






A Capsule Network-based Embedding Model for Knowledge Graps Completion and Search Personalization
基于胶囊网络的知识图完成和搜索个性化嵌入模型
发表于:NAACL-HLT 2019, pages 2180–2189
摘要:在本文中,我们引入了一个名为CapsE的嵌入模型,探索一个胶囊网络来模拟关系三元组(主题,关系,对象)。我们的CapsE将每个三元组表示为3列矩阵,其中每个列向量表示元素在三元组中的嵌入。然后将该3列矩阵馈送到卷积层,其中操作多个滤波器以生成不同的特征映射。将这些特征映射重建到相应的胶囊中,然后将其路由到另一个胶囊以产生连续向量。该向量的长度用于测量三元组的合理性得分。我们提出的CapsE在两个基准数据集WN18RR和FB15k-237上获得了比以前最先进的知识图完成嵌入模型更好的性能,并且在搜索上优于强大的搜索个性化基线17。
如果不太了解胶囊神经网络的话可以先去看一下苏神的笔记(赞美苏神!)
揭开迷雾,来一顿美味的Capsule盛宴 - 科学空间|Scientific Spaces
https://spaces.ac.cn/archives/4819
本文将vs,vr和vo分别表示为s,r和o的k维嵌入。在CapsE中将每个嵌入三元组[vs,vr,vo]视为矩阵A=[vs,vr,vo]∈Rk×3,Ai∈R1×3作为A的第i行。我们使用滤波器ω∈R1×3在卷积层上操作。这个滤波器在A的每一行上重复操作,生成一个特征映射q[q1,q2,…,qk]∈ 其中qi=g(ω·Ai+b)其中·表示点积b∈R是偏置项,g是非线性激活函数,如ReLU。我们的模型使用了多个过滤器∈R1×3生成要素图。我们表示Ω 作为一组滤波器,N=|Ω| 作为过滤器的数量,因此我们有Nk维特征映射,对于这些特征映射,每个特征映射可以在同一维度的条目中捕获单个特征。
我们用两个单胶囊层构建CapsE,以简化架构。在第一层中,我们构造k个胶囊,其中来自所有特征映射的相同维度的条目被封装到相应的胶囊中。因此,每个胶囊可以在嵌入三元组中的相应维度处捕获条目之间的许多特征。这些特征被推广到第二层中的一个胶囊中,其产生矢量输出,其长度用作三元组的得分。
第一胶囊层由k个胶囊组成,每个胶囊i∈ {1,2,…,k}有一个向量输出ui∈RN×1。向量输出量乘以权重矩阵Wi∈Rd×N生成向量ui∈Rd×1,求和得到向量输入s∈Rd×1到第二层的胶囊。然后胶囊执行非线性squash函数以产生向量输出e∈Rd×1:
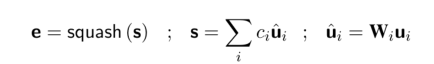
其中squash函数为:
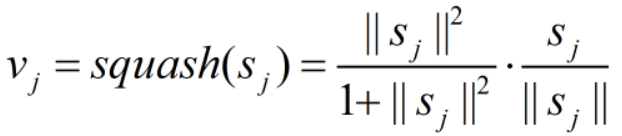
ci是由算法1中提出的路由过程确定的耦合系数。因为在第二层中有一个胶囊,所以我们在Abour等人(2017)提出的路由过程中只做了一个区别,为此我们将softmax应用于从前一层中的所有胶囊到每个胶囊的方向下一层

我们在图1中说明了我们提出的模型,其中嵌入大小:k=4,滤波器的数量:n=5,第一层胶囊内的神经元数量等于N,第二层胶囊内的神经元数量:d=2。矢量输出e的长度用作输入三元组的分数。
我们将三元组(s,r,o)的得分函数定义如下:
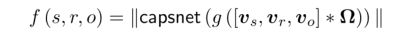
过滤器Ω 是卷积层中的共享参数;∗表示卷积算子;capsnet表示胶囊网络。我们使用Adam优化器通过最小化损失函数来训练CapsE:
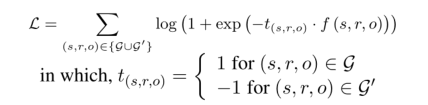
这里G和G’分别是有效和无效三元组的集合.G’是通过破坏G中的有效三元组生成的。
链接预测实验结果:

个人总结:本篇论文的核心是胶囊神经网络,胶囊神经网络实际上应该是对于传统卷积神经网络中最大池化层的改进,原本的最大池化层在池化的过程中丢失了很多信息,因此造成CNN的很多缺点。本文可以说是在CovKB的基础上进行的改进,效果也可以看出和CovKB不相上下。
















 1163
1163











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









