







0.Summary:
Title: Learning Knowledge Graph Embedding With Heterogeneous Relation Attention Networks
Journal: IEEE TRANSACTIONS ON NEURAL NETWORKS AND LEARNING SYSTEMS 2021
JCR: 1区
IF:8.591
Abstract:
图嵌入是为了更好的保留图的固有结构,图神经网络在图嵌入有着接触的性能。
但是知识图谱存在内在的异质性( heterogeneity),因此如何在处理复杂图数据的同时聚合多类型的语义信息便是一个关键问题。
在这篇论文中,提出了一个基于注意力的异构GNNs框架,具体来说:首先便是在每一个关系的路径下聚合实体的相邻特征,然后通过关系特征学习不同关系路径的重要性。最后,将每个基于关系路径的特征与学习的权重值进行聚合来生成嵌入表示。因此这个方法不仅仅是通过不同的语义聚合实体特征,还为其分配权重。这一方法可以捕捉各种语义信息并选择聚类信息特征
文章目录
1.引文
1.1 简介
知识图谱的结构,虽然包含了大量的实体关系和三元组,但人仍然存在比如完整性,局部性和新增知识等问题,为了克服这些问题,研究者看向了连接预测。
( link prediction)旨在预测图谱中丢失的真相。已存在的连接预测方法被称为图谱嵌入(KGE : KG embedding)KGE学习关系和实体的嵌入表达,以保持KGs的固有结构。然后利用这些嵌入来促进后续的链路预测任务。
但是,以前很少有KGE方法具有结构强制并将连接结构纳入嵌入空间。相比之下,**图神经网络(GNN)**可以有效地聚合每个节点的局部信息
为什么:
1.GNN作为图形数据的表示学习工具,可以利用与节点相关的邻居特征
2.通过施加相同的聚合函数,可以提高卷积计算的学习效率
但是,KG通常具有多种类型的实体和关系,被广泛称为异构信息网络,实体在不同的关系下表现不同的语义特征,**因此,**传统的GNN方法不能直接应用于KGs,必须要解决以下问题
要解决的问题:
1.知识图谱的异构性,如何保留多个特征信息
2.关系的重要性,如何融合语义特征以及如何选择有意义的路径并分配权重
3.聚合器的影响,由于图结构的数据的无序性,聚合器通常运行在无序的特征向量上,因此需要研究不同聚合器对性能的影响。
基于上述分析,本文提出了一个新的异构关系注意力网络学习框架HRAN,其首先融合每个基于关系路径的实体的用于表示语义的特征。然后通过到实体的不同关系路径聚合这些特征。之后利用注意力机制获得不同关系路径的权重值。基于每个关系路径的学习注意力值,我们的方法可以在层次结构中聚合适当的邻居特征组合。因此,聚合实体特征可以有效地处理异构KG中丰富的语义信息和复杂的结构。
1.2 相关工作
1.介绍了图神经网络和注意力机制的研究成果 ,但这些GNN的研究都不能直接应用到异构的知识图谱中
2.介绍了几种经典的知识图谱嵌入方法,比如TransE及其变体,但其学习的表达特征较少,限制了其性能。介绍了神经网络在KGE中的研究,但存在没有考虑图异构型和注意力的问题
3.HRAN遵循层次结构,包括实体级聚合、关系级聚合和三重态预测,并给出了主要符号
2 预备工作
2.1 链路预测
G = ( ε , R , T ) w h e r e ε = { e 1 , e 2 , … , e ∣ ε ∣ } a n d R = { r 1 , r 2 , … , r ∣ R ∣ } 表示实体和关系集 T ⊆ ε 表示三元组的集合 × R × ε 表示三元组的集合 e s , r , e 0 ∈ R d 表示其的 d 维嵌入 G = (\varepsilon,R,T) \\ where\\ \ \varepsilon = \{ e_1,e_2,…,e_{|\varepsilon|}\}\ and \ R = \{r_1,r_2,…,r_{|R|}\} 表示实体和关系集\\ T\subseteq \varepsilon 表示三元组的集合 \times R \times \varepsilon \ \ 表示三元组的集合\\ \bold e_s,\bold r,\bold e_0 \in R^d 表示其的d维嵌入 G=(ε,R,T)where ε={e1,e2,…,e∣ε∣} and R={r1,r2,…,r∣R∣}表示实体和关系集T⊆ε表示三元组的集合×R×ε 表示三元组的集合es,r,e0∈Rd表示其的d维嵌入
