







深度学习最令人振奋的最新动态之一,就是端到端深度学习end-to-end deep learning的兴起。
什么是“端到端深度学习”
以前有一些数据处理系统或学习系统,它们需要多个阶段的处理。
端到端深度学习end-to-end deep learning简而言之就是:忽略这些不同的阶段,用单个的神经网络替代它。
例子如下:
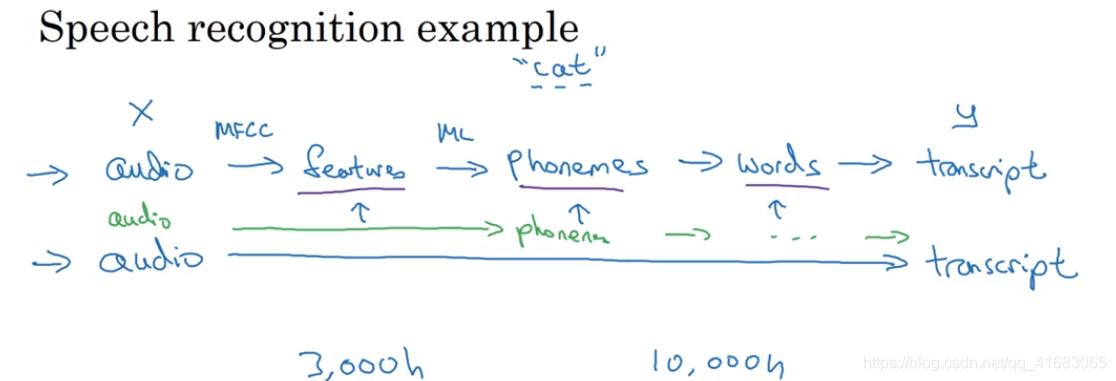
端到端深度学习的挑战之一是:需要大量的数据才能让系统表现良好。
根据数据集的大小可大致分为下面几种情况:
- 少量数据集
比如你有3000小时的数据去训练语音识别系统,那么传统的流水线效果真的很好。 - 大量数据集
但当有非常大的数据集时,比如10000小时的数据或者100000小时,这时候端到端深度学习就 suddenly starts to work really well。 - 数据量适中
也可以用中间件方法,但可以将多个连续的阶段组合到一起,然后用端到端深度学习替代。
另一个人脸识别的门禁系统:
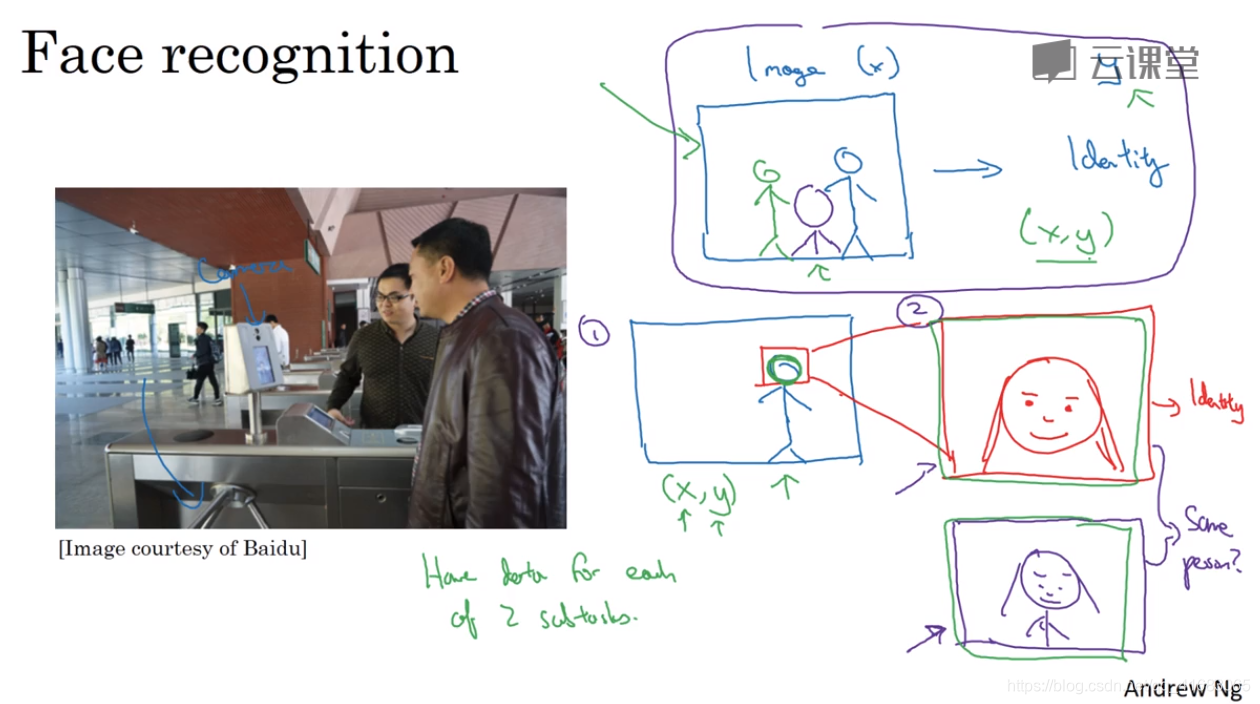
在这个例子中,将识别过程分为两步(人脸检测+人脸识别),要好于直接用端对端深度学习。
原因如下:
