







目录
Notebook使用(keras实现minist手写数字识别)
简介
华为云ModelArts产品链接(点击管理控制台即可使用):https://www.huaweicloud.com/product/modelarts.html
开发者社区:https://developer.huaweicloud.com/develop/aigallery/home.html
华为云ModelArts支持pytorch,tensorflow等主流框架,但是百度PaddlePaddle只支持自研的paddle;但是百度AI的生态比华为云AI好很多吧,截至到现在华为云ModleArts没有遥感方面的资料。
我已经支持华为云240+元了,先入为主,感觉华为云好用,不听解释。
求评委多给点分!
新手入门教程(找云宝)
ModelArts 是面向开发者的一站式 AI 开发平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。
这是ModleArts首页的介绍,做完找云宝就能体验交互式智能标注、自动化模型生成、快速部署等功能。
官方有教程就不在这写了,提示一点,遇到不会的就在上方搜索框中搜索。
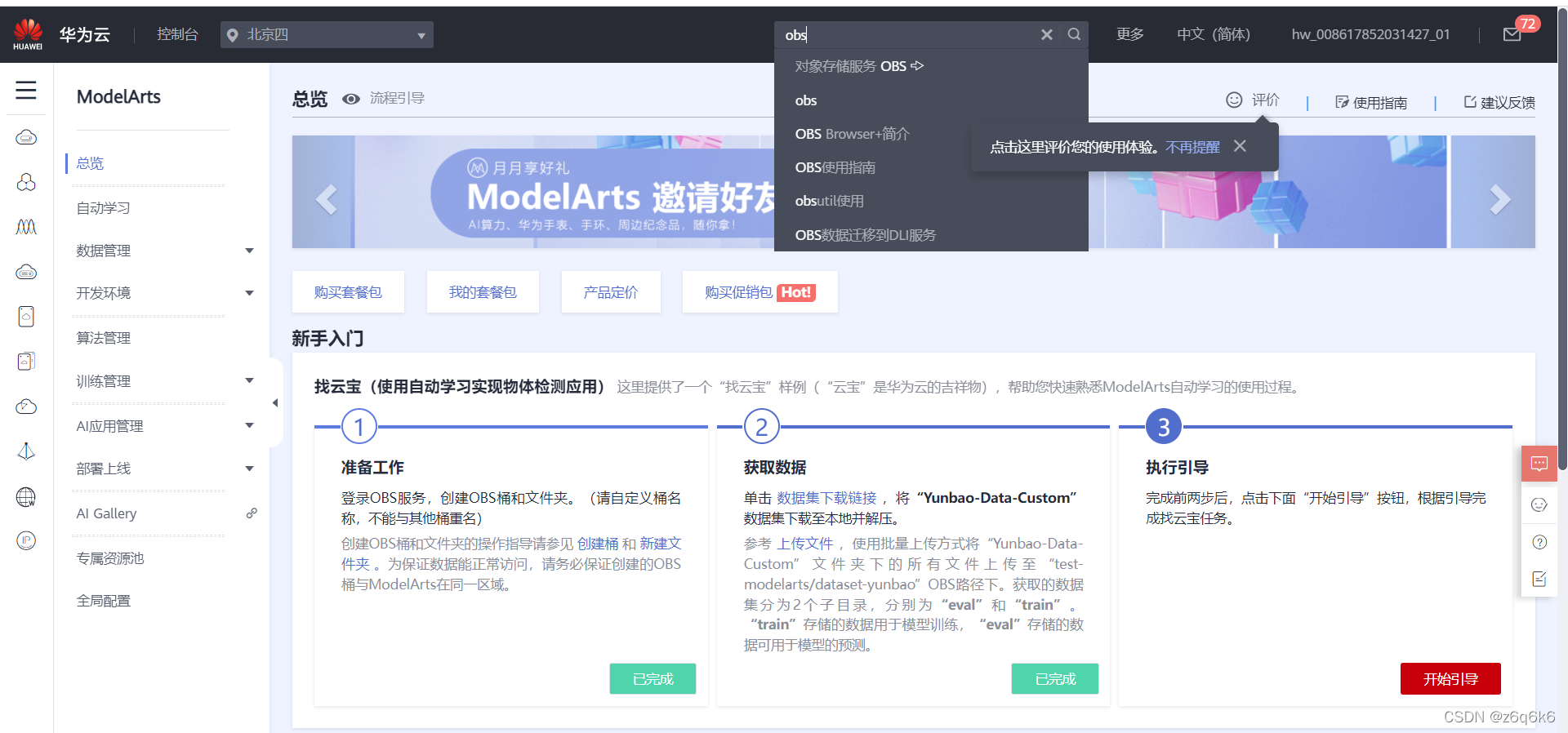
最后模型部署完成后,可以在线调用
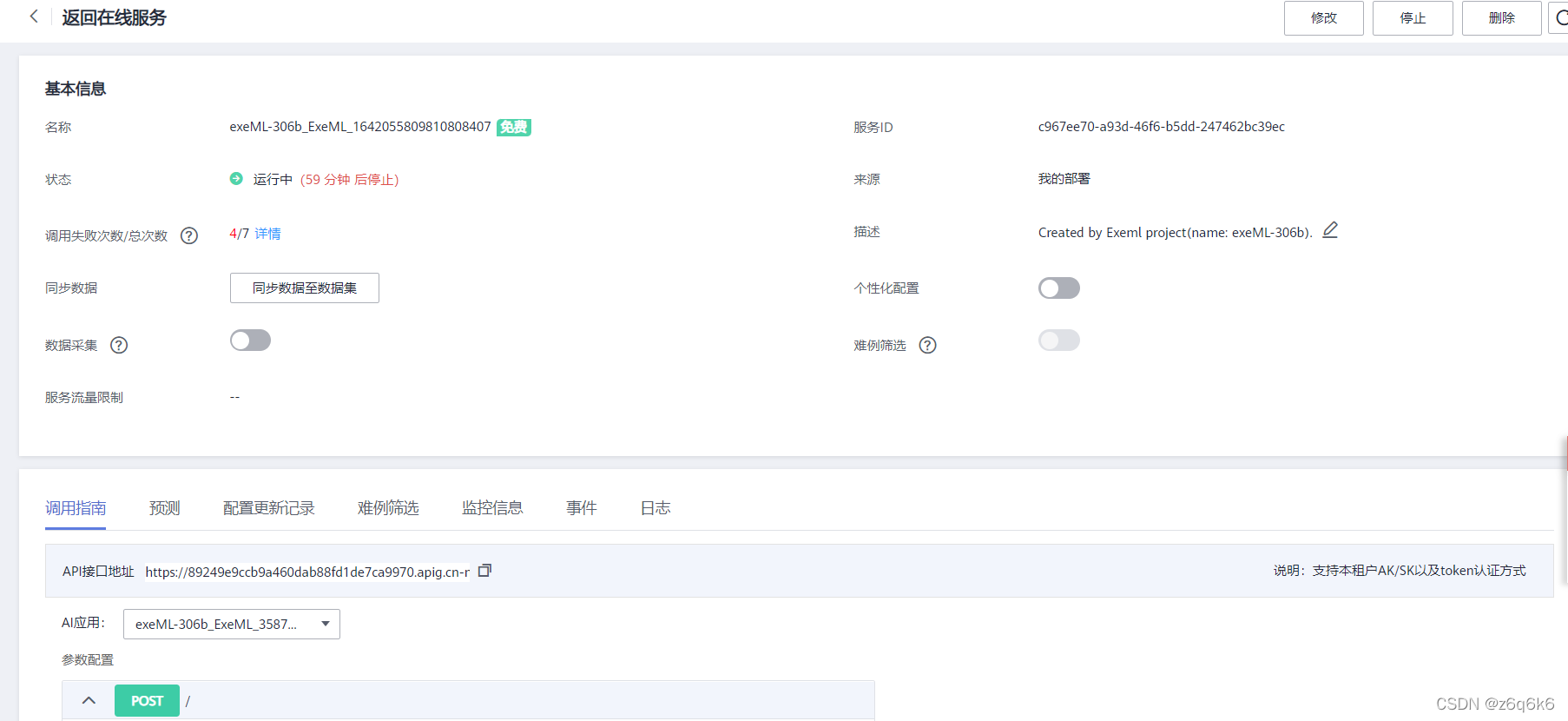