对于给定一个特定关系的实体,链路预测旨在预测另一个能组成正确三元组的实体,优化的目的通常是评分正确的三元组高于不正确的三元组
HRAN框架
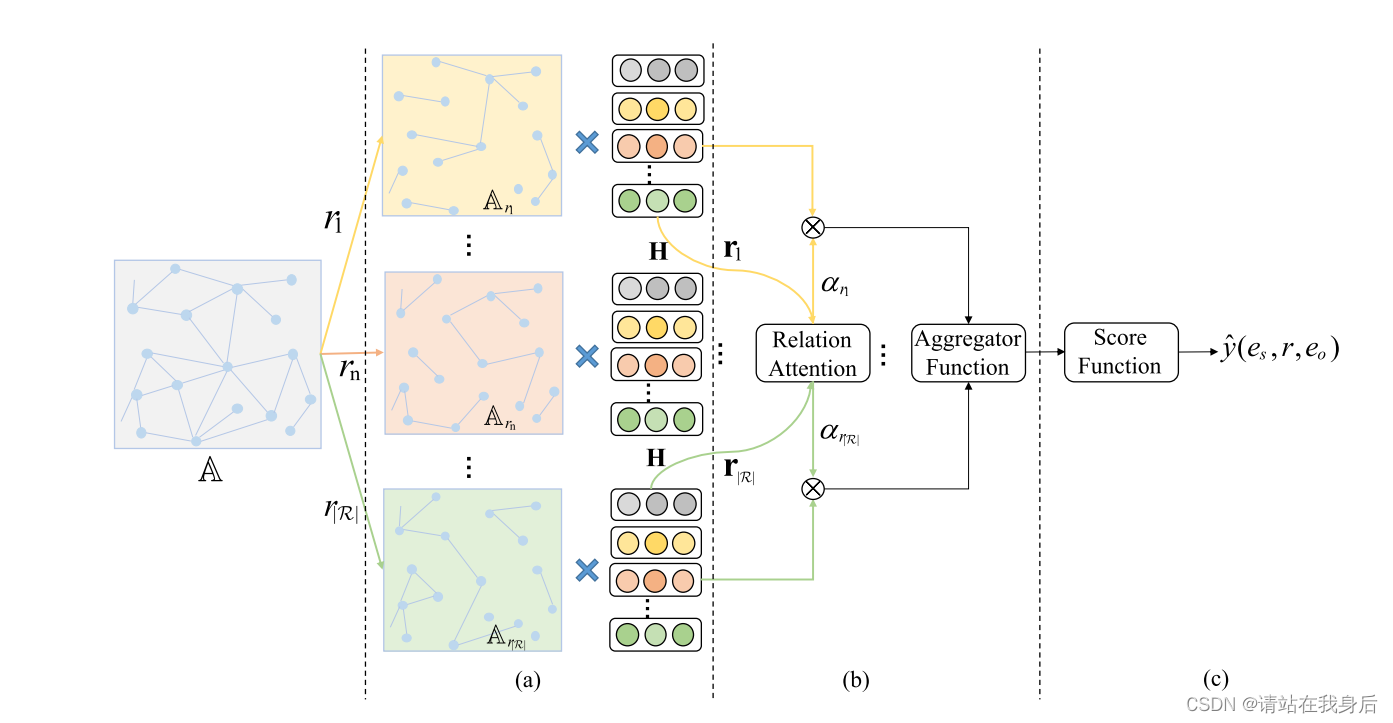
(a) 首先,根据每个基于关系路径的邻接矩阵聚合实体的基于关系路径的邻居。
(b) 然后,通过不同的聚合函数聚合具有每个关系路径的学习权重的聚合信息。
(c) 最后利用分数函数提供三元组是否正确的概率预测。
(a) 实体级聚合。(b) 关系级聚合。(c) 三重态预测。
2.2 图卷积
在本文中,图卷积被用来聚合节点特征以及为连接预测生成嵌入
令 H代表节点特征矩阵,则前向传播可以写成:
H
(
l
)
=
f
(
D
~
−
1
2
A
~
D
~
−
1
2
H
(
l
−
1
)
W
(
l
)
)
f
是激活函数
A
~
=
(
A
+
I
)
∈
R
∣
ε
∣
×
∣
ε
∣
代表
G
的邻接矩阵
D
~
代表
A
~
的度量矩阵
D
~
i
i
=
∑
j
A
~
i
j
H^{(l)} = f(\tilde D^{-\frac12}\tilde A \tilde D^{-\frac12}H^{(l-1)}W^{(l)})\\ f 是激活函数 \tilde A = (A+I)\in R^{|\varepsilon|\times|\varepsilon|} 代表G的邻接矩阵\\ \tilde D 代表\tilde A的度量矩阵\tilde D_{ii}=\sum_j \tilde A_{ij}
H(l)=f(D~−21A~D~−21H(l−1)W(l))f是激活函数A~=(A+I)∈R∣ε∣×∣ε∣代表G的邻接矩阵D~代表A~的度量矩阵D~ii=j∑A~ij
对于非对称邻接矩阵的有向图D,可以通过逆矩阵归一化A
H
(
l
)
=
f
(
D
~
−
1
A
~
H
(
l
−
1
)
W
(
l
)
)
H^{(l)}=f(\tilde D ^{-1}\tilde AH^{(l-1)}W^{(l)})
H(l)=f(D~−1A~H(l−1)W(l))
上述卷积公式是为了处理异构图结构数据,因为关系和关系路径实体是两种基础元素,一个新的异构图数据GNN框架是捕捉其内在差异的必要条件
3 模型
3.1 实体类聚合
由于异构性,不适合直接进行聚类。因此提出实体类聚合,首先聚合每一个基于关系路径的实体特征
基于h和r作为初始实体和关系特征,我们首先融合每个基于关系路径的实体特征,等式如下:
h
N
(
e
)
r
(
l
−
1
)
=
Θ
a
g
g
(
{
h
i
(
l
−
1
)
∀
i
∈
N
(
e
)
r
}
)
∀
r
∈
R
w
h
e
r
e
N
e
r
代表基于关系实体的集合
h
代表着基于路径
r
聚合的特征
\bold h^{(l-1)}_{N^r_{(e)}}=\Theta_{agg}(\{ \bold h ^{(l-1)} _i \forall i\in N^r_{(e)}\}) \ \forall r \in R\\ where \ N^r_e 代表基于关系实体的集合 \\h代表着基于路径r聚合的特征
hN(e)r(l−1)=Θagg({hi(l−1)∀i∈N(e)r}) ∀r∈Rwhere Ner代表基于关系实体的集合h代表着基于路径r聚合的特征
在本文中,聚合函数\theta 在实体类中紧挨着GCN 因此可以写成
h
N
(
e
)
r
(
l
−
1
)
=
1
∣
N
(
e
)
r
∣
(
∑
i
∈
N
(
e
)
r
h
i
(
l
−
1
)
)
∀
r
∈
R
w
h
e
r
e
h
代表着依靠关系路径的相邻节点特征,
这些特征被加在一起并被标准化函数
N
处理
h^{(l-1)}_{N^r_{(e)}}=\frac1{|N^r_{(e)}|}(\sum_{i\in N^r_{(e)}}h_i^{(l-1)}) \ \ \forall r \in R\\ where\ h 代表着依靠关系路径的相邻节点特征,\\这些特征被加在一起并被标准化函数N处理
hN(e)r(l−1)=∣N(e)r∣1(i∈N(e)r∑hi(l−1)) ∀r∈Rwhere h代表着依靠关系路径的相邻节点特征,这些特征被加在一起并被标准化函数N处理
因此 h通过单个关系生成路径,每个路径都是语义特定的,可以捕获一种语义信息
