







爬虫框架一般有以下三种:
1. Scrapy
2.PySpider
3.Selenium(自动化测试的一个框架)
这里主要介绍Scrapy
Scrapy的基本用法:
1. 在cmd中输入pip install scrapy
注意:1.如果安装过程当中提示time out使用以下的命令来安装
pip install -i https://pypi.douban.com/simple scrapy
注释: scrapy是从国外服务器来下载,这里使用国内的网站进行下载,效果更好,速度更快,而且不会出现链接超时等情况.
注意:2.如果安装过程当中提示以下错误:
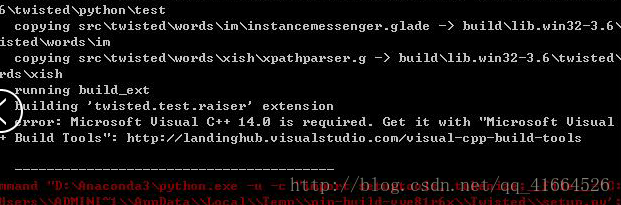
说明你的电脑上还缺少一个c++14.0这个软件,需要从提示的网址上下载即可.
2. 在cmd中输入pip list 查看所有包中有没有scrapy如果有则说明导入成功!
3. 通过命令创建项目
在cmd中输入
cd Desktop(这里使用的是桌面,也可以自己定义,直接将想要放的位置的路径或者主文件夹拖进来即可,系统会自动生成文件路径)
scrapy startproject Job51Spider(前面两个单词是固定格式,后面一般以网站com之前的名字命名.后面加个Spider表示爬虫项目,也可以用自己的命名方式)
注意: 这里的爬虫命名首字母必须是以字母开头否则会报错

4. 用pycharm打开项目
打开之后一般是这种形式:
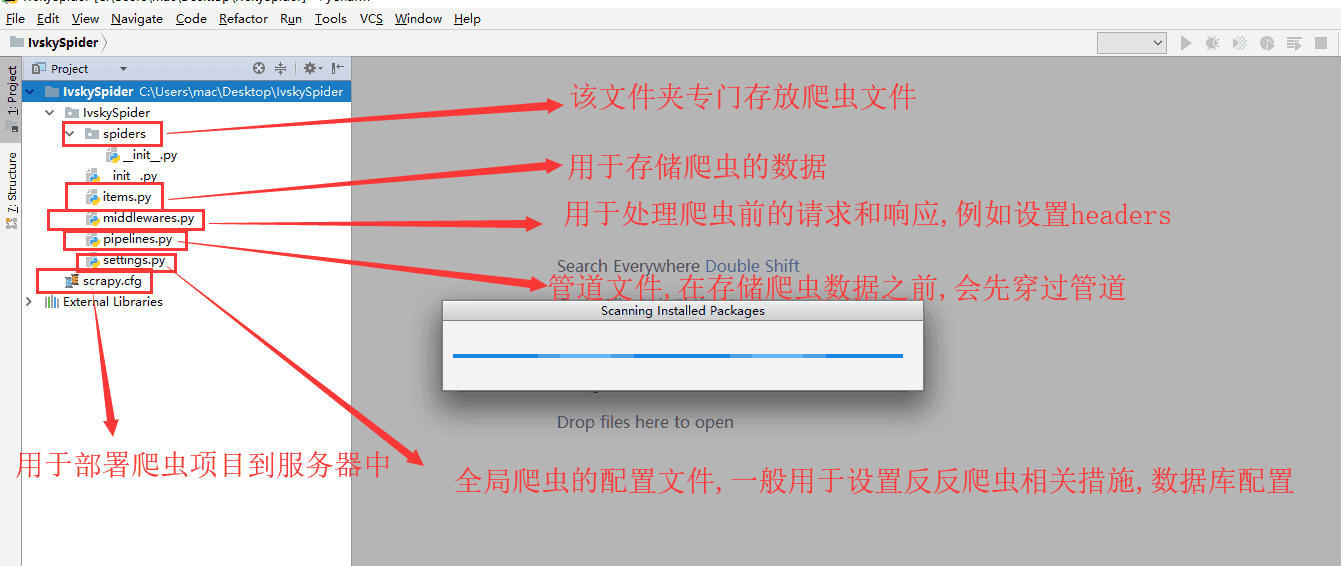
这里面的各个.py文件所包含的功能和作用都是不一样的!
以下是它们之间的分工:
5. 通过命令创建爬虫
这里使用pycharm自带的命令窗口来执行
工具栏 --- View --- Toolwindows --- Terminal
在命令行中输入: scrapy genspider 51job 51job.com
注释: 运行爬虫name为job51的爬虫文件
注意: 这里在输命令的时候要先查看是否已经进入爬虫项目当中否则会报错.
可以用 cd 来一级一级文件名称来添加,来进入爬虫项目中.
一般进入主爬虫项目文件夹即可
提示以下信息说明创建成功:

