






reduce操作通常指给定N个数值,对它们进行累计的算术操作,例如求总和、求最值、求均值、异或等数值计算。也称作redection操作。
在这里以求和操作为例子,一步一步优化代码的并行:
先看基础版本的核心代码部分,这里只涉及了简单的求和计算(完整代码贴在文章末尾,这里仅关注算法的优化:
__global__ void reduce_base(const int* input, int* output, size_t n) {
int sum = 0;
for (size_t i = 0; i < n; ++i) {
sum += input[i];
}
*output = sum;
}//只分配了1个block和1个thread,相当于CPU上的串行程序
reduce_base<<<1, 1>>>(d_a, d_out, N);
并行(Ⅰ):引入shared memory和并行规约算法;
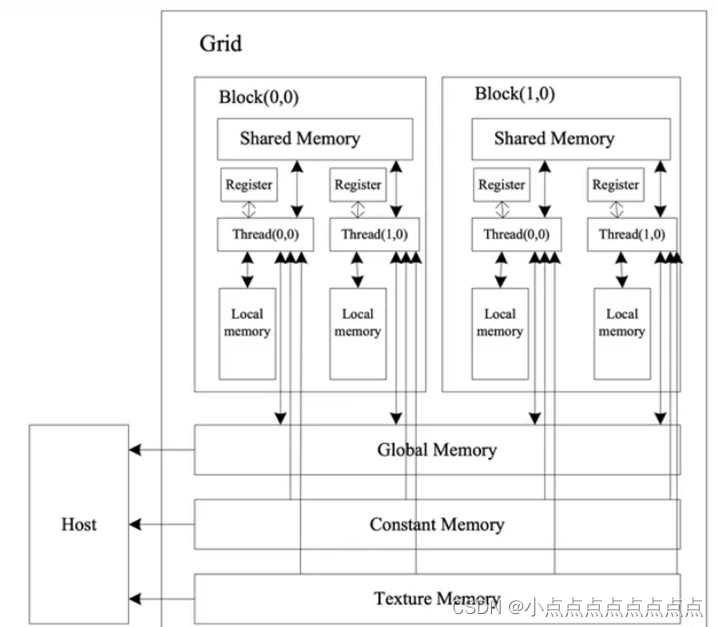
shared memory 共享内存,片上存储。可以在同一个线程块的thread之间共享通信和协作。而且,共享内存缓冲器驻留在物理GPU上,而不是驻留在GPU之外的系统内存中。因此,在访问共享内存时的延迟远远低于访问普通访问区(global memory全局内存)的延迟,使得使用共享内存像每个线程块的高速缓存或者中间结果缓存区那样高效。
global memory 全局内存,片外存储。latency对比shared memory要高近十倍
下图为GPU执行核函数时的内存调用:
并行规约算法:对与N个数据的加法可以考虑以下计算,但计算量很大

 可以看到,对8个数据而言,串行和并行(2、3方式)的实现效率已经对比很明显了,时间复杂度O(N)与O(log(N))。对后两种实现方式,思想是一样的。
可以看到,对8个数据而言,串行和并行(2、3方式)的实现效率已经对比很明显了,时间复杂度O(N)与O(log(N))。对后两种实现方式,思想是一样的。
在优化(Ⅰ)中,我们在shared memory上做并行规约计算,然后把最终结果先存在shared memory[0],再把结果写回显存。核心代码如下:
template<int blockSize>
__global__ void reduce_v0(float *d_in,float *d_out){
__shared__ float smem[blockSize];
int tid = threadIdx.x;
int gtid = blockIdx.x * blockSize + threadIdx.x;
smem[tid] = d_in[gtid];
__syncthreads();//并行思想
for(int index = 1; index < blockDim.x; index *= 2) {
if (tid % (2 * index) == 0) {
smem[tid] += smem[tid + index];
}
__syncthreads();
}
if (tid == 0) {
d_out[blockIdx.x] = smem[0];
}
}
在以上for循环中,index = 1时,if(tid%2==0) 偶数id的线程,执行smem[tid] += smem[tid + 1],例如tid=0时,smem[0]+=smem[0+1];即smem[0]=smem[0]+smem[1];将1号线程的值加到0号线程上,并保存到0号线程。以此类推,3号线程的值加并存到2号线程。对应上图的第二个对数步长算法的第一层实现。
#include <bits/stdc++.h>
#include <cuda.h>
#include "cuda_runtime.h"
template<int blockSize>
__global__ void reduce_v0(float *d_in,float *d_out){
__shared__ float smem[blockSize];
int tid = threadIdx.x;
int gtid = blockIdx.x * blockSize + threadIdx.x;
smem[tid] = d_in[gtid];
__syncthreads();
for(int index = 1; index < blockDim.x; index *= 2) {
if (tid % (2 * index) == 0) {
smem[tid] += smem[tid + index];
}
__syncthreads();
}
if (tid == 0) {
d_out[blockIdx.x] = smem[0];
}
}
//检查结果对错
bool CheckResult(float *out, float groudtruth, int n){
float res = 0;
for (int i = 0; i < n; i++){
res += out[i];
}
if (res != groudtruth) {
return false;
}
return true;
}
int main(){
float milliseconds = 0;
const int N = 25600000;
cudaSetDevice(0);
cudaDeviceProp deviceProp;
cudaGetDeviceProperties(&deviceProp, 0);
const int blockSize = 256;
int GridSize = std::min((N + 256 - 1) / 256, deviceProp.maxGridSize[0]);
//int GridSize = 100000;
float *a = (float *)malloc(N * sizeof(float));
float *d_a;
cudaMalloc((void **)&d_a, N * sizeof(float));
float *out = (float*)malloc((GridSize) * sizeof(float));
float *d_out;
cudaMalloc((void **)&d_out, (GridSize) * sizeof(float));
for(int i = 0; i < N; i++){
a[i] = 1.0f;
}
float groudtruth = N * 1.0f;
cudaMemcpy(d_a, a, N * sizeof(float), cudaMemcpyHostToDevice);
dim3 Grid(GridSize);
dim3 Block(blockSize);
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start);
reduce_v0<blockSize><<<Grid,Block>>>(d_a, d_out);
cudaEventRecord(stop);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&milliseconds, start, stop);
cudaMemcpy(out, d_out, GridSize * sizeof(float), cudaMemcpyDeviceToHost);
printf("allcated %d blocks, data counts are %d", GridSize, N);
bool is_right = CheckResult(out, groudtruth, GridSize);
if(is_right) {
printf("the ans is right\n");
} else {
printf("the ans is wrong\n");
//for(int i = 0; i < GridSize;i++){
//printf("res per block : %lf ",out[i]);
//}
//printf("\n");
printf("groudtruth is: %f \n", groudtruth);
}
printf("reduce_v0 latency = %f ms\n", milliseconds);
cudaFree(d_a);
cudaFree(d_out);
free(a);
free(out);
}













 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









