







Learning Knowledge Graph Embedding with Entity Descriptions based on LSTM Networks
基于LSTM网络的实体描述学习知识图嵌入
发表于:2020 IEEE | DOI: 10.1109/ISPCE-CN51288.2020.9321857
摘要:知识推理和知识预测被广泛应用于对产品安全至关重要的智能故障诊断中。大多数学习型知识图嵌入方法都是通过翻译嵌入模型,只使用知识图的事实三元组来表示实体和关系,而没有在实体描述中集成丰富的语义信息。而基于实体描述的DKRL方法在使用CNN编码器模型进行训练时,仅将实体描述的高频词作为输入数据,失去了实体描述中的词序特征和上下文的相关性。本文提出了一种新的基于实体描述的学习知识图嵌入方法——基于LSTM网络的实体描述学习知识图嵌入方法(Learning Knowledge Graph Embedding with Entity Descriptions based on LSTM Networks-KGDL)。将实体描述中每个句子的语序特征与三元语义信息相结合,丰富语义语义表示,促进知识的获取和推理。更具体地说,我们探索LSTM编码器模型,在不丢失实体描述句子之间的语义关联的前提下,基于每个句子对实体描述的所有语义信息进行编码。然后将这些句子嵌入编码为实体描述嵌入,并进一步从包含实体描述嵌入的事实三元组中学习知识图嵌入。实验结果表明,KGDL在平均秩值和HITS@K方面优于目前最先进的方法DKRL,具有较高的准确性、快速性和鲁棒性。此外,基于实体描述的两步关系路径的KGDL在关系预测和实体预测方面具有良好的能力,在知识推理方面优于目前最先进的Path-based TransE方法。
我们使用LSTM模型对实体描述的每个句子中的词序特征进行编码,然后联合TransE模型和LSTM模型将实体描述的句子嵌入和KGs的事实三重结构编码为实体描述嵌入。它可以利用实体描述中每个句子的词序特征,避免失去实体描述的上下文关联。对于KGs的三元组,我们采用典型的平移嵌入方法TransE和PTransE。通过设置权值对模型进行序列训练,得到节点嵌入。
PTransE模型利用KGs的两个实体的关系路径,挖掘隐藏在两个实体之间的间接关系,在低维向量空间中具有良好的关系预测和知识推理能力。研究表明,KGs的关系路径包含丰富的语义信息。
图2显示了使用三元组(Michael Jackson, born in, Indiana) 和三元组(Indiana, located in, America) 来导出名为Michael Jackson的头实体和名为America的尾实体之间名为国籍的新关系的示例。

目前,还没有将实体描述的语义信息加入到低维向量空间的两步关系路径知识推理方法的研究工作。
基于实体描述的嵌入方法:
DKRL算法可以从具有实体描述的KGs中自动学习实体的嵌入和关系,该算法是2016年提出的。基于DKRL的嵌入学习具有更强的语义表示和识别能力,可以有效缓解知识库的稀疏问题,更有利于促进知识库的完成。图3显示了具有相同语义向量空间中实体描述的三元组(Michael_Jackson, publish_song, Breaking_News)的实体嵌入和关系嵌入。

