






Week1
前端游戏

看代码

通关之后调用mota()方法

mota方法是一个算法,计算flag
想办法先调用mota方法就可以了
改一下代码即可(源代码dump一下,重新跑一下)
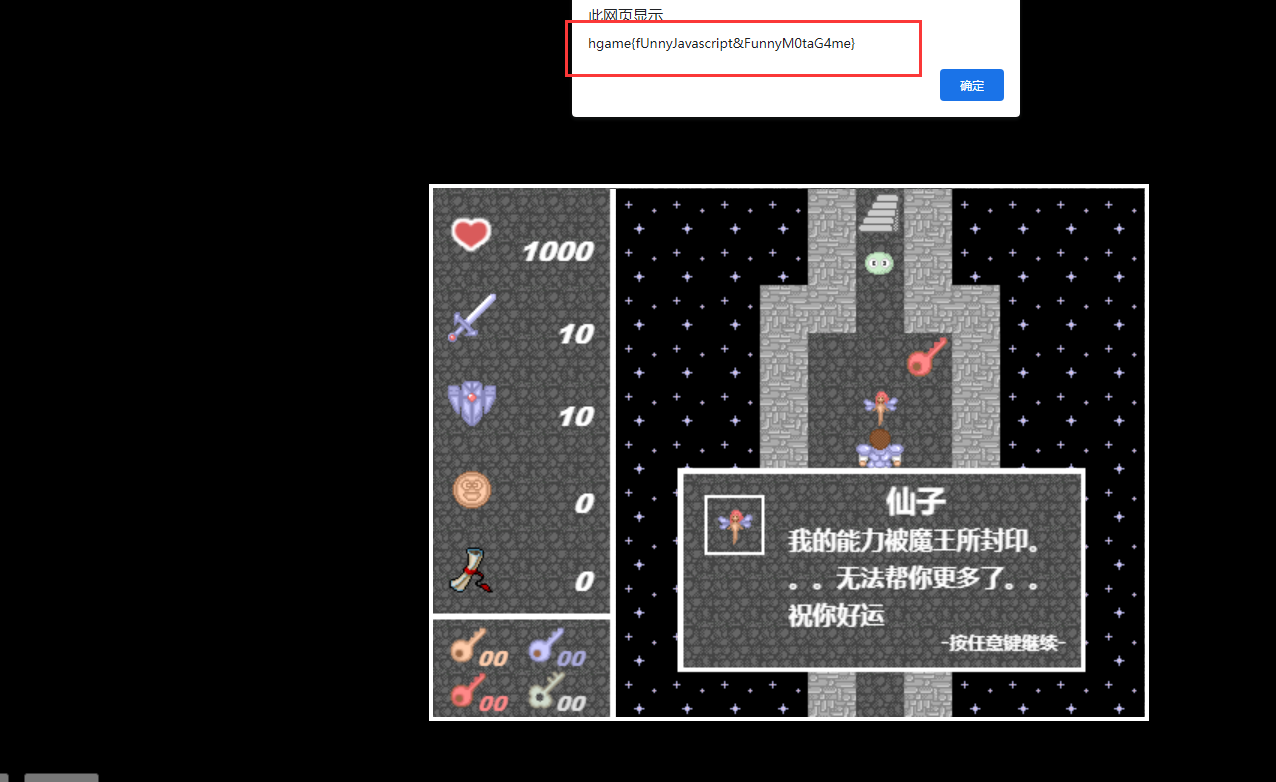

身份伪造类型
补充知识点
headers(UA、referer、cookies)
Cookie:在我们每次访问对方服务器的时候,服务器都会为在我们本地设置cookie,为什么要设置cookie呢?因为对方的服务器要了解我们的身份。在我们下一次访问该服务器的时候,都会带上这个cookie,表明我们的身份。(例如我们在登陆某个网站的时候,在一段时候内在次进行访问,不需要再次登录)
Referer:这个请求参数的作用主要是标识着请求是从哪个页面过来的。例如:在登陆某个网站的时候,登陆成功会跳转到个人中心。那么Referer的值就会是登录界面的url。
User-Agent:在我们访问浏览器的时候,对方浏览器会识别我们的操作系统,版本,浏览器版本等等,来判断我们是否是正常请求。
总结:
我们在爬虫的时候,主要是想要获取对面的数据,而对面则是不想让我们进行获取。所以我们会进行各种各样的伪装,上面的几个请求头都是让我们伪装成浏览器,让对方识别我们为爬虫的概率更小,让我们爬取到想要的数据。
根据类型来判定
网站为了保护自己的数据不被爬取,都会设置许多反爬措施。其中较为简单的就是检测访问请求头部,如果检测出不是合法的请求头,服务器就不返回数据。请求头headers中常用于设置反爬的参数有User Agent、referer和cookies。在做爬虫时,遇到了一些相关案例,将案例和相关应对措施发出来与大家分享下。
1、User Agent反爬
User Agent是标识请求的浏览器身份的,网站常用这个参数来分辨爬虫。如豆瓣网,当请求headers中没带User Agent时,返回404.
2、referer反爬-上海证券交易所
当请求不带referer时,返回403错误。
import requests
url = 'http://query.sse.com.cn/security/stock/getStockListData2.do?&jsonCallBack=jsonpCallback96332&isPagination=true&stockCode=&csrcCode=&areaName=&stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=1&pageHelp.pageSize=25&pageHelp.pageNo=2&pageHelp.endPage=21&_=1522509003629'
response = requests.get(url)
print(response.text)返回403

而带上referer后,则可正常返回所请求数据。
import requests
headers={
'Referer':'http://www.sse.com.cn/assortment/stock/list/share/'
}
url = 'http://query.sse.com.cn/security/stock/getStockListData2.do?&jsonCallBack=jsonpCallback96332&isPagination=true&stockCode=&csrcCode=&areaName=&stockType=1&pageHelp.cacheSize=1&pageHelp.beginPage=1&pageHelp.pageSize=25&pageHelp.pageNo=2&pageHelp.endPage=21&_=1522509003629'
response = requests.get(url,headers= headers)
print(response.text)如下图,带上referer后,服务器返回所请求数据。
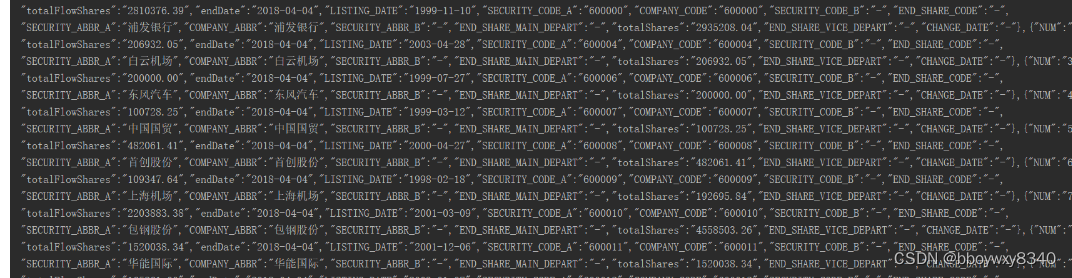















 3064
3064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