- 将一个问题分为两个问题,每个问题实际上要简单得多(each of two problems you’re solving is actually much simpler)
- 两个子训练集数据都很多,而直接满足端到端深度学习的训练数据要少得多。
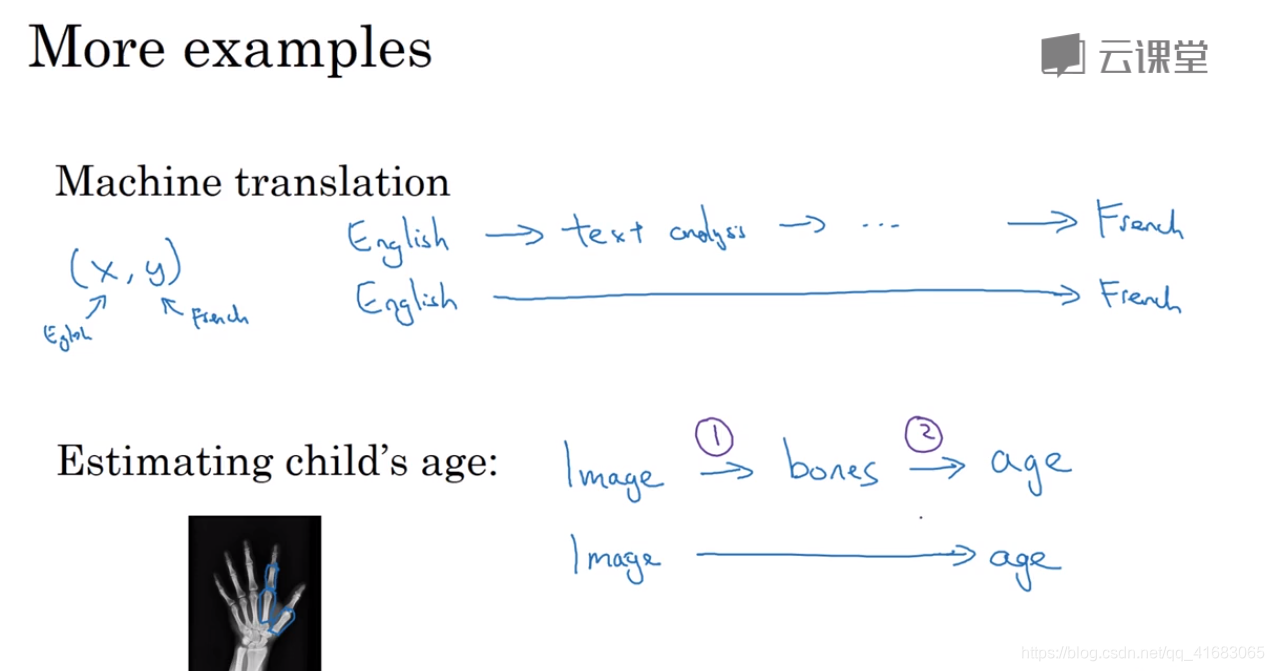
端对端深度学习的优缺点

对应的来解释一下:
pros:
- 不会引入人类的知识(比如音位),从而可能更能捕获数据中的任何统计信息,而不是被迫引入人类的成见。
- 没有需要解释的
cons:
- 有可能满足子任务的数据很多,而满足端到端深度学习的数据很少。
- 在没有足够数据的情况下,加入手工组件可能是把人类知识直接注入算法的途径,而这不总是一件坏事情。
吴恩达老师认为:
学习算法有两个主要的知识来源,一个是数据,一个是你手工设计的任何东西。
当你有成吨数据时,手工设计的东西就不太重要了。但当你没有太多的数据时,构造一个精心设计的系统实际上可以将人类对这个问题的很多认识直接注入到问题里,and should help。
何时使用端对端深度学习

有足够多的数据去完成x到y的映射。














 358
358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