3.2 关系类聚合
在关系级聚合部分,通过与实体相关的关系路径聚合各种类型的语义信息。由于KG的异构性,实体反映了多种类型的语义信息。每个特定于语义的聚合特征只能捕获来自一个方面的信息,因此需要多个特征。
此外,需要获取不同关系路径的权重,然后加以利用
为了里哦阿姐不同关系路径的权重,使用实体类聚合特征的R作为输入,每个关系路径{r}的权重可以表示为:
{
a
r
1
(
l
−
1
)
,
…
,
a
r
∣
R
∣
(
l
−
1
)
}
=
Θ
a
t
t
{
r
r
1
(
l
−
1
)
,
…
,
r
r
∣
R
∣
(
l
−
1
)
}
i
n
w
h
i
c
h
a
r
(
l
−
1
)
=
Θ
a
t
t
(
{
r
r
1
(
l
−
1
)
∀
r
∈
R
}
)
其中
Θ
a
t
t
代表着通过深层神经网络设计的注意力机制,
可以捕捉权重以及利用权重选择性的聚合信息特征
\{ a_{r_1}^{(l-1)},…, a_{r_{|R|}}^{(l-1)}\} = \Theta_{att}\{ r_{r_1}^{(l-1)},…, r_{r_{|R|}}^{(l-1)}\}\\in\ which\\a^{(l-1)}_r = \Theta_{att}(\{ r_{r1}^{(l-1)}\forall r \in R \})\\ 其中 \Theta_{att}代表着通过深层神经网络设计的注意力机制,\\可以捕捉权重以及利用权重选择性的聚合信息特征
{ar1(l−1),…,ar∣R∣(l−1)}=Θatt{rr1(l−1),…,rr∣R∣(l−1)}in whichar(l−1)=Θatt({rr1(l−1)∀r∈R})其中Θatt代表着通过深层神经网络设计的注意力机制,可以捕捉权重以及利用权重选择性的聚合信息特征
为了学习每个关系路径的权重,一个非线性的转变(比如一层MLP)首先被用来转换关系的特定特征r,然后利用权重向量q度量关系特异性特征的重要性,通过激活函数得到最终a ,这个过程表示如下
a
r
(
r
−
1
)
=
σ
(
q
T
t
a
n
h
(
W
r
r
(
l
−
1
)
+
b
)
)
∀
r
∈
R
a_r^{(r-1)} = \sigma (\bold q^T tanh(\bold{Wr}_r^{(l-1)}+\bold b))\forall r \in R
ar(r−1)=σ(qTtanh(Wrr(l−1)+b))∀r∈R
W表示变换权重矩阵,b表示偏差相邻,q表示注意向量,显然,与重要的关系r,学习到的a函数越高
在获得每个关系路径的重要性后,可以使用学习的α(l)对每个基于关系路径的聚合特征进行加权,然后,可以连接和融合所有基于关系路径的聚合邻居特征获得每个实体的最终聚合邻居特征,如下所示
h
N
(
e
)
(
l
−
1
)
=
Θ
a
g
g
(
C
O
N
C
A
T
{
a
r
h
N
(
e
)
r
(
l
−
1
)
∀
r
∈
R
}
)
h_{N_{(e)}}^{(l-1)} = \Theta _{agg}(CONCAT\{ a_rh_{N_{(e)}^r}^{(l-1)} \forall r \in R\})
hN(e)(l−1)=Θagg(CONCAT{arhN(e)r(l−1)∀r∈R})
CONCAT表示卷积操作,Theta表示聚合器函数,在训练期间,平均值、最大值、总和的三种方法如下:
h
N
(
e
)
(
l
−
1
)
=
{
1
∣
r
∣
∑
l
d
∑
∀
r
∈
R
(
a
r
h
N
(
e
)
r
(
l
−
1
)
)
m
a
x
(
C
O
N
C
A
T
{
a
r
h
N
(
e
)
r
(
l
−
1
)
∀
r
∈
R
}
)
∑
l
d
∑
∀
r
∈
R
(
a
r
h
N
(
e
)
r
(
l
−
1
)
h_{N_{(e)}}^{(l-1)} = \begin{cases} \frac 1{|r|}\sum \limits _l ^d\sum \limits_{\forall r \in R}(a_r\bold h_{N_{(e)}^r}^{(l-1)})\\ max(CONCAT\{a_r h_{N_{(e)}^r}^{(l-1)}\forall r \in R\})\\ \sum \limits _l ^d\sum \limits_{\forall r \in R}(a_r\bold h_{N_{(e)}^r}^{(l-1)} \end{cases}
