







之前发布了一个对求职信息的网页爬虫,这之后做了一些机器学习的探索,这段时间项目基本介绍了,整理一下发布出来,供大家交流。
3基于逻辑回归的岗位分类器设计
3.1 ;逻辑回归算法简介
假设数据集有n个独立的特征,x1到xn为样本的n个特征。常规的回归算法的目标是拟合出一个多项式函数,使得预测值与真实值的误差最小:
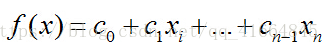
而我们希望这样的f(x)能够具有很好的逻辑判断性质,最好是能够直接表达具有特征x的样本被分到某类的概率。比如f(x)>0.5的时候能够表示x被分为正类,f(x)<0.5表示分为反类。而且我们希望f(x)总在[0, 1]之间。有这样的函数吗?
sigmoid函数就出现了。这个函数的定义如下:
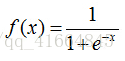
先直观的了解一下,sigmoid函数的图像如下所示:
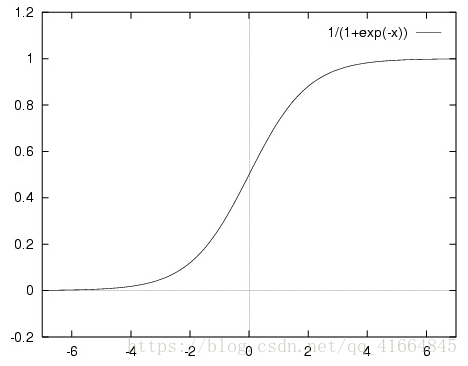
sigmoid函数具有我们需要的一切优美特性,其定义域在全体实数,值域在[0, 1]之间,并且在0点值为0.5。
那么,如何将f(x)转变为sigmoid函数呢?令p(x)=1为具有特征x的样本被分到类别1的概率,则p(x)/[1-p(x)]被定义为让步比(odds ratio)。引入对数:
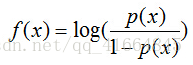
上式很容易就能把p(x)解出来得到下式:
现在,我们得到了需要的sigmoid函数。接下来只需要和往常的线性回归一样,拟合出该式中n个参数c即可。
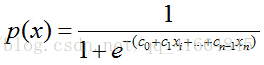
3.2 :算法流程
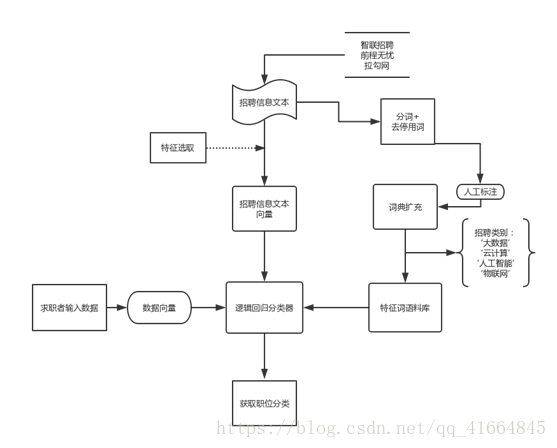
3.3 :算法运用
1数据清洗
数据清洗是整个数据挖掘过程中必不可少的一部分,数据清洗的质量直接影响后续的模型效果和最终结果。从52job、智联招聘利用爬虫爬取的数据都是有噪声的,不完全的和不一致的。在数据清洗的过程中进行填补遗漏数据、清除异常数据、平滑噪声数据和纠正不一致数据。
2.中文分词
英文中,计算机可以很容易的通过空格分辨英文单词。但中文与英文不同,中以字为单位,词是由俩个字或者多个字组成。计算机很难理解哪些是中文的词,把中文的汉字序列切分成有意义的词,就是中文分词。在分词中,我们运用到的工具如下:
分词工具 | 分词粒度 | 出错情况 | 词性标注 | 认证方法 | 接口 |
Nltk | 多选择 | 有 | 有 | 无 | 多语言工具 |
jieba分词 | 多选择 | 无 | 有 | 无 | Python库 |
3.去停用词
在文本挖掘中,为提高算法效率和节省存储空间,一般会把一些过于常用的词,或者没有意义的词去除,这些词是停用词。在我们的系统中采用了中文停用词表,进行去停用词处理。
另外,在词频统计中,从高频词的分布上我们发现大量对分类贡献率低的词,于是我们人为添加一个停用词表
类别 | 分词去停用词后文档示例 |
大数据 | Hadoop 数据挖掘 Hive HBase Spark Storm Flume hadoop Map Reduce... |
云计算 | Openstack TCP IP socket CCNA CCNP Citrix VMware SDN NFV ..... |
人工智能 | 机器学习 深度学习 计算机视觉 自然语言处理 语音处理 神经网络.. |
物联网 | 智慧 物联网 制造 socket FTP 通信 DLNA AireKiss mqtt 5G时代... |
4 TF-IDF算法词向量化
在将招聘信息分词去停用词后我们用TF-IDF特征提取算法来把单词文档转化成向量矩阵,用于逻辑回归训练。
TF-IDF(TermFrequency-Inverse Document Frequency)是一种资讯检索与资讯探勘的常用加权技术。TF-IDF值代表一个词语在体文档中的相对重要性。
| 包含该词的文档数(K) | IDF | TFIDF |
hadoop | 37.8 | 3.421 | 0.0898 |
Openstack | 14.3 | 2.713 | 0.0643 |
计算机视觉 | 2.4 | 0.603 | 0.0121 |
5G通信 | 5.5 | 2.410 | 0.0482 |
5逻辑回归
得到的招聘信息矩阵我们使用机器学习算法逻辑回归对其进行分类训练,保留训练矩阵,在之后网页端,求职者输入其职业技能,对其输入信息进行算法智能分类。在逻辑回归算法特征工程中,我们设置单词贡献率区间max_df=0.95 去除了比如‘数据’‘公司’这类出现几率很高的,但是对分类贡献率很低的词, min_df=2 去除出现频度少于2次的单词。建立了包涵30000个特征词的语料库,在特征词组成上 选取1-4个字组成的单词。
下面是实例代码:
NBmain模块(主模块):
import os