运行结束后,找到spiders点击a51job
里面的代码是(ivsky就是51job):
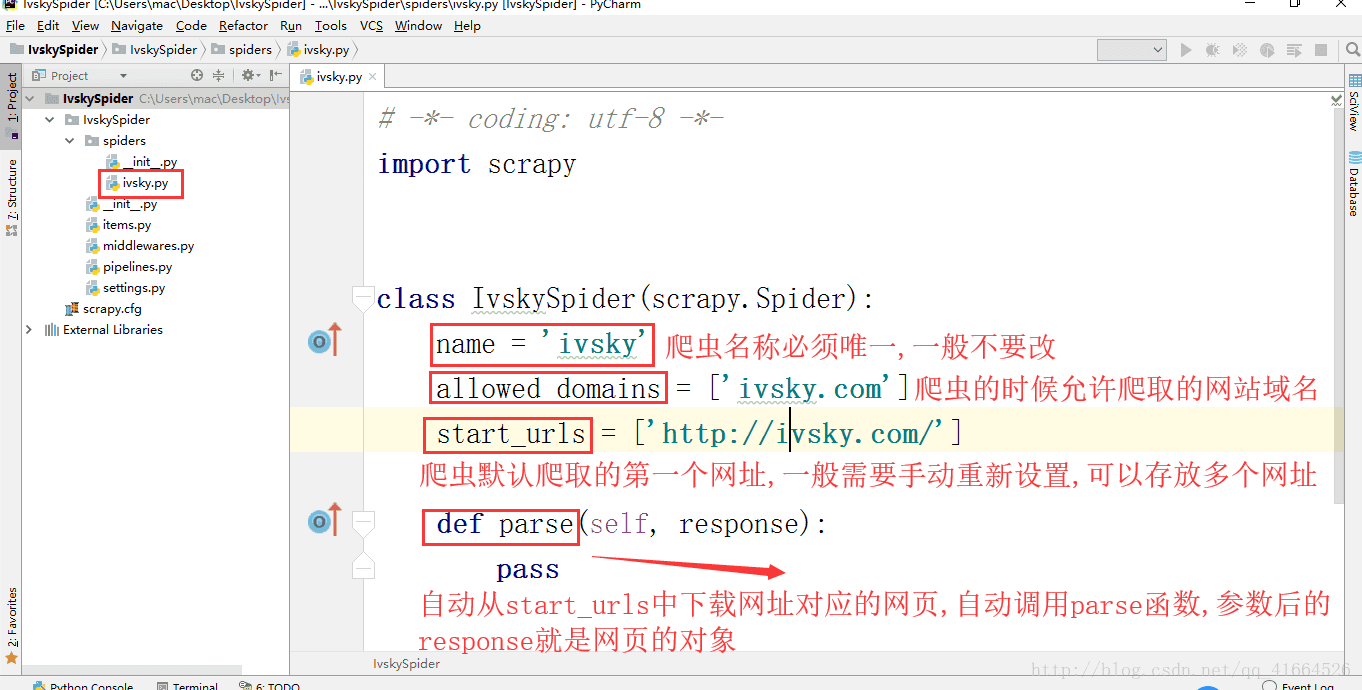 一般这里改动的是start_urls,将里面的网址补全齐
一般这里改动的是start_urls,将里面的网址补全齐
start_urls=['你想要爬的网址的全部url']
6. 配置settings
1) robots.txt 这个文件是一种协议用于告诉爬虫哪些网站你不能爬取
例如: http://baidu.com/robots.txt
默认遵守,要改为False
robots_obey = False
2)用来设置时间延迟
Download_delay = 0.5
3)禁用cookie追踪
Cookie_enable = False
添加(设置User-Agent)
以上这些也是4种反反爬虫的方法与手段
7. 自定义UserAgentMiddleWare
为什么要自定义UserAgentMiddleWare?
因为,在进行爬虫的时候对方服务器会显示的user-agent是scrapy....这样很容易被发现是个爬虫,所以为了防止这种情况需要对scrapy的useragent进行修改.
1)在External Libraries