hN(e)(l−1)=⎩
⎨
⎧∣r∣1l∑d∀r∈R∑(arhN(e)r(l−1))max(CONCAT{arhN(e)r(l−1)∀r∈R})l∑d∀r∈R∑(arhN(e)r(l−1)
其中d 代表着d-尺寸特征,总和聚合器近似于GCN框架中使用的聚合器函数,均值和最大聚集起收到CNN池化层的启发,图卷积传播可以通过非线性变换更新为:
{
h
e
(
l
)
=
f
(
W
(
l
)
h
N
(
e
)
(
l
−
1
)
)
r
r
(
l
)
=
f
(
W
(
l
)
r
r
(
l
−
1
)
)
\begin{cases} \bold h_e^{(l)} = f(W^{(l)}h_{N_{(e)}}^{(l-1)})\\ \bold r_r^{(l)}=f(W^{(l)}r_r^{(l-1)}) \end{cases}
{he(l)=f(W(l)hN(e)(l−1))rr(l)=f(W(l)rr(l−1))
其中W 为特定实体和关系的连接系数矩阵,f为校正线性单元(ReLU),然而,可以观察到,所有相邻特征在h_N中融合,而不是h_e本身中,因此需要将自循环纳入卷积传播中,此外,为了让方法更加灵活,入了超参数β,命名为子注意力值,将h_e重新定义为:
h
e
(
l
)
=
f
(
W
(
l
)
(
(
1
−
β
)
h
N
(
e
)
(
l
−
1
)
+
β
h
e
(
l
−
1
)
)
)
\bold h_e^{(l)} = f(W^{(l)}((1-\beta)h_{N_{(e)}}^{(l-1)}+\beta h_e^{(l-1)}))\\
he(l)=f(W(l)((1−β)hN(e)(l−1)+βhe(l−1)))
其中 β决定尸体特征在自循环中的保留率,最终我们可以得到所有实体特征h和关系特征r ,在最后一层获取嵌入矩阵,将其表示为
{
E
=
C
O
N
C
A
T
{
h
e
(
L
)
∀
e
∈
ε
}
R
=
C
O
N
C
A
T
{
r
r
(
L
)
∀
r
∈
R
}
\begin{cases} E = CONCAT\{ h_e^{(L)}\forall e \in \varepsilon\}\\ R = CONCAT\{ r_r^{(L)}\forall r \in R\} \end{cases}
{E=CONCAT{he(L)∀e∈ε}R=CONCAT{rr(L)∀r∈R}
比起先前的基于GCN的方法,提出的实体聚合和关系聚合可以从各种与一方面通过不同的关系路径聚合实体特征,其次,注意力机制被用于选择聚合信息特征,过程如下列算法1所示:

3.3 三重态预测
为了解决知识图谱中多个关系类,引入了一种新的基于CNN的分数函数,称为卷积动态神经网络(ConvD)为每个就与关系的三元组生成特定于关系的过滤器,借此提取所有主题实体特定于关系的语义特征。
给定一个三元组输入,首先必须确定没一个实体和关系在矩阵E,R中的嵌入
e
s
=
x
e
T
E
,
r
=
x
r
T
R
,
a
n
d
e
o
=
x
e
0
T
E
e_s =x_e^TE,r=x_r^TR,and \ e_o = x_{e_0}^TE
es=xeTE,r=xrTR,and eo=xe0TE
其中x代表e,r的高维向量,输入矩阵M可以通过目标实体e 和关系r 获得
M
=
C
O
N
C
A
T
{
e
s
,
r
}
M = CONCAT\{e_s,r\}
M=CONCAT{es,r}
然后,通过N个不同的滤波器在输入矩阵M上实现卷积运算来生成特征图谱V
v
n
(
i
,
j
)
=
(
M
∗
Ω
r
n
)
(
i
,
j
)
=
∑
a
=
1
h
∑
b
=
1
w
M
(
i
+
a
,
j
+
b
)
Ω
r
n
(
a
,
b
)
v_n^{(i,j)}=(M*\Omega_r^n)(i,j)=\sum\limits_{a=1}^h\sum\limits_{b=1}^wM(i+a,j+b)\Omega_r^n(a,b)
vn(i,j)=(M∗Ωrn)(i,j)=a=1∑hb=1∑wM(i+a,j+b)Ωrn(a,b)
其中*表示卷积运算,Oedema 代表着有着高度h和宽度w的特定关系卷积过滤层,此外v是输出的特征图谱 其中H=2-h+1,W=d-w+1
在预测连接对象实体e时,输出的特则会那个图谱被展开并投影到d维向量中,该向量包含实体e和关系r之间潜在的语义连接,然后ConvD分数函数可以定义为