import pandas as pd
import nltk
from NBtools import proc_text, split_train_test, get_word_list_from_data, \
extract_feat_from_data, cal_acc
from nltk.text import TextCollection
from sklearn.linear_model import LogisticRegression
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.model_selection import cross_val_score
import matplotlib.pylab as plt
dataset_path = './dataset'
# 原始数据的csv文件
output_text_filename = '51job.csv'
# 清洗好的文本数据文件
output_cln_text_filename = 'clean_job_text.csv'
# 处理和清洗文本数据的时间较长,通过设置is_first_run进行配置
# 如果是第一次运行需要对原始文本数据进行处理和清洗,需要设为True
# 如果之前已经处理了文本数据,并已经保存了清洗好的文本数据,设为False即可
is_first_run = False
def run_main():
"""
主函数
"""
# 1. 数据读取,处理,清洗,准备
if is_first_run:
print('处理清洗文本数据中...', end=' ')
# 如果是第一次运行需要对原始文本数据进行处理和清洗
# 读取原始文本数据,将标签和文本数据保存成csv
# 读取处理好的csv文件,构造数据集
text_df = pd.read_csv(os.path.join(dataset_path, output_text_filename),usecols = ['岗位分类','岗位需求'],encoding = 'gbk').dropna()
# #字典映射处理类别
# title = {'大数据': 0, '云计算': 1 , '人工智能': 2 ,'物联网': 3}
# text_df['岗位分类'] = text_df['岗位分类'].map(title)
# 处理文本数据
text_df['岗位需求'] = text_df['岗位需求'].apply(proc_text)
# 过滤空字符串
text_df = text_df[text_df['岗位需求'] != '']
# 保存处理好的文本数据
text_df.to_csv(os.path.join(dataset_path, output_cln_text_filename),
index=None, encoding='utf-8')
print('完成,并保存结果。')
# 2. 分割训练集、测试集
print('加载处理好的文本数据')
clean_text_df = pd.read_csv(os.path.join(dataset_path, output_cln_text_filename),
encoding='gbk')
# 分割训练集和测试集
train_text_df, test_text_df = split_train_test(clean_text_df)
# 查看训练集测试集基本信息
print('训练集中各类的数据个数:', train_text_df.groupby('岗位分类').size())
print('测试集中各类的数据个数:', test_text_df.groupby('岗位分类').size())
vectorizer = TfidfVectorizer(
max_df=0.90, min_df=2,
sublinear_tf=True,
token_pattern=r'\w{1,}',
ngram_range=(1, 4),
max_features=30000)
vectorizer.fit(clean_text_df['岗位需求'])
train_features = vectorizer.transform(train_text_df['岗位需求'])
test_features = vectorizer.transform(test_text_df['岗位需求'])
print('TfidfVectorizer done.... start train')
train_target = train_text_df['岗位分类']
classifier = LogisticRegression(solver='sag')
cv_score = np.mean(cross_val_score(
classifier, train_features, train_target, cv=3))
print('对 {} 的准确率是 {}'.format('岗位分类', cv_score))