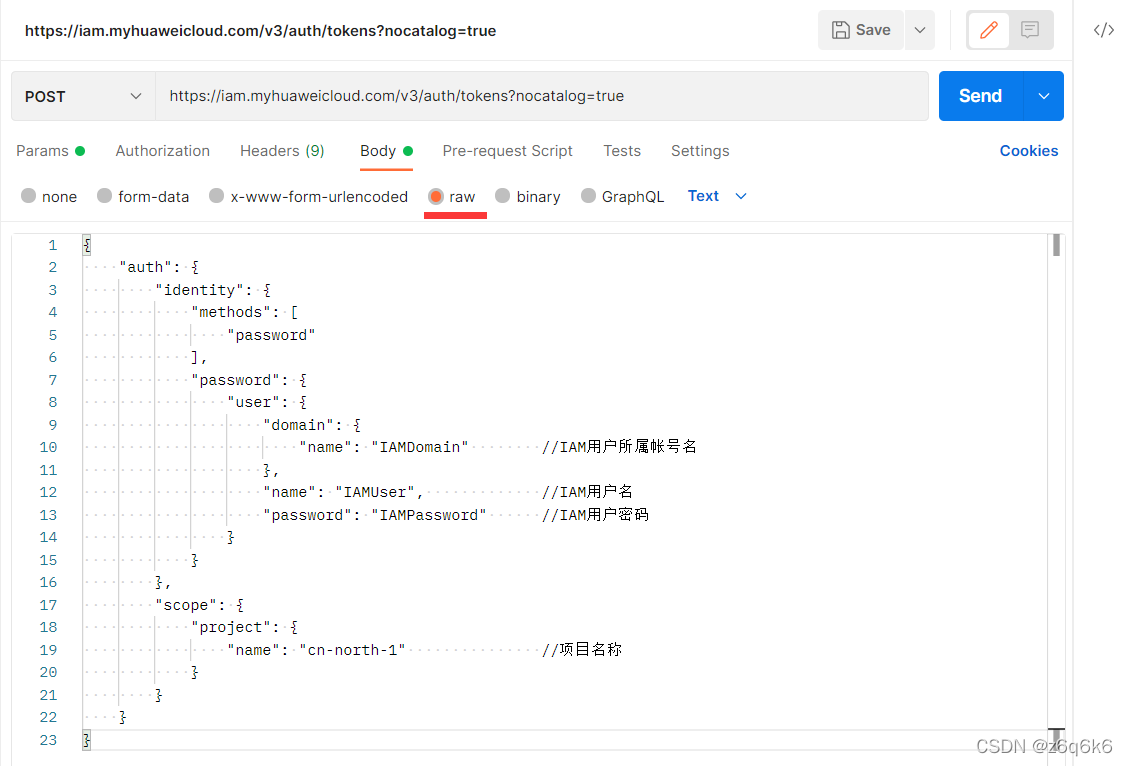
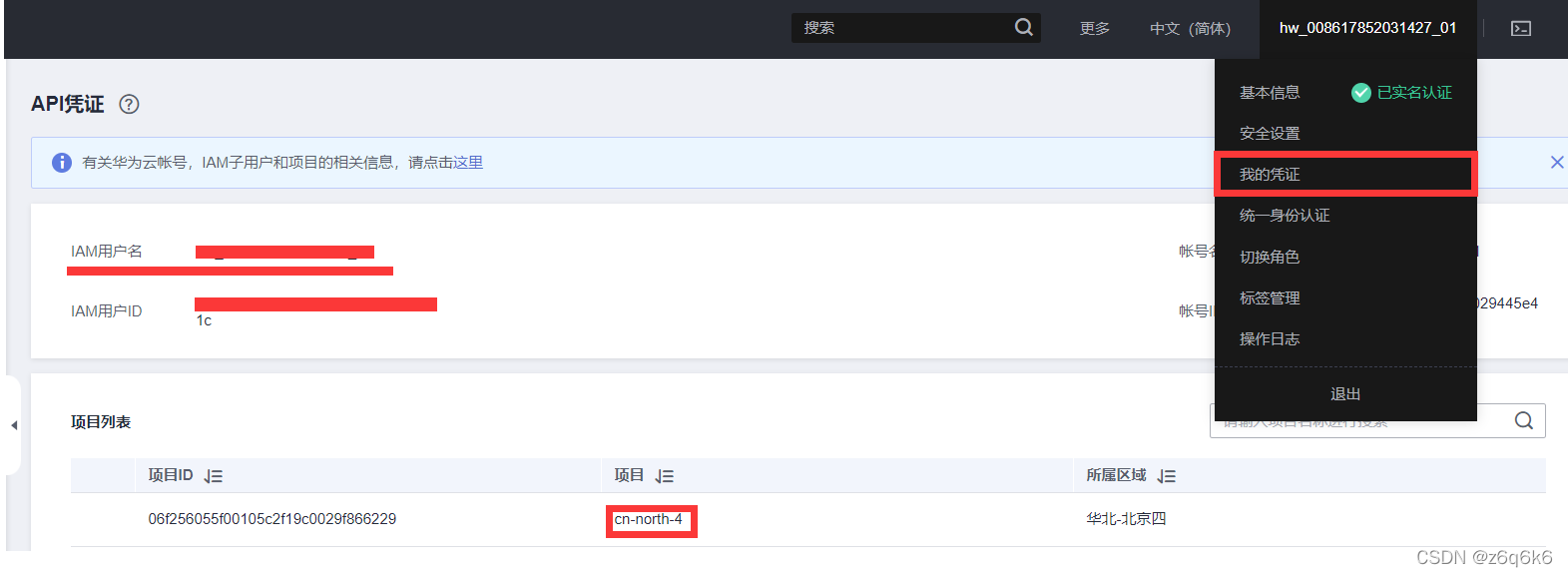
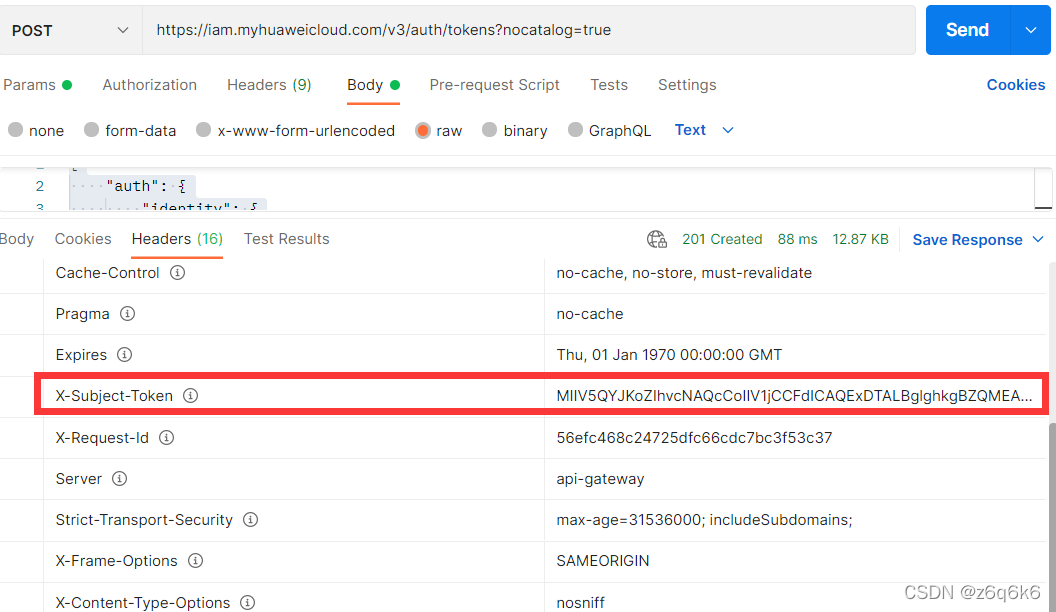
获取Token(X-Auth-Token)
 https://support.huaweicloud.com/api-iam/iam_30_0001.html
https://support.huaweicloud.com/api-iam/iam_30_0001.html官方文档写的有点迷,以下是详细步骤
使用postman软件
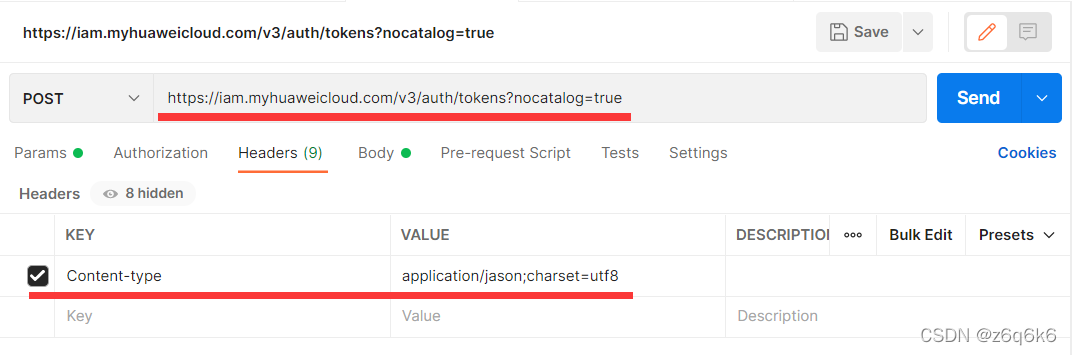
访问在线服务
 https://support.huaweicloud.com/inference-modelarts/inference-modelarts-0023.html
https://support.huaweicloud.com/inference-modelarts/inference-modelarts-0023.htmlNotebook使用(keras实现minist手写数字识别)
选择TensorFlow-1.8的Notebook
首先导入需要的函数和包