ψ
(
e
s
,
r
,
e
0
)
=
f
(
(
v
e
c
)
f
(
V
)
W
)
)
e
0
\psi(e_s,r,e_0)=f((vec)f(V)W))e_0
ψ(es,r,e0)=f((vec)f(V)W))e0
vec(x)表示展开操作,W是完全连接的变换矩阵,用于重新校准特征映射投影到d维向量,然后用于对候补对象实体进行评分,评分函数可以定义为
p
s
i
(
e
s
,
r
,
e
0
)
=
f
(
v
e
c
(
f
(
C
O
N
C
A
T
{
e
s
,
r
}
∗
Ω
)
)
W
)
e
0
\\psi(e_s,r,e_0)=f(vec(f(CONCAT\{e_s,r\}*\Omega))W)e_0
psi(es,r,e0)=f(vec(f(CONCAT{es,r}∗Ω))W)e0
最终,三元组的预测概率定义为:
y
~
(
e
s
,
r
,
e
0
)
=
σ
(
ψ
(
e
s
,
r
,
e
0
)
+
b
)
∈
(
0
,
1
)
\tilde y(e_s,r,e_0)=\sigma(\psi (e_s,r,e_0)+b)\in (0,1)
y~(es,r,e0)=σ(ψ(es,r,e0)+b)∈(0,1)
其中b代表着偏置项
在以前的方法中,ConvD没有采用共享过滤器,而是旨在生成特定于关系的(动态)过滤器,从而从主题中提取特定于关系的特征
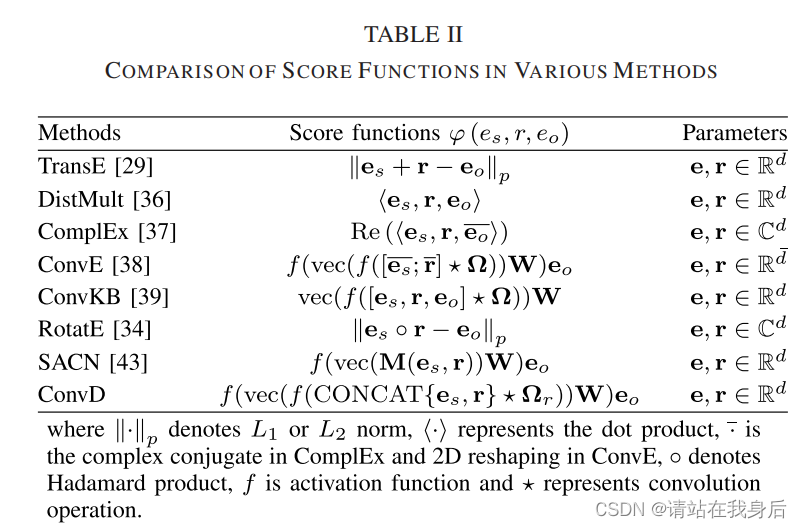
训练过程表现在算法2中,集中最先进的方法总结在表二中

3.4 训练目标
在HRAN中,它打算在给定所有方法参数的情况下,最大化似然函数p(G|Θ),如果三元组正确,则可能性y为1 ,反之为0,因此似然函数被定义为伯努利分布
p
(
G
∣
Θ
)
=
∏
(
e
s
,
r
,
e
o
)
∈
T
(
e
s
,
r
,
e
o
)
∈
T
(
y
~
(
e
s
,
r
,
e
0
)
)
y
(
1
−
y
~
(
e
s
,
r
,
e
0
)
)
1
−
y
y
=
{
1
i
f
(
e
s
,
r
,
e
0
∈
T
)
0
i
f
(
e
s
,
r
,
e
0
∈
T
′
)
p(G|\Theta) = \prod\limits_{(e_s,r,e_o )∈T\\(e_s,r,e_o )∈T}(\tilde y(e_s,r,e_0))^y(1-\tilde y (e_s,r,e_0))^{1-y}\\ y = \begin{cases} 1\ if(e_s,r,e_0\in T)\\ 0\ if(e_s,r,e_0\in T^\prime) \end {cases}
p(G∣Θ)=(es,r,eo)∈T(es,r,eo)∈T∏(y~(es,r,e0))y(1−y~(es,r,e0))1−yy={1 if(es,r,e0∈T)0 if(es,r,e0∈T′)
HRAN的损失函数可以定义如下:
m
i
n
L
=
−
l
o
g
p
(
G
∣
Θ
)
=
−
∑
(
e
s
,
r
,
e
o
)
∈
T
(
e
s
,
r
,
e
o
)
∈
T
(
y
l
o
g
y
~
(
e
s
,
r
,
e
0
)
+
(
1
−
y
)
l
o
g
(
1
−
y
~
(
e
s
,
r
,
e
0
)
)
)
min\ L = − log\ p(G|\Theta)\\=-\sum\limits_{(e_s,r,e_o )∈T\\(e_s,r,e_o )∈T}(ylog\ \tilde y(e_s,r,e_0)+(1-y)log(1-\tilde y(e_s,r,e_0)))
min L=−log p(G∣Θ)=−(es,r,eo)∈T(es,r,eo)∈T∑(ylog y~(es,r,e0)+(1−y)log(1−y~(es,r,e0)))
并使用 dropout对HRAN进行正则化,在每一层之后使用Batch就进行归一化,提高算法的精准度,避免过拟合,提高泛化能力,本文使用Adam optimizer对损失函数进行优化。
4 实验
在本文将HRAN与几种连接预测最先进的方法进行评估,来回答以下问题
1.异构GNNs生成的实体和关系嵌入能否有效预测KG中的缺失连接?
2.基于关系路径的注意机制在整个方法框架中的作用是什么?
3.使用不同的聚合器函数对链路预测性能有何影响?