找到site-packages

找到scrapy

找到downloadermiddlewares

找到useragent.py
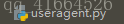
点击查看这个.py文件进行分析,一般来说源码最好不要随意修改乱动,可以将其复制粘贴到爬虫项目的middlewares.py文件中在进行修改.
2) 在middlewares.py文件中
1. 导入用来随机获取user-agent的第三方包
from fake_useragent import UserAgent
2. 对代码进行修改

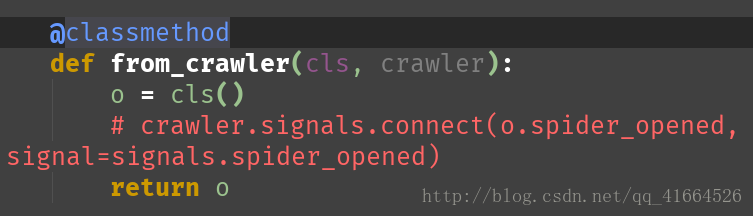


将以上步骤完成以后
在settings.py文件里
对 DOWNLOADER_MIDDLEWARES 进行修改
修改结果时:
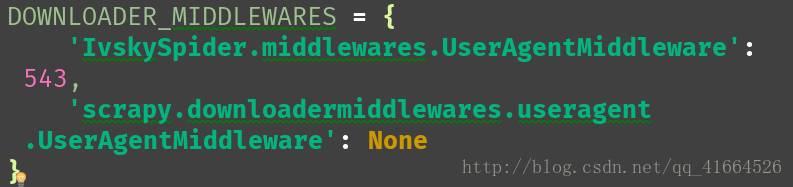
注释: 字典第一个键值对意思是,使用你修改后的useragent文件,来获取useragent
字典第二个键值对意思是,对以前的useragent文件进行限制不使用它,如果你没写这句话,即使第一个字典使用正确但在运行爬虫的时候scrapy框架会自动将这个修改后的useragent文件进行覆盖使用它自带的useragent文件,这样的话对方服务器上的useragent显示还是scrapy......这样就起不到任何的效果了.
对于这个的验证可以使用抓包工具charles来进行查看
查看的位置是:
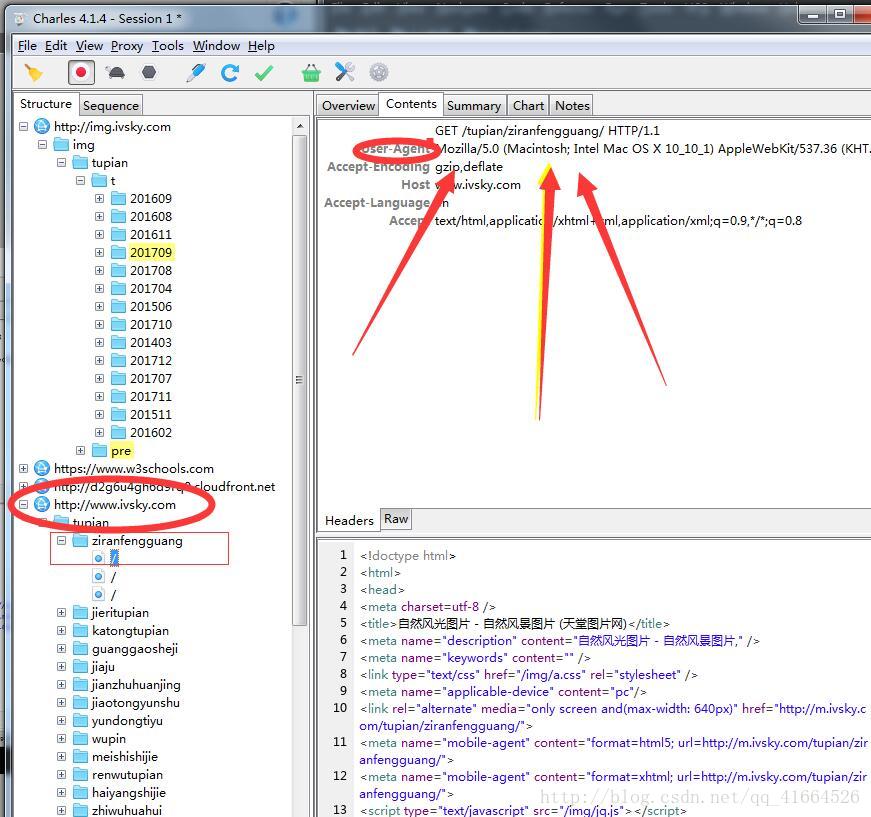
这是运行成功后的抓包获取的useragent,没成功之前这里是scrapy...
8. 开始解析数据
9. 运行爬虫
(这两个操作看博客内容)
1. Scrapy
2.PySpider
3.Selenium(自动化测试的一个框架)
这里主要介绍Scrapy
Scrapy的基本用法:
1. 在cmd中输入pip install scrapy
注意:1.如果安装过程当中提示time out使用以下的命令来安装
pip install -i https://pypi.douban.com/simple scrapy
注释: scrapy是从国外服务器来下载,这里使用国内的网站进行下载,效果更好,速度更快,而且不会出现链接超时等情况.
注意:2.如果安装过程当中提示以下错误:
说明你的电脑上还缺少一个c++14.0这个软件,需要从提示的网址上下载即可.
2. 在cmd中输入pip list 查看所有包中有没有scrapy如果有则说明导入成功!
3. 通过命令创建项目
在cmd中输入
cd Desktop(这里使用的是桌面,也可以自己定义,直接将想要放的位置的路径或者主文件夹拖进来即可,系统会自动生成文件路径)
scrapy startproject Job51Spider(前面两个单词是固定格式,后面一般以网站com之前的名字命名.后面加个Spider表示爬虫项目,也可以用自己的命名方式)
注意: 这里的爬虫命名首字母必须是以字母开头否则会报错
4. 用pycharm打开项目
打开之后一般是这种形式:
这里面的各个.py文件所包含的功能和作用都是不一样的!