如何从具有实体描述的知识库中自动学习实体嵌入和关系嵌入,以及如何对实体描述的每个句子中的语序特征进行编码是本文研究的核心问题。本文提出的基于LSTM网络实体描述的学习知识图嵌入算法(KGDL)将实体描述和事实三元组中每个句子的词序特征的语义信息整合在一起。在接下来的小节中,将详细介绍KGDL的动机、LSTM编码器模型、KGDL的总体架构以及它的训练。
DKRL算法采用CNN和TransE序列训练,只选取实体描述中排名前N的高频词,用Word2V ec模型作为输入对这些关键词进行编码。由于DKRL模型仅以实体描述中出现频率最高的N个关键词作为输入,实体描述的每个句子中的词序特征和上下文的相关性都存在严重的语义信息丢失。
为此,我们提出了一种编码实体描述的所有语义信息和实体描述每个句子中的词序特征的方法,该方法不丢失实体描述每个句子中的词序特征和实体描述各句子之间的语义关联。并进一步学习从具有实体描述的事实三元组中嵌入知识图。我们使用LSTM模型学习句子嵌入,并将这些包含事实三元组的句子嵌入编码为实体描述嵌入。一般情况下,我们将LSTM和翻译嵌入模型结合在一起进行训练,得到KGs的联合实体向量和关系向量,其中既包含事实三元语义信息,又包含实体描述的每句句子中具有词序特征的完整语义信息。
为此,我们提出了一种编码实体描述的所有语义信息和实体描述每个句子中的词序特征的方法,该方法不丢失实体描述每个句子中的词序特征和实体描述各句子之间的语义关联。并进一步学习从具有实体描述的事实三元组中嵌入知识图。我们使用LSTM模型学习句子嵌入,并将这些包含事实三元组的句子嵌入编码为实体描述嵌入。一般情况下,我们将LSTM和翻译嵌入模型结合在一起进行训练,得到KGs的联合实体向量和关系向量,其中既包含事实三元语义信息,又包含实体描述的每句句子中具有词序特征的完整语义信息。
为了将事实三元组和实体描述结合起来,KGDL试图使输出嵌入包含文本实体描述和事实三元组中每个句子的词序特征的所有句子语义信息。KGDL的输入是KGs中的实体描述和事实三元组,我们采用TransE模型和PtransE模型结合LSTM模型,对三元组和实体描述进行串行训练。具体来说,我们采用TransE模型和PTransE模型来训练事实三元组,使用LSTM模型来训练KGs的实体描述,我们将KGDL(TransE)的能量函数E定义为:
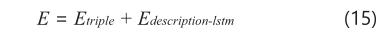
Etriple是TransE的能量分数,Edescription-lstm是具有实体描述的三元组能量函数。
定义KGDL的评分函数G(h,r,t)
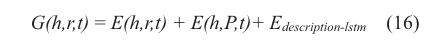
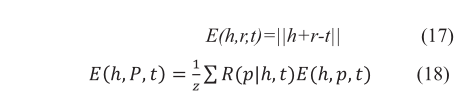
其中E(h,r,t)等于公式(17)中的Etriple。E(h,P,t)是以路径概率信息为权值的三元组的路径向量所组成的能量函数的平均值。能量函数是头部实体向量加上路径向量p到尾部实体的距离。
R(p | h , t)为给定头部实体对路径(r,t)的可靠性权重,由PCRA计算。Z是归一化参数。本文提出了KGDL算法中的联合向量vJ,定义为:
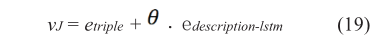
Θ是合并两个模型的权重,Etriple表示从TransE模型或PTransE模型中得到三元组向量 ,Edescription-lstm表示实体描述中的实体向量,由LSTM模型得到。KGDL算法的总体架构如图5所示。

训练集包含实体描述和事实三元组。首先用Xavier初始化方法初始化基于三元组结构的实体向量、关系向量和基于实体描述的实体向量,确保数据相互独立,数据分布大致相同。然后,采用随机梯度下降(minibatch)方法和负采样方法构造训练样本,利用KGDL模型得到实体向量。在串行训练中,计算各损失函数值L:

我们向L值递减的方向更新实体向量和关系向量,γ为边距参数。d(h+r,t)是h+r和t之间的L1距离。S为正采样,S’为负采样。
链接预测结果:

个人总结:本文通过将TransE或P-TransE的向量于LSTM的实体描述向量进行加权相加,得到一个新的向量,算是在传统的嵌入模型上添加了语义的信息,本文对于二步关系的描述与之前的路径上下文相似,或许可以通过这种方法实现添加关系信息。
















 1584
1584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