# # 3. 特征提取
# # 计算词频
# n_common_words = 200
# # 将训练集中的单词拿出来统计词频
# print('统计词频...')
# all_words_in_train = get_word_list_from_data(train_text_df)
# fdisk = nltk.FreqDist(all_words_in_train)
# common_words_freqs = fdisk.most_common(n_common_words)
# print('出现最多的{}个词是:'.format(n_common_words))
# for word, count in common_words_freqs:
# print('{}: {}次'.format(word, count))
# print()
# # 在训练集上提取特征
# text_collection = TextCollection(train_text_df['岗位需求'].values.tolist())
# print('训练样本提取特征...', end=' ')
# train_X, train_y = extract_feat_from_data(train_text_df, text_collection, common_words_freqs)
# print('完成')
# print()
# print('测试样本提取特征...', end=' ')
# test_X, test_y = extract_feat_from_data(test_text_df, text_collection, common_words_freqs)
# print('完成')
# #4. 训练模型Naive Bayes
# print('训练模型...', end=' ')
# #gnb = GaussianNB()
# gnb = LogisticRegression(solver='sag')
# gnb.fit(train_X, train_y)
# print('完成')
# print()
# # 5. 预测
# print('测试模型...', end=' ')
# test_pred = gnb.predict(test_X)
# print('完成')
# # 输出准确率
# print('逻辑回归准确率:', cal_acc(test_y, test_pred))
NBtools导入模块代码:
import re
import jieba.posseg as pseg
import pandas as pd
import math
import numpy as np
# 加载常用停用词
stopwords1 = [line.rstrip() for line in open('./中文停用词库.txt', 'r', encoding='utf-8')]
stopwords2 = [line.rstrip() for line in open('./哈工大停用词表.txt', 'r', encoding='utf-8')]
stopwords = stopwords1 + stopwords2
def proc_text(raw_line):
"""
处理每行的文本数据
返回分词结果
"""
# # 1. 使用正则表达式去除非中文字符
# filter_pattern = re.compile('[^\u4E00-\u9FD5]+')
# chinese_only = filter_pattern.sub('', raw_line)
# 2. 结巴分词+词性标注
words_lst = pseg.cut(raw_line)
# 3. 去除停用词
meaninful_words = []
for word, flag in words_lst:
# if (word not in stopwords) and (flag == 'v'):
# 也可根据词性去除非动词等
if word not in stopwords:
meaninful_words.append(word)
return ' '.join(meaninful_words)
def split_train_test(text_df, size=0.8):
"""
分割训练集和测试集
"""
# 为保证每个类中的数据能在训练集中和测试集中的比例相同,所以需要依次对每个类进行处理
train_text_df = pd.DataFrame()
test_text_df = pd.DataFrame()
#labels = ['大数据', '云计算', '人工智能','物联网']
labels = [0, 1, 2, 3]
for label in labels:
# 找出label的记录
text_df_w_label = text_df[text_df['岗位分类'] == label]
# 重新设置索引,保证每个类的记录是从0开始索引,方便之后的拆分
text_df_w_label = text_df_w_label.reset_index()
# 默认按80%训练集,20%测试集分割
# 这里为了简化操作,取前80%放到训练集中,后20%放到测试集中
# 当然也可以随机拆分80%,20%(尝试实现下DataFrame中的随机拆分)
# 该类数据的行数
n_lines = text_df_w_label.shape[0]
split_line_no = math.floor(n_lines * size)
text_df_w_label_train = text_df_w_label.iloc[:split_line_no, :]
text_df_w_label_test = text_df_w_label.iloc[split_line_no:, :]
# 放入整体训练集,测试集中
train_text_df = train_text_df.append(text_df_w_label_train)
test_text_df = test_text_df.append(text_df_w_label_test)
train_text_df = train_text_df.reset_index()
test_text_df = test_text_df.reset_index()
return train_text_df, test_text_df
def get_word_list_from_data(text_df):
"""
将数据集中的单词放入到一个列表中
"""
word_list = []
for _, r_data in text_df.iterrows():
word_list += r_data['岗位需求'].split(' ')
return word_list
def extract_feat_from_data(text_df, text_collection, common_words_freqs):
"""
特征提取
"""
# 这里只选择TF-IDF特征作为例子
# 可考虑使用词频或其他文本特征作为额外的特征
n_sample = text_df.shape[0]
n_feat = len(common_words_freqs)
common_words = [word for word, _ in common_words_freqs]
# 初始化
X = np.zeros([n_sample, n_feat])
y = np.zeros(n_sample)
print('提取特征...')
for i, r_data in text_df.iterrows():
if (i + 1) % 5000 == 0:
print('已完成{}个样本的特征提取'.format(i + 1))
text = r_data['岗位需求']
feat_vec = []
for word in common_words:
if word in text:
# 如果在高频词中,计算TF-IDF值
tf_idf_val = text_collection.tf_idf(word, text)
else:
tf_idf_val = 0
feat_vec.append(tf_idf_val)
# 赋值
X[i, :] = np.array(feat_vec)
y[i] = int(r_data['岗位分类'])
return X, y
def cal_acc(true_labels, pred_labels):
"""
计算准确率
"""
n_total = len(true_labels)
correct_list = [true_labels[i] == pred_labels[i] for i in range(n_total)]
acc = sum(correct_list) / n_total
return acc
















 748
748

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