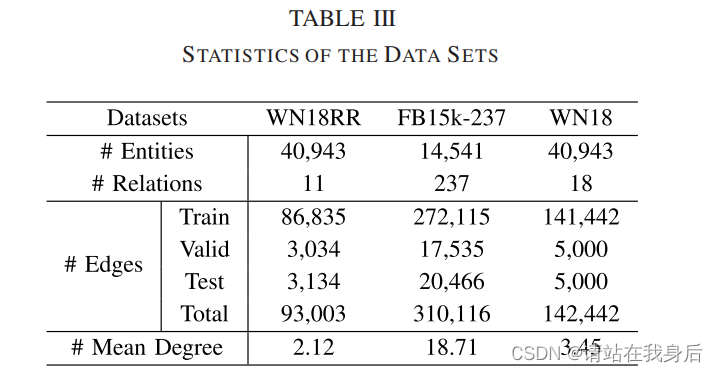
数据集统计如下
4.1 常规设置:
1)评估指标:遵循TransE的过滤设置,对于第i个测试三元组x_i ,通过将实体换成其他所有实体来获取其所有可能的错误三元组,然后看其是否在x_i获得高分,在错误三元组获得低分, 第i个测试三元组的左秩和右秩都与破坏分数函数下的主体或客体实体相关,如下所示:
{
r
a
n
k
i
s
=
(
∑
x
~
i
s
∉
T
t
e
s
t
I
[
ψ
(
x
i
)
<
ψ
(
x
~
i
s
)
]
)
+
1
r
a
n
k
i
o
=
(
∑
x
~
i
o
∉
T
t
e
s
t
I
[
ψ
(
x
i
)
<
ψ
(
x
~
i
o
)
]
)
+
1
\begin{cases} rank_i^s = (\sum\limits_{\tilde x _i^s \notin T_{test}}I[\psi (x_i) < \psi(\tilde x_i^s)])+1\\ rank_i^o= (\sum\limits_{\tilde x _i^o \notin T_{test}}I[\psi (x_i) < \psi(\tilde x_i^o)])+1 \end{cases}
⎩
⎨
⎧rankis=(x~is∈/Ttest∑I[ψ(xi)<ψ(x~is)])+1rankio=(x~io∈/Ttest∑I[ψ(xi)<ψ(x~io)])+1
其中 I为指示符函数,为真则返回1,否则为0,三个通用的评估矩阵用来衡量预测精度,包括平均秩( mean rank (MR)平均倒数秩(,mean reciprocal rank (MRR)),以及Hits@k (for k = 1, 3, and 10)
{
M
R
:
1
2
∣
T
t
e
s
t
∣
∑
x
i
∈
T
t
e
s
t
(
r
a
n
k
i
s
+
r
a
n
k
i
o
)
M
R
r
:
1
2
∣
T
t
e
s
t
∣
∑
x
i
∈
T
t
e
s
t
(
1
r
a
n
k
i
s
+
1
r
a
n
k
i
o
)
H
i
t
s
@
k
:
1
2
∣
T
t
e
s
t
∣
∑
x
i
∈
T
t
e
s
t
I
[
r
a
n
k
i
s
<
=
k
]
+
I
[
r
a
n
k
i
o
<
=
k
]