以下是它们之间的分工:
5. 通过命令创建爬虫
工具栏 --- View --- Toolwindows --- Terminal
在命令行中输入: scrapy genspider 51job 51job.com
注释: 运行爬虫name为job51的爬虫文件
注意: 这里在输命令的时候要先查看是否已经进入爬虫项目当中否则会报错.
可以用 cd 来一级一级文件名称来添加,来进入爬虫项目中.
一般进入主爬虫项目文件夹即可
提示以下信息说明创建成功:
运行结束后,找到spiders点击a51job
里面的代码是(ivsky就是51job):
一般这里改动的是start_urls,将里面的网址补全齐 start_urls=['你想要爬的网址的全部url']
6. 配置settings
1) robots.txt 这个文件是一种协议用于告诉爬虫哪些网站你不能爬取
例如: http://baidu.com/robots.txt
默认遵守,要改为False
robots_obey = False
2)用来设置时间延迟
Download_delay = 0.5
3)禁用cookie追踪
Cookie_enable = False
添加(设置User-Agent)
以上这些也是4种反反爬虫的方法与手段
7. 自定义UserAgentMiddleWare
为什么要自定义UserAgentMiddleWare?
因为,在进行爬虫的时候对方服务器会显示的user-agent是scrapy....这样很容易被发现是个爬虫,所以为了防止这种情况需要对scrapy的useragent进行修改.
1)在External Libraries
找到site-packages
找到scrapy
找到downloadermiddlewares
找到useragent.py
点击查看这个.py文件进行分析,一般来说源码最好不要随意修改乱动,可以将其复制粘贴到爬虫项目的middlewares.py文件中在进行修改.
2) 在middlewares.py文件中
1. 导入用来随机获取user-agent的第三方包
from fake_useragent import UserAgent
2. 对代码进行修改
将以上步骤完成以后
在settings.py文件里
对 DOWNLOADER_MIDDLEWARES 进行修改
修改结果时:
注释: 字典第一个键值对意思是,使用你修改后的useragent文件,来获取useragent
字典第二个键值对意思是,对以前的useragent文件进行限制不使用它,如果你没写这句话,即使第一个字典使用正确但在运行爬虫的时候scrapy框架会自动将这个修改后的useragent文件进行覆盖使用它自带的useragent文件,这样的话对方服务器上的useragent显示还是scrapy......这样就起不到任何的效果了.
对于这个的验证可以使用抓包工具charles来进行查看
查看的位置是:
这是运行成功后的抓包获取的useragent,没成功之前这里是scrapy...
8. 开始解析数据
9. 运行爬虫
(这两个操作看博客内容)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