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
from keras.optimizers import SGD
from keras.datasets import mnist
import numpy as np构建模型的网络结构:
model = Sequential()
model.add(Dense(500,input_shape=(784,))) #输入层, 28*28=784
model.add(Activation('tanh'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(500)) #隐藏层, 500
model.add(Activation('tanh'))
model.add(Dropout(0.5)) #50% dropout
model.add(Dense(10)) #输出结果, 10
model.add(Activation('softmax'))编译模型:
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) #设定学习效率等参数
model.compile(loss = 'categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) #使用交叉熵作为loss读取数据集作为训练集和测试集:
(x_train,y_train),(x_test,y_test) = mnist.load_data() #使用mnist读取数据(第一次需要下载)
X_train = x_train.reshape(x_train.shape[0], x_train.shape[1]*x_train.shape[2])
X_test = x_test.reshape(x_test.shape[0],x_test.shape[1]*x_test.shape[2])
Y_train = (np.arange(10) == y_train[:,None]).astype(int) #将index转换橙一个one_hot矩阵
Y_test = (np.arange(10) == y_test[:,None]).astype(int)对使用转换后的数据对模型进行训练:
model.fit(X_train,Y_train,batch_size=50,epochs=200,shuffle=True,verbose=1,validation_split=0.3)输出对测试集进行测试的结果:
print("test set")
scores = model.evaluate(X_test,Y_test,batch_size=100,verbose=1)
# print(scores)
print("The test loss is %f" % scores[0])
result = model.predict(X_test,batch_size=100,verbose=1)
result_max = np.argmax(result, axis = 1)
test_max = np.argmax(Y_test, axis = 1)
result_bool = np.equal(result_max, test_max)
true_num = np.sum(result_bool)
print("The accuracy of the model is %f" % (true_num/len(result_bool)))模型保存
print("Saving model to disk \n")
mp = "./model.h5"
model.save(mp)发布Notebook
链接:
发布Notebook步骤
发布模型
我只是把Notebook训练出来的Modle.h5上传到obs中,然后发布模型时,从obs桶中导入,部署后,应该要写预测的代码,调用指南等,感觉挺繁琐的,没有继续。
结论
明明华为云有限时免费的资源,但偏偏抢不到,写这篇博客花了不少钱,希望。。。


















 1155
1155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