\begin{cases} MR: \frac1{2|T_{test|}} \sum\limits_{x_i\in T_{test}}(rank_i^s+rank_i^o)\\ MRr: \frac1{2|T_{test|}} \sum\limits_{x_i\in T_{test}}(\frac1 {rank_i^s}+\frac1{rank_i^o})\\ Hits@k: \frac1{2|T_{test|}} \sum\limits_{x_i\in T_{test}}I[rank_i^s <=k]+I[rank_i^o<=k] \end{cases}
⎩
⎨
⎧MR:2∣Ttest∣1xi∈Ttest∑(rankis+rankio)MRr:2∣Ttest∣1xi∈Ttest∑(rankis1+rankio1)Hits@k:2∣Ttest∣1xi∈Ttest∑I[rankis<=k]+I[rankio<=k]
MR的值越低,或者MRR越高,或者Hit@k为1,则性能越好
2)数据集:本文使用以下数据集WN18、FB15k-237和WN18RR,每一个都包含大量实体和关系,分为训练集,有效集和测试集
3)比较方法为了验证方法的性能,选用集中先进方法进行比较,包括基于翻译距离的方法,基于语义匹配的方法,和基于神经网络的方法。
4)实现细节:对HRN和HRAN的实验,选择网格搜索选择的超参数如下:嵌入维度200,层深1,自注意力值:0.5,聚合函数sum,过滤器数目48,过滤器大小【2 * 1/2 * 7】,标签平滑0.1,批量大小128,学习率0.001,放弃率:1.3
4.2 连接预测结果
根据表示显示,HRAN总体上优于其他方法,
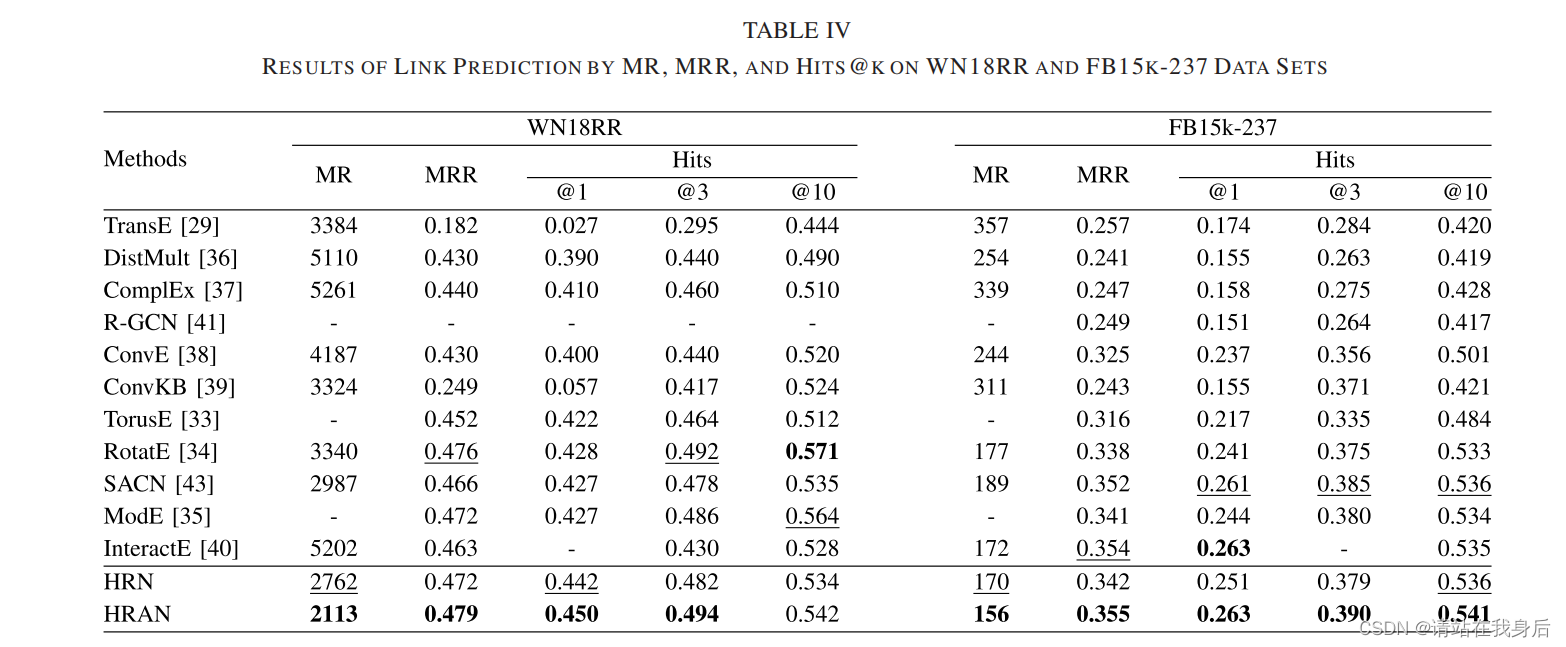
且根据图3所示,两者都不容易产生过拟合问题,证明了网络框架的解释性和健壮性
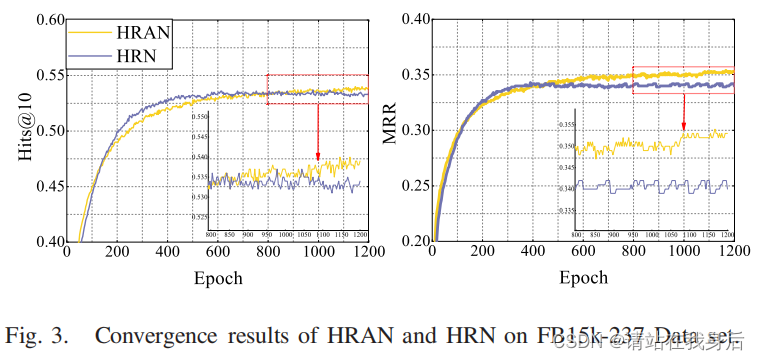
结果表明,有必要关注异构图中的一些重要关系路径。
4.3 注意机制的作用
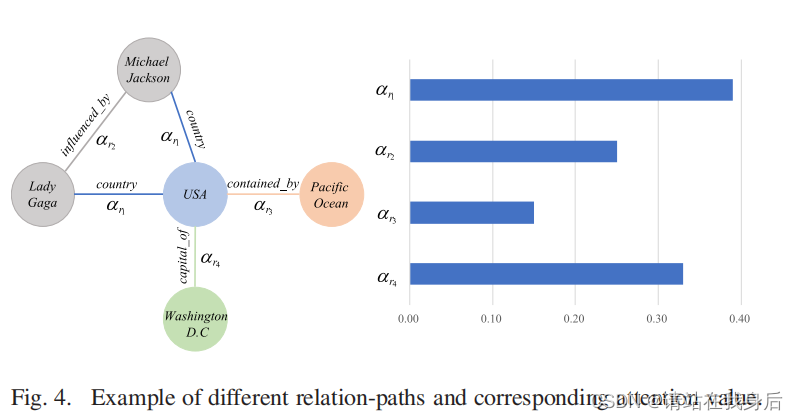
图4中报告了几个关系路径和相应的注意力值。显然,单一关系路径与其注意力值呈正相关。对于的关系路径country和capital_of,给出了更高的关注值,这表明HRAN认为这两个关系更重要,结果表明,注意力机制可以揭示这些关系之间的差异,并进行加权来进行选择性的聚合信息
在表6中,度数较高的实体表示其包含更多的相邻实体,及更复杂的语义信息
