






 本文介绍了数据库中分区表(包括动态分区和静态分区)、非分区表以及不同建表模型(如聚合、唯一、明细和主键模型)的区别和使用场景,特别关注了RocksDB中的分区参数设置。
本文介绍了数据库中分区表(包括动态分区和静态分区)、非分区表以及不同建表模型(如聚合、唯一、明细和主键模型)的区别和使用场景,特别关注了RocksDB中的分区参数设置。
分区表与非分区表
动态分区表(需加分区分桶字段和动态分区的参数,一般都使用数据的创建时间作为分区字段,此时间之后再也不会发生变化,否则在之后的数据进行更新操作时,相同的数据会落入不同的分区之中,造成数据重复问题。动态分区表的动态主要体现在分区的创建是动态的,无需手动创建)

静态分区表(需加分区分桶字段,但不需要加动态分区参数,一般都使用数据的创建时间作为分区字段,此时间之后再也不会发生变化,否则在之后的数据进行更新操作时,相同的数据会落入不同的分区之中,造成数据重复问题。静态分区表的静态主要体现在分区的创建是需要手动创建的)

非分区表(无需加分区字段,但需加分桶字段,否则报错)
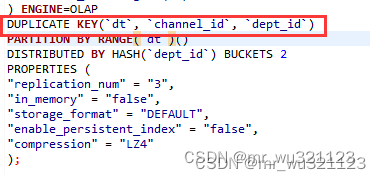
建表模型
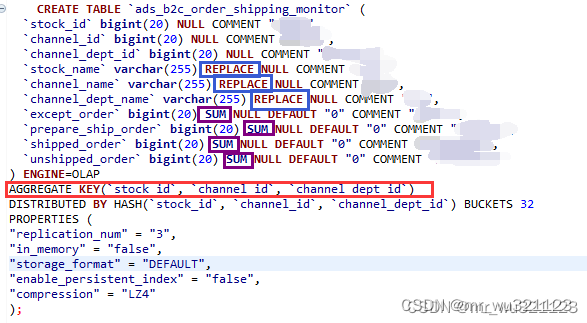
聚合模型(aggregate key,需要将非key列的维度字段加replace,如下图的蓝色框所示,指标字段加具体的聚合方式sum,max,min等等,如下图的紫色框所示。此模型会将相同key的指标值进行聚合操作。)
唯一模型(unique key,采用merge on read策略,不会真正的删除数据,而是先将相同key的数据合并为一组,然后返回一组中的最新数据。此模型只显示相同key的最新数据,从而实现去重的效果。)

明细模型(duplicate key,来什么数据就插入什么数据,不会进行去重,也不会进行聚合等等操作)

startRocks比doris多出一种主键模型(delete+insert,真正会删除相同key的历史数据,然后将最新数据进行插入。此模型只存储相同key的最新数据,从而实现去重的效果。)
分区表中的分区参数指定

参数解释:dynamic_partition.start表示以今天为时间基准,创建且保留多少天的历史分区数,为负数。
dynamic_partition.end表示以今天为时间基准,创建且保留多少天的未来分区数,为正数。
因此上图的总分区就是90+60=150个分区















 1257
1257











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









