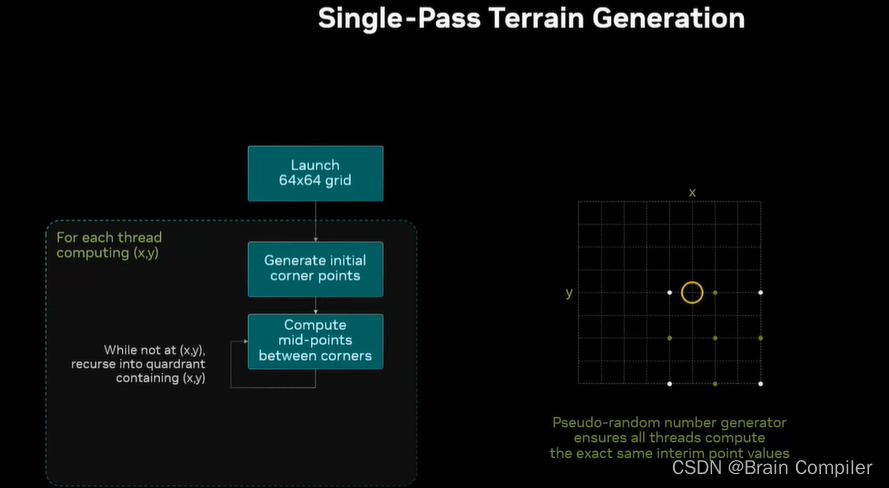
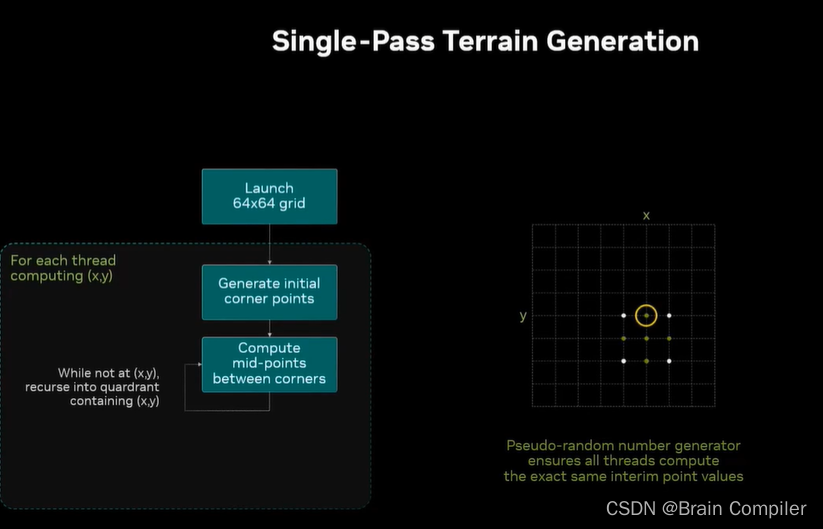
最终找到了我们黄圈位置的目标,而每个线程都在相同的时间生成目标点,计算次数完全相同,对于任何给定的线程,需要记录n个步骤,对于1024宽的网格是10步,每一步计算5个中点,所以每个线程计算了50个点。我可以以一次内存load的成本进行100次计算,而不需要从内存中反复反复读写,这是一个单次通过的算法,而不需要反复调用内核,只有一个内核启动,用快速计算的代价代替缓慢的内存读写代价。
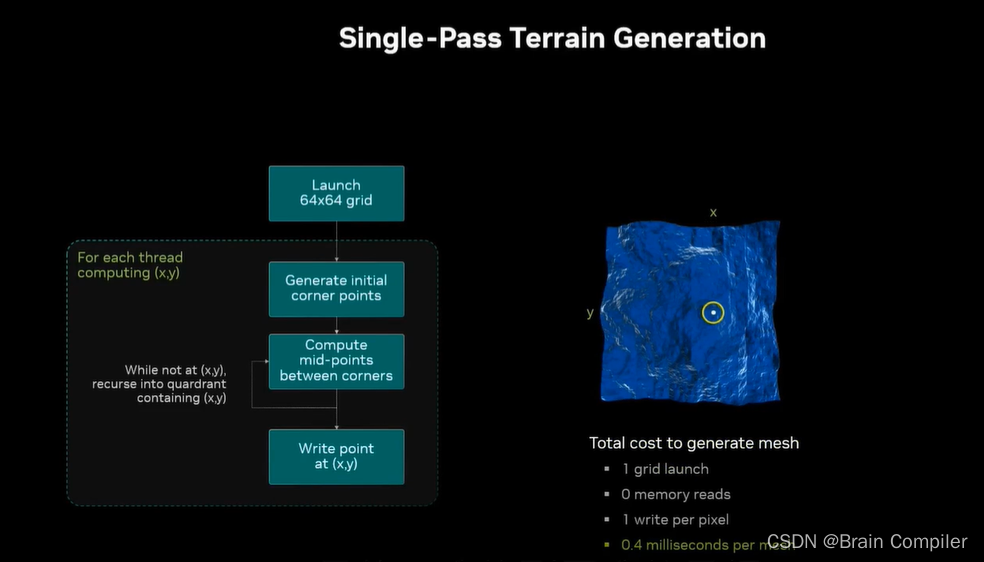
对比两个算法,左边循环要紧密得多,而且不涉及读取和写入数据。左边优化后的算法比旧的要快一倍(尽管计算部分快了很多,但是有很多开销仍没有改变)
总结和收获
我们回顾一下整个CUDA程序的设计流程及其优化核心:
写出你要写的算法;
分解网格块和做线程-任务的映射;
编写更少的代码——复用;
用cudaRand生成大规模随机数;
美化显示逻辑;
最重要的是保持数据在GPU上;
但是当我们必须在GPU和CPU之间复制的时候,需要正确设置内存以避免PCI总线成为瓶颈;
学习Nsight等相关工具;
优化即有算法使其更快。















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