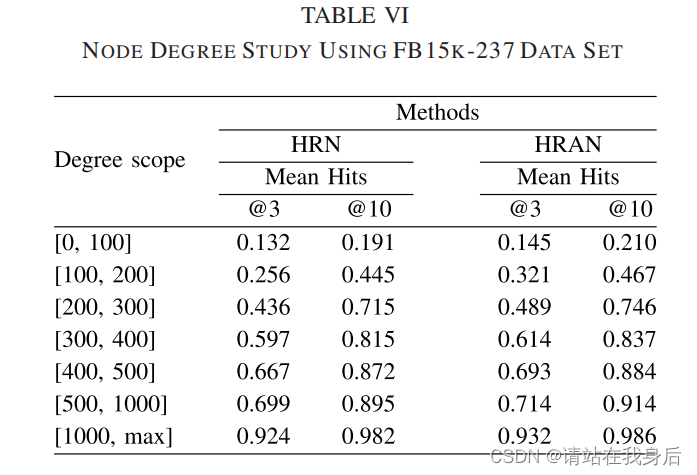
节点度平均值随着度量范围的增加而增加,这意味着HRAN可以受益于更多邻居信息的聚合,然后生成的实体和关系嵌入可以更具表现力。
4.4 不同聚合器的影响
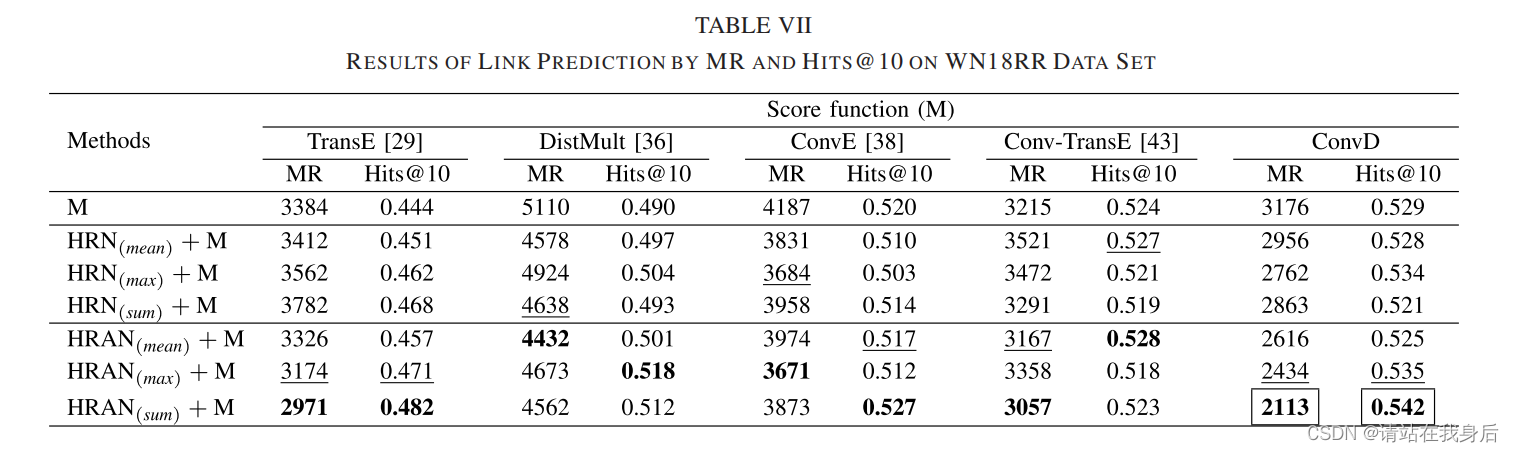
结果表7所示,由不同聚合器函数组成的GNN架构对方法的性能有重大影响。因此,建议在每个数据集的基础上评估聚合函数的影响。
5 参数敏感性
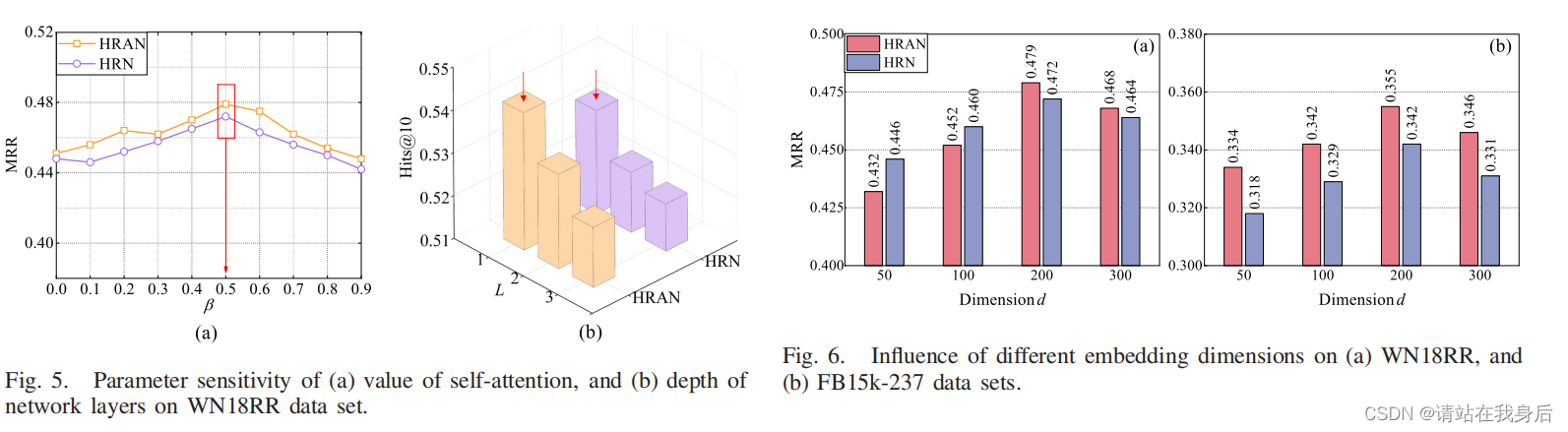
1)自注意力值β:自注意力值β决定自循环的权重。整体结果如图5(a)所示。当β等于0.5时,结果最好
2) 网络层深度L:结果如图5(b)所示。随着网络层数的增加,实验结果会变得更差。
3)嵌入维度,如图6所示。维度大小为200可以获得显著的结果。
6.结论
在本文中,为了捕捉异构知识图谱中复杂的结构和丰富的语义,我们提出了异质关系注意网络(HRAN)。HRAN通过关系路径分别聚合相邻特征。同时,通过注意力机制学习每个关系路径的重要性,注意力机制用于选择性地聚合信息特征。对于三重态预测,提出了生成关系特定滤波器的ConvD。然后,从每个实体中提取特定于关系的语义特征,在卷积运算期间。链路预测任务的实验结果证明了该方法的有效性。此外,还研究了不同参数的灵敏度效应和进一步分析。对于未来的工作,由于采样有用的错误训练示例是一项关键任务,因此可以利用最新生成的对抗网络来生成错误的三元组。
1.提出了一种新的端到端异构关系注意网络(HRAN)框架。具体来说,HRAN通过关系路径融合每种特定于语义的信息。它能分层聚合相邻特征,同时保留不同的特征信息。我们的工作使GNN直接应用于异构KGs,并进一步方便后续的链路预测任务。
2.注意机制被用来学习每个关系路径的重要性。基于学习到的注意值,该方法可以选择性地聚合信息特征,抑制无用的信息特征。此外,HRAN采用了三种有效的聚合函数来降低方差和计算复杂度,可应用于大规模异构图。
此外,还研究了不同参数的灵敏度效应和进一步分析。对于未来的工作,由于采样有用的错误训练示例是一项关键任务,因此可以利用最新生成的对抗网络来生成错误的三元组。















 1584
1584











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









